安装ruby
首先通过 /etc/issue 命令查看当前使用centos是哪个版本:
[hadoop@hadoop03 ~]$ cat /etc/issue
由于centos版本是6.6,安装ruby时就要选择在centos 6.X环境,具体安装步骤参考如下所示即可!
yum install gcc-c++ patch readline readline-devel zlib zlib-devel libyaml-devel libffi-devel openssl-devel make bzip2 autoconf automake libtool bison iconv-devel wget tar
cd ~/
wget https://ruby.taobao.org/mirrors/ruby/ruby-2.2.3.tar.gz
tar xvf ruby-2.2.3.tar.gz
makemake install
查看验证
[root@hadoop02
~]#
ruby -v
ruby 2.2.3p173 (2015-08-18 revision 51636) [x86_64-linux]

安装fluent-plugin-sql插件(输入源)
[root@hadoop03 ~]#
gem install fluent-plugin-sql

准备MySQL表及数据
在test数据库创建一张表,建表语句如下:
其中id是主键,自增
备注:
grant ALL PRIVILEGES ON *.* to dong@"172.16.1.158" identified by "123456" WITH GRANT OPTION;
flush privileges;
use test; 进入test数据库里操作
create table test_fluent
(
id int unsigned not null auto_increment,
sex varchar(1),
name varchar(225),
primary key(id)
)engine=innodb default charset=utf8 auto_increment=1;
插入数据,插入语句如下命令:
insert into test_fluent(sex,name) values('f','dongdong');
insert into test_fluent(sex,name) values('m','heihei');
insert into test_fluent(sex,name) values('m','qingsong');
insert into test_fluent(sex,name) values('f','jiafu');
insert into test_fluent(sex,name) values('m','angrybaby');
insert into test_fluent(sex,name) values('f','jack');
insert into test_fluent(sex,name) values('f','helloword');
insert into test_fluent(sex,name) values('m','sunlongfei');
insert into test_fluent(sex,name) values('m','donglang');
insert into test_fluent(sex,name) values('f','deguang');
insert into test_fluent(sex,name) values('m','yuanijng');
insert into test_fluent(sex,name) values('f','yangqun');
由于我操作的MySQL数据库位于172.16.1.156机器上,用户名是dong,密码是123456
而我安装的fluent位于172.16.1.158机器上,不在一台机器上,如果要从158机器远程访问156机器上MySQL会受限,禁止访问。
为此,需要在156机器上执行以下命令给指定IP授权。
授权158机器上的dong用户可以远程访问156上MySQL,dong用户登录密码是123456
使刚授予权限立即生效
准备ODPS测试表
创建ODPS 表为 demo_access_log,其建表语句为:
drop table if exists demo_access_log;
create table demo_access_log(
sex string,
name string)
into 5 shards hublifecycle 7;
编辑fluent.conf配置文件
编辑fluent.conf配置文件
配置mysql输入源、ODPS输出源:
state_file /var/run/fluentd/sql_state 配置项 (path to a file to store last rows该文件默认不存在,需要提前创建好!)
state_file stores last selected rows to a file (named state_file) to not forget last row when Fluentd restarts.
[root@hadoop03 ~]# vi /etc/fluent/fluent.conf --编辑fluent.conf配置文件
<source>
@type sql
host 172.16.1.156
port 3306
database test
adapter mysql
username dong
password 123456
select_interval 10s
select_limit 10
state_file /var/run/fluentd/sql_state
<table>
table test_fluent
tag in.sql
update_column id
</table>
</source>
<match
in.**>
type aliyun_odps
aliyun_access_id UQV2yoSSWNgquhhe
aliyun_access_key bG8xSLwhmKYRmtBoE3HbhOBYXvknG6
aliyun_odps_endpoint
http://service.odps.aliyun.com/api
aliyun_odps_hub_endpoint
http://dh.odps.aliyun.com
buffer_chunk_limit 2m
buffer_queue_limit 128
flush_interval 5s
project dtstack_dev
<table
in.sql>
table demo_access_log
fields sex,name
shard_number 5
</table>
</match>
启动fluent
fluentd启动时会自动加载/etc/fluent/fluent.conf中读取fluent.conf配置文件
fluentd --启动命令
大概 5 分钟后,实时导入数据会被同步到离线表,可以使用 select count(*) from demo_access_log这样sql 语句进行验证。
如果安装Fluentd 用的是Ruby Gem,可以创建一个配置文件运行下面命令。发出一个终止信号将会重新安装配置文件。(如果修改了配置文件—fluent.conf 文件,ctrl c 终止进程,然后在配置文件下重新启动)
$ ctrl c
$ fluentd -c fluent.conf
如果有类似如下输出,就可以说明数据实时写入Datahub服务已经成功。

运行过程遇到异常及排查
(1) 异常描述:fluent.conf文件没有配置正确

异常产生原因:输入端没有配置 tag,输出端table上也没有制定对应tag。输入tag,在输出match时要能
匹配上,在输出table 要能对应上才行。
解决方法:在mysql输入源上添加上tag标签,即 tag in.sql
/usr/local/lib/ruby/gems/2.2.0/gems/activerecord- 4.2.6/lib/active_record/connection_adapters/connection_specification.rb:177:in `rescue in spec': Specified 'mysql' for database adapter, but the gem is not loaded. Add `gem 'mysql'` to your Gemfile (and ensure its version is at the minimum required by ActiveRecord). (Gem::LoadError)
[root@hadoop03 fluent]#
yum install mysql-devel
[root@hadoop03 fluent]#
gem install mysql
Building native extensions. This could take a while...
Successfully installed mysql-2.9.1
Parsing documentation for mysql-2.9.1
Installing ri documentation for mysql-2.9.1
Done installing documentation for mysql after 2 seconds
1 gem installed
连接数据库适配器路径:
mysql2_adapter.rb、mysql_adapter.rb、
postgresql_adapter.rb在
/usr/local/lib/ruby/gems/2.2.0/gems/activerecord-4.2.6/lib/active_record/connection_adapters目录下
gem安装插件时遇到异常及排查
ERROR: While executing gem ... (Gem::RemoteFetcher::FetchError)
Errno::ECONNRESET: Connection reset by peer - SSL_connect (https://api.rubygems.org/quick/Marshal.4.8/cool.io-1.4.4.gemspec.rz)

异常产生原因:
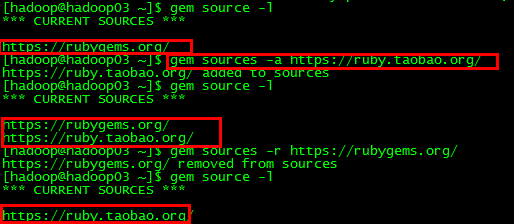
由于gem源引起,需要加上淘宝源后要把原来那个rubygems那个删掉
解决方法:
# 删除默认的官方源
gem sources -r https://rubygems.org/
# 添加淘宝源
具体解决截图展示如下:
没有写入执行权限
第二种异常
[hadoop@hadoop03 ~]$
gem install fluent-plugin-aliyun-odps
ERROR: While executing gem ... (Gem::FilePermissionError)
You don't have write permissions for the /usr/local/lib/ruby/gems/2.2.0 directory.
异常产生原因:
解决方法:
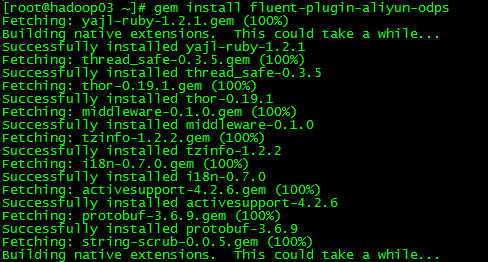
切换到root用户下进行gem install操作
具体解决截图展示如下:
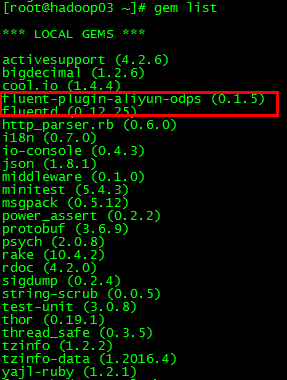
再次查看已安装插件:
