1 基本术语
- 有向图:图中的每条边都有方向的图叫有向图。此时,边的两个顶点有次序关系,有向边<u,v>成为从顶点u到顶点v的一条弧,u成为弧尾(始点),v成为弧头(终点),即有向图中弧<u,v>和弧<v,u>表示不同的两条边。
- 无向图:图中的每条边没有方向的图。边的两个顶点没有次序关系,无向图用边(u,v)表示对称弧<u,v>和<v,u>。
- 权:图中的边或弧上有附加的数量信息,这种可反映边或弧的某种特征的数据成为权。
- 网:图上的边或弧带权则称为网。可分为有向网和无向网。
- 邻接和关联:若边e=(u,v)或弧e=<u,v>,则称点u和v互为邻接顶点,并称边e或弧e关联于顶点u和v。
- 度:在无向图中,与顶点v关联的边的条数成为顶点v的度。有向图中,则以顶点v为弧尾的弧的条数成为顶点v的出度,以顶点v为弧头的弧的条数成为顶点v的入度,而顶点v的度=出度+入度。图中各点度数之和是边(或弧)的条数的2倍。
- 圈:图中联接同一个顶点的边叫圈。
- 平行边:图中两个顶点之间若有两条或两条以上的边,称这些边为平行边。
- 简单图:没有圈也没有平行边的图。
- 有向完全图:有n个顶点,n(n-1)条弧的有向图。每两个顶点之间都有两条方向相反的边连接的图。
- 完全图:有n个顶点,n(n-1)/2条边的无向图。若一个图的每一对不同顶点恰有一条边相连,则称为完全图。完全图是每对顶点之间都恰连有一条边的简单图。
- 路径长度:路径上边或弧的数目。若路径上的各顶点均不相同,则称这条路经为简单路经(或路),除第一个和最后一个顶点相同外,其他各顶点均不相同的路径成为回路(或环)。
- 连通图:在无向图G中,对与图中的任意两个顶点u、v都是连通的,则称图G为连通图。
- 强连通图:在有向图G中,如果对于每一对Vi和Vj 属于顶点集V,Vi不等于Vj ,从Vi到Vj和从Vj到Vi都存在路径,则称G是强连通图。
- 强连通分量:有向图中的极大强连通子图称做有向图的强连通分量。
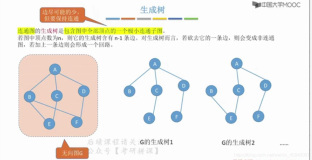
- 生成树:一个连通图的生成树是一个极小的连通子图,它含有图中全部的n个顶点,但只有足以构成一棵树的n-1条边。
- 有向树:如果一个有向图恰有一个顶点的入度为0,其余顶点的入度为1,则是一棵有向树。
2 图的存储结构
2.1 邻接矩阵表示法
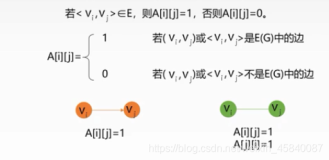
图的邻接矩阵存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中的边或弧的信息。
设图G有n个顶点,则邻接矩阵是一个n*n的方阵,定义为:
![]()
看一个实例,下图左就是一个无向图。

从上面可以看出,无向图的边数组是一个对称矩阵。所谓对称矩阵就是n阶矩阵的元满足aij = aji。即从矩阵的左上角到右下角的主对角线为轴,右上角的元和左下角相对应的元全都是相等的。
从这个矩阵中,很容易知道图中的信息。
(1)要判断任意两顶点是否有边无边就很容易了;
(2)要知道某个顶点的度,其实就是这个顶点vi在邻接矩阵中第i行或(第i列)的元素之和;
(3)求顶点vi的所有邻接点就是将矩阵中第i行元素扫描一遍,arc[i][j]为1就是邻接点;
而有向图讲究入度和出度,顶点vi的入度为1,正好是第i列各数之和。顶点vi的出度为2,即第i行的各数之和。
若图G是网图,有n个顶点,则邻接矩阵是一个n*n的方阵,定义为:

这里的wij表示(vi,vj)上的权值。无穷大表示一个计算机允许的、大于所有边上权值的值,也就是一个不可能的极限值。下面左图就是一个有向网图,右图就是它的邻接矩阵。

2.2 邻接表表示法
邻接矩阵是不错的一种图存储结构,但是,对于边数相对顶点较少的图,这种结构存在对存储空间的极大浪费。因此,找到一种数组与链表相结合的存储方法称为邻接表。
邻接表的处理方法是这样的:
(1)图中顶点用一个一维数组存储,当然,顶点也可以用单链表来存储,不过,数组可以较容易的读取顶点的信息,更加方便。
(2)图中每个顶点vi的所有邻接点构成一个线性表,由于邻接点的个数不定,所以,用单链表存储,无向图称为顶点vi的边表,有向图则称为顶点vi作为弧尾的出边表。
例如,下图就是一个无向图的邻接表的结构。

从图中可以看出,顶点表的各个结点由data和firstedge两个域表示,data是数据域,存储顶点的信息,firstedge是指针域,指向边表的第一个结点,即此顶点的第一个邻接点。边表结点由adjvex和next两个域组成。adjvex是邻接点域,存储某顶点的邻接点在顶点表中的下标,next则存储指向边表中下一个结点的指针。
对于带权值的网图,可以在边表结点定义中再增加一个weight的数据域,存储权值信息即可。如下图所示。

- 若无向图(或网)中有n个顶点、e条边,则它的邻接表需n个头结点和2e个表结点。对于稀疏图而言,用邻接表表示法比邻接矩阵表示法节省存储空间。临街表中顶点vi的度恰为第i个链表中的结点数。
- 若有向图(或网)中有n个顶点、e条弧,则它的邻接表需n个头结点和e个表结点。顶点vi的出度为第i个链表中的结点数,但要计算这个顶点的入度则需遍历所有邻接表。
- 有时为了方便求一个顶点的入度,或者如果需要反复访问一个结点的直接前驱,可以建立一个有向图(或网)的逆邻接表,即对每个顶点vi建立一个链表,用以链接以顶点vi为头的弧。
2.3 邻接多重表表示法
2.4 十字链表表示法
对于有向图来说,邻接表是有缺陷的。关心了出度问题,想了解入度就必须要遍历整个图才知道,反之,逆邻接表解决了入度却不了解出度情况。下面介绍的这种有向图的存储方法:十字链表,就是把邻接表和逆邻接表结合起来的。
重新定义顶点表结点结构,如下所示。
![]()
其中firstin表示入边表头指针,指向该顶点的入边表中第一个结点,firstout表示出边表头指针,指向该顶点的出边表中的第一个结点。
重新定义边表结构,如下所示。
![]()
其中,tailvex是指弧起点在顶点表的下表,headvex是指弧终点在顶点表的下标,headlink是指入边表指针域,指向终点相同的下一条边,taillink是指边表指针域,指向起点相同的下一条边。如果是网,还可以增加一个weight域来存储权值。
比如下图,顶点依然是存入一个一维数组,实线箭头指针的图示完全与邻接表相同。就以顶点v0来说,firstout指向的是出边表中的第一个结点v3。所以,v0边表结点hearvex = 3,而tailvex其实就是当前顶点v0的下标0,由于v0只有一个出边顶点,所有headlink和taillink都是空的。

重点需要解释虚线箭头的含义。它其实就是此图的逆邻接表的表示。对于v0来说,它有两个顶点v1和v2的入边。因此的firstin指向顶点v1的边表结点中headvex为0的结点,如上图圆圈1。接着由入边结点的headlink指向下一个入边顶点v2,如上图圆圈2。对于顶点v1,它有一个入边顶点v2,所以它的firstin指向顶点v2的边表结点中headvex为1的结点,如上图圆圈3。
十字链表的好处就是因为把邻接表和逆邻接表整合在一起,这样既容易找到以v为尾的弧,也容易找到以v为头的弧,因而比较容易求得顶点的出度和入度。
而且除了结构复杂一点外,其实创建图算法的时间复杂度是和邻接表相同的,因此,在有向图应用中,十字链表是非常好的数据结构模型。
3 图的邻接表表示法实现
#ifndef _ALGRAPH_H_
#define _ALGRAPH_H_
#include <Windows.h>
#define MAX_VERTEX_NUM 20
enum GraphStyle
{
DG, //有向图
DN, //有向网
UDG, //无向图
UDN //无向网
};
class EdgeNode
{
EdgeNode(int = -1, int = 0);
int adjVertex;
int weight;
EdgeNode* next;
};
EdgeNode::EdgeNode(int a, int w):adjVertex(a),weight(w),next(NULL)
{
}
template<class T> class VertexNode
{
public:
void ClearEdgeList(); //删除该点的邻接表
bool AppendEdge(int, int = 0);
bool RemoveEdge(int);
T data;
EdgeNode* edgeList; //指向第一条依附于该顶点的边的指针
};
template<class T> void VertexNode<T>::ClearEdgeList()
{
EdgeNode *p,*q;
p = edgeList;
while(p != NULL)
{
q = p->next;
delete p;
p = q;
}
edgeList = NULL;
}
template<class T> bool VertexNode<T>::AppendEdge(int v, int wgh)
{
EdgeNode* p = edgeList;
EdgeNode* q = NULL;
while (p != NULL)
{
if (p->adjVertex == v)
{
return false;
}
q = p;
p = p->next;
}
p = new EdgeNode(v,wgh);
if (q == NULL)
{
edgeList = p;
}
else
{
q->next = p;
}
return true;
}
template<class T> bool VertexNode<T>::RemoveEdge(int v)
{
ASSERT(edgeList);
EdgeNode* p = edgeList;
EdgeNode* q = NULL;
while(p != NULL)
{
if (p->adjVertex == v)
{
if (p == edgeList)
{
edgeList = p->next;
}
else
{
q->next = p->next;
}
delete p;
return true;
}
q = p;
p = p->next;
}
return false;
}
template<class T> class ALGraph
{
public:
ALGraph(int = 0, GraphStyle = UDG);
~ALGraph();
int LocateVertex(const T&);
inline int GetNumVertices(){return numVertices;}
bool GetVertex(int, T&);
bool SetVertex(int, const T&);
bool InsertVertex(const T&);
bool DeleteVertex(const T&);
bool InsertEdge(const T&,const T&,int = 0);
bool DeleteEdge(const T&,const T&);
int GetFirstAdjVex(int);
int GetNextAdjVex(int v, int w);
bool GetEdge(int, int, EdgeNode*&);
inline int GetNumEdges();
void DFSTraverse(void (*Visit)(const T&));
void BFSTraverse(void (*Visit)(const T&));
private:
void DFS(void (*Visit)(const T&),int); //深度优先遍历
VertexNode<T>* vertices;
int numVertices;
int numEdges;
int maxVertices;
GraphStyle style;
bool *visited;
};
template<class T> bool ALGraph<T>::GetVertex(int v, T& vex)
{
if (v < 0 || v >= numVertices)
{
return false;
}
vex = vertices[v].data;
return true;
}
template<class T> bool ALGraph<T>::SetVertex(int v, const T& vex)
{
if (v < 0 || v >= numVertices)
{
return false;
}
vertices[v].data = vex;
return true;
}
template<class T> ALGraph<T>::ALGraph(int s, GraphStyle gs):numVertices(0),numEdges(0),
maxVertices(s),style(s)
{
if (s > 0)
{
vertices = new VertexNode<T>[s];
}
}
template<class T> ALGraph<T>::~ALGraph()
{
for (int i = 0; i < numVertices; i++)
{
vertices[i].ClearEdgeList();
}
if (maxVertices != 0)
{
delete [] vertices;
}
}
template<class T> bool ALGraph<T>::InsertVertex(const T& vex)
{
if (numVertices >= maxVertices)
{
return false;
}
for (int i = 0; i < numVertices; i++)
{
if (vertices[i].data == vex)
{
return false;
}
}
vertices[numVertices].data = vex;
vertices[numVertices++].edgeList = NULL;
return true;
}
template<class T> bool ALGraph<T>::DeleteVertex(const T& vex)
{
int i, v;
if ((v = LocateVertex(vex)) == -1)
{
return false;
}
for (int i = 0; i < numVertices; i++)
{
if (i != v)
{
if (vertices[i].RemoveEdge(v))
{
numEdges--;
}
}
}
vertices[v].ClearEdgeList();
for (i = v; i < numVertices - 1; i++)
{
vertices[i] = vertices[i + 1];
}
numVertices--;
EdgeNode* p;
for(int i = 0; i < numVertices; i++)
{
p = vertices[i].edgeList;
while(p != NULL)
{
if (p->adjVertex >= v) //判断邻接顶点号是否大于要删除的顶点号
{
p->adjVertex--;
}
p = p->next;
}
}
return true;
}
template<class T> int ALGraph<T>::LocateVertex(const T& vex)
{
for (int i = 0; i < numVertices; i++)
{
if (vertices[i].data == vex)
{
return i;
}
}
return -1;
}
template<class T> bool ALGraph<T>::InsertEdge(const T& vex1,const T& vex2,int wgh)
{
int v1 = LocateVertex(vex1);
int v2 = LocateVertex(vex2);
if (v1 = -1 || v2 == -1)
{
return false;
}
vertices[v1].AppendEdge(v2,wgh);
if (style === UDG || style == UDN)
{
vertices[v2].AppendEdge(v1,wgh);
}
numEdges++;
return true;
}
template<class T> bool ALGraph<T>::DeleteEdge(const T& vex1,const T& vex2)
{
int v1 = LocateVertex(vex1);
int v2 = LocateVertex(vex2);
if (v1 == -1 || v2 == -1)
{
return false;
}
vertices[v1].RemoveEdge(v2);
if (style == UDG || style == UDN)
{
vertices[v2].RemoveEdge(v1);
}
numEdges--;
return true;
}
template<class T> void ALGraph<T>::DFSTraverse(void (*Visit)(const T&))
{
int v;
visited = new bool[numVertices];
for (v = 0; v < numVertices; v++)
{
visited[v] = false;
}
for (v = 0; v < numVertices; v++)
{
if (!visited[v])
{
DFS(Visit,v);
}
}
delete [] visited;
}
template<class T> void ALGraph<T>::DFS(void (*Visit)(const T&), int v)
{
visited[v] = true;
Visit(vertices[v].data);
EdgeNode* p = vertices[v].edgeList;
while(p != NULL)
{
int w = p->adjVertex;
if (!visited[v])
{
DFS(Visit,w);
}
p = p->next;
}
}
template<class T> void ALGraph<T>::BFSTraverse(void (*Visit)(const T&))
{
int v;
queue<int> vertexQueue;
EdgeNode* p;
visited = new bool[numVertices];
for (v = 0; v < numVertices; v++)
{
visited[v] = false;
}
for (v = 0; v < numVertices; v++)
{
if (visited[v])
{
continue;
}
visited[v] = true;
Visit(vertices[v].data);
vertexQueue.push(v);
while (!vertexQueue.empty())
{
int u = vertexQueue.front();
vertexQueue.pop();
p = vertices[v].edgeList;
while (p != NULL)
{
int w = p->adjVertex;
if (!visited[w])
{
visited[w] = true;
Visit(vertices[w].data);
vertexQueue.push(w);
}
p = p->next;
}
}
}
delete [] visited;
}
#endif
4 图的遍历
4.1 深度优先搜索
4.2 广度优先搜索
5 求强连通分量
step2:选择具有最晚离开时间的顶点,对反图GT进行遍历,删除能够遍历到的顶点,这些顶点构成一个强连通分量。
step3:如果还有顶点没有删除,继续step2,否则算法结束。
6 最小生成树
6.1 Prim算法
2) 初始化:Vnew = {x},其中x为集合V中的任一节点(起始点),Enew = {},为空;
3) 重复下列操作,直到Vnew = V:
a 在集合E中选取权值最小的边<u, v>,其中u为集合Vnew中的元素,而v不在Vnew集合当中,并且v∈V(如果存在有多条满足前述条件即具有相同权值的边,则可任意选取其中之一);
b 将v加入集合Vnew中,将<u, v>边加入集合Enew中;
4).输出:使用集合Vnew和Enew来描述所得到的最小生成树。
#pragma region Prim算法
//返回给定数组中,非0最小元素的下标值
int Minimum(int arr[], int n)
{
int i;
int min = 0;
for (int i = 0; i < n; i++)
{
if (arr[i] > 0)
{
min = i;
break;
}
}
for (i = min; i < n; i++)
{
if (arr[i] > 0 && arr[i] < arr[min])
{
min = i;
}
}
return min;
}
//从第0个顶点出发,计算并打印网g的最小生成树
template<class T> void Prim(ALGraph<T>& g)
{
if (g.GetNumVertices() == 0)
{
cout<<"图中无顶点"<<endl;
return;
}
int i, j, k = 0;
T vex;
EdgeNode* edge = NULL;
int* lowcost = new int[g.GetNumVertices()];
T* U = new T[g.GetNumEdges()];
for (i = 0; i < g.GetNumVertices(); i++)
{
lowcost[i] = INT_MAX;
}
for (i = 0; i < g.GetNumVertices(); i++)
{
if (i != k && g.GetEdge(k,i,edge))
{
lowcost[i] = edge->weight;
g.GetVertex(k,U[i]);
}
}
g.GetVertex(k, U[k]);
lowcost[k] = 0;
for (i = 1; i < g.GetNumVertices(); i++)
{
k = Minimum(lowcost,g.GetNumVertices());
g.GetVertex(k,vex);
cout<<U[k]<<"-->"<<vex<<":"<<lowcost[k]<<endl;
lowcost[k] = 0;
for (j = 0; j < g.GetNumVertices(); j++)
{
if (g.GetEdge(k,j,edge) && edge->weight < lowcost[j]))
{
lowcost[j] = edge->weight;
g.GetVertex(k,U[j]);
}
}
}
delete [] lowcost;
delete [] U;
}
#pragma endregion
6.2 Kruskal算法
2) 新建图Graphnew,Graphnew中拥有原图中相同的e个顶点,但没有边
3) 将原图Graph中所有e个边按权值从小到大排序
4) 循环:从权值最小的边开始遍历每条边,直至图Graph中所有的节点都在同一个连通分量中
if 这条边连接的两个节点于图Graphnew中不在同一个连通分量中
添加这条边到图Graphnew中
7 拓扑排序
#pragma region 拓扑排序
//对图中的顶点求入度,存入inArr
template<class T> void FindInDegree(ALGraph<T>& g, int inArr[])
{
int i,v;
for (i = 0; i < g.GetNumVertices(); i++)
{
inArr[i] = 0;
}
for (i = 0; i < g.GetNumVertices(); i++)
{
v = g.GetFirstAdjVex(i);
while(v != -1)
{
inArr[v]++;
v = g.GetNextAdjVex(i,v);
}
}
}
template<class T> bool TopologicalSort(ALGraph<T>& g, int* topoArr)
{
queue<int> q; //存放度为0的顶点的序号
T vex;
int count = 0;
int i;
int w;
int* inDegree = new int[g.GetNumVertices()];
FindInDegree(g,inDegree);
for (i = 0; i < g.GetNumVertices(); i++)
{
if (inDegree[i] == 0)
{
q.push(i)
}
}
i = 0;
while(!q.empty())
{
topoArr[i++] = q.front();
for (w = g.GetFirstAdjVex(q.front()); w != -1;
w = g.GetNextAdjVex(q.front(),w))
{
if (--inDegree[w] == 0)
{
q.push(w);
}
}
q.pop();
count++;
}
delete [] inDegree;
return count == g.GetNumVertices();
}
#pragma endregion分析上述程序,对于有n个顶点和e条弧的有向图来说,建立各顶点的入度的时间复杂度为O(n+e),建立入度为0的顶点队列的时间复杂度为O(n)。在拓扑过程中,若有向图无环,则每个顶点入队列和出队列一次,入度减1的操作执行e此,所以拓扑排序总的时间复杂度为O(n+e)。
8 关键路径
8.1 相关概念
AOE网中, 从事件i到j的路径中,加权长度最大者称为i到j的关键路径(Critical Path),记为cp(i,j)。特别地,始点0到终点n的关键路径cp(0,n)是整个AOE的关键路径。
显然,关键路径决定着AOE网的工期,关键路径的长度就是AOE网代表的工程所需的最小工期。
2.事件最早/晚发生时间
事件vi的最早发生时间ve(i)定义为:从始点到vi的最长(加权)路径长度,即cp(0,i)
事件vi的最晚发生时间vl(i)定义为:在不拖延整个工期的条件下,vi的可能的最晚发生时间。即vl(i) = ve(n) - cp(i, n)
3.活动最早/晚开始时间
活动ak=<vi, vj>的最早开始时间e(k):等于事件vi的最早发生时间,即
e(k) = ve(i) = cp(0, i)
活动ak=<vi, vj>的最晚开始时间l(k)定义为:在不拖延整个工期的条件下,该活动的允许的最迟开始时间,即
l(k) = vl(j) – len(i, j)
这里,vl(j)是事件j的允许的最晚发生时间,len(i, j)是ak的权。
活动ak的最大可利用时间:定义为l(k)-e(k)
4. 关键活动
若 活动ak的最大可利用时间等于0(即(l(k)=e(k)),则称ak 为关键活动,否则为非关键活动。
显然,关键活动的延期,会使整个工程延期。但非关键活动不然,只要它的延期量不超过它的最大可利用时间,就不会影响整个工期。
8.2 相关算法
(2) 从源点v1出发,令ve(1)=0,求 ve(j) 2<=j<=n。
(3) 从汇点vn出发,令vl(n)=ve(n),求 vl(i) 1<=i<=n-1。
(4) 根据各顶点的ve和vl值,求每条弧s(活动)的最早开始时间e(s)和最晚开始时间l(s),其中e(s)=l(s)的为关键活动。
8.3 程序实现
template<class T> void PrintCriticalPath(ALGraph<T>& g)
{
int i, j;
T vex, start, end;
int w;
EdgeNode* edge;
int* ve;
int* vl;
int* pArr = new int[g.GetNumVertices()];
if (!TopologicalSort(g, pArr))
{
cout<<"Graph has a circle!"<<endl;
delete [] pArr;
return;
}
ve = new int[g.GetNumVertices()];
vl = new int[g.GetNumVertices()];
for (i = 0; i < g.GetNumVertices(); i++)
{
ve[i] = 0;
}
for (i = 0; i < g.GetNumVertices(); i++)
{
for (w = g.GetFirstAdjVex(pArr[i]); w != -1; w = g.GetNextAdjVex(pArr[i],w))
{
g.GetEdge(pArr[i], w, edge);
ve[w] = max(ve[w], ve[pArr[i]] + edge->weight);
}
}
for (i = 0; i < g.GetNumVertices(); i++)
{
vl[i] = ve[g.GetNumVertices()-1];
}
for (i = g.GetNumVertices() - 1; i >= 0; i--)
{
for (w = g.GetFirstAdjVex(pArr[i]); w != -1; w = g.GetNextAdjVex(pArr[i], w))
{
g.GetEdge(pArr[i], w, edge);
vl[pArr[i]] = min(vl[pArr[i]], vl[w] - edge->weight);
}
}
cout<<"| 起点 | 终点 | 最早开始时间 | 最晚开始时间 | 差值 | 备注 |"<<endl;
for (i = 0, j = 0; i < g.GetNumVertices(); i++)
{
for (w = g.GetFirstAdjVex(i); w != -1; w = g.GetNumVertices(i,w), j++)
{
g.GetEdge(i,w,edge);
g.GetVertex(i,start);
g.GetVertex(w,end);
cout<<setiosflags(ios::right)
<<setw(6)<<start
<<setw(9)<<end
<<setw(14)<<ve[i]
<<setw(19)<<vl[i]
<<setw(14)<<edge->weight
<<setw(12)<<(ve[i] == vl[w] - edge->weight ? "关键路径":"")<<endl;
}
}
delete [] ve;
delete [] vl;
delete [] pArr;
}上述程序时间复杂度为O(n+1)。
9 最短路径
9.1 单元最短路径
为了求得最短路径,荷兰籍计算机科学家Dijkstra提出一个按路径长度递增次序产生最短路径的方法,称之为Dijkstra(迪杰斯特拉算法)单源最短路径算法。
在具体实现Dijkstra算法时,可设计一个结构体TableEntry:
struct TableEntry
{
bool known;
int dist;
int preVertex;
};Dijkstra算法的具体描述:
//返回table中known为false且dist最小的元素的位置,n是table的数组程度
int SmallestUnknownDistIndex(TableEntry table[], int n)
{
int min = INT_MAX;
int i;
int index = -1;
for (i = 0; i < n; i++)
{
if (table[i].known)
{
continue;
}
if (table[i].dist < min)
{
min = table[i].dist;
index = i;
}
}
return index;
}
//用Dijkstra算法求有向图g的顶点vex到其余各顶点的最短路径。
template<class T> TableEntry* ShortestPath_DIJ(ALGraph<T>& g, T vex)
{
int i, v, w;
int start = g.LocateVertex(vex);
EdgeNode* edge;
TableEntry* table = new TableEntry[g.GetNumVertices()];
//init table
for (i = 0; i < g.GetNumVertices(); i++)
{
table[i].known = false;
table[i].dist = INT_MAX;
table[i].preVertex = -1;
}
table[start].dist = 0;
while(true)
{
v = SmallestUnknownDistIndex(table,g.GetNumVertices());
if (v == -1)
{
break;
}
table[v].known = true;
for (w = g.GetFirstAdjVex(v); w != -1; w = g.GetNumVertices(v,w))
{
if (!table[w].known)
{
g.GetEdge(v,w,edge);
if (table[v].dist + edge->weight < table[w].dist)
{
table[w].dist = table[v].dist + edge->weight;
table[w].preVertex = v;
}
}
}
}
return true;
}上述程序时间复杂度为O(n^2)。