linux内核网络中RPS/RFS原理
在上篇中,从整体上讲解了网络软中断的机制和优化,但是在RPS和RFS处并没有彻底讲清楚,只是描述了其整体功能和涉及初衷。这篇,进一步深度并搞明白RPS和RFS机制。
1.1.1 自带irqbalance瓶颈
基于简单的中断负载均衡(如系统自带的irqbalance进程)可能会弄巧成拙。因为其并不识别网络流,只识别到这是一个数据包,不能识别到数据包的元组信息。
在多处理器系统的每个处理器都有单独的硬件高速缓存,如果其中一个CPU修改了自己的硬件高速缓存,它就必须该数据是否包含在其它CPU的硬件高速缓存,如果存在,必须通知其它CPU更新硬件高速缓存,这叫做CPU的cache一致性。所以为了降低CPU硬件高速缓存的刷新频率,需要把特征相似的数据包分配给同一个CPU处理。
另外在TCP的IP包的分段重组问题,一旦乱序就要重传,一个linux主机如果只是作为一台路由器的话,那么进入系统的一个TCP包的不同分段如果被不同的cpu处理并向一个网卡转发了,那么同步问题会很麻烦的,如果不做同步处理,那么很可能后面的段被一个cpu先发出去了,那最后接收方接收到乱序的包后就会请求重发,这样则还不如是一个cpu串行处理。
这个需要一套方案,需要弄清楚三个问题:
l  哪个CPU在消耗这个网络数据
l  哪个CPU在处理中断
l  哪个CPU在做软中断
这个三个问题就是RPS/RFS需要去解决的。
1.1.2 数据结构
linux底层的很多机密都藏在数据结构中,包括其面向对象的设计。所以先来看下这些数据结构。
网卡的硬件接收队列netdev_rx_queue, 定义在文件:
include/linux/netdevice.h中。
struct netdev_rx_queue {
#ifdef CONFIG_RPS
struct rps_map __rcu *rps_map;
struct rps_dev_flow_table __rcu *rps_flow_table;
#endif
struct kobject kobj;
struct net_device *dev;
struct xdp_rxq_info xdp_rxq;
} ____cacheline_aligned_in_smp;
存放解析结果的就是网卡硬件接收队列实例的rps_map成员, cpus数组用来记录配置文件中配置的参与报文分发处理的cpu的数组,而len成员就是cpus数组的长度。解析函数为store_rps_map定义在文件net/core/net-sysfs.c中。
/*
* This structure holds an RPS map which can be of variable length. The
* map is an array of CPUs.
*/
struct rps_map {
unsigned int len;
struct rcu_head rcu;
u16 cpus[0];
};
设备流表rps_dev_flow_table,定义在文件:include/linux/netdevice.h中。mask成员是类型为struct rps_dev_flow的数组的大小,也就是流表项的数目,通过配置文件 /sys/class/net/(dev)/queues/rx-(n)/rps_flow_cnt进行指定的。当设置了配置文件,那么内核就会获取到数据,并初始化网卡硬件接收队列中的设备流表成员rps_flow_table(初始化过程函数store_rps_dev_flow_table_cnt)。
/*
* The rps_dev_flow_table structure contains a table of flow mappings.
*/
struct rps_dev_flow_table {
unsigned int mask;
struct rcu_head rcu;
struct rps_dev_flow flows[0];
};
rps_dev_flow类型的实例则主要包括存放着上次处理该流中报文的cpu以及所在cpu私有数据对象softnet_data的input_pkt_queue队列尾部索引的两个成员.
/*
* The rps_dev_flow structure contains the mapping of a flow to a CPU, the
* tail pointer for that CPU's input queue at the time of last enqueue, and
* a hardware filter index.
*/
struct rps_dev_flow {
u16 cpu;
u16 filter;
unsigned int last_qtail;
};
下面的rps_sock_flow_table是一个全局的数据流表,这个表中包含了数据流期望被处理的CPU,是当前处理流中报文的应用程序所在的CPU。全局socket流表会在调recvmsg,sendmsg (inet_accept(), inet_recvmsg(), inet_sendmsg(), inet_sendpage() and tcp_splice_read())被设置更新。最终调用函数rps_record_sock_flow来更新ents数组的。
mask成员存放的就是ents这个数组的大小,通过配置文件/proc/sys/net/core/rps_sock_flow_entries的方式指定的。
rps_record_sock_flow函数定义在include/linux/netdevice.h文件中,
每次用户程序读取数据包都会更新rps_sock_flow_table表,保证其中的CPU号是最新的
/*
* The rps_sock_flow_table contains mappings of flows to the last CPU
* on which they were processed by the application (set in recvmsg).
* Each entry is a 32bit value. Upper part is the high-order bits
* of flow hash, lower part is CPU number.
* rps_cpu_mask is used to partition the space, depending on number of
* possible CPUs : rps_cpu_mask = roundup_pow_of_two(nr_cpu_ids) - 1
* For example, if 64 CPUs are possible, rps_cpu_mask = 0x3f,
* meaning we use 32-6=26 bits for the hash.
*/
struct rps_sock_flow_table {
u32 mask;
u32 ents[0] ____cacheline_aligned_in_smp;
};
1.1.3 RPS
rps和rfs的工作都是在软中断上下文中执行,因为该阶段处理工作是和进程无关的,又和底层硬件剥离了。能够实现网络协议栈软中断的负载均衡。
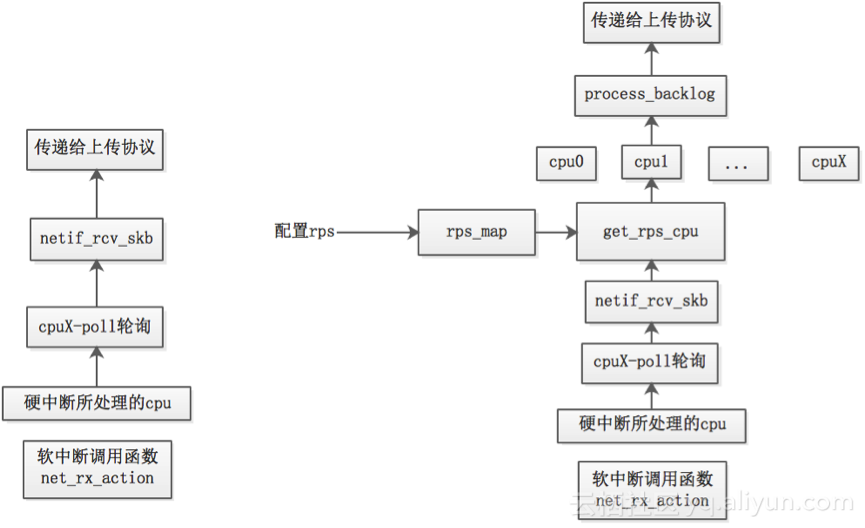
rps实现的总流程如下:将数据包加入其它CPU的接收队列,其它CPU将会在自己的软中断中执行process_backlog,process_backlog将会接收队列中的所有数据包,并调用__netif_receive_skb()执行后续工作。
1.1.3.1 RPS配置
Linux是通过配置文件的方式指定哪些cpu核参与到报文的分发处理,配置文件存放的路径是:/sys/class/net/(dev)/queues/rx-(n)/rps_cpus。
设置好该配置文件之后,内核就会去获取该配置文件的内容,然后根据解析的结果生成一个用于参与报文分发处理的cpu列表,这样当收到报文之后,就可以建立起hash-cpu的映射关系了,解析函数为store_rps_map,结果存放在rps_map中。
1.1.3.2 RPS细节
rps会根据数据包的hash值(报文hash值,可以由网卡计算得到,也可以是由软件计算得到,具体的计算也因报文协议不同而有所差异,如tcp报文的hash值是根据四元组信息,即源ip、源端口、目的ip和目的端口进行hash计算得到的)来选择CPU,选目标cpu的动作具体的实现函数是get_rps_cpu,其定义在net/core/dev.c文件中, 实现从cpu列表中获取核号的:
staticint get_rps_cpu(struct net_device *dev, struct sk_buff *skb, structrps_dev_flow **rflowp)
rps是单纯用报文的hash值来分发报文,而不关注处理该流中报文的应用程序所在的cpu。
那么何时调用函数get_rps_cpu呢?
支持NAPI接口的驱动而言,在上半部主要就是将设备加入到cpu的私有数据softnet_data的待轮询设备列表中,下半部主要就是调用poll回调函数从网卡缓冲区中获取报文,然后向上给协议栈。
函数get_rps_cpu会被netif_rcv_skb调用,获取到用于分发处理报文的目标cpu,如果目标cpu有效,则会调用enqueue_to_backlog()(net/core/dev.c )函数,尝试将报文加入到cpu私有数据对象softnet_data的input_pkt_queue队列中。
数据对象softnet_data中有backlog的成员,该成员类型为struct napi_struct,在函数enqueue_to_backlog()中,会将backlog加入到cpu的待轮询设备列表中,并触发软中断,在软中断处理函数net_rx_action()中会依次遍历待轮询设备列表中的设备,并调用设备注册的poll回调函数来进行报文处理。
从input_pkt_queue队列该队列中取出报文,然后调用__netif_receive_skb()上报文送至协议栈进行后续处理。
如果没有rps的处理流程(现在一般均采用的是NAPI收包方式),软中断处理函数net_rx_action()会调用网卡驱动注册的poll回调函数从网卡中获取到报文数据后就将报文数据上送至协议栈。
对于有rps的处理流程,软中断处理函数net_rx_action()会调用网卡驱动注册的poll回调函数从网卡中获取到报文数据后,暂时不直接送至协议栈,而是选择一个目标cpu,将报文放到该cpu私有数据对象softnet_data的input_pkt_queue队列中,待对列input_pkt_queue满了之后,就将该cpu对应的backlog设备对象加入到该cpu的待轮询设备列表中,并触发软中断,软中断处理函数轮询到backlog设备对象后,调用poll回调函数process_backlog()从input_pkt_queue队列中取出报文,再上送至协议栈。
如下图左边是没有使用rps,右边是使用rps。
1.1.4 RFS
RFS在RPS上的改进,通过RPS可以把同一流的数据包分发给同一个CPU核来处理,但是有可能发给该数据流分发的CPU核和执行处理该数据流的应用程序的CPU核不是同一个。
当用户态处理报文的cpu和内核处理报文软中断的cpu不同的时候,就会导致cpu的缓存不命中。而rfs就是用来处理这种情况的,rfs的目标是通过指派处理报文的应用程序所在的cpu来在内核态处理报文,以此来增加cpu的缓存命中率。rfs和rps,主要差别就是在选取分发处理报文的目标cpu上。
rfs实现指派处理报文的应用程序所在的cpu来在内核态处理报文主要是依靠两个流表来实现的:一个是设备流表rps_dev_flow_table,记录的是上次在内核态处理该流中报文的cpu;另外一个是全局的socket流表rps_sock_flow_table,记录报文期望被处理的目标cpu。
1.1.4.1 RFS细节
rfs相比于rps,主要差别就是在选取分发处理报文的目标cpu上。所以rfs负载均衡策略的实现也主要体现在函数get_rps_cpu()中,具体可以查看其中代码(et/core/dev.c)。
rfs的负载均衡策略通过判断报文的hash值(流hash值)所对应的两个流表(设备流表和全局socket流表)中的记录的cpu是否相同来实施的。
如果当前CPU表对应表项未设置或者当前CPU表对应表项映射的CPU核处于离线状态,那么使用期望CPU表对应表项映射的CPU核。
如果当前CPU表对应表项映射的CPU核和期望CPU表对应表项映射的CPU核为同一个,就使用这一个核。
如果当前CPU表对应表项映射的CPU核和期望CPU表对应表项映射的CPU核不为同一个:
a)如果同一流的前一段数据包未处理完,必须使用当前CPU表对应表项映射的CPU核,避免乱序。
b)如果同一流的前一段数据包已经处理完,那么则可以使用期望CPU表对应表项映射的CPU核。
1.1.5 配置方法
在大于等于2.6.35版本的Linux kernel上可以直接使用,默认都是关闭的。
RPS设置:
RPS指定哪些接收队列需要通过rps平均到配置的cpu列表上。
/sys/class/net/(dev)/queues/rx-(n)/rps_cpus
RFS设置:
每个队列的数据流表总数可以通过下面的参数来设置:
该值设置成rps_sock_flow_entries/N,其中N表示设备的接收队列数量。
/sys/class/net/(dev)/queues/rx-(n)/rps_flow_cnt
全局数据流表(rps_sock_flow_table)的总数,红帽是建议设置成32768,一般设置成最大并发链接数量
/proc/sys/net/core/rps_sock_flow_entries