常用模块与正则表达式
1、常用模块
2、正则表达式
一、常用模块
当我们在程序开发时代码变的庞大时,使我们对代码的维护越来越困难。
我们把庞大的代码分成几个文件,这样一个文件中的代码就相对来说少点维护起来也容易点,
在python中一个.py文件就是一个模块(Module)。
模块分为三个模块:
- 自定义模块
- 内置模块
- 开源模块
几种模块导入的方式
- import time
- import time as X
- from a import func
- from a import func as b
其中import的导入方法就是建立一个到该模块应用,我们不能够直接使用该模块里面的方法,必须加上该模块名。
如:time模块中的time()方法,我们调用的方法是time.time()才行
而from time import func该方法是把time模块中的func()方法直接导入到该文件中,我们可以直接使用func调用该函数。如果该文件中有相同的函数名时,我们调用该函数时,需要看我们倒入该函数是在本文件中定义该函数名前还是定义该函数后。因为该方法导入的函数就是把别的模块中的函数中的摸个方法写到该文件中所以那个在后面我们在最后调用的时候那个函数起效果。一般我们导入都是在文件的开头所以一般起效果的函数使我们自定的的函数。我们可以这让认为我们调用该函数时在有相同函数名时那个离我们近,调用的就是那个函数。(自上而下)。
1、time和datetime模块
time
时间相关的操作,有三种表示方式:
- 时间戳 1970年1月1日之后的多少秒:time.time()
- 格式化的字符串 2017-11-11 11:11:11这样格式的时间:time.strftime("%Y-%m-%d %H:%M:%S")
- 结构化时间 返回的是一个元组,里面包含了年、月、日等: time.local()
12345678910111213141516171819202122232425262728293031
importtimeprint(time.time())#1513565782.2545097print(time.mktime(time.localtime()))#1513565782.0#上面返回的都是以时间戳方式,当地时间距离1970.1.1多少秒#知识上面2个精确度不一样print(time.altzone)#返回与utc时间的时间差以秒计算print(time.asctime())#返回"Mon Dec 18 10:59:37 2017"这样的时间格式#默认为当地时间print(time.ctime())#同上,返回的一样print(time.asctime(time.localtime()))#同上,返回的一样print(time.localtime())#返回本地的结构化时间。print(time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()))print(time.strftime("%Y-%m-%d %H:%M:%S")2017-12-1811:10:35#上面不写的话就是默认转换成当地时间的日期字符串print(time.strptime("2017/12/12","%Y/%m/%d"))#将字符串的日期改为结构化时间importdatetimeprint(datetime.datetime.now())#返回当前时间2017-12-18 11:16:18.224196print(datetime.datetime.now()+datetime.timedelta(3))#当前时间加三天print(datetime.datetime.now()+datetime.timedelta(hours=3))#当前时间加三个小时print(datetime.datetime.now()+datetime.timedelta(minutes=20))#当前时间加20分钟上面的这些不是全部的方法,只是列举了一些常用的方法。
python中时间日期格式化符号:
- %y 两位数的年份表示(00-99)
- %Y 四位数的年份表示(000-9999)
- %m 月份(01-12)
- %d 月内中的一天(0-31)
- %H 24小时制小时数(0-23)
- %I 12小时制小时数(01-12)
- %M 分钟数(00=59)
- %S 秒(00-59)
- %a 本地简化星期名称
- %A 本地完整星期名称
- %b 本地简化的月份名称
- %B 本地完整的月份名称
- %c 本地相应的日期表示和时间表示
- %j 年内的一天(001-366)
- %p 本地A.M.或P.M.的等价符
- %U 一年中的星期数(00-53)星期天为星期的开始
- %w 星期(0-6),星期天为星期的开始
- %W 一年中的星期数(00-53)星期一为星期的开始
- %x 本地相应的日期表示
- %X 本地相应的时间表示
- %Z 当前时区的名称
- %% %号本身
2、random模块
该模块是随机数模块
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import
random
print
(random.random())
#随机0-1之间的浮点数
print
(random.randint(
0
,
6
))
#随机0-6之间的整数
print
(random.randrange(
10
))
#随机0-9之间的整数
随机生成
4
位验证码(里面有数字和字母)
sec
=
""
for
i
in
range
(
4
):
j
=
random.randint(
0
,
9
)
if
j
=
=
i:
tmp
=
random.randint(
0
,
9
)
else
:
tmp
=
chr
(random.randint(
65
,
90
))
sec
+
=
str
(tmp)
print
(sec)
|
3、os模块
os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import
os,sys
# os.remove("path/filename") #删除文件
# os.rename('oldname','newname')#重命名文件
# os.getcwd()#获取当前工作位置
# os.chdir()#改变当前工作位置
# os.curdir#是一个属性,返回当前的位置:(.)
# os.pardir#是一个属性,返回当前目录的父目录位置:(..)
# os.makedirs("dir1/dir2/dir3...")#生成多级递归目录
# os.removedirs("dir1/dir2/dir3...")#最后一层目录为空测删除,递归到上一个目录,如为空就删除,以此类推
# os.mkdir('dirname')#创建单一目录
# os.rmdir('dirname')#删除单一目录
# os.listdir("dirname")#列出指定目录下的子目录和文件(包含隐藏文件)
# os.stat("path")#获取文件或者目录的信息
# os.sep #输出当前操作系统特定的路径分隔符
# os.linesep#输出当前操作系统行终止符
# os.pathsep#输出当前操作系统分隔文件的分隔符
# os.name #输出当前使用的平台
# os.system("dir")#运行shell命令
# os.environ#获取系统环境变量
# os.path.abspath("path")#返回path的绝对路径
# os.path.split("path")#返回元组,把完整的路径分隔,第一个为完整路径取出最后一个路径,第二个元素为最后一个路径
# os.path.pardir("path")#返回os.path.split("path")元组中的第一个元素
# os.path.basename("path")#返回os.path.split("path")元组中的第二个元素
# os.path.exists("path")#确认该路径是否存在
# os.path.isabs("path")#确认给出的路径是否为绝对路径
# os.path.isdir()#确认目录是否存在
# os.path.isfile()#确认文件是否存在
# os.path.join("path","path1")#将多个路径组合返回
# os.path.getatime("path")#返回path所指文件或目录最后访问时间
# os.path.getmtime("path")#返回path所指文件或目录最后修改时间
# os.path.getctime()#返回path所指文件或目录最后修改
|
4、sys模块
sys模块负责程序与python解释器的交互,提供一些列的函数和变量,用于操控python的运行时的环境
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import
sys,time
# sys.argv
# script, first, second, third = sys.argv
# 这个可以认为将sys.argv解包后的东西赋值给左边的变量
# sys.argv的第一个参数是程序的本身路径其他的是看你要解包多少个参数就写几个
# 这个程序实在我们运行程序时要输入参数
# 比如上面程序运行 python name.py firstargv secondargv thirdargv
# 在程序里面script, first, second, third = path(name.py) firstargv secondargv thirdargv
# sys.exit() #退出程序,正常退出为exit(0)
# sys.version #当前python的版本号
#sys.path #返回模块的搜索路径,初始化为python的环境变量
#sys.stdout.write()#做一个关于进度条的
# for i in range(1,101):
# sys.stdout.write("\r")
# sys.stdout.write("%s%% | %s"% (int(i%101), "#"*int(i%101)))
# sys.stdout.flush()
# time.sleep(0.5)
|
5、shutil模块
shutil模块用于高级的文件、文件夹、压缩包处理模块
shutil.copyfileobj(fsrc,fdst[,length])
将文件内容拷贝到另一个文件中,可以使部分内容
|
1
2
3
4
5
6
|
import
shutil
f
=
open
(
'zhetian.txt'
)
f2
=
open
(
'xiao.txt'
,
"w"
)
shutil.copyfileobj(f,f2)
|
shutil其他方法
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
shutil.copyfile(src,dst)
#拷贝文件,相对于shutil.copyfileobj()来说少了打开文件直接使用
shutil.copymode(src,dst)
#仅仅只拷贝文件的权限。文件的内容、组、用户都不变。
shutil.,copystat(src,dst)
#拷贝状态的信息,如:mode bits,atime,mtime,flags
shutil.copy(src,dst)
#拷贝文件和权限
shutil.copy2(src,dst)
#拷贝文件和状态信息
shutil.copytree(src, dst, symlinks
=
False
, ignore
=
None
)
#递归的去拷贝文件相当于拷贝目录及以下的文件和目录
shutil.rmtree(path[, ignore_errors[, onerror]])
#递归的去删除文件
shutil.move(src, dst)
#递归的去移动文件
shutil.make_archive(base_name,
format
,...)
#创建压缩包并返回文件路径
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:wwww
=
>保存至当前路径
如:F:\python\test\wwww
=
>保存至F:\python\test\
format
: 压缩包种类,“
zip
”, “tar”, “bztar”,“gztar”
root_dir: 要压缩的文件夹路径(默认当前目录)
owner: 用户,默认当前用户
group: 组,默认当前组
logger: 用于记录日志,通常是logging.Logger对象
实列
import
shutil
shutil.make_archive(
'wwww'
,
'gztar'
,
'F:\python\day1'
)
|
其他的压缩和解压缩
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
zipfile
import
zipfile
压缩
z
=
zipfile.ZipFile(
'test.zip'
,
'w'
)
#压缩后的名字
z.write(
'login'
)
#要压缩的文件名
z.write(
'test1'
)
#要压缩的文件名
z.close()
#想要压缩多少个就写几个
解压缩
z
=
zipfile.ZipFile(
'test.zip'
,
'r'
)
z.extractall()
z.close()
tarfile
import
tarfile
# 压缩
tar
=
tarfile.
open
(
'test.tar'
,
'w'
)
tar.add(
'F:\python\day1'
, arcname
=
'day1.zip'
)
tar.add(
'F:\python\day2'
, arcname
=
'day2.zip'
)
tar.close()
#上面可以吧要压缩的文件名字改掉arcname='newname'
# 解压
tar
=
tarfile.
open
(
'test.tar'
,
'r'
)
tar.extractall()
# 可设置解压地址
tar.close()
|
6、shelve模块
shelve模块是一个简单的key,value将内存数据通过文件持久化的模块。
shelve模块可以持久化任何pickle可支持的python数据格式
shelve就是pickle模块的封装
shelve模块可以多次dump和load
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
数据持久化:
import
shelve,datetime
bbs
=
{
'name'
:
'bob'
,
'age'
:
12
}
lis
=
[
'name'
,
'age'
,
'hobby'
]
t
=
datetime.datetime.now()
with shelve.
open
(
'shelve.txt'
) as f:
f[
'bbs'
]
=
bbs
#持久化字典
f[
'lis'
]
=
lis
#持久化列表
f[
'time'
]
=
t
#持久化时间
会生成shelve.txt.bak、shelve.txt.dat、shelve.txt.
dir
这三个文件
数据的读取
import
shelve
with shelve.
open
(
'shelve.txt'
) as f:
b
=
f.get(
'bbs'
)
l
=
f.get(
'lis'
)
t
=
f.get(
'time'
)
print
(b)
#{'name': 'bob', 'age': 12}
print
(l)
#['name', 'age', 'hobby']
print
(t)
#2017-12-19 11:42:41.157437
|
7、hashlib模块
hashlib是一个提供了一些流行的hash算法的Python标准库,其中主要提供SHA1,SHA256,SHA384,SHA512,MD5.
|
1
2
3
4
5
6
|
import
hashlib
m
=
hashlib.md5()
m.update(
"hello"
.encode())
print
(m.hexdigest())
m.update(
"你好呀"
.encode(
'utf-8'
))
#后面表明是什么编码
print
(m.hexdigest())
#这个加密的是上面的‘hello’和‘你好呀’
|
二、re正则表达式
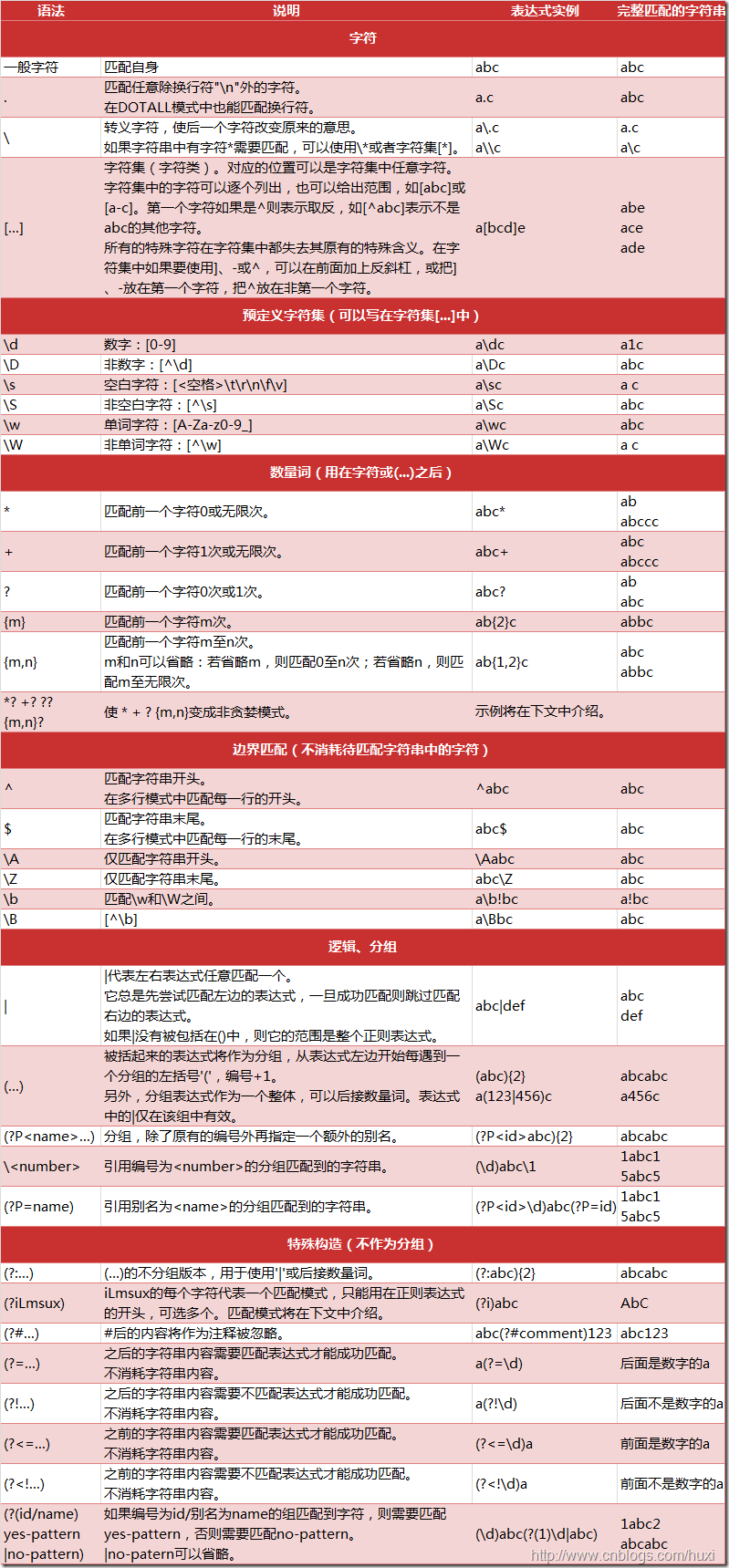
常用的正则表达式符号。
这个图是从一个不知道的大神那拷贝过来的
常用的匹配模式
- re.match(pattern,string,flags=0) 从字符串的起始位置匹配,第一个没匹配上就返回空
- re.findall(pattern,string,flags=0) 每匹配到一次当做一个元素放到列表中并返回
- re.search(pattern,string,flags=0) 扫描整个字符串,并返回第一个成功匹配
- re.finditer(pattern, string, flags=0) 找到RE匹配的所有字符串,并把他们作为一个迭代器返回
- re.split(pattern, string, maxsplit=0, flags=0) 把匹配到的字符当做分隔符,把字符串分隔开当做元素放到列表中 #re.split('[0-9]','aab2bbb4dbb') >>['aab','bbb','dbb']
- re.sub(pattern, repl, string, count=0, flags=0) 把匹配到的字符替换掉
re.I(re.IGNORECASE): 忽略大小写
re.M(MULTILINE): 多行模式,改变'^'和'$'的行为
re.S(DOTALL): 使.匹配包括换行在内的所有字符模式,改变'.'的行为
re.L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
re.X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
贪婪模式与非贪婪模式匹配
Python3默认的是贪婪模式也就是说我们'.*'这个就是匹配出换行符以外的所有字符有多少个匹配多少个如'abbbc'匹配'ab*'那么匹配到的是'abbb'
但是费贪婪模'ab*?'就是在后面多一个问号(?)匹配到的是'a',这就是非贪婪模式尽量匹配到少的。
compile()
我们有时候重复匹配同一个表达式时,那么我们可以把这个重复的正则字符串编译成正则表达式对象。也就是compile()方法
|
1
2
3
4
5
|
import
re
patt
=
re.
compile
(
'abc'
)
print
(re.search(patt,
'abcdddabckabc'
))
#运行的结果为<_sre.SRE_Match object; span=(0, 3), match='abc'>
|
match()
match()方法会尝试从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果,如果不匹配,那就返回None。
|
1
2
3
4
5
6
7
8
9
10
|
import
re
print
(re.match(
'abc'
,
'abc hello abc'
))
#'abc'在前面,所以匹配成功
print
(re.match(
'abc'
,
'hello abc'
))
#'abc'不在前面,所以匹配失败返回None
#上面的运行结果
<_sre.SRE_Match
object
; span
=
(
0
,
3
), match
=
'abc'
>
None
#因为match()方法是从字符的第一个开始匹配所以在该正则表达式不需要'^',
|
search()
re.search()扫描整个字符串,并返回第一个匹配成功。
这个这个方法还有group(),groups()等函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import
re
res
=
re.search(
'are'
,
'How are you?,how are you'
)
print
(res.group())
# 运行的结果 'are'
res2
=
re.search(
'(if).+(me)'
,r
"I'll be the one, if you want me to"
)
print
(res2.group(
1
))
#运行的结果 'if you want me'
print
(res2.groups())
#运行的结果为 ('if', 'me')
#上面可以知道group()函数返回的是匹配到的所有正则表达式
#而groups()返回的是分组中匹配到的字符并把它们当做元素放到元组中
#group()函数也能够得到分组中的字符串如:group(1)只能得到groups()结果中的第一个元素
#而group(1,2)得到的是groups结果中前面2个元素组成元组。
print
(res2.group(
1
))
#if
print
(res2.group(
1
,
2
))
#('if', 'me')
#这2个函数在findall(),finditer(),split()和sub()并没有这2个函数。
|
findall()
re.findall()扫描整个字符串每匹配到一个就把这个当做一个元素放到列表中。
|
1
2
3
4
|
import
re
print
(re.findall(
'o.?'
,r
"I'll be the one, if you want me to"
))
#['on', 'ou', 'o']
|
finditer()
re.finditer()通过正则表达式把所有匹配到的字符串,并把它们作为迭代器返回
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import
re
res
=
re.finditer(
'o.?'
,r
"I'll be the one, if you want me to"
)
print
(res)
#<callable_iterator object at 0x00000000025F5A58>
for
i
in
res:
print
(i.group())
#运行结果
# on
# ou
# o
#上面我们可以知道我们的finditer()没有方法groups()和group()
#但是当我们迭代的时候里面的元素可以使用者2个方法、
|
split()
re.split()扫描整个字符串吧匹配到的正则表达式作为分隔符把字符分割
并把分割的函数存储到列表中
|
1
2
3
4
5
6
7
8
9
10
11
|
import
re
res
=
re.split(r
'\s '
,r
"I'll be the one, if you want me to"
)
print
(res)
#["I'll", 'be', 'the', 'one,', 'if', 'you', 'want', 'me', 'to']
res2
=
re.split(r
'(\s)'
,r
"I'll be the one, if you want me to"
)
print
(res2)
#["I'll", ' ', 'be', ' ', 'the', ' ', 'one,', ' ', 'if', ' ', 'you', ' ', 'want', ' ', 'me', ' ', 'to']
#有上面的结果我们可以知道当我们使用分组的方式,匹配到的元素不会删除
#它会以该匹配到的元素周围作为分隔符整个字符串不会少。
|
sub()
re.sub()是扫描整个字符串吧匹配到的字符替换掉
|
1
2
3
4
5
|
import
re
res
=
re.sub(
'you'
,
'my'
,
"I'll be the one, if you want me to"
)
print
(res)
#I'll be the one, if my want me to
|
from:https://www.cnblogs.com/yang-China/p/8056695.html