1、pstree
进程树查看
-p:并显示各进程的PID
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
[root@Note3 ~]
# pstree
init─┬─ManagementAgent───2*[{ManagementAgen}]
├─NetworkManager
├─VGAuthService
├─atd
├─auditd───{auditd}
├─console-kit-dae───63*[{console-kit-da}]
├─crond
├─cupsd
├─dbus-daemon
├─dhclient
├─hald─┬─hald-runner─┬─hald-addon-acpi
│ │ └─hald-addon-inpu
│ └─{hald}
├─login───
bash
├─master─┬─pickup
│ └─qmgr
├─5*[mingetty]
├─modem-manager
├─polkitd
├─rsyslogd───3*[{rsyslogd}]
├─sshd─┬─sshd───
bash
│ └─sshd───
bash
───pstree
├─ssserver
├─udevd───2*[udevd]
├─vmtoolsd───{vmtoolsd}
└─wpa_supplicant
|
2、pgrep
-U UID:仅显示以指定用户身份运行的进程号;可接用户名或UID
-G GID
-l: 显示PID和进程名;
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@Note3 ~]
# pgrep -U postfix
1852
20521
[root@Note3 ~]
# pgrep -G postfix
1852
20521
[root@Note3 ~]
# pgrep -l -U postfix
1852 qmgr
20521 pickup
[root@Note3 ~]
# pgrep -U -l postfix
pgrep: invalid user name: -l
|
3、pidof
显示指定命令所启动的pid
pidof PROGRAM #PROGRAM是给定命令或程序
|
1
2
|
[root@Note3 ~]
# pidof sshd
20140 19956 19828 14103 1637
|
4、ps
显示的是当前进程状态信息的快照,为静态结果
|
1
2
3
4
5
6
7
|
[root@Note3 ~]
# ping 192.168.10.10 >/dev/null &
[1] 18435
[root@Note3 ~]
# ps
PID TTY TIME CMD
8587 pts
/0
00:00:00
bash
18435 pts
/0
00:00:00
ping
18473 pts
/0
00:00:00
ps
|
默认情况,ps命令只显示属于当前用户并正在当前终端中运行的进程。
 支持众多选项:
支持众多选项:
BSD风格:选项前不加“-”
SysV风格
根据进程启动时是否是通过终端上的用户接口交互式启动的,进程可分为两类:
所有与终端相关的进程:a
所有与终端无关的进程:x
以用户为中心组织进程状态信息显示:u
常用选项组合1:axu
|
1
2
3
4
5
6
7
8
|
[root@Note3 ~]
# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 19360 1536 ? Ss 03:55 0:01
/sbin/init
root 2 0.0 0.0 0 0 ? S 03:55 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 03:55 0:00 [migration
/0
]
root 4 0.0 0.0 0 0 ? S 03:55 0:00 [ksoftirqd
/0
]
root 5 0.0 0.0 0 0 ? S 03:55 0:00 [migration
/0
]
root 6 0.0 0.0 0 0 ? S 03:55 0:00 [watchdog
/0
]
|
USER:进程的属主
PID:进程号
%CPU:占据CPU的的百分比
%MEM:占据内存的百分比
VSZ:占用线性地址空间的大小
RSS:常驻内存集,指不可以被交换至swap空间的数据占据空间大小;
TTY:终端
START:进程启动时间
TIME:占据CPU累计时间
COMMAND:启动当前进程的命令,[COMMAND]表示为内核线程
STAT:进程状态
R:运行
S:interruptible sleeping,可中断睡眠
D:uniterruptible sleeping, 不可中断睡眠
T: stopped 停止
Z: zombie 僵死
s: session leader 进程领导者
+: 前台进程,占据着某终端,终端关闭进程也被关闭
l: 多线程进程
<: 高优先级进程
N: 低优先级进程
常用选项组合2: -ef
-e: 显示所有进程;
-f: 显示丰富格式信息
ppid:父进程号
常用选项组合3:-eFH
-F: 显示额外信息
-H: 以层级形式显示进程间关系;
o 要显示的字段:自定义
例如:ps axo pid,command,psr,pri,ni
psr: 当前进程运行的CPU编号;
pri: 当前进程的优先级;
ni: 当前进程的nice值:-20, 19
5、uptime
显示当前系统时间,运行时长(上次开机至现在运行的时间),登录的用户数及系统平均负载
系统平均负载:在特定时间间隔内CPU上等待运行的进程队列的长度(平均进程数)
通过top\uptime\w\tload可以获取到load average的值,它的三个数字值分别记录了一分钟\五分钟\十五分钟的系统平均负载。
6、top命令
top是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止,比较准确的说,top命令提供了实时的对系统的整体运行状态监视.它将显示系统中CPU最“敏感”的任务列表,是一个综合了多方信息监测系统性能和运行信息的实用工具。
该命令可以按CPU使用、内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定,有许多交互式的子命令:
首部信息显示:
l: 是否显示系统负载行;队列长度的合理区间:CPU颗数*0.7
t: 是否显示进程摘要信息及CPU平均占用率(负载状态);
1:(数字1)分别显示多颗CPU负载状态
m:是否显示内存和交换分区使用信息
排序:
P:以占据的CPU百分比大小排序;从大到下依次排序
M:以占据Memory空间大小排序;
T:以累积占用CPU时间排序;
cpu平均占用率栏详解:
|
1
2
|
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%
id
, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
us: user space
|
us:用户空间所占的比率
sy: system (kernel space) 内核空间
ni: nice (被nice调整过的进程)改变过优先级的进程占用CPU的百分比
id: idle 空闲
wa: wait io 等待io完成
hi:hardware interrupt 硬件中断
si: software interrupt 软件终端
st: stolen, 被虚拟化(虚拟机)“偷走”的百分比
q: 退出命令
s:修改刷新间隔时间,默认为3
k: 终止指定进程
top命令的选项:
-b: batch,批次显示
-n #: 显示的批次数量,和-b一起使用
-d N: 指明延迟时长
|
1
2
3
4
5
6
7
8
9
|
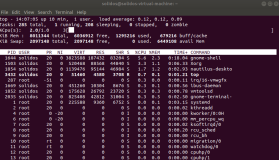
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9916 root 20 0 169m 114m 17m S 9.6 0.2 128:36.64 svr_scene
26430 root 20 0 167m 119m 17m S 5.0 0.2 445:02.57 svr_scene
9920 root 20 0 156m 28m 4948 S 3.6 0.0 52:39.27 svr_gateway
9911 root 20 0 74728 35m 14m S 3.0 0.1 23:01.81 svr_manager
9918 root 20 0 92628 53m 16m S 3.0 0.1 38:44.87 svr_app
5421 root 20 0 150m 23m 1464 S 2.7 0.0 572:10.42 redis-server
9914 root 20 0 215m 76m 15m S 2.7 0.1 27:45.02 svr_data
26431 root 20 0 96556 51m 16m R 1.7 0.1 131:52.15 svr_app
|
进程信息
| 列名 |
含义 |
| PID |
进程id |
| PPID |
父进程id |
| RUSER |
Real user name |
| UID |
进程所有者的用户id |
| USER |
进程所有者的用户名 |
| GROUP |
进程所有者的组名 |
| TTY |
启动进程的终端名。不是从终端启动的进程则显示为 ? |
| PR |
优先级 |
| NI |
nice值。负值表示高优先级,正值表示低优先级 |
| P |
最后使用的CPU,仅在多CPU环境下有意义 |
| %CPU |
上次更新到现在的CPU时间占用百分比 |
| TIME |
进程使用的CPU时间总计,单位秒 |
| TIME+ |
进程使用的CPU时间总计,单位1/100秒 |
| %MEM |
进程使用的物理内存百分比 |
| VIRT |
进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| SWAP |
进程使用的虚拟内存中,被换出的大小,单位kb。 |
| RES |
进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| CODE |
可执行代码占用的物理内存大小,单位kb |
| DATA |
可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| SHR |
共享内存大小,单位kb |
| nFLT |
页面错误次数 |
| nDRT |
最后一次写入到现在,被修改过的页面数。 |
| S |
进程状态。 |
| COMMAND |
命令名/命令行 |
| WCHAN |
若该进程在睡眠,则显示睡眠中的系统函数名 |
| Flags |
任务标志,参考 sched.h |
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
通过 f 键可以选择显示的内容:
按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
按 o 键可以改变列的显示顺序:
按小写的 a-z 可以将相应的列向右(下)移动,而大写的 A-Z 可以将相应的列向左(上)移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
VIRT:virtual memory usage 虚拟内存
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等
2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量
RES:resident memory usage 常驻内存
1、进程当前使用的内存大小,但不包括swap out
2、包含其他进程的共享
3、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反
4、关于库占用内存的情况,它只统计加载的库文件所占内存大小
SHR:shared memory 共享内存
1、除了自身进程的共享内存,也包括其他进程的共享内存
2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小
3、计算某个进程所占的物理内存大小公式:RES – SHR
4、swap out后,它将会降下来
DATA
1、数据占用的内存。如果top没有显示,按f键可以显示出来。
2、真正的该程序要求的数据空间,是真正在运行中要使用的。
VIRT=SWAP+RES
RES=CODE+DATA
8、htop
htop是Linux系统下一个基本文本模式的、交互式的进程查看器,主要用于控制台或shell中,可以替代top,或者说是top的高级版。
快速查看关键性能统计数据,如CPU(多核布局)、内存/交换使用
可以横向或纵向滚动浏览进程列表,以查看所有的进程和完整的命令行
杀掉进程时可以直接选择而不需要输入进程号
通过鼠标操作条目
比top启动得更快
命令:
u: 过滤仅显示选定用户的进程;
s: 跟踪选定的进程所发起的系统调用;
l: 显示选定进程所打开的文件;
t: 显示进程的层次结构;
a: 设定进程的cpu亲缘性;(将选定的进程绑定在指定的CPU上)
选项:
-d #: 延迟时长
-u USERNAME: 仅显示指定用户的进程;
-s COLUMN: 根据指定的字段进行排序;
9、vmstat
报告关于进程、内存、磁盘I/O,系统中断,进程切换,cpu平均占用率等系统整体运行状态
|
1
2
3
4
|
[root@Note3 ~]
# vmstat #默认显示一次
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd
free
buff cache si so bi bo
in
cs us sy
id
wa st
1 0 0 1383072 59572 325744 0 0 4 0 21 21 0 0 100 0 0
|

r:运行或等待运行的进程个数
in:中断发生速率,每秒的中断数
使用格式:
vmstat [delay [counts]]
延时刷新 刷新几次
-s:显示内存统计数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
[root@Note3 ~]
# vmstat 1 3 #每隔1秒刷新一次,总共刷新3次,不指定刷新次数则一直运行下去
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd
free
buff cache si so bi bo
in
cs us sy
id
wa st
0 0 0 1383104 59676 325744 0 0 4 0 21 21 0 0 100 0 0
0 0 0 1383080 59676 325744 0 0 0 0 41 34 0 0 100 0 0
0 0 0 1383080 59676 325744 0 0 0 0 74 46 0 0 100 0 0
[root@Note3 ~]
# vmstat -s
1914492 total memory
531264 used memory
201280 active memory
218100 inactive memory
1383228
free
memory
59676 buffer memory
325744 swap cache
2047992 total swap
0 used swap
2047992
free
swap
2140 non-
nice
user cpu ticks
36
nice
user cpu ticks
7526 system cpu ticks
8954651 idle cpu ticks
7688 IO-wait cpu ticks
29 IRQ cpu ticks
1649 softirq cpu ticks
0 stolen cpu ticks
385801 pages paged
in
40062 pages paged out
0 pages swapped
in
0 pages swapped out
1897682 interrupts
1896584 CPU context switches
1481831717 boot
time
16382 forks
|
10、dstat
动态地统计系统资源信息
dstat命令是一个全能信息统计工具,拥有彩色界面,实时刷新,功能非常强大
使用格式:
dstat [-afv] [options..] [delay [count]]
-c: 显示cpu性能指标相关的统计数据;
-d: 显示disk相关的速率数据;
-g: 显示page相关的速率数据;
-i: 显示interrupt相关的速率数据;
-l: 显示load average相关的统计数据;
-m: 显示memory相关的统计数据;
-n: 显示网络收发数据的速率;
-p: 显示进程相关的统计数据,
-r: io请求的速率;
-s: 显示swap的相关数据
-y: 显示系统相关的数据,包括中断和进程切换;
--top-cpu:显示最占用CPU的进程;
--top-bio:显示最消耗block io的进程;
--top-io:最占用io的进程;
--top-mem:显示最占用内存的进程;
--ipc: 显示进程间通信相关的速率数据;
--raw: 显示raw套接的相关的数据;
--tcp: 显示tcp套接字的相关数据;
--udp: 显示udp套接字的相关数据;
--unix: 显示unix sock接口相关的统计数据;
--socket:
-a: -cdngy
11、iostat来对linux硬盘IO性能进行了解
Linux系统中的 iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。iostat属于sysstat软件包。可以用yum install sysstat 直接安装。
1.命令格式:
iostat[参数][时间][次数]
2.命令功能:
通过iostat方便查看CPU、网卡、tty设备、磁盘、CD-ROM 等等设备的活动情况,负载信息。
3.命令参数:
-c 显示CPU使用情况
-d 显示磁盘使用情况;可以指定只显示某分区的使用情况,不指定显示所有磁盘的使用情况,
-k 以 KB 为单位显示
-m 以 M 为单位显示
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS 使用情况
-p[磁盘] 显示磁盘和分区的情况
-t 显示终端和CPU的信息
-x 显示详细信息
-V 显示版本信息
4.使用实例:
实例1:显示所有设备负载情况
命令:
iostat
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
[xmxiuman@esf ~]$ iostat
Linux 2.6.32-431.el6.x86_64 (esf) 05
/20/2017
_x86_64_ (24 CPU)
avg-cpu: %user %
nice
%system %iowait %steal %idle
0.23 0.00 0.09 0.27 0.00 99.41
Device: tps Blk_read
/s
Blk_wrtn
/s
Blk_read Blk_wrtn
sda 16.43 3.55 446.43 15920980 2004854200
[xmxiuman@esf ~]$ iostat -k
Linux 2.6.32-431.el6.x86_64 (esf) 05
/20/2017
_x86_64_ (24 CPU)
avg-cpu: %user %
nice
%system %iowait %steal %idle
0.23 0.00 0.09 0.27 0.00 99.41
Device: tps kB_read
/s
kB_wrtn
/s
kB_read kB_wrtn
sda 16.43 1.77 223.22 7960490 1002488360
|
说明:
cpu属性值说明:
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
备注:
如果%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
disk属性值说明:
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。
“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;kB_wrtn:写入的总数量数据量;
这些单位都为Kilobytes。
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rsec/s: 每秒读扇区数。即 rsect/s
wsec/s: 每秒写扇区数。即 wsect/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
wkB/s: 每秒写K字节数。是 wsect/s 的一半。
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。
avgqu-sz: 平均I/O队列长度。
await: 平均每次设备I/O操作的等待时间 (毫秒)。
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
%util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比
备注:
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有当量io在等待。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[xmxiuman@esf ~]$ iostat -xk
Linux 2.6.32-431.el6.x86_64 (esf) 05
/20/2017
_x86_64_ (24 CPU)
avg-cpu: %user %
nice
%system %iowait %steal %idle
0.23 0.00 0.09 0.27 0.00 99.41
Device: rrqm
/s
wrqm
/s
r
/s
w
/s
rkB
/s
wkB
/s
avgrq-sz avgqu-sz await svctm %util
sda 0.00 39.45 0.09 16.33 1.77 223.17 27.39 0.25 15.45 4.97 8.16
[xmxiuman@esf ~]$ iostat -xkd
Linux 2.6.32-431.el6.x86_64 (esf) 05
/20/2017
_x86_64_ (24 CPU)
Device: rrqm
/s
wrqm
/s
r
/s
w
/s
rkB
/s
wkB
/s
avgrq-sz avgqu-sz await svctm %util
sda 0.00 39.45 0.09 16.33 1.77 223.17 27.39 0.25 15.45 4.97 8.16
|
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的.即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈.
idle小于70% IO压力就较大了,一般读取速度有较多的wait.
同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)。
另外 await 的参数也要多和 svctm 来参考.差的过高就一定有 IO 的问题.
avgqu-sz 也是个做 IO 调优时需要注意的地方,这个就是直接每次操作的数据的大小,如果次数多,但数据拿的小的话,其实 IO 也会很小。如果数据拿的大,才IO 的数据会高。也可以通过 avgqu-sz × ( r/s or w/s ) = rsec/s or wsec/s。也就是讲,读定速度是这个来决定的。
svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
别人一个不错的例子.(I/O 系统 vs. 超市排队)
举一个例子,我们在超市排队 checkout 时,怎么决定该去哪个交款台呢? 首当是看排的队人数,5个人总比20人要快吧? 除了数人头,我们也常常看看前面人购买的东西多少,如果前面有个采购了一星期食品的大妈,那么可以考虑换个队排了.还有就是收银员的速度了,如果碰上了连 钱都点不清楚的新手,那就有的等了.另外,时机也很重要,可能 5 分钟前还人满为患的收款台,现在已是人去楼空,这时候交款可是很爽啊,当然,前提是那过去的 5 分钟里所做的事情比排队要有意义 (不过我还没发现什么事情比排队还无聊的).
I/O 系统也和超市排队有很多类似之处:
总IO请求数:r/s+w/s;类似于交款人的总数
平均队列长度(avgqu-sz):类似于单位时间里平均排队人的个数
平均服务时间(svctm):类似于收银员的收款速度
平均等待时间(await):类似于平均每人的等待时间
平均I/O数据(avgrq-sz):类似于平均每人所买的东西多少
I/O 操作率 (%util):类似于收款台前有人排队的时间比例.
我们可以根据这些数据分析出 I/O 请求的模式,以及 I/O 的速度和响应时间.
下面是别人写的这个参数输出的分析
|
1
2
3
4
5
|
# iostat -x 1
avg-cpu: %user %
nice
%sys %idle
16.24 0.00 4.31 79.44
Device: rrqm
/s
wrqm
/s
r
/s
w
/s
rsec
/s
wsec
/s
rkB
/s
wkB
/s
avgrq-sz avgqu-sz await svctm %util
/dev/cciss/c0d0
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
|
上面的 iostat 输出表明秒有 28.57 次设备 I/O 操作:
总IO(io)/s = r/s(读) +w/s(写) = 1.02+27.55 = 28.57 (次/秒) 其中写操作占了主体 (w:r = 27:1).
平均每次设备 I/O 操作只需要 5ms 就可以完成,但每个 I/O 请求却需要等上 78ms,为什么?
因为发出的 I/O 请求太多 (每秒钟约 29 个),系统处理不过来,产生IO阻塞,需要等待
假设这些请求是同时发出的,那么平均等待时间可以这样计算:
平均等待时间 = 单个 I/O 服务时间 * ( 1 + 2 + … + 请求总数-1) / 请求总数
应用到上面的例子:
平均等待时间 = 5ms * (1+2+…+28)/29 = 70ms
和 iostat 给出的78ms 的平均等待时间很接近.这反过来表明 I/O 是同时发起的.
一秒中有 14.29% 的时间 I/O 队列中是有请求的,也就是说,85.71% 的时间里 I/O 系统无事可做,所有 29 个 I/O 请求都在142毫秒之内处理掉了.
delta(ruse+wuse)/delta(io) = await = 78.21 => delta(ruse+wuse)/s =78.21 * delta(io)/s = 78.21*28.57 = 2232.8
表明每秒内的I/O请求总共需要等待2232.8ms.所以平均队列长度应为 2232.8ms/1000ms = 2.23,而 iostat 给出的平均队列长度 (avgqu-sz) 却为 22.35,为什么?! 因为 iostat 中有 bug,avgqu-sz 值应为 2.23,而不是 22.35.
每秒发出的 I/O 请求很多 (约 29 个),平均队列却不长 (只有 2个 左右),这表明这 29 个请求的到来并不均匀,大部分时间 I/O 是空闲的.
本文转自xiexiaojun51CTO博客,原文链接:http://blog.51cto.com/xiexiaojun/1883447 ,如需转载请自行联系原作者