本次的分享Topic是:精准营销中的数据应用。
内容概要
- O2O的营销业务和系统演变;
- 数据系统和服务在营销系统中的应用;
- 数据挖掘和用户画像的建设。
O2O的营销业务和系统演变
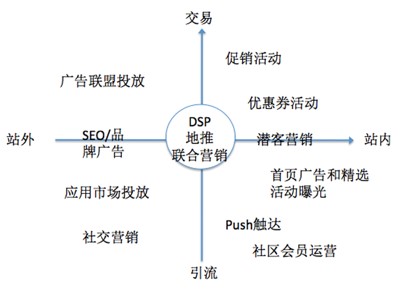
在介绍技术框架前,为了方便大家理解,先简单阐述一下O2O营销的基本组成:O2O营销是由营销发生的渠道(站内,站外)与营销的主题业务(流量,交易)两个维度组成的,其中产生了多种营销的形态,如精准化用户营销活动、DSP的精准投放、渠道价值排名和反作弊等,数据分析和挖掘在这些环节都能发挥很大的价值。本次我们主要介绍站内精准化营销。
一个站内用户运营活动的生命周期大概可以归纳为:确定目标、选取活动对象、设计活动方案、活动配置与上线、线上精准营销与动态优化以及效果监控与评估六个环节。
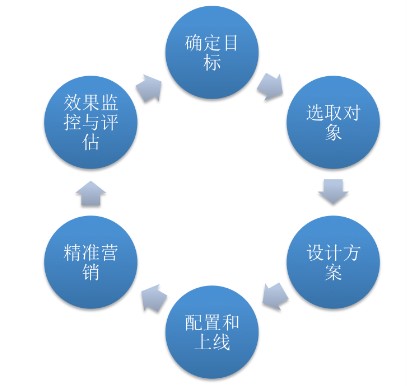
这里最基础的是需要一个营销系统进行配置和投放,在线上用户可以查看,进行交易并享受优惠。
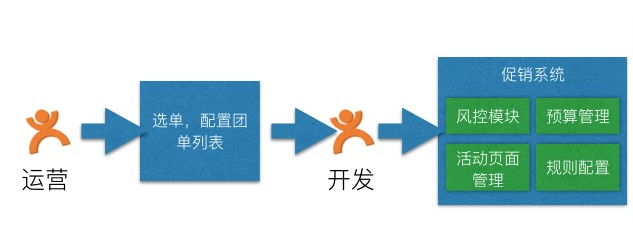
过去的营销系统,运营人员都是自己手工配置优惠团单,由开发同学导入线上系统,过程低效,而且各个相关服务和模块不管从数据上还是接口上都是耦合在一起,出问题排查困难,而且基本无法scale扩展。并且活动效果数据无法统计评估。如下图所示:
通过几轮改造后,我们从数据模型和服务上解偶系统,分为预算中心,提报中心,活动制作中心,数据中心。同时将其他依赖系统作为旁路服务。
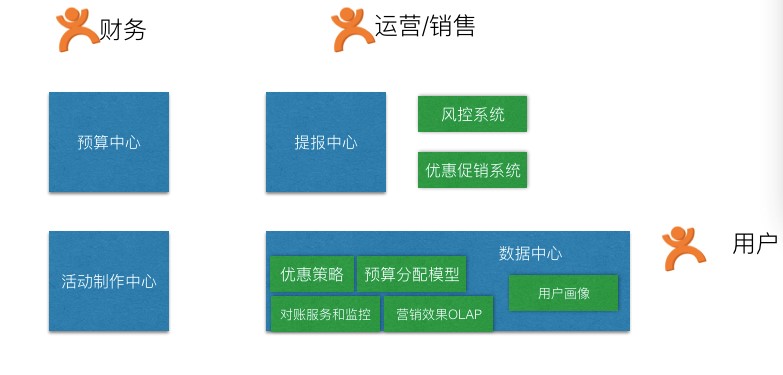
从图中可以看出,新系统中对数据非常重视,一些包括预算分配,优惠策略模型,效果分析都包在数据中心里,通过服务提供出来。
数据系统和服务在营销系统中的应用
下面重点和大家分享这一块的系统设计和相关组件应用场景。
我们先看一下点评目前整个数据体系:
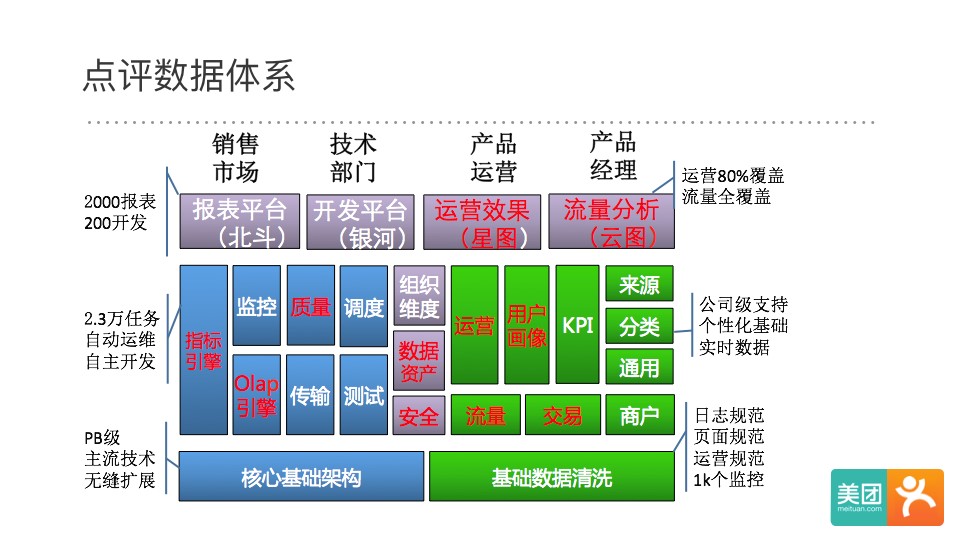
- 蓝色部分为系统和服务:主要包括传输,计算,调度;
- 绿色部分为数据仓库模型:分为底层基础模型和上层的数据集市
- 紫色部分是产品和平台:主要分为流量分析,运营分析,开发和报表等;
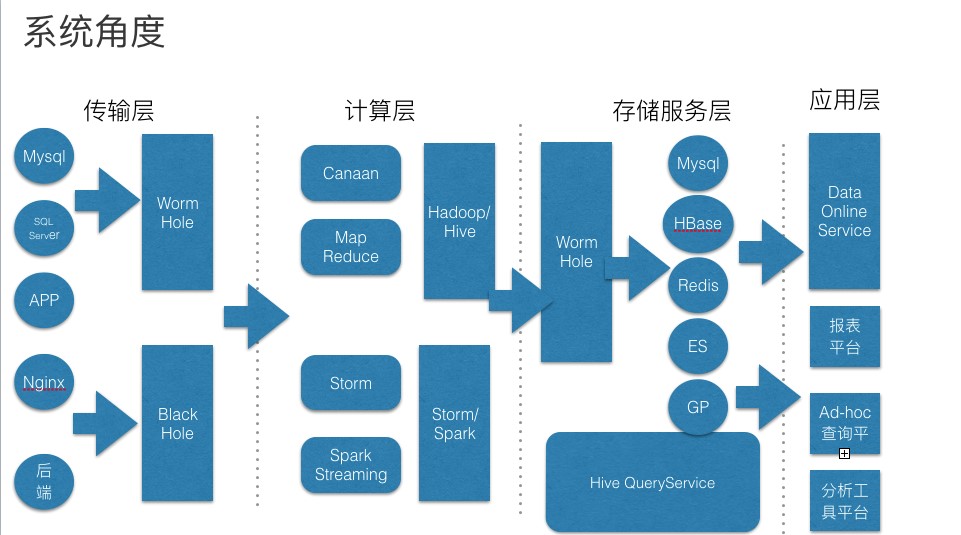
系统角度看,分为4大部分:
- 传输层:将异构的业务系统的数据传输到数据仓库中,这里我们开发了两个自己的传输组件(Wormhole和Blackhole)分别负责日志和结构化数据的传输
- 计算层:我们开发了基于模版语言的Hive 开发框架Cannan,另外也从离线和实时计算两个搭建了基于hadoop/hive和Storm/spark的计算平台
- 存储层:经过加工计算的数据,我们提供多种存储介质以供不同场景使用:Mysql主要服务报表系统,Hbase和Redis服务
- 应用层:分为面向线上高可用4个9的数据服务和报表以及即席查询和分析平台
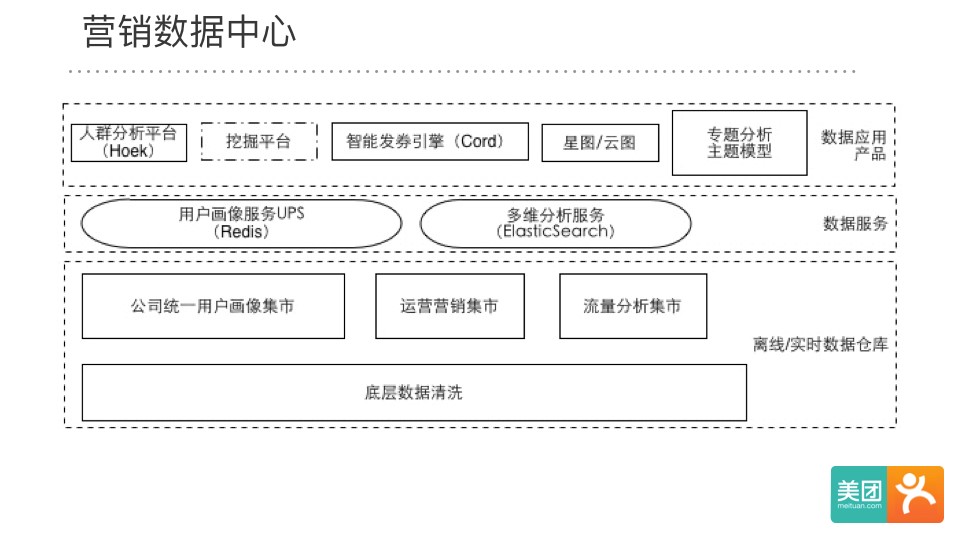
最底层是我们的数据仓库和模型层,这里又大致可以分为三个主题:画像,运营和营销,流量。这三个都是运营活动必不可少的数据组成部分。
在营销运营集市上,我们与财务和支付系统协作,开发了一套公司预算流水号系统。运营人员在配置活动时,从财务申请预算流水号,并在优惠后台配置与对应活动关联,用户享受优惠的每一笔订单都会在业务表中进行打点,做到在最细粒度上的预算监控。同时在用户、商品等维度建模后,形成了营销交易评估的指标体系:新用户成本,新老用户分布,7天、30天购买留存等。
活动评估的另一个维度就是流量:活动页的点击、转化漏斗、不同渠道来源等指标是运营人员无时无刻不关心的,这部分模型作为数据中心数据仓库中核心的一环。我们参考了其他公司的做法,建立了自己的PV、UV、Session以及路径树转化等模型,可以很好地满足运营需求。
在数据仓库之上,我们建立了数据服务层。在统一使用公司高性能的RPC框架之上,针对不同的应用选择了差异化的数据存储和查询引擎。比如在画像服务中,需求是满足线上业务系统的实时访问需求,要求毫秒级的并发和延迟,因此我们选用了Redis作为存储。
而相较之下,分析类产品对并发和延迟要求相对较低,但对数据在不同维度上的聚合操作要求较高,在对比了Kylin、ElasticSearch(以下简称ES)、Druid后,我们决定使用ES作为存储和查询引擎,主要有2个理由:一是我们有留存等指标,需要重刷数据,而对于Kylin来说,无法使用其提供的自动增量cube机制,重建数据代价较大,同时ES在同样的维度上,空间膨胀度上比Kylin少近一半;二是ES整个系统设计和架构非常简洁,运维方案简单,也有专门的工具支持,对于当时没有专职运维的开发团队来说是一个捷径。
这里要补充一下,上次和kylin的开发团队交流,kylin新版本有一些优化,可以解决数据重刷的问题,并且我们北京的同事作为kylin的committer,和我们紧密合作,修复了不少bug,后续我们的OLAP查询分析系统可能会考虑kylin作为QueryEngine。
数据挖掘
另外一块数据线上服务,我们基于Redis提供了譬如:新用户,闪惠随机立减和用户实时行为等服务。
最上层是数据产品和应用,针对前面提到的运营活动的不同阶段提供数据平台和工具。
spark挖掘平台
云图/星图:基于ES的多维查询平台:活动效果实时更新和查询
人群分析平台(Hoek)
用户可以通过选择画像服务提供的不同的标签组合快速创建人群包,创建的人群包可以提供给其他不同业务和形态的营销工具,如push,促销工具等。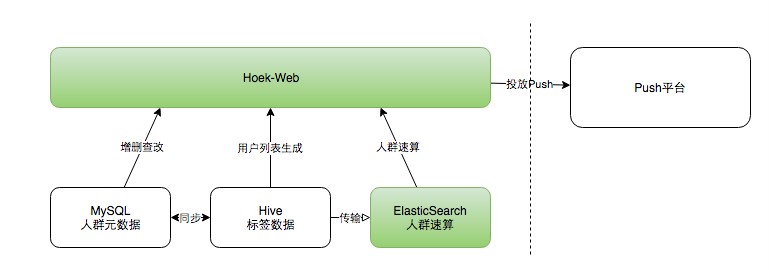
由于运营需要实时知道人群包大小,由于我们是亿级别的用户和百级别的标签,这个数量级下Hive很难在规定时间返回结果,我们采用了基于ES的方案,通过自定义docid和嵌套的文档结构模型设计开发了人群速算功能,能够在秒级返回。
智能发券引擎:Cord
Cord是智能发券引擎,背景是点评会在微信群/朋友圈中用红包发各种优惠券,当好友来领券时,如何决定发哪个业务什么面值的券更容易转化。本质上是一个简化的推荐问题,我们也参照广告系统的架构设计了Cord引擎。主要包含分流模块(用于灰度发布和AB测试)、召回模块(负责从画像服务和优惠配置系统获取人和券的物料信息)、过滤模块(负责进行两者的匹配)、推荐模块(可以根据业务规则或者我们挖掘的策略对结果进行排序,返回給活动系统最合适的优惠券进行发放)。
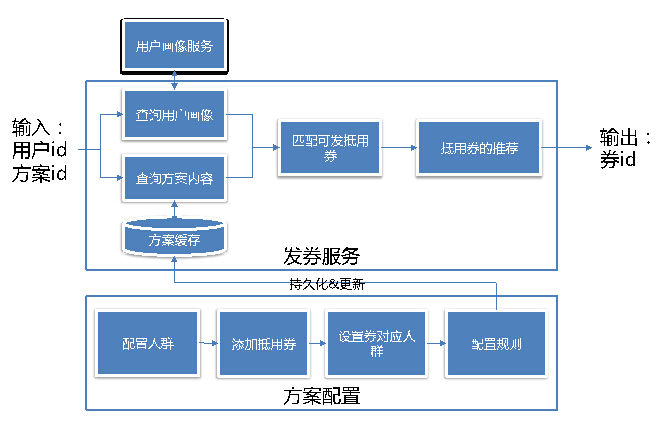
整个系统实现完全服务化和可配置化,外部的活动系统可以根据配置的开关启用或者在特殊场景下禁用Cord服务;而Cord内部,也可以根据配置中心的设置,动态调整推荐策略。
背景是点评会在微信群/朋友圈中用红包发各种优惠券,当好友来领券时,如何决定发哪个业务什么面值的券更容易转化。
建设用户画像
在数据体系中,另外一个很重要的建设就是用户画像体系和服务。我们的做法是部分自主建设,同时集成业务方如搜索、广告和风控团队开发的画像标签,形成统一的画像宽表。目前我们的用户标签体系覆盖了包括:基本信息、设备信息、消费浏览以及特征人群等5个大类的180多个标签。在标签的实现上,我们也秉承从需求出发的原则逐步迭代,从最初的以统计和基本的营销模型如RFM为主,到现在在潜在用户挖掘和用户偏好上开始探索使用机器学习的挖掘方法。
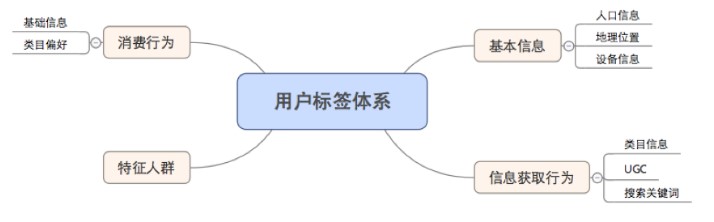
特别是在点评这个平台上,目前已有包括美食、外卖、丽人、教育等近20个业务,如何在平台近一亿的活跃用户中挖掘垂直频道的潜在用户就成了精准化营销的一个很现实的问题。
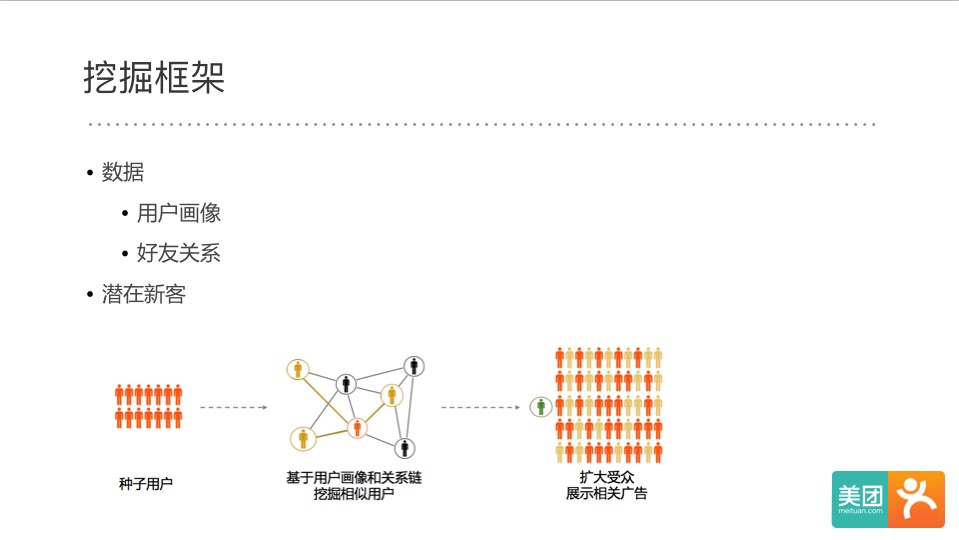
Facebook和腾讯的广告系统都提供类似的Lookalike功能,帮助客户找出和投放人群相似的用户群,其广告的点击率和转化率都高于一般针对广泛受众的广告我们大致的思路也是根据用户画像和好友关系,通过挖掘和相似度模型通过种子用户扩展受众。
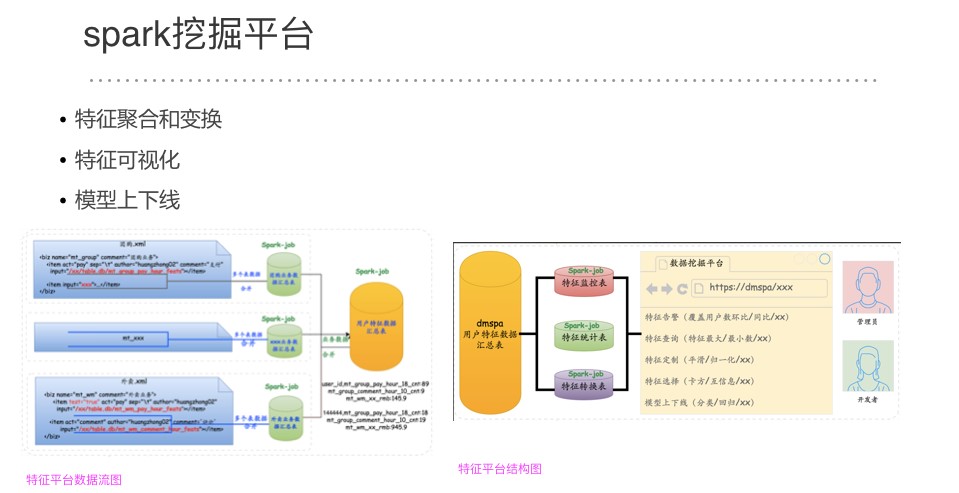
目前,在新美大,公司内部有一套基于spark的挖掘平台,我们也是基于这个平台开展挖掘工作。
这个平台主要提供:1. 特征聚合和变换;2. 特征可视化;3. 模型上下线
详情可以查看之前同事发在美团点评技术博客上的文章:http://tech.meituan.com/spark-in-meituan.html 这里面我们主要用到了关联规则,LR,基于社交网络的标签传播和协同过滤的算法(mllib里的ALS)
总结
最后总结一下我们在数据建设中遇到的一些坑和经验。第一:需要强大的金字塔模型提供准确,完整的底层数据
相信做过数据应用的同学都肯定受过数据不准确,不及时带来对数据模型,运营活动效果评估不准确的问题我们从一开始就有专门的团队负责数据仓库的建设,也建设了配套的主数据,数据质量监控工具。不同层的SLA约束保证了数据的准确性和完整性
第二:需要有接耦和稳定可靠的数据系统和服务
由于像新用户接口和活动实时效果数据都是非常critical的服务和应用,可用性和可靠性要求很高我们在基于Redis和ES的组件上开发了运维和监控体系。同时对Query Engine进行分布式化和降级备案
第三:深入业务,不断试验,评估和迭代
对于做数据挖掘和精准化服务,首先是要理解业务和运营规则,不要一味迷信模型同时要有完整的AB测试和灰度化方案,支持线上多套策略并行运行,并且有实时化的数据反馈,可以帮助新模型和策略上线后的快速评估。
Q&A
Q: 请问hadoop和spark都可以做数据挖掘和机器学习,在技术选型上有什么诀窍?谢谢A: spark因为基于内存的迭代计算模式,而机器学习大部分模型也就是基于迭代的,所以原则上来说spark更快,而且spark的mllib 封装的机器学习的算法和特征工程库也很丰富,我个人推荐用spark
Q: 能具体讲讲wormhole和blackhole的区别吗?后端没有数据总线吗?
A: blackhole类似于kafkawormhole是用于传输结构化数据。可以参考我们同事之前的一篇文章: http://www.csdn.net/article/2013-12-18/2817838-big-data-practice-in-dianping
Q: 请问期间有用过hortonworks或者sas工具么
A: hortonworks具体的什么组件?没有用SAS,但调研和分析数据的时候用R
可用参考: http://www.csdn.net/article/2015-03-26/2824303
分享者简介
樊聪 美团大众点评到店综合事业群大数据负责人目前负责美团大众点评到店综合事业群B端基础数据仓库、供应链和商家平台数据产品和服务, 以及C端推荐和个性化项目。主导点评AB测试平台、流量分析平台以及精准化营销系统的开发和设计。加入点评前曾在百度参与流量数据仓库和画像服务的建设, 再早之前在微软MSRA自然语言组和上海研发集团工作和实习。主要关注领域:数据挖掘和数据产品,OLAP建模和工具点评AB测试平台、流量分析平台以及 精准化营销系统的开发和设计。
