之前在学Django时,发现它的模型层非常好用,把对数据库的操作映射成对类、对象的操作,避免了我们直接写在Web项目中SQL语句,当时想,如果这个模型层可以独立出来使用就好了,那我们平台操作数据库也可以这么玩了,我不喜欢写SQL语句。
后来才知道,原来这个叫ORM(Object Relational Mapping,对象关系映射),在Python下面有很多这样的类库,如SQLObject、Storm、peewee和SQLAlchemy。
这里就给你们介绍一下Peewee的基本使用,因为它非常的轻量级,最主要是和Django的ORM 操作很像,如果你学过Django那么很容易上手。
这篇博客承接上一篇,以操作MySQL为例。前提条件:
-
Python3.x 编程语言
-
MySQL数据库
-
PyMySQL驱动
一、安装peewee
安装非常简单,推荐使用pip命令。
> pip install peewee
另外,你也可以通过下载包安装:https://pypi.python.org/pypi/peewee
二、创建表
from peewee import *import datetime
db = MySQLDatabase("guest", host="127.0.0.1", port=3306, user="root", passwd="123456")
db.connect()class BaseModel(Model): class Meta:
database = dbclass User(BaseModel):
username = CharField(unique=True)class Tweet(BaseModel):
user = ForeignKeyField(User, related_name='tweets')
message = TextField()
created_date = DateTimeField(default=datetime.datetime.now)
is_published = BooleanField(default=True)if __name__ == "__main__": # 创建表
User.create_table() # 创建User表
Tweet.create_table() # 创建Tweet表
这里面包含不了少知识点,我们来一一解释。
首先,导入peewee库下面的所有方法,这个当然需要。
然后,通过MySQLDatabase连接数据库,把数据连接的几个必要参数一一填写。通过connect()方法与MySQL数据库建立链接。
接下来就是表的创建,创建BaseModel类,在该类下创建子类Meta,Meta是一个内部类,它用于定义peewee的Model类的行为特性。指定dabatase 为 前面定义的db。
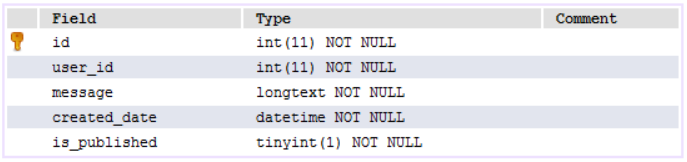
再接下来就是表的创建了,我们在SQL语句创建表时一般需要知道以下信息。表的名字,表有哪些字段?这些字段分别是什么类型?是否允许为空,或自增?哪个字段是主键是?哪个是外键?
ORM用编程语言里的概念帮我们映射了这些东西。
创建 User 和 Tweet类做为表名。在类下面定义的变量为字段名,如username、message、created_date等。通过CharField、DateTimeField、BooleanField表示字段的类型。ForeignKeyField 建立外键。 主键呢? 建表时不都要有个主键id嘛,不用!peewee默认已经为我们加上这个id了。
最后,执行create_table()方法创建两张表。
通过数据库工具,查看生成的两张表。

三、插入数据
要想操作表数据,首先表里得有数据。先来看看如何添加数据。
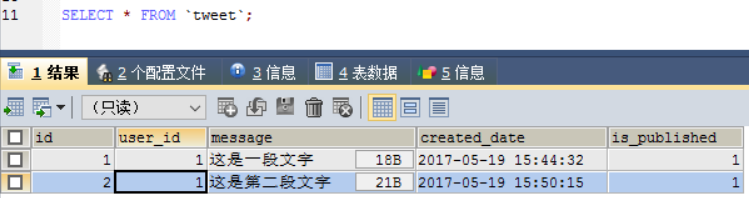
if __name__ == "__main__": # ... user = User.create(username='tom') Tweet.create(user=user, message="这是一段文字")
这样就要User表里添加一个tom的用户,这用户发了一条Tweet,在Tweet表里。但这个用户兴致来了,想继续发第二条Tweet。于是:
if __name__ == "__main__": # ... Tweet.create(user_id=1, message="这是第二段文字")
咦~!?不对,我们没有创建user_id字段啊!但是,如果你查询Tweet表,就会发现有这个字段,用它来关联User表的id。
四、查询数据
接下来,查询数据。
if __name__ == "__main__": # ... # 查询 1 t = Tweet.get(message="这是一段文字") print(t.user_id) print(t.created_date) print(t.is_published)
查询结果:
1 2017-05-19 15:44:32True
不过,get()方法只能查询一条,且是唯一的一条数据;通过查询条件不能查询出多条,也不能查询出0条。
if __name__ == "__main__": # ... # 查询 2 ts = Tweet.filter(user_id=1) for t in ts: print(t.message)
运行结果:
这是一段文字 这是第二段文字
而,filter()方法,就会更加灵活,可以查询多条结果,并把结果循环输出。
五、Playhouse库
Playhouse库中提供了一些比较有意思的方法。当我们在安装peewee时,也会捎带着把它装上。
这里只介绍它里面的model_to_dict和dict_to_model两个方法。
model_to_dict方法用法:
from playhouse.shortcuts import model_to_dict, dict_to_model# ……if __name__ == "__main__": # …… user = User.create(username='jack') # 把数据对象转成字典 u = model_to_dict(user) print(u)
运行结果:
{'id': 7, 'username': 'jack'}
dict_to_model方法用法:
from playhouse.shortcuts import model_to_dict, dict_to_model# ……if __name__ == "__main__": # ……
# 把字典转成数据对象
user_data = {'id': 2, 'username': 'charlie'}
user = dict_to_model(User, user_data) print(user.username)
运行结果:
charlie
本文转自lzwxx 51CTO博客,原文链接:http://blog.51cto.com/13064681/1944357
