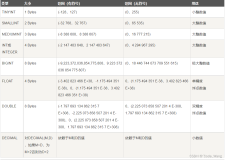
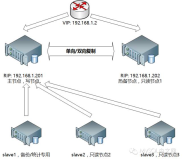
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
|
生产环境如何设置一定要以压测结果为准,以实际效果为准,不能盲目信任经验值
1.mysql connections->threads cached->threads cached
mysql connections->threads cached->threads connected(已用连接数,连接池)
mysql connections->threads cached->connections per second
2.表缓存,已经打开的表数
3.已经打开的文件数
4.QPS
/TPS
show status like
'queries'
QPS:Query per second,每秒查询量
show status like
'com_commit'
TPS:Transaction per second,每秒事物量
TPS = (Com_commit + Com_rollback) / Seconds
5.DML persecond图标
对应mysql innodb rows
6.Transaction Persecond(mysql innodb transactions)
commit
/rollback
7.innodb (mysql innodb buffer pool)
innodb buffer pool reads
innodb buffer pool pages flushed
8.key buffer
key buffer
read
rate
key buffer write rate
key blocks used rate
9.network
bytes_received,bytes_sent
10.aborted
aborted_clients,aborted_connects
11.MySQL InnoDB, MySQL InnoDB Buffer Pool
database pages InnoDB Buffer Pool Pages Data
free
pages InnoDB Buffer Pool Pages Free
modified pages InnoDB Rows Modified per second
12.MySQL Performance
MySQLTransactions Handler
handler commit InnoDB Transaction Committing
handler rollback InnoDB Transaction Rolling Back
handler savepoint
handler savepoint rollback
InnoDB Last Checkpoint at per second (MySQL InnoDB, MySQL InnoDB Log File)
13.MySQLProcesslist
具体如下
show processlist;
show full processlist;
show
open
tables;
show status like ‘%lock%’
show engine innodb status\G;
show variables like ‘%timeout%’;
1.线程池
thread_cache_size = 32
thread_stack = 512K
#innodb_file_io_threads = 8
innodb_thread_concurrency = 16
#thread_stack = 192K
#thread_concurrency = 128
尤其注意以下监控项
MySQL InnoDB Buffer Pool
pool size
database pages InnoDB Buffer Pool Pages Data
free
pages InnoDB Buffer Pool Pages Free
modified pages
UserParameter=MySQL.pool-size,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh gq
UserParameter=MySQL.modified-pages,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh gt
UserParameter=MySQL.
free
-pages,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh gr
UserParameter=MySQL.database-pages,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh gs
MySQLTransactions Handler
handler commit InnoDB Transaction Committing
handler rollback InnoDB Transaction Rolling Back
handler savepoint
handler savepoint rollback
UserParameter=MySQL.Handler-rollback,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh mw
UserParameter=MySQL.modified-pages,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh gt
UserParameter=MySQL.Handler-savepoint-rollback,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh my
UserParameter=MySQL.Handler-savepoint,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh mx
UserParameter=MySQL.Handler-commit,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh mm
MySQLProcesslist
UserParameter=MySQL.State-updating,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh mi
UserParameter=MySQL.State-freeing-items,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh lt
UserParameter=MySQL.State-other,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh ml
UserParameter=MySQL.State-none,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh mk
UserParameter=MySQL.State-init,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh lu
UserParameter=MySQL.State-sorting-result,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh mg
UserParameter=MySQL.State-statistics,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh mh
UserParameter=MySQL.State-copying-to-tmp-table,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh lr
UserParameter=MySQL.State-end,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh
ls
UserParameter=MySQL.State-login,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh lw
UserParameter=MySQL.State-reading-from-net,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh ly
UserParameter=MySQL.State-locked,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh lv
UserParameter=MySQL.State-sending-data,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh lz
UserParameter=MySQL.State-preparing,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh lx
UserParameter=MySQL.State-writing-to-net,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh mj
UserParameter=MySQL.State-closing-tables,
/var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper
.sh lq
5.6
last(
"mysql.innodb[Innodb_node_heap_buffers]"
,0)*last(
"mysql.status[innodb_page_size]"
,0) (MySQL InnoDB)
last(
"Qcache_used_blocks"
,0)
/last
(
"mysql.status[Qcache_queries_in_cache]"
,0) (MySQL Query Cache)
last(
"Qcache_used_memory"
,0)
/last
(
"Qcache_used_blocks"
,0)
(MySQL Query Cache)
last(
"mysql.status[Qcache_total_blocks]"
,0)-last(
"mysql.status[Qcache_used_blocks]"
,0) (MySQL Query Cache)
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
show processlist 哪些运行状态时要引起关注
copy to tmp table 执行ALTER TABLE修改表结构时 建议: 放在凌晨执行或者采用类似pt
-
osc工具
Copying to tmp table 拷贝数据到内存中的临时表,常见于GROUP BY操作时 建议: 创建适当的索引
Copying to tmp table on disk 临时结果集太大,内存中放不下,需要将内存中的临时表拷贝到磁盘上
形成
#sql***.MYD、#sql***.MYI(在5.6及更高的版本,临时表可以改成InnoDB引擎了,可以参考选项 default_tmp_storage_engine ) 建议: 创建适当的索引,并且适当加大 sort_buffer_size/tmp_table_size/max_heap_table_size
Creating sort index 当前的SELECT中需要用到临时表在进行ORDER BY排序 建议: 创建适当的索引
Creating tmp table 创建基于内存或磁盘的临时表,当从内存转成磁盘的临时表时,状态会变成:Copying to tmp table on disk 建议: 创建适当的索引,或者少用UNION、视图(VIEW)之类的
Reading
from
net 表示server端正通过网络读取客户端发送过来的请求 建议: 减小客户端发送数据包大小,提高网络带宽
/
质量
Sending data 从server端发送数据到客户端,也有可能是接收存储引擎层返回的数据,再发送给客户端,数据量很大时尤其经常能看见备注:Sending Data不是网络发送,是从硬盘读取,发送到网络是Writing to net 建议: 通过索引或加上LIMIT,减少需要扫描并且发送给客户端的数据量
Sorting result 正在对结果进行排序,类似Creating sort index,不过是正常表,而不是在内存表中进行排序 建议: 创建适当的索引
statistics 进行数据统计以便解析执行计划,如果状态比较经常出现,有可能是磁盘IO性能很差建议: 查看当前io性能状态,例如iowait
Waiting
for
global
read lock FLUSH TABLES WITH READ LOCK整等待全局读锁 建议: 不要对线上业务数据库加上全局读锁,通常是备份引起,可以放在业务低谷期间执行或者放在slave服务器上执行备份
Waiting
for
tables,Waiting
for
table flush FLUSH TABLES, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE, OPTIMIZE TABLE等需要刷新表结构并重新打开 建议: 不要对线上业务数据库执行这些操作,可以放在业务低谷期间执行
Waiting
for
lock_type lock
等待各种类型的锁: Waiting
for
event metadata lock Waiting
for
global
read lock
Waiting
for
schema metadata lock
Waiting
for
stored function metadata lock
Waiting
for
stored procedure metadata lock
Waiting
for
table level lock
Waiting
for
table metadata lock
Waiting
for
trigger metadata lock
建议:比较常见的是上面提到的
global
read lock以及table metadata lock,建议不要对线上业务数据库执行这些操作,可以放在业务低谷期间执行。如果是table level lock,通常是因为还在使用MyISAM引擎表,赶紧转投InnoDB引擎吧,别再老顽固了
|
最根本的原因是该表的平均行长度, 查看该表结构和数据,表结构设计问题。
select * from information_schema.tables where TABLE_NAME like '%mysites_vul%';
|
1
2
3
4
|
总结一下:
(
1
)表设计时需要考虑到这样的问题。像这种存放大数据的字段需要拆分到其他 表中。或者是考虑细化存储其中的数据
(
2
)select时,用哪个就查哪个。不要select没用的列,或者 Select
*
(
3
)只要固定几行数据就使用LIMIT
|
针对io和innodb
从系统方面入手的话,参考MySQL 调优基础(四) Linux 磁盘IO
https://www.2cto.com/database/201510/445288.html
iotop -k -u mysql (-k 表示KB,-u mysql表示显示mysql用户的所有进程的IO)
iostat -d -k 1 |grep sda10
iostat -d -x -k 1
可以看到磁盘的平均响应时间<5ms,磁盘使用率>80。磁盘响应正常,但是已经很繁忙了
因为磁盘IO的操作分成了4个层面,所以IO的优化也可以从这四个方面入手:
1)正对mysql系统的调优,还需要选择正确的IO调度算法,如果是SSD,选择NOOP调度算法,如果是磁盘,那么选择deadline调度算法;
2)针对mysql还显然可以通过maser-slave来读写分离进行磁盘IO优化。
3)另外增大内存,可以对更多的磁盘文件进行缓存,也能减轻IO压力。
4)还有文件系统的挂载选项 noatime, nodiratime也能减轻IO压力,另外选择正确的文件系统也能提高磁盘的tps. mysql数据库推荐使用XFS文件系统。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
|
目录
show engine innodb status\G; 解读
mysql关于IO
/
内存方面的一些优化
http:
/
/
www.cnblogs.com
/
chenpingzhao
/
p
/
5119161.html
原理解析的最清楚
https:
/
/
www.
2cto
.com
/
database
/
201510
/
445288.html
read
/
write
/
fsync与fread
/
fwrite
/
fflush的关系和区别
http:
/
/
blog.csdn.net
/
ybxuwei
/
article
/
details
/
22727565
read
/
write
/
fsync:
1.
linux底层操作;
2.
内核调用, 涉及到进程上下文的切换,即用户态到核心态的转换,这是个比较消耗性能的操作。
fread
/
fwrite
/
fflush:
1.
c语言标准规定的io流操作,建立在read
/
write
/
fsync之上
2.
在用户层, 又增加了一层缓冲机制,用于减少内核调用次数,但是增加了一次内存拷贝。
优化方向
Innodb
buffer
pool(内存):undo page
/
insert
buffer
page
/
adaptive
hash
index
/
index page
/
lock info
/
data dictionary
show engine innodb status\G;
mysql线程
FILE
IO
FILE
I
/
O
-
-
-
-
-
-
-
-
I
/
O thread
0
state: waiting
for
i
/
o request (insert
buffer
thread)
innodb后台所有线程
| thread
/
sql
/
main | BACKGROUND | YES |
| thread
/
innodb
/
io_handler_thread | BACKGROUND | YES |
IO线程分别是insert
buffer
thread、log thread、read thread、write thread。
InnoDB Plugin版本开始增加了默认IO thread的数量,默认的read thread和write thread分别增大到了
4
个,并且不再使用innodb_file_io_threads参数,而是分别使用innodb_read_io_threads和innodb_write_io_threads参数。
mysql访问文件流程
影响IO
/
内存的一些参数
innodb_flush_log_at_trx_commit 设置为
2
sync_binlog
大多数情况下,对数据的一致性并没有很严格的要求,所以并不会把 sync_binlog 配置成
1
,为了追求高并发,提升性能,可以设置为
100
或直接用
0
write
/
read thread
异步IO线程数
innodb_write_io_threads
=
16
innodb_read_io_threads
=
16
innodb_max_dirty_pages_pct
innodb_io_capacity
=
5000
innodb_flush_method
=
O_DIRECT(该参数需要重启mysql实例起效)
innodb_adaptive_flushing 设置为 ON (使刷新脏页更智能)
innodb_adaptive_flushing_method 设置为 keep_average
innodb_stats_on_metadata
=
OFF
innodb_change_buffering
=
all
innodb_old_blocks_time
=
1000
binlog_cache_size
show status like
'binlog_%'
;
select @@binlog_cache_size;
运行情况Binlog_cache_use 表示binlog_cache内存方式被用上了多少次,Binlog_cache_disk_use表示binlog_cache临时文件方式被用上了多少次
innodb_file_per_table
=
1
增加本地端口,以应对大量连接
echo ‘
1024
65000
′ >
/
proc
/
sys
/
net
/
ipv4
/
ip_local_port_range
增加队列的链接数
echo ‘
1048576
’ >
/
proc
/
sys
/
net
/
ipv4
/
tcp_max_syn_backlog
设置链接超时时间
echo ’
10
’ >
/
proc
/
sys
/
net
/
ipv4
/
tcp_fin_timeout
show engine innodb status\G; 解读
http:
/
/
www.cnblogs.com
/
ajianbeyourself
/
p
/
6941905.html
你可以通过修改innodb_sync_spin_loops的值,试着在空转等待与操作系统等待之间达成平衡,不要担心空转等待,除非你在一秒里看到几十万个空转等待。此时,你可以考虑performance_schema库或者show engine innodb mutex;查看下相关信息
146246831
OS
file
reads,
760501349
OS
file
writes,
247143684
OS fsyncs
#这行显示了读,写和fsync()调用执行的数目,在你的机器环境负载下这些绝对值可能会有所不同,因此更重要的是监控它们过去一段时间内是如何改变的。
Last checkpoint at
1351373900020
#这行显示了上一次检查点的位置(一个检查点表示一个数据和日志文件都处于一致状态的时刻,并且能用于恢复数据),如果上一次检查点落后与上一行太多,并且差异接近于事务日志文件的大小,Innodb会触发“疯狂刷”,这对性能而言非常糟糕。
0
pending log writes,
0
pending chkp writes
#这行显示了当前挂起的日志读写操作,可以将这行的值与第7部分FILE I/O对应的值做比较,以了解你的I/O有多少是由于日志系统引起的。
286879989
log i
/
o
's done, 15.92 log i/o'
s
/
second
#这行显示了日志操作的统计和每秒日志I/O数,可以将这行的值与第7部分FILE I/O对应的值做比较,以了解你的I/O有多少是由于日志系统引起的。
这部分显示了关于innodb缓冲池及其如何使用内存的统计
0
queries inside InnoDB,
0
queries
in
queue
#这行显示了innodb内核内有多少个线程,队列中有多少个线程,队列中的查询是innodb为限制并发执行的线程数量而不运行进入内核的线程。查询在进入队列之前会休眠等待
END OF INNODB MONITOR OUTPUT
#要注意了,如果看不到这行输出,可能是有大量事务或者是有一个大的死锁截断了输出信息
|
线上发现用pt-ioprofile --profile-pid=23949 --cell=sizes
内存占用90%,vm.swappiness=70情况下,有时候会大量写以下两个文件
ibdata
ib_logfile
可能是刷binlog的时候导致的
binlog cache 设置的太大了,没内存,然后vmstat ,si,so,bi,bo一直不为0
尽量分散io
innodb_flush_methodΪO_DIRECT
上面最常提到的fsync(int fd)函数,该函数作用是flush时将与fd文件描
述符所指文件有关的buffer刷写到磁盘,并且flush完元数据信息(比如修
改日期、创建日期等)才算flush成功。
echo 0 > /proc/sys/vm/swappiness
free -gt 查看内存使用情况,如果cached 和 used 相差特别大的话,基
本可确定系统发生内存泄露
它表示给CPU动态分配内存,可能会导致当某个CPU需要占用大量内存的时
候,会分配不了,然后就去占用SWAP的空间了
解决方式:5.6.27之后的版本,修改mysql里面的
innodb_numa_interleave配置。
如果版本比较低,则可以在mysql_safe的启动脚本中加上numactl –
interleave all 来解决
修改innodb_flush_method为O_DIRECT,这样InnoDB会绕过Cache来访问磁
盘
对于数据库来说,一个好的策略应该是诸如缓冲池这样的全局内存可以向
所有节点申请内存,而线程级别的内存还是坚持本地分配策略。
innodb-numa-interleave FALSE
MySQL5.7.9版本+,新增了参数innodb_numa_interleave。根据官方文档
的描述:当设置innodb_numa_interleave=1的时候,对于mysqld进程的
numa内存分配策略设置为MPOL_INTERLEAVE,而一旦Innodb buffer pool
分配完毕,则策略重新设置回MPOL_DEFAULT。当然这个参数是否生效,必
须建立在mysql是在支持numa特性的linux系统上编译的基础上。
在MySQL5.7.17版本+, CMake编译软件新增了WITH_NUMA参数,可以在支持
numa特性的linux系统上编译mysql。
在MySQL进程启动前,使用sysctl -q -w vm.drop_caches=3清空文件缓存所占用的空间
numa原理
https://www.cnblogs.com/cenalulu/p/4358802.html
1.判断是否存在numa陷阱
是否开启 grep -i numa /var/log/dmesg
numastsat,lscpu
当发现numa_miss数值比较高时,说明需要对分配策略进行调整。例如将指定进程关联绑定到指定的CPU上,从而提高内存命中率
内核参数overcommit_memory :
它是 内存分配策略
可选值:0、1、2。
0:表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1:表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
2:表示内核允许分配超过所有物理内存和交换空间总和的内存
内核参数zone_reclaim_mode:
可选值0、1
a、当某个节点可用内存不足时:
1、如果为0的话,那么系统会倾向于从其他节点分配内存
2、如果为1的话,那么系统会倾向于从本地节点回收Cache内存多数时候
b、Cache对性能很重要,所以0是一个更好的选择
mongodb的NUMA问题
mongodb日志显示如下:
WARNING: You are running on a NUMA machine.
We suggest launching mongod like this to avoid performance problems:
numactl –interleave=all mongod [other options]
解决方案,临时修改numa内存分配策略为 interleave=all (在所有node节点进行交织分配的策略):
1.在原启动命令前面加numactl –interleave=all
如# numactl --interleave=all ${MONGODB_HOME}/bin/mongod --config conf/mongodb.conf
2.修改内核参数
echo 0 > /proc/sys/vm/zone_reclaim_mode ; echo "vm.zone_reclaim_mode = 0" >> /etc/sysctl.conf
swap占用过高临时解决方案
http://blog.csdn.net/smooth00/article/details/72725941
O_DIRECT 由于没有操作系统缓冲的作用,对于数据写入磁盘的速度会降低明显(表现为写入响应时间的拉长) 稳定性确实比较高,在大并发量读写操作中,能够较长时间运行
默认datasync模式,整体表现较好 拥有了高性能,但不会有高稳定性 定时的对操作系统进行echo 3 >/proc/sys/vm/drop_caches,清理一下OS缓存
sysctl -w vm.swappiness=10