第一次访问
1.Last-Modified/If-Modified-Since
fiddler->inspectors->服务器返回的HTTP头标签中有Last-Modified
第二次访问
If-Modified-Since
第三次,改动内容
Last-Modified
If-Modified-Since
服务器返回的HTTP头标签中有Last-Modified,告诉客户端页面的新的最后修改时间
2.网页请求在什么情况下会携带If-None-Match或If-Modified-Since头信息
3.一次完整的HTTP请求过程
HTTP请求格式
HTTP请求格式主要有四部分组成,分别是:请求行、请求头、空行、消息体,每部分内容占一行
<request-line>
<general-headers>
<request-headers>
<entity-headers>
<empty-line>
[<message-body>]

HTTP响应格式
服务器接收处理完请求后返回一个HTTP相应消息给客户端。HTTP响应消息的格式包括:状态行、响应头、空行、消息体。每部分内容占一行。
<status-line>
<general-headers>
<response-headers>
<entity-headers>
<empty-line>
[<message-body>]

Socket
WEB Server都是基于Socket编程,又称之为网络编程,网络协议通过一个叫做socket的对象抽象出来,socket可以建立网络连接,读数据,写数据。socket模块定义了一些常量参数,用来指定socket的的地址族、socket的类型、以及支持的TCP/IP协议。
socket.socket([family[, type[, proto]]]):根据指定的地址族和套接字类型、协议编号(默认为0)来创建套接字对象。AF_INET对应的IPV4, AF_INET6对应的IPV6。
Socket对象方法
socket.bind(address):绑定IP地址以及端口
socket.listen(backlog) :在指定的端口开始监听,backlog表示connection队列的最大长度
socket.setblocking(flag) : 设置为非阻塞还是阻塞的socket,如果是非阻塞的,那么调用recv的时候如果没有数据可读,那么久直接返回一个错误,相反如果设置为阻塞模式,如果没有数据可读,那么就一直处于阻塞等待数据的状态。
socket.accept():当有连接请求过来时,接收该连接,返回一个socket对象,该对象可以在基于该连接发送和接收数据。
socket.sendall(string[, flags]):发送数据
socket.recv(bufsize[, flags]):接收数据
socket.close():关闭socket连接。
搞清楚了HTTP规范和Socket之后,我们就可以使用Socket实现一个对简单的HTTP服务器了
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# -*- coding:utf-8 -*-
import
socket
if
__name__
=
=
'__main__'
:
PORT
=
8000
sock
=
socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind((
'127.0.0.1'
, PORT))
sock.listen(
1
)
print
'Serving HTTP on port %s ...'
%
PORT
while
1
:
conn, addr
=
sock.accept()
print
conn, addr
request
=
conn.recv(
1024
)
# HTTP响应消息
response
=
"HTTP/1.1 200 OK\nContent-Type:text/html\nServer:myserver\n\nHello, World!"
conn.sendall(response)
conn.close()
|
4.最近在准备优化日志请求时遇到了一些令人疑惑的问题,比如为什么响应头里出现了两个 cache control、为什么明明设置了 no cache 却还是发请求,为什么多次访问时有时请求里带了 etag,有时又没有带?等等。。。
1、缓存的分类
缓存分为服务端侧(server side,比如 Nginx、Apache)和客户端侧(client side,比如 web browser)。
服务端缓存又分为 代理服务器缓存 和 反向代理服务器缓存(也叫网关缓存,比如 Nginx反向代理、Squid等),其实广泛使用的 CDN 也是一种服务端缓存,目的都是让用户的请求走”捷径“,并且都是缓存图片、文件等静态资源。
客户端侧缓存一般指的是浏览器缓存,目的就是加速各种静态资源的访问,想想现在的大型网站,随便一个页面都是一两百个请求,每天 pv 都是亿级别,如果没有缓存,用户体验会急剧下降、同时服务器压力和网络带宽都面临严重的考验
2、浏览器缓存机制详解
浏览器缓存控制机制有两种:HTML Meta标签 vs. HTTP头信息
2.1 HTML Meta标签控制缓存
浏览器缓存机制,其实主要就是HTTP协议定义的缓存机制(如: Expires; Cache-control等)。但是也有非HTTP协议定义的缓存机制,如使用HTML Meta 标签,Web开发者可以在HTML页面的<head>节点中加入<meta>标签,代码如下:
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">
上述代码的作用是告诉浏览器当前页面不被缓存,每次访问都需要去服务器拉取。使用上很简单,但只有部分浏览器可以支持,而且所有缓存代理服务器都不支持,因为代理不解析HTML内容本身。而广泛应用的还是 HTTP头信息 来控制缓存,下面我主要介绍HTTP协议定义的缓存机制。
2.2 HTTP头信息控制缓存
2.2.1 浏览器请求流程
浏览器第一次请求流程图:
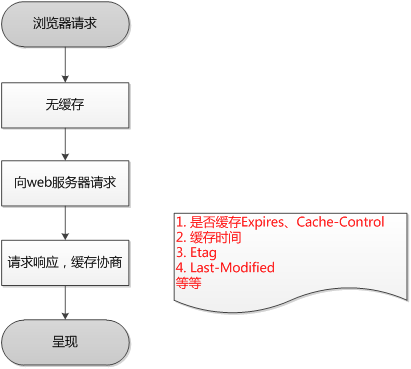
浏览器再次请求时

2.2.2 几个重要概念解释
-
Expires策略:Expires是Web服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据,而无需再次请求。不过Expires 是HTTP 1.0的东西,现在默认浏览器均默认使用HTTP 1.1,所以它的作用基本忽略。Expires 的一个缺点就是,返回的到期时间是服务器端的时间,这样存在一个问题,如果客户端的时间与服务器的时间相差很大(比如时钟不同步,或者跨时区),那么误差就很大,所以在HTTP 1.1版开始,使用Cache-Control: max-age=秒替代。
-
Cache-control策略(重点关注):Cache-Control与Expires的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据。只不过Cache-Control的选择更多,设置更细致,如果同时设置的话,其优先级高于Expires。
|
1
2
3
4
5
6
7
8
9
|
值可以是public、private、no-cache、no- store、no-transform、must-revalidate、proxy-revalidate、max-age
各个消息中的指令含义如下:
Public指示响应可被任何缓存区缓存。
Private指示对于单个用户的整个或部分响应消息,不能被共享缓存处理。这允许服务器仅仅描述当用户的部分响应消息,此响应消息对于其他用户的请求无效。
no-cache指示请求或响应消息不能缓存,该选项并不是说可以设置”不缓存“,容易望文生义~
no-store用于防止重要的信息被无意的发布。在请求消息中发送将使得请求和响应消息都不使用缓存,完全不存下來。
max-age指示客户机可以接收生存期不大于指定时间(以秒为单位)的响应。
min-fresh指示客户机可以接收响应时间小于当前时间加上指定时间的响应。
max-stale指示客户机可以接收超出超时期间的响应消息。如果指定max-stale消息的值,那么客户机可以接收超出超时期指定值之内的响应消息。
|
-
Last-Modified/If-Modified-Since:Last-Modified/If-Modified-Since要配合Cache-Control使用。
|
1
2
|
Last-Modified:标示这个响应资源的最后修改时间。web服务器在响应请求时,告诉浏览器资源的最后修改时间。
If-Modified-Since:当资源过期时(使用Cache-Control标识的max-age),发现资源具有Last-Modified声明,则再次向web服务器请求时带上头 If-Modified-Since,表示请求时间。web服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。若最后修改时间较新,说明资源又被改动过,则响应整片资源内容(写在响应消息包体内),HTTP 200;若最后修改时间较旧,说明资源无新修改,则响应HTTP 304 (无需包体,节省浏览),告知浏览器继续使用所保存的cache。
|
-
Etag/If-None-Match:Etag/If-None-Match也要配合Cache-Control使用。
|
1
2
|
Etag:web服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)。Apache中,ETag的值,默认是对文件的索引节(INode),大小(Size)和最后修改时间(MTime)进行Hash后得到的。
If-None-Match:当资源过期时(使用Cache-Control标识的max-age),发现资源具有Etage声明,则再次向web服务器请求时带上头If-None-Match (Etag的值)。web服务器收到请求后发现有头If-None-Match 则与被请求资源的相应校验串进行比对,决定返回200或304。
|
-
既生Last-Modified何生Etag?你可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag(实体标识)呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
|
1
2
3
|
Last-Modified标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的修改时间
如果某些文件会被定期生成,当有时内容并没有任何变化,但Last-Modified却改变了,导致文件没法使用缓存
有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形
|
Etag是服务器自动生成或者由开发者生成的对应资源在服务器端的唯一标识符,能够更加准确的控制缓存。Last-Modified与ETag一起使用时,服务器会优先验证ETag。
-
yahoo的Yslow法则中则提示谨慎设置Etag:需要注意的是分布式系统里多台机器间文件的last-modified必须保持一致,以免负载均衡到不同机器导致比对失败,Yahoo建议分布式系统尽量关闭掉Etag(每台机器生成的etag都会不一样,因为除了 last-modified、inode 也很难保持一致)。
-
Pragma行是为了兼容HTTP1.0,作用与Cache-Control: no-cache是一样的。
-
最后总结下几种状态码的区别:
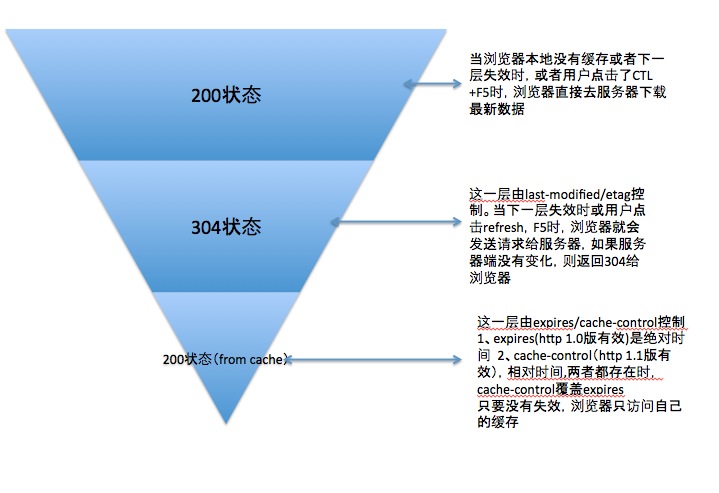
3、用户行为与缓存
浏览器缓存行为还有用户的行为有关,如果大家对 强制刷新(Ctrl + F5) 还有印象的话应该能立刻明白我的意思
| 用户操作 |
Expires/Cache-Control |
Last-Modified/Etag |
| 地址栏回车 |
有效 |
有效 |
| 页面链接跳转 |
有效 |
有效 |
| 新开窗口 |
有效 |
有效 |
| 前进、后退 |
有效 |
有效 |
| F5/按钮刷新 |
无效(BR重置max-age=0) |
有效 |
| Ctrl+F5刷新 |
无效(重置CC=no-cache) |
无效(请求头丢弃该选项) |
4、Refer:
[1] 浏览器缓存机制
http://www.cnblogs.com/skynet/archive/2012/11/28/2792503.html
[2] Web 开发人员需知的 Web 缓存知识
http://www.oschina.net/news/41397/web-cache-knowledge
[3] 浏览器缓存详解:expires,cache-control,last-modified,etag详细说明
http://blog.csdn.net/eroswang/article/details/8302191
[4] 在浏览器地址栏按回车、F5、Ctrl+F5刷新网页的区别
http://cloudbbs.org/forum.php?mod=viewthread&tid=15790
http://blog.csdn.net/yui/article/details/6584401
[5] Cache Control 與 ETag
https://blog.othree.net/log/2012/12/22/cache-control-and-etag/
[6] 缓存的故事
http://segmentfault.com/blog/animabear/1190000000375344
[7] Google的PageSpeed网站优化理论中提到使用Etag可以减少服务器负担
https://developers.google.com/speed/docs/pss/AddEtags
[8] yahoo的Yslow法则中则提示谨慎设置Etag
http://developer.yahoo.com/performance/rules.html#etags
[9] H5 缓存机制浅析 移动端 Web 加载性能优化
http://segmentfault.com/a/1190000004132566
[10] 网页性能: 缓存效率实践
http://www.w3ctech.com/topic/1648
[11] 透过浏览器看HTTP缓存
http://www.cnblogs.com/skylar/p/browser-http-caching.html
[12] 浏览器缓存知识小结及应用
[13] 大公司里怎样开发和部署前端代码?
[14] 浏览器缓存机制详解
https://mangguo.org/browser-cache-mechanism-detailed/
5.漫谈HTTP
http://groot.blog.51cto.com/11448219/1872795
HTTP版本:
http/0.9:作为HTTP协议的第一个版本。是非常弱的,只定义了最基本的简单请求和简单回答。
http/1.0:新增了cache, MIME{MIME: multipurpose internet mail extensions(多用途的网际邮件扩充协议)}机制,用非持久连接,即在非持久连接下,一个tcp连接只传输一个Web对象
http/1.1:新增了缓存功能,条件式请求;
speedy协议: SPDY是Google开发的基于TCP的应用层协议,用以最小化网络延迟,提升网络速度,优化用户的网络使用体验。SPDY并不是一种用于替代HTTP的协议,而是对HTTP协议的增强。新协议的功能包括数据流的多路复用、请求优先级以及HTTP报头压缩。谷歌表示,引入SPDY协议后,在实验室测试中页面加载速度比原先快64%。
http/2.0:在开放互联网上HTTP 2.0将只用于https://网址,而 http://网址将继续使用HTTP/1,目的是在开放互联网上增加使用加密技术,以提供强有力的保护去遏制主动攻击。DANE RFC6698允许域名管理员不通过第三方CA自行发行证书。
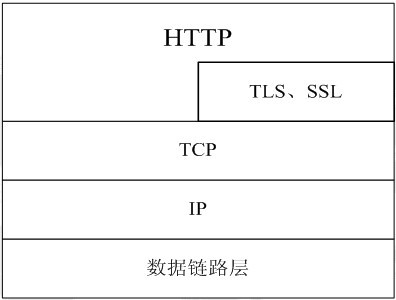
HTTP协议HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们现在常用的HTTPS,如下图所示:
一次完整的Http请求处理过程:
一次HTTP操作称为一个事务,其工作过程可分为七步
(1) 建立或处理连接请求 :接受或拒绝请求
(2) 接收请求:接受来自于网络的请求报文中对某资源的一次请求的过程;接收请求的方式通常是并发访问响应模型(WEB I/O)
(3) 解析请求,处理请求:对请求报文进行解析,并获取请求的资源及请求方法等相关信息
(4) 加载用户请求的资源;
(5) 构建响应报文,根据用户请求的资源MIME类型以及URL重定向进行报文响应;
(6) 发送响应报文;
(7) 记录访问于日志中;
web资源:
URL:统一资源定位符(Uniform Resource Locator);是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URI:统一资源标识符(Uniform Resource Identifier);是一类更通用的资源标识符,URL 实际上是它的一个子集。URI 是一个通用的概念,由两个主要的子集URL 和URN(统一资源名称 (Uniform Resource Name, URN)) 构成,URL 是通过描述资源的位置来标识资源的,而URN则是通过名字来识别资源的,与它们当前所处位置无关。
URL格式:
比如说,你想要获取URL http://www.xxxx.com/index-fall.html。
URL 分以下三部分。
URL 的第一部分(http)是 URL 方案(scheme)。方案可以告知 Web 客户端怎样访问资源。在这个例子中,URL 说明要使用HTTP 协议。
URL 的第二部分(www.xxxx.com)指的是服务器的位置。这部分告知Web 客户端资源位于何处。
URL 的第三部分(/index-fall.html)是资源路径。路径说明了请求的是服务器上哪个特定的本地资源。
HTTP请求(HTTP Request)
所谓的HTTP请求,也就是Web客户端向Web服务器发送信息,这个信息由如下三部分组成:
1.请求行
2.HTTP头
3.内容
请求行写法是固定的,由三部分组成,第一部分是请求方法,第二部分是请求网址,第三部分是HTTP版本。 如: GET www.xxxx.com HTTP/1.1
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本,格式如下:
Method Request-URI HTTP-Version CRLF
其中 Method表示请求方法;Request-URI是一个统一资源标识符;HTTP-Version表示请求的HTTP协议版本;CRLF表示回车和换行(除了作为结尾的CRLF外,不允许出现单独的CR或LF字符)。
<method>(资源传递方法):GET,HEAD,POST, PUT, DELETE, OPTIONS, TRACE, ...
GET:从服务器获取一个资源;
HEAD:只从服务器获取文档的响应首部;
POST:向服务器发送要处理的数据;
PUT:将请求的主体部分存储在服务器上;
DELETE:请求删除服务器上指定的文档;
TRACE:追踪请求到达服务器中间经过的代理服务器;
OPTIONS: 请求服务器返回对指定资源支持使用的请求方法;
访问资源:获取请求报文中请求的资源
HTTP响应(HTTP Response)
当Web服务器收到HTTP请求后,会根据请求的信息做某些处理(这些处理可能仅仅是静态的返回页,或是包含Asp.net,PHP,Jsp等语言进行处理后返回),相应的返回一个HTTP响应。HTTP响应在结构上很类似于HTTP请求,也是由三部分组成,分别为:
1.状态行
2.HTTP头
3.响应正文
首先来看状态行,一个典型的HTTP状态如下: HTTP/1.1 200 OK
状态行格式如下:
HTTP-Version Status-Code Reason-Phrase CRLF
其中,HTTP-Version表示服务器HTTP协议的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
-
1xx: 信息提示
-
2xx: 成功响应
200:成功,请求的所有数据通过响应报文的entity-body部分发送;ok
-
3xx: 重定向响应
301:请求的URL执行的资源已经被删除,但在响应报文中通过首部location指明了资源现在所在的新位置:Moved Permanently
302:与301相似,但在响应报文中通过location指明资源现在所在的临时新位置:Found
304:客户端发出了条件式请求,但服务器上的资源未曾发生改变,则通过响应状态码通知客户端:Not Modified
-
4xx: 客户端错误
401: 需要输入账号和密码认证方能访问资源
403:请求被禁止:Forbidden
404: 服务器无法找到客户端请求的资源 : Not Found
-
5xx: 服务端错误
500:服务器内部错误 : Internal Server Error
502:代理服务器从后端服务器收到一条伪响应 : Bad Gateway
首部分类:
通用首部、请求首部、响应首部、实体首部、扩展首部
通用首部:
Connection: {close|keep-alive}
Date:报文创建的日期时间
Via:经由,
Cache-Control:缓存控制;
Pragma:
请求首部:
Host:
Referer:跳转至当前页面的上级资源;
User-Agent:用户代理;
Client-IP:
Accept:可接收的MIME类型;
Accept-Language:
Accept-Encoding:gzip, defalte,
Accept-Charset:
响应首部:
信息性首部:
Server:
协商类首部:
Accept-Range:服务器端可接受的请求类型范围
Vary:其它首部列表
安全相关的首部:
WWW-Authenticate:认证质询
Set-Cookie:
Set-Cookie2:
实体首部
Content-Encoding
Content-Language
Content-Lenth
Content-Location
Content-Type
...
Allow:允许使用的请求方法;
Location:
缓存相关:
Etag:扩展标签
Last-Modified:
Expires:
扩展首部:
X-Forwarded-For
……
url:Uniform Resource Locator
scheme://host:port/path
完整格式:
scheme://[<user>[:<password>]@<host>[:<port>]/<path>;<params>?<query>#frag
params:参数, ;param1=value1¶m2=value2
query:查询字符串, ?field1=value1&field2=value2
frag:页面锚定,#frag_id, 例如#ch1
本文转自 liqius 51CTO博客,原文链接:http://blog.51cto.com/szgb17/1909266,如需转载请自行联系原作者




