
NLP-深度学习时代之前:
在深度学习来临之前的日子里,在自然语言处理算法(NLP)领域出乎意料地有许多相对成功的经典挖掘算法,对于像垃圾邮件过滤或词类标记问题可以直接使用可解释的模型来解决它们。
但并非所有问题都可以通过这种方式解决,简单的模型不能充分捕捉语境或反语等细微语言要点。基于总体概括的算法(例如,文字袋(bag-of-words))证明了不足以捕捉文本的连续性,而n-gram努力克服这些困难,但受到维度灾难的严重影响。即使是基于HMM的模型也无法克服这些问题,因为它们是无记忆。
第一个突破——Word2Vec:
语言分析的主要挑战之一是将文本转换为数字输入的方式,只有完成这一步才能使得建模变得可行。在计算机视觉任务中这不是问题,因为在图像中,每个像素都用三个数字来表示,这三个数字描绘了三种基色的饱和度。多年来,研究人员尝试了大量算法来寻找所谓的嵌入,通常指的是将文本表示为矢量。起初,这些方法中的大多数是基于计数单词或短序列的单词(n-gram)。
解决这个问题的最初方法是单热编码,其中来自词汇表的每个单词被表示为仅具有一个非零的唯一二进制向量。一个简单的概括是编码n-gram(连续n个单词的序列)而不是单个单词。这种方法的主要缺点是非常高的维度,每个矢量都有词汇的大小(或者在n-gram情况下甚至更大),这使得建模变得困难。这种方法的另一个缺点是缺乏语义信息,这意味着代表单个单词的所有矢量是等距的。在这种嵌入中,空间同义词就像完全不相关的单词一样远离彼此。使用这种类型的词语表达可能会使得任务变得更加困难,因为它会迫使你的模型记忆特定的单词而不是试图捕获语义。

自然语言处理算法的第一个重大飞跃发生在2013年,随着Word2Vec的推出——一种专门用于生成嵌入的基于神经网络的模型。想象一下,从一系列单词开始,去除中间单词,并通过查看上下文单词(例如CBOW的连续袋)来预测它。该模型的另一个版本是要求预测中间词(skip-gram)的上下文)。这个想法是违反直觉的,因为这样的模型可能被用在信息检索任务中(某个单词突然不见了,问题是使用它的上下文来预测它),但这种情况很少。相反,事实证明,如果随机初始化嵌入,然后在训练CBOW或skip-gram模型时将它们用作可学习参数,则可以获得可用于任何任务的每个单词的矢量表示。通过这种方式,你可以避免记忆特定的词语,而且可以传达不是由单词本身解释的单词的语义含义,而是通过其上下文来解释。
在2014年斯坦福大学的研究小组挑战Word2Vec的竞争方案是:手套(GloVe)。他们提出了一种不同的方法,认为在矢量中对单词的语义含义进行编码的最佳方式是通过全局词共现矩阵,而不是像Word2Vec中的局部共现。正如你在图2中看到的,与场景词相比,同现概率的比率能够区分单词。大约1时,两个目标单词经常或很少与上下文单词共同出现。只有当上下文词与目标词中的一个共同出现时,比例要么非常小,要么非常大。这是GloVe背后的力量,确切的算法涉及将单词表示为向量,其方式是它们的差乘以上下文词语等于共现概率的比率。
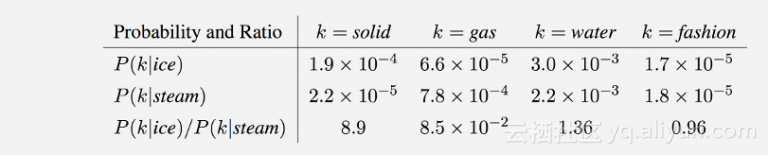
进一步改进:
尽管新的强大的Word2Vec提高了许多经典算法的性能,但仍然需要能够捕获文本(长期和短期)中的顺序的解决方案。这个问题的第一个解决方案是所谓的递归神经网络(RNN)。RNN利用文本数据的时间特性,通过将字串馈入网络,同时使用存储在隐藏状态中的先前文本的信息。
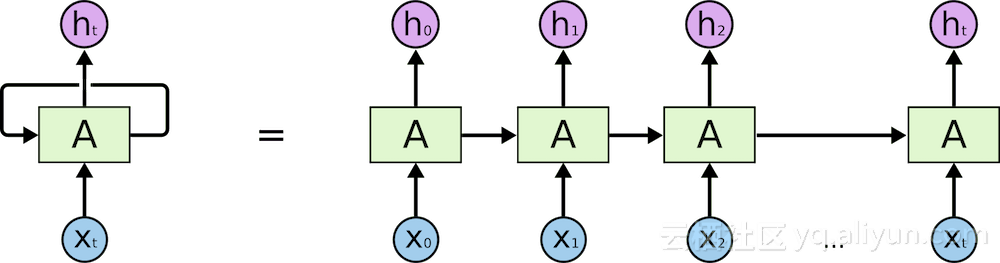
这个网络在处理局部时间依赖性方面非常有效,但是当呈现长序列时表现很差。这种失败是由于在每个时间步骤之后,隐藏状态的内容被网络的输出覆盖。为了解决这个问题,计算机科学家和研究人员设计了一种新的RNN架构,称为长期短期记忆(LSTM)。LSTM通过在网络中引入一个称为存储单元的额外单元来处理这个问题,这是一种负责存储长期依赖性的机制,以及负责控制单元中信息流的多个门。这是如何工作的呢?在每个时间步骤,忘记门生成一个分数,表示要忘记的存储单元内容的数量。接下来,输入门决定将多少输入添加到存储器单元的内容中。最后,输出门决定将多少存储单元内容生成为整个单元的输出。所有的门都像有规律的神经网络层一样,具有可学习的参数,这意味着随着时间的推移,网络会适应并更好地决定与任务相关的输入类型以及可以忘记哪些信息。
自20世纪90年代后期以来,LSTM实际上已经存在,但是它们在计算和记忆方面都非常昂贵,所以直到最近,由于硬件的显着进步,在合理的时间内训练LSTM网络变得可行。目前,存在许多LSTM的变体,例如mLSTM,其引入了对输入GRU的乘法依赖性,由于存储单元更新机制的智能化简化,显着减少了可训练参数的数量。
不久之后,这些模型的性能明显优于传统方法,但研究人员渴望获得更多。他们开始研究卷积神经网络在计算机视觉领域取得了不错的成功,并想知道这些概念是否可以纳入NLP。它很快证明,用一维滤波器(处理一个小句子)简单地替换2D滤波器(处理图像的一小部分,例如3×3像素的区域)使其成为可能。与2D CNN类似,这些模型随着第一层处理原始输入和其前一层的所有后续图层处理输出而变得更深入,学习越来越多的抽象特征。当然,一个单词嵌入(嵌入空间通常大约300个维度)比单个像素承载更多的信息,这意味着没有必要像图像一样使用如此深的网络。你可能会认为它是嵌入式应用程序应该在前几层完成的,所以它们可以被跳过。这些直觉在各种任务的实验中被证明是正确的。1D CNN比RNN更轻更精确,并且由于更容易的并行化,所以可以训练更快的数量级。
尽管CNN做出了令人难以置信的贡献,但这些网络仍然存在一些缺点。在经典的设置中,卷积网络由多个卷积层组成,负责创建所谓的特征映射和将其转换为预测的模块。特征映射本质上是从文本(或图像)中提取的高级特征,用于保存它在文本(或图像)中出现的位置。预测模块在特征映射上执行聚合操作,或者忽略特征的位置(完全卷积网络)或学习特定特征最经常出现的位置(完全连接的模块)。这些方法的问题出现在例如问题回答中任务,其中模型应该给出文本和问题的答案。在这种情况下,如经典预测模块所做的那样,将文本所携带的所有信息存储在单个文本中是困难的并且通常是不必要的。相反,我们希望将重点放在文本的粒子部分,其中为特定问题存储了最关键的信息。注意机制解决了这个问题,该机制根据基于输入的相关内容权衡文本的部分内容。这种方法也被发现对于文本分类或翻译等经典应用是非常有用。OpenAI联合创始人兼研究总监llya Sutskever在接受采访时表示:最近推出的注意机制使我非常兴奋,因为它简单并且它工作得很好。虽然这些模式是新的,但我相信他将在未来的深度学习中发挥非常重要的作用。
典型的NLP问题:
有很多语言任务,对人类来说简单,但对于一台机器来说却是非常困难的。这种困难主要是由于讽刺和成语等语言上的细微差别。让我们来看看研究人员是如何试图解决的一些NLP领域:
最常见也可能是最简单的:情绪分析。它本质上决定了演讲者/作家对特定主题的态度或情感反应,情绪可能是积极的,中性的和消极的。看看这篇关于使用深度卷积神经网络来检测推文中的情绪的文章。

另外一个案例就是文档分类,我们不是将三种可能的标志之一分配给每篇文章,而是解决普通的分类问题。根据深度学习算法的全面比较,可以肯定地说,深度学习是进行强类型分类的方式。
机器翻译的自然语言处理算法:
我们转向真正的具有挑战的领域:机器翻译。机器翻译长时间以来一直是一个严峻的挑战。知道这一点非常重要,这与我们前面讨论的两个完全不同。对于这项任务,我们需要一个模型来预测单词序列,而不是标签。机器翻译可以说明深度学习的重要性,因为它在顺序数据方面已经取得了难以置信的突破。在这篇博客文章中,它们利用Recurrent Neural Networks(RNN)解决翻译问题,在这篇文章中,你可以了解他们如何达到最新的结果。
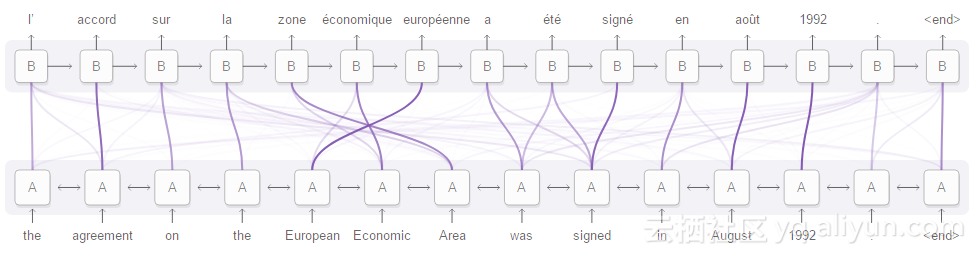
假设你需要一个自动的文本摘要模型,并且你希望它只提取文本中最重要的部分,同时保留所有的含义。这需要一种能够理解整个文本的算法,同时关注具有大部分含义的特定部分。这个问题可以通过前面提到的注意机制来解决,它可以作为模块在端到端解决方案中引入。
自然语言生成:
你可能已经注意到所有上述任务都有一个共同点。对于情绪分析,文章是分为积极的,消极的或中立的。在文档分类中,每个例子都属于一个类。这意味着这些问题属于监督式学习的问题。但,当你想让你的模型生成文本时,事情会变得棘手。
Andrej Karpathy在其优秀的博客文章中详细介绍了RNN如何解决这个问题。他展示了一个例子,用于生成新的莎士比亚小说或如何生成似乎是由人类编写的源代码,实际上他并没有做任何事情。这些都是很好的例子,这可以说明这种模型是非常强大的,但也有这些算法的真实商业应用。想象一下,你希望以广告为目标,并且不希望它们通过将相同的消息复制并粘贴到每个人而变得通用。编写数千个不同版本的程序绝对是不可能的,因此一个广告生成工具就可能派上用场。
RNNs在字符级别生成文本方面表现得相当好,这意味着网络可以预测生成连续字母(也包括空格,标点符号等)。然而,事实证明,这些模型生成声音是非常困难的。这是因为要产生一个单词只需要几个字母,但是产生高质量声音时,即使是16kHz采样,也会有数百甚至数千个点形成口语单词。研究人员再一次转向CNN,并取得了巨大成功。DeepMind的数学家开发了一个非常复杂的卷积生成WaveNet模型,它通过使用所谓的attrous卷积来处理非常大的(实际原始输入的长度)问题。这是目前最先进的模型,其性能明显优于其他所有基线,但使用起来非常昂贵,即需要90秒才能生成1秒的原始音频。这意味着还有很多需要改进的空间,但这绝对是在正确的道路上。
概括:
深度学习最近出现在NLP中,由于计算问题,我们需要更多地了解神经网络以了解它们的能力,这样才能更好的解决NLP问题。
本文由阿里云云栖社区组织翻译。
文章原标题《Natural Language Processing Algorithms (NLP AI)》
作者:sigmoidal
译者:虎说八道,审校:。
文章为简译,更为详细的内容,请查看原文


