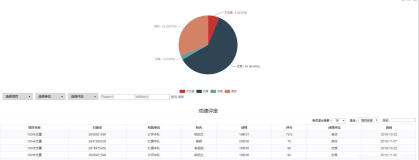
在上一篇博客里面。我们已经把智联的招聘信息存入到数据库(mysql)里面。
接下来我们就需要对里面需要的信息进入 筛选和显示。
直接上代码:
import jieba
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud
import pymysql
import urllib
import bs4
from urllib import request
from bs4 import BeautifulSoup as bs
#数据库定义
class selectMysql(object):
def select_data(self):
list1=[]
#创建数据库链接
conn =pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="zfno11",db="job",charset='utf8')
#创建游标
sql = 'select jobname from job '
cursor = conn.cursor()
try:
cursor.execute(sql)
#提交,不然无法保存新建或者修改的数据
except MySQLdb.Error:
print("数据库执行语句异常")
finally:
alldata = cursor.fetchall()
conn.commit()
#关闭游标
cursor.close()
conn.close()
for i in alldata:
list1.append(i)
return(list1)
#返回获取到的字符串结果
def get_result(self,list1):
self.list1=list1
with open("shuju",'w') as f:
for i in self.list1:
b= str(i).replace("(","").replace(")","").replace("-","").replace(",","").replace(" ","").replace("("," ").replace(")"," ").replace("'","")
f.write(b +'\n')
f.close()
# 创建停用词list
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
#去掉空格
# 对句子进行分词
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
stopwords = stopwordslist('stopwords.txt') # 这里加载停用词的路径
outstr1 = ''
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr += word
outstr1 += " "
#去重
for i in outstr1:
if i not in outstr1:
outstr.append(i)
return outstr
inputs = open('shuju', 'r', encoding='utf-8')
outputs = open('output.txt', 'w')
for line in inputs:
line_seg = seg_sentence(line) # 这里的返回值是字符串
outputs.write(line_seg + '\n')
outputs.close()
inputs.close()
###以上部分完成了从数据库读取jobname然后存入到文本shuju里面,最后对文本进入简单的处理
class ciyun(object):
def __init__(self):
pass
def ciyundis(self):
text = open("output.txt",'rb').read()
wordlist = jieba.cut(text,cut_all=True)
w1= " ".join(wordlist)
# print(w1)
#词云
backgroud_Image=plt.imread('timg.jpg')
wc = WordCloud(background_color = "black", #设置背景颜色
mask = backgroud_Image, #设置背景图片
max_words = 50, #设置最大显示的字数
#stopwords = "", #设置停用词
font_path = "/usr/share/fonts/simfang.ttf",
#设置中文字体,使得词云可以显示(词云默认字体是“DroidSansMono.ttf字体库”,不支持中文)
max_font_size = 150, #设置字体最大值
random_state = 30, #设置有多少种随机生成状态,即有多少种配色方案
)
myword = wc.generate(w1) #生成词云
plt.imshow(myword)
plt.axis("off")
plt.savefig('pink.png', dpi=700) #700是像素,像素越高,放大越清楚
plt.show()
#data= selectMysql()
#EEE=data.select_data()
#data.get_result(EEE)
ciyun1=ciyun()
ciyun1.ciyundis()
执行结果截图: