如果要评选2017三大流行金酸梅奖,毫无疑问,获奖的肯定是指尖陀螺、人工智能以及加密货币。加密货币是一项颠覆性的技术,它背后的原理引人注目,我十分看好它未来的发展。
实际上,我并没有持有任何加密货币,但说起凭借深度学习、机器学习以及人工智能成功预测加密货币的价格,我觉得自己还算是个老司机。
一开始,我认为把深度学习和加密货币结合在一起研究是个非常新颖独特的想法,但是当我在准备这篇文章时,我发现了一篇类似的文章。那篇文章只谈到比特币。我在这篇文章中还会讨论到以太币(它还有一些别名:ether、eth或者lambo-money)。
类似文章链接:
http://www.jakob-aungiers.com/articles/a/Multidimensional-LSTM-Networks-to-Predict-Bitcoin-Price
我们将使用一个长短时记忆(LSTM)模型,它是深度学习中一个非常适合分析时间序列数据的特定模型(或者任何时间/空间/结构序列数据,例如电影、语句等)。
如果你真的想了解其中的基础理论,那么我推荐你阅读这三篇文章:《理解LSTM网络》、《探究LSTM》、原始白皮书。出于私心,我主要是想吸引更多的非专业机器学习爱好者,所以我会尽量减少代码的篇幅。如果你想自己使用这些数据或者建立自己的模型,本篇文章同样提供了Jupyter (Python) 笔记供参考。那么,我们开始吧!
![]() 理解LSTM网络
理解LSTM网络
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
![]() 探究LSTM
探究LSTM
http://blog.echen.me/2017/05/30/exploring-lstms/
![]() 原始白皮书
原始白皮书
http://www.bioinf.jku.at/publications/older/2604.pdf
Jupyter (Python) 笔记 https://raw.githubusercontent.com/dashee87/blogScripts/master/Jupyter/2017-11-20-predicting-cryptocurrency-prices-with-deep-learning.ipynb数据
在建立模型之前,我们需要获取相应的数据。在Kaggle上有过去几年比特币详细到每分钟的价格数据(以及其他一些相关的特征,可以在另外一篇博客中看到)。但是如果采用这个时间颗粒度,其中的噪音可能会掩盖真正的信号,所以我们以天为颗粒度。
另外一篇博客:
http://www.jakob-aungiers.com/articles/a/Multidimensional-LSTM-Networks-to-Predict-Bitcoin-Price
但这样的话,我们会面临数据不够的问题(我们的数据量只能达到几百行,而不是上千或者上百万行)。在深度学习中,没有模型能够解决数据过少的问题。我也不想依赖于静态文件来建立模型,因为这会使未来注入新数据更新模型的流程变得很复杂。取而代之,我们来试试从网站和API上爬取数据。
因为我们需要在一个模型中使用多种加密货币,也许从同一个数据源中爬取数据是个不错方法。我们将使用网站coinmarketcap.com。
截至目前,我们只考虑比特币和以太币,但是用同样的渠道获取最近火爆的Altcoin相关数据也不难。在我们导入数据之前,我们必须载入一些python包,它们会让分析过程便捷很多。
import pandas as pd
import time
import seaborn as sns
import matplotlib.pyplot as plt
import datetime
import numpy as np
# get market info for bitcoin from the start of 2016 to the current day
bitcoin_market_info = pd.read_html("https://coinmarketcap.com/currencies/bitcoin/historical-data/?start=20130428&end="+time.strftime("%Y%m%d"))[0]
# convert the date string to the correct date format
bitcoin_market_info = bitcoin_market_info.assign(Date=pd.to_datetime(bitcoin_market_info['Date']))
# when Volume is equal to '-' convert it to 0
bitcoin_market_info.loc[bitcoin_market_info['Volume']=="-",'Volume']=0
# convert to int
bitcoin_market_info['Volume'] = bitcoin_market_info['Volume'].astype('int64')
# look at the first few rows
bitcoin_market_info.head()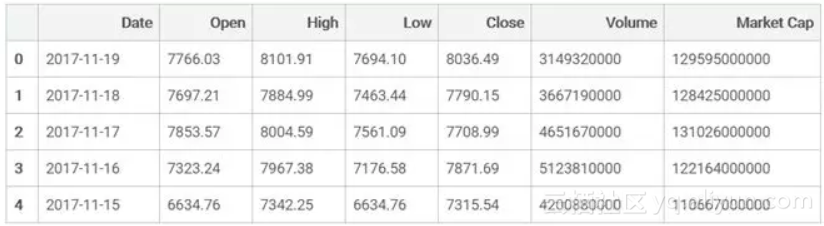
解释一下刚才发生了什么,我们加载了一些python包,并导入了在这个网站(链接见下)上看到的表格。经过简单的数据清理,我们得到了上面的这张表。通过简单地把URL地址(此处代码忽略)中的“bitcoin”换成“ethereum”,就可以相应的获得以太币的数据。
网站链接:
https://coinmarketcap.com/currencies/bitcoin/historical-data/
为了验证数据的准确性,我们可以作出两种货币的价格和成交量时间线图。
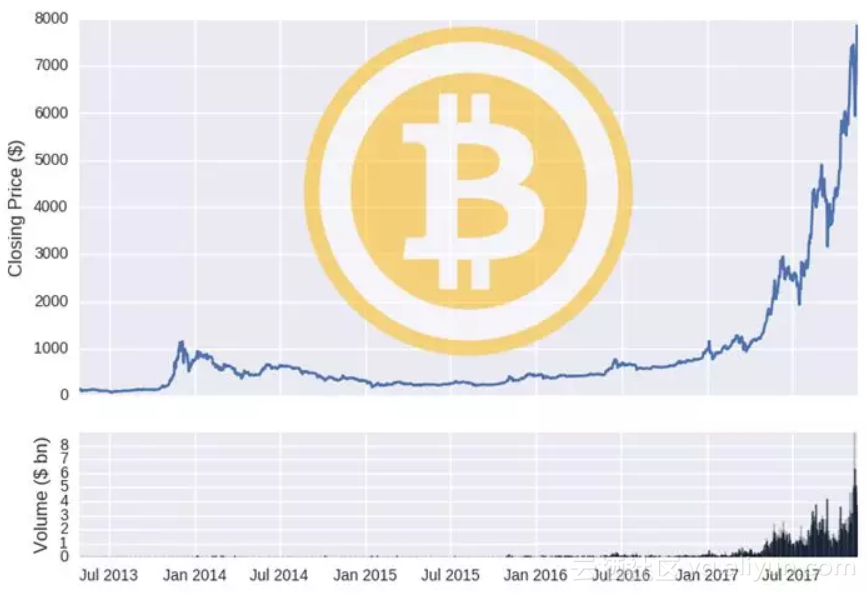
图注:上半部分-收盘价; 下半部分-成交量
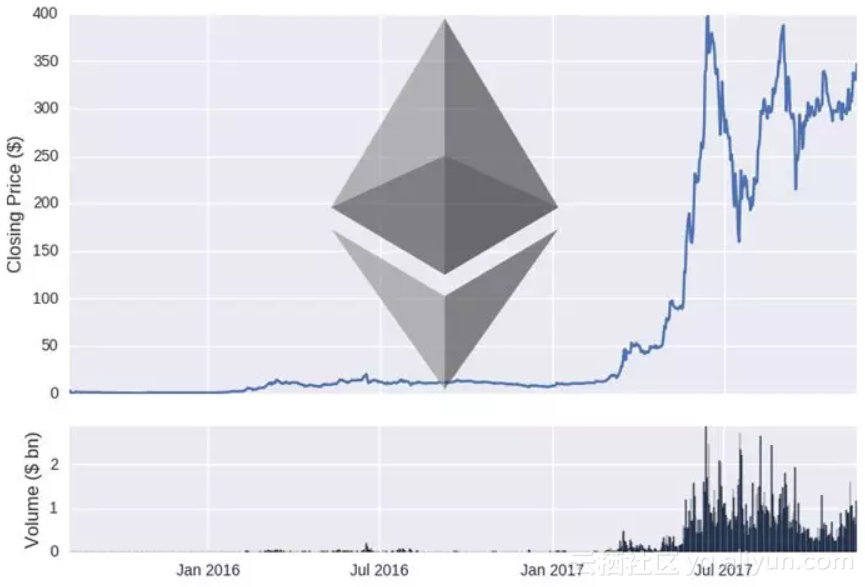
图注:上半部分-收盘价; 下半部分-成交量
训练,测试以及随机游走我们有了数据,现在可以开始创建模型了。在深度学习领域中,数据一般分为训练数据和测试数据,用训练数据集建立模型,然后用训练样本之外的测试数据集进行评估。
在时间序列模型中,一般我们用一段时间的数据训练,然后使用另一段时间的数据测试。我比较随意的把时间节点设为2017年6月1日(也就是说模型将用6月1日之前的数据训练,用其后的数据进行评估)。
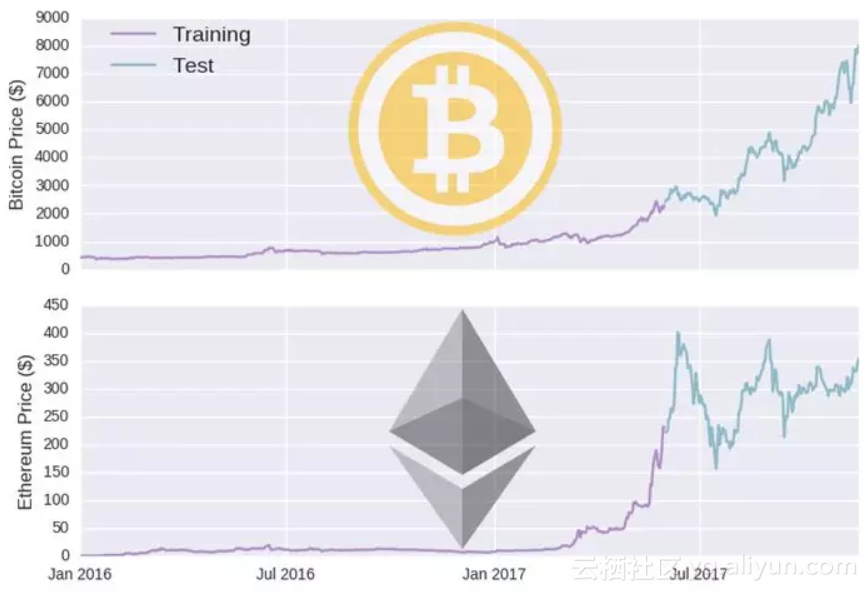
图注:紫色线-训练集; 蓝色线-测试集
上半部分-比特币价格($); 下半部分-以太币价格($)
你可以观察到,训练集的数据大多处于货币价格较低的时候,因此,训练数据的分布也许并不能很好地代表测试数据的分布,这将削弱模型推广到样本外数据的能力(你可以参照这个网站把数据变换成平稳的时间序列)。
网站链接:
https://dashee87.github.io/data%2520science/general/A-Road-Incident-Model-Analysis/
但是为什么要让不如人意的现实干扰我们的分析呢?在我们带着深度人工智能机器模型起飞前,讨论一个更简单的模型是很有必要的。最简单的模型就是假设明天的价格相等于今天的价格,我们简单粗暴地称之为递延模型。下面我们用数学语言来定义这个模型:
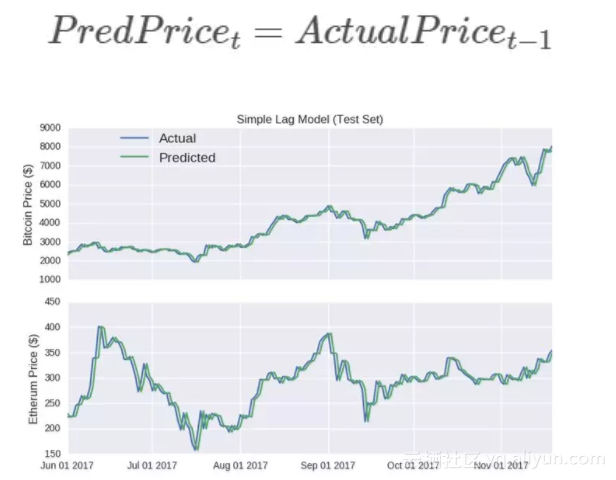
图:简单递延模型
上半部分-比特币价格($); 下半部分-以太币价格($)
稍稍拓展一下这个简单的模型,一般人们认为股票的价格是随机漫步的,用数学模型表示为:
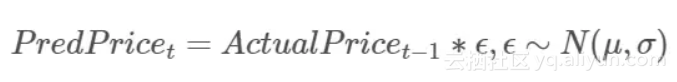
我们将从训练数据集中获取μ和σ的取值,然后在比特币和以太币的测试数据集上应用随机漫步模型。
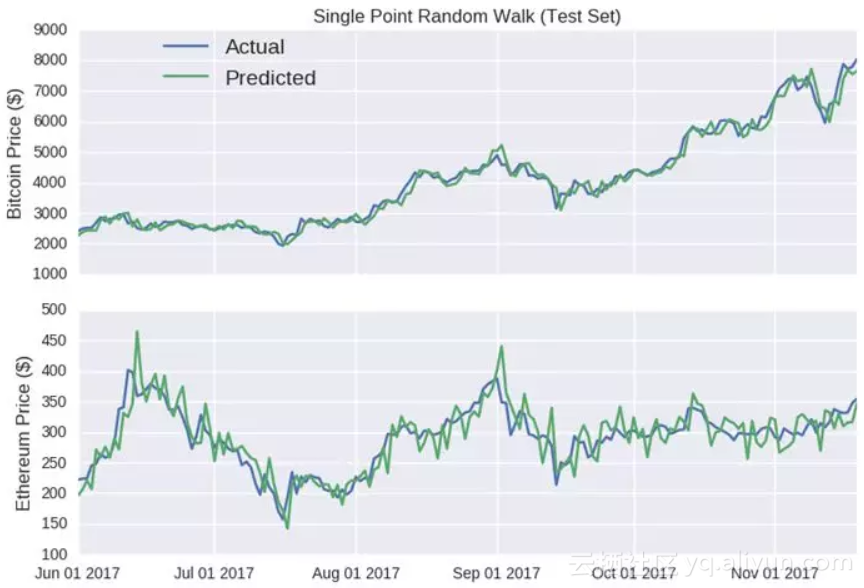
图:单点随机游走模型(测试数据)
上半部分-比特币价格($); 下半部分-以太币价格($)
哈哈,看看这些预测线,除了一些弯折,它基本追随了每个货币的实际收盘价格,它甚至预测了以太币在六月中旬及八月下旬的涨势(以及随后的跌势)。
那些仅仅只预测未来某个点的模型展现出来的准确性都很误导人,因为误差并不会延续到后续的预测中。无论上一个值有多大的误差,由于每个时间点的输入都是真实值,误差都会被重置。
比特币随机漫步模型尤其具有欺骗性,因为y轴的范围很大,让这个预测曲线看上去非常平滑。
不幸的是,单点预测在时间序列模型的评估中十分常见(比如文章一、文章二)。更好的做法是用多点预测来评估它的准确性,用这种方法,之前的误差不会被重置,而是被纳入之后的预测中。越是预测能力差的模型受到的限制也越严重。数学模型如下:
![]() 文章一链接:
文章一链接:
https://medium.com/@binsumi/neural-networks-and-bitcoin-d452bfd7757e
![]() 文章二链接:
文章二链接:
https://blog.statsbot.co/time-series-prediction-using-recurrent-neural-networks-lstms-807fa6ca7f
我们基于所有的测试数据集得到了随机漫步模型,并对收盘价格进行了预测。
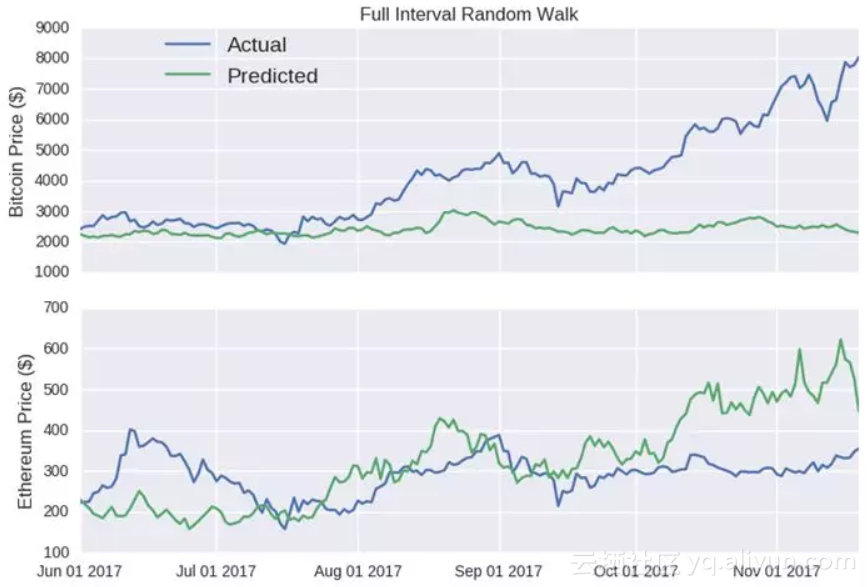
图:完全区间随机模型
上半部分-比特币价格($); 下半部分-以太币价格($)
模型预测对随机种子的选取极度敏感,我已经选择了一个预测以太币结果较好的完全区间随机漫步模型。在相应的Jupyter笔记中,你可以通过交互界面尝试下面动图中的种子值,看看随机漫步模型表现差的情况。
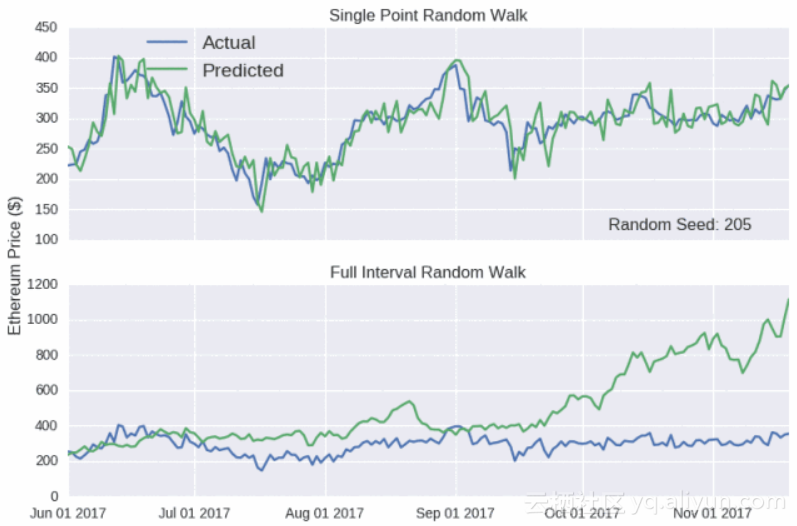
图:单点漫步模型/完全区间随机模型对比
纵坐标-以太币价格($)
需要注意的是,单点随机漫步总是看上去非常准确,即使其背后没有任何含义。希望你能够带着怀疑的眼光看任何宣称能够准确预测价格的文章。但也许我不需要担心,加密货币的爱好者们似乎并不会被虚有其表的广告语所诱惑。
长短期记忆(LSTM)
就像我之前所说的,如果你对LSTM的原理感兴趣,可以阅读:《理解LSTM网络》、《探究LSTM》、原始白皮书。(链接见上文)
幸运的是,我们不需要从头开始建立网络(甚至不需要理解它),我们可以运用一些包含多种深度学习算法标准实现的函数包(例如TensorFlow、 Keras,、PyTorch等等)。我将采用Keras,因为我发现对于非专业的爱好者来说,它是最直观的。如果你对Keras不熟悉,那么可以看看我之前推出的教程。
![]() TensorFlow
TensorFlow
https://www.tensorflow.org/get_started/get_started
![]() Keras
Keras
https://keras.io/#keras-the-python-deep-learning-library
![]() PyTorch
PyTorch
http://pytorch.org/
![]() 之前的教程
之前的教程
https://dashee87.github.io/data%2520science/deep%2520learning/python/another-keras-tutorial-for-neural-network-beginners/
model_data.head()
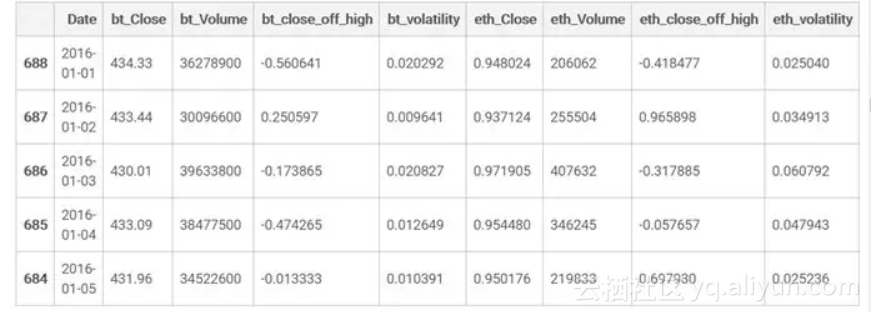
我建好了一个新数据表格model_data,移除了部分列(开盘价,当日的价最高价、当日最低价),重新安排了新的列:close_off_high代表当天收盘价格和最高价格的差值,-1和1的值分别代表收盘价格与每日最低或者最高价格相等。
volatility列就是最高价和最低价的差值除以开盘价。你可能还会注意到model_data数据集是按照时间由古至今排列的。实际上模型输入不包括Date,所以我们不再需要这一列了。
我们的LSTM模型将会使用以往数据(比特币和以太币均有)来预测某一特定货币第二天的收盘价格。我们需要决定在模型中使用以往多少天的数据。
同样的,我又随意地决定选择使用之前10天的数据,因为10是一个很好的整数。我们用连续10天的数据(称之为窗口)建立了多个小数据表格,第一个窗口将由训练数据集中的第0-9行组成(Python从0开始计数),下一个窗口由1-10行组成,以此类推。
选择较小的窗口规模意味着我们能在模型中使用更多的窗口,不利之处在于这个模型没有充足的信息以预测复杂长期行为(如果能够预测的话)。
深度学习并不喜欢变化范围大的输入值。观察一下这些列,有些值在-1到1之间,其他的值则达到了上百万。我们需要进行数据标准化,保证我们的输入值的变化范围是一致的。
一般-1到1的值是最理想的,off_high列和 volatility列的值是符合要求的,但是对于其他的列,我们需要把输入值按照窗口的第一行值进行标准化。
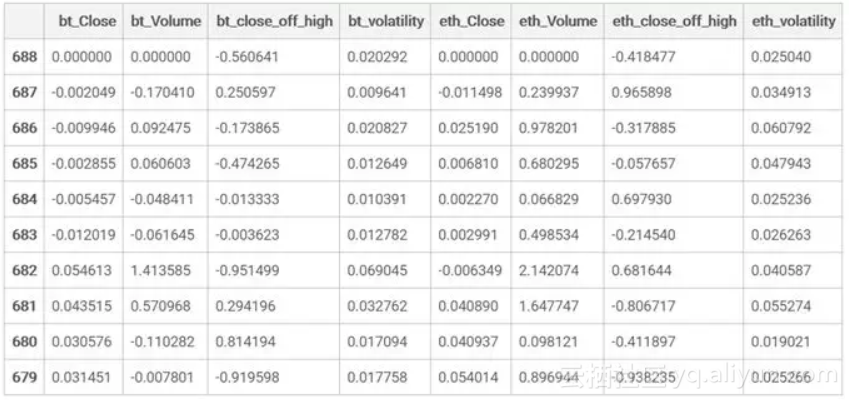
表格展示了LSTM模型的输入的一部分(实际上会有几百个相似的表格)。我们对一些列进行了标准化处理,使它们在第一个时间点的值为0,以便预测相较此时间点而言价格的变动。
现在我们准备构建LSTM模型,实际上使用Keras来构建会非常简单,你只需将几个模块堆叠在一起。
更好的解释请戳这里:
https://dashee87.github.io/data%2520science/deep%2520learning/python/another-keras-tutorial-for-neural-network-beginners/
代码如下:
# import the relevant Keras modules
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras.layers import LSTM
from keras.layers import Dropout
def build_model(inputs, output_size, neurons, activ_func = "linear",
dropout =0.25, loss="mae", optimizer="adam"):
model = Sequential()
model.add(LSTM(neurons, input_shape=(inputs.shape[1], inputs.shape[2])))
model.add(Dropout(dropout))
model.add(Dense(units=output_size))
model.add(Activation(activ_func))
model.compile(loss=loss, optimizer=optimizer)
return model不出所料,build_model 函数建立了一个空模型,名字为model(即这行代码model= Sequential),LSTM层已加在模型中,大小与输入相匹配(n * m的表格,n和m分别代表时间点/行和列)。
函数也包含了更通用的神经网络特征,例如 dropout和activation functions。现在我们只需确定放置到LSTM层中的神经元个数(我选择了20个以便保证合理的运行时间)和创建模型的训练数据。
代码如下:
# random seed for reproducibility
np.random.seed(202)
# initialise model architecture
eth_model = build_model(LSTM_training_inputs, output_size=1, neurons = 20)
# model output is next price normalised to 10th previous closing price
LSTM_training_outputs = (training_set['eth_Close'][window_len:].values/training_set['eth_Close'][:-window_len].values)-1
# train model on data
# note: eth_history contains information on the training error per epoch
eth_history = eth_model.fit(LSTM_training_inputs, LSTM_training_outputs,
epochs=50, batch_size=1, verbose=2, shuffle=True)
#eth_preds = np.loadtxt('eth_preds.txt')
结果:
Epoch 50/50
6s - loss: 0.0625我们建好了一个LSTM模型,可以预测以太币明日的收盘价。让我们来看看模型表现如何。首先检验模型在训练集上的表现情况(2017年6月前的数据)。代码下面的数字是对训练集进行50次训练迭代(或周期)后,模型的平均绝对误差(mae)。我们可将模型的输出结果视为每日的收盘价,而不是相对的变化。
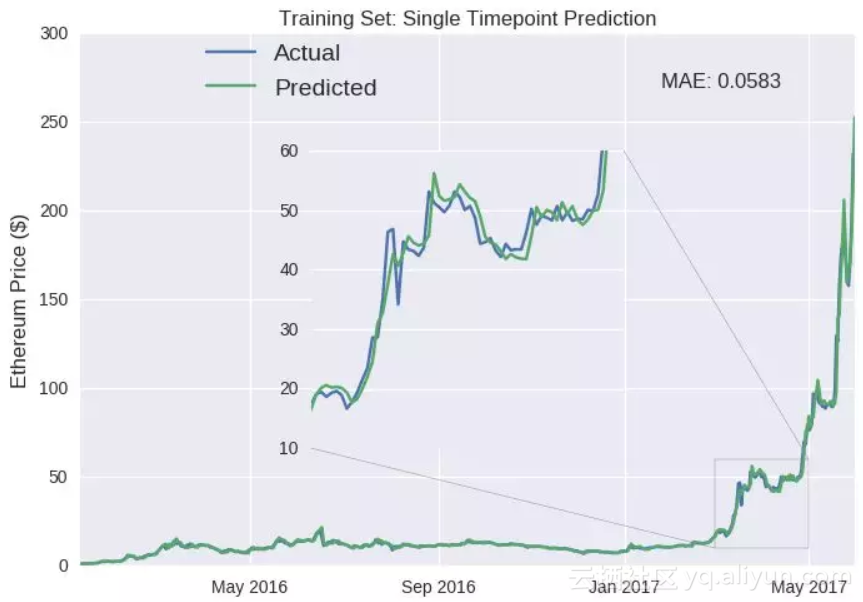
训练集:单时间点预测
蓝色线-实际价格;绿色线-预测价格
纵坐标:以太币价格($)
平均绝对误差:0.0583
正如我们所期待的,准确性看起来很高。训练过程中,模型可以了解其误差来源并相应地做出调整。
实际上,训练误差达到几乎为零不会很难,我们只需用上几百个神经元并且训练数千个周期(这就是过度拟合,实际上是在预测噪音,我在build_model 函数中加入了Dropout() , 可以为我们相对小的模型降低过度拟合的风险)。
我们应该更关注模型在测试集上的表现,因为可以看到模型处理全新数据的表现。
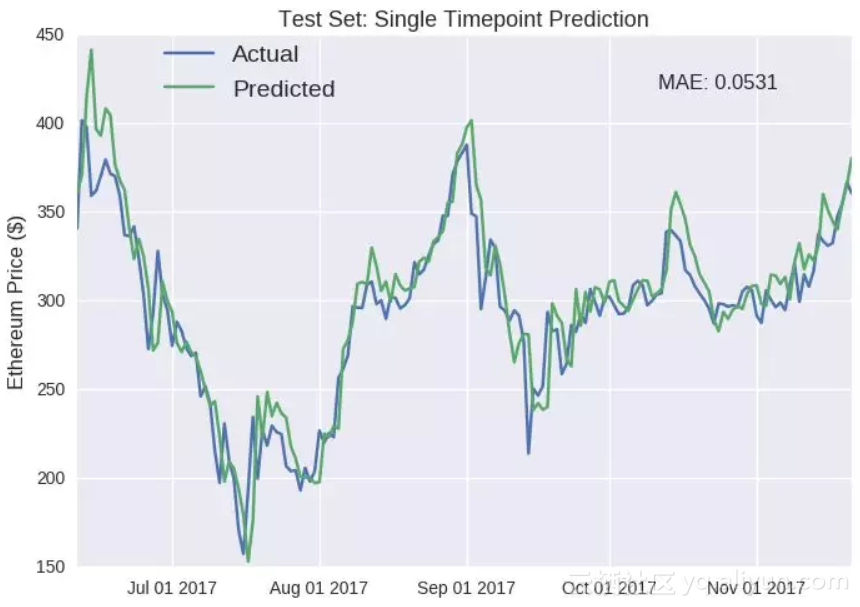
测试集:单时间点预测
蓝色线-实际价格;绿色线-预测价格
纵坐标:以太币价格($)
平均绝对误差:0.0531
撇开单点预测误导性的局限,LSTM模型似乎在测试集中表现良好。但它最明显的缺陷是以太币的价格在暴增后(例如六月中旬和十月)不可避免的下降,模型无法探测出来。
实际上这个问题一直存在,只是在这些剧烈变化的时间点更加明显。预测价格曲线几乎是实际价格曲线向未来平移一天的结果(例如七月中旬的下跌)。此外,模型似乎整体高估了以太币的未来价值(我们也是~),预测曲线总是高于实际曲线。
我怀疑这是由于训练集所属的时间范围内,以太币的价格以天文数字增长,因此模型推断这种趋势仍会持续(我们也是~)。我们也建立了一个相似的LSTM模型用来预测比特币,测试集的预测图如
完整代码的Jupyter notebook链接:
https://github.com/dashee87/blogScripts/blob/master/Jupyter/2017-11-20-predicting-cryptocurrency-prices-with-deep-learning.ipynb
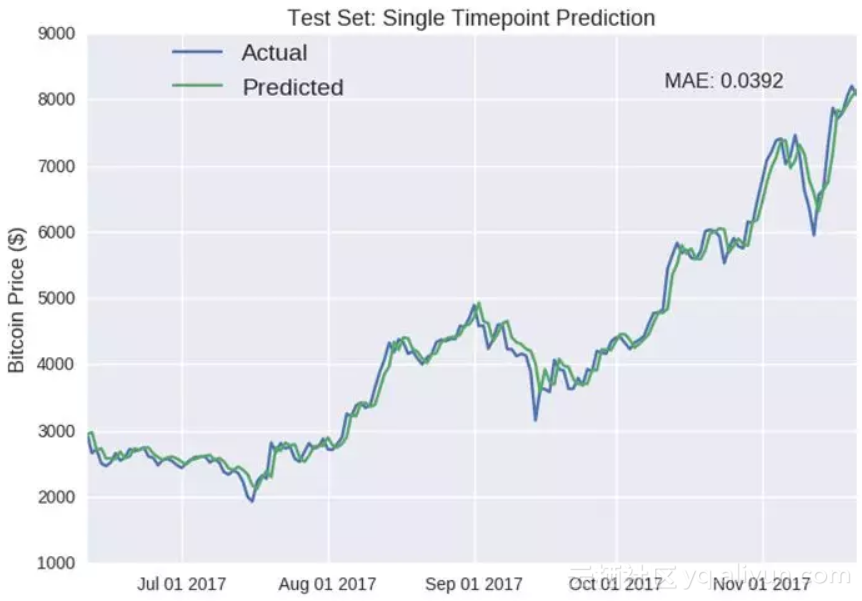
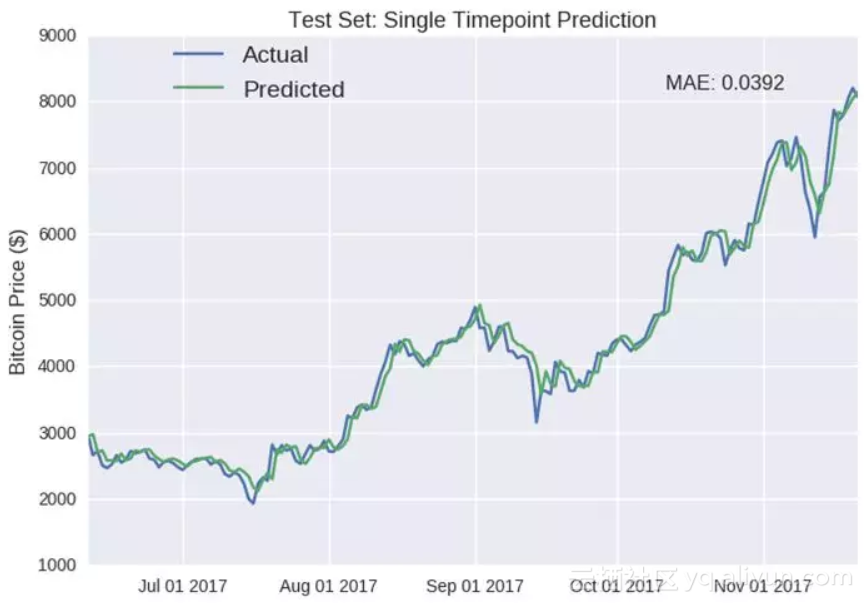
测试集:单时间点预测
蓝色线-实际价格;绿色线-预测价格
纵坐标:比特币价格($)
平均绝对误差:0.0392
正如我之前所说的,单点预测会有欺骗作用。如果仔细观察你会注意到,预测值通常会反映出先前的值(例如十月)。深度学习模型LSTM已经部分推导出了p元自回归模型(autoregression model,AR),未来的值仅仅是先前p个值的加权和。AR模型的数学公式如下:
![]()
好的方面是,AR模型常运用于时间序列中 ,因此LSTM模型似乎有了合理的用武之地。坏消息是,这是对LSTM能力的浪费,我们可以建立更加简单的AR模型,花费时间更少,可能会得到相似的结果。
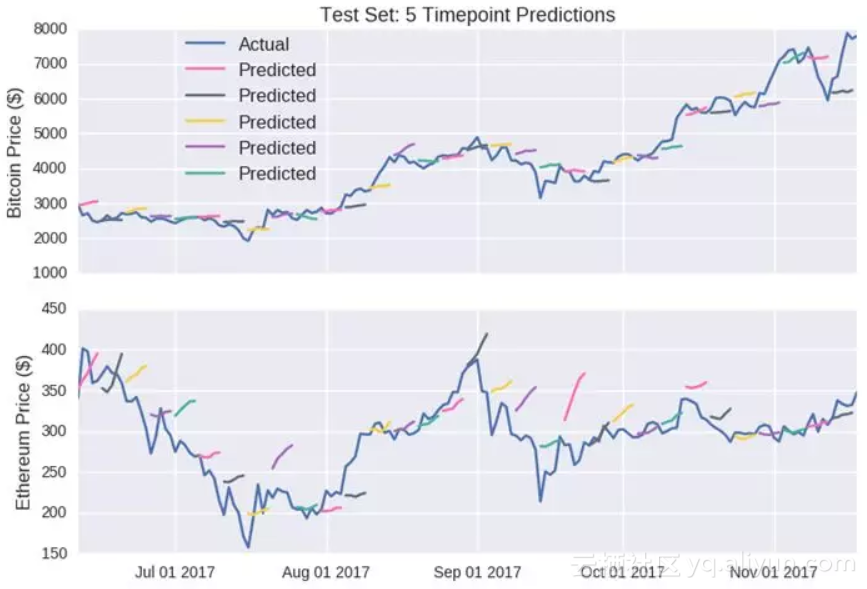
测试集:5个时间点的预测
蓝色连续线:实际价格
其他颜色线:预测价格
上半部分:比特币价格($);下半部分:以太币价格($)
这个预测结果显然没有单点预测的结果吸引眼球。然而,我很开心这个模型输出有些微妙的状况(例如以太币的第二条线);它并没有简单的预测价格会朝着一个方向统一移动,这是个好现象。
回过头来看一下单点预测,深度机器人工神经模型运行的还可以,但随机漫步模型也不差。和随机漫步模型一样,LSTM模型对随机种子的选择也很敏感(模型的权重最初是随机分配的)。
因此,如果我们想去比较这两个模型,就需要多次运行(大约25次)之后获取模型误差的估计值,测试集中实际和预测的收盘价之间差值的绝对值记为误差。
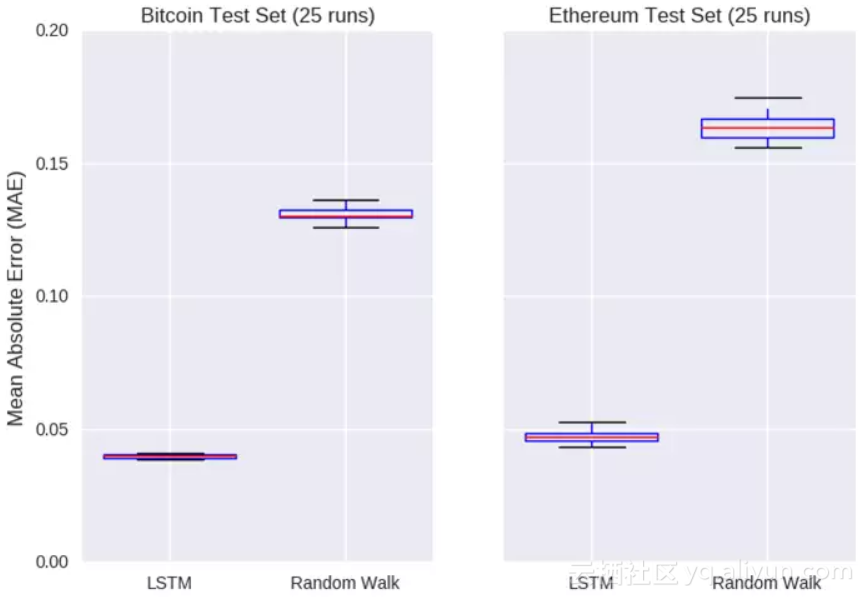
左图:比特币测试集(运行25次)纵坐标:平均绝对误差横坐标:LSTM模型,随机游走模型
右图:以太币测试集(运行25次)纵坐标:平均绝对误差横坐标:LSTM模型,随机游走模型
也许AI还是值得广而告之的,上图显示了对每个模型进行25次初始化后测试集的误差。LSTM模型在比特币和以太币上价格的平均误差分别是0.04和0.05,这个结果完胜随机漫步模型。
战胜随机漫步模型是很低的标准,将LSTM与更合适的时间序列模型做比较会更有趣(比如加权平均,AR,ARIMA 或Facebook的 Prophet algorithm)。另一方面,我相信改进LSTM模型并不难(尝试加入更多层和/或神经元,改变批次的大小,学习率等)。
也就是说,希望你已经发现了我对应用深度学习预测加密货币的价格变化的疑虑。这是因为我们忽视了最好的框架:人类智能。显然,预测加密货币的完美模型*应是:
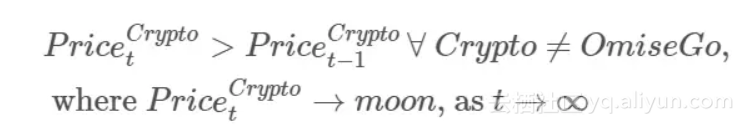
(译者注:如果在时过境迁之后,加密货币的价格接近月球的高度,那么所有不在OmiseGo区块链中的加密货币会一直升值)
*本篇文章不涉及财务建议,也不应该做财务建议使用。尽管加密货币的投资在长时间的范围看肯定会增值,但它们也可能会贬值。
总结
我们收集了一些加密货币数据,并将其输入到酷炫的深度智能机器学习LSTM模型中,不幸的是,预测值与先前的输入值并无太大差别。那么问题来了,如何使模型学习更复杂的行为?
获取更多且/或更好的数据:如果过去的价格已经足以预测较为准确的未来价格,那么我们需要引入其他具有相当预测能力的特征。这样LSTM模型不会过度依赖过去的价格,也
如果以上是积极的一面,那接下来的负面消息是,有可能加密货币的价格变化模式根本找不出来;没有任何模型(无论多么深)可以将信号与噪音分开(这与利用深度学习预测地震类似),即使出现了某种模式也会很快消失 。
想想看2016年和2017年末狂热的比特币差别多么大,任何建立在2016年数据的模型肯定难以复刻2017年空前的变化。以上讨论就是在建议你,不妨节省些时间,还是坚持研究AR模型吧。
但我相信他们最终会为深度学习找到用武之地,与此同时,你可以通过下载 Python 代码建立自己的LSTM模型。
原文发布时间为:2018-03-14
本文作者:文摘菌