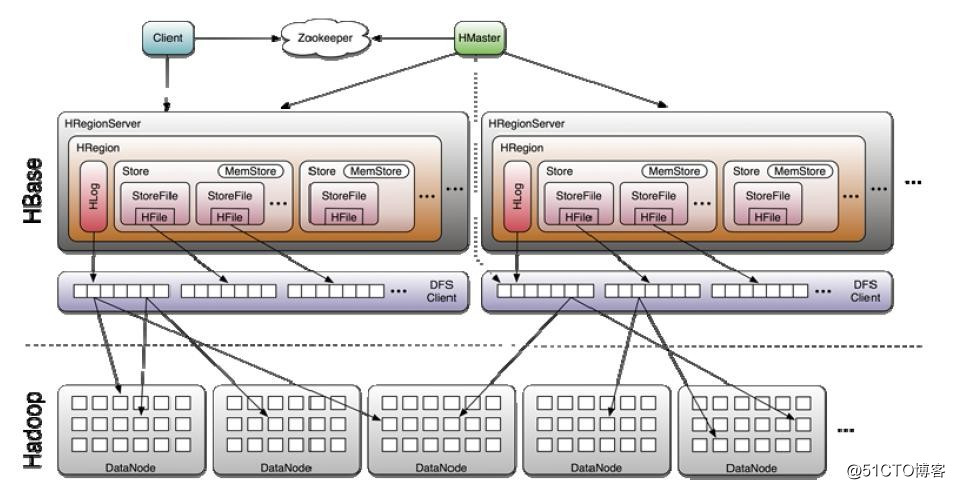
Hbase 写数据流程
- 1、 client 向 hregionserver 发送写请求。
- 2、hregionserver 将数据写到 hlog (write ahead log )。为了数据的持久化和恢复。
- 3、 hregionserver 将数据写到内存 (memstore)
- 4、 反馈 client 写成功。
数据 flush 过程
- 1、 当 memstore 数据达到阈值(默认是 64M),将数据刷到硬盘,将内存中的数据删除,同时删除 hlog 中的历史数据。
- 2、 并将数据存储到 hdfs 中。
- 3、 在 hlog 中做标记点。
数据合并过程
- 1、 当数据达到 4 块, hmaster 将数据块加载到本地,进行合并
- 2、 当合并的数据超过 256M,进行拆分,将拆分后的 region 分配给不同的 hregionserver 管理
- 3、 当 hregionser 宕机后,将 和regionserver 上的 hlog 拆分,然后分配给不同的 hregionserver 加载,修改 .META。
- 4、 注意:hlog 会同步到 hdfs
Hbase 读数据流程
- 1、 通过 zookeeper 和 -ROOT-.META。表定位 hregionserver 。
- 2、 数据从内存和硬盘合并后返回 client
- 3、 数据块会缓存
hmaster 的职责
- 1、 管理用户对 table 的增、删、改、查等操作。
- 2、 记录 region 在哪台 HRegion Server 上
- 3、 在 Region Split 后,负责新 Region 的分配
- 4、 新机器加入时,管理 HRegion Server 的负载均衡,调整 Region 分布
- 5、 在 HRegion Server 宕机后,负责失效 HRegion Server 上的 Region 迁移。
hmaster 的职责
- 1、 HRegion Server主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBASE中最核心的模块。
- 2、 HRegion Server管理了很多table的分区,也就是region。
client职责
- 1、 HBASE Client使用HBASE的RPC机制与HMaster和RegionServer进行通信
- 2、 管理类操作:Client与HMaster进行RPC;
- 3、 数据读写类操作:Client与HRegionServer进行RPC。
hbase依赖zookeeper
1、保存Hmaster的地址和backup-master地址
hmaster:
- a)管理HregionServer
- b)做增删改查表的节点
- c)管理HregionServer中的表分配
2、保存表-ROOT-的地址
hbase默认的根表,检索表。
3、HRegionServer列表
表的增删改查数据。
和hdfs交互,存取数据。
Hbase 命令
| 名称 | 命令表达式 |
|---|---|
| 创建表 | create '表名', '列族名1','列族名2','列族名N' |
| 查看所有表 | list |
| 描述表 | describe ‘表名’ |
| 判断表存在 | exists '表名' |
| 判断是否禁用启用表 | is_enabled '表名'; is_disabled ‘表名’ |
| 添加记录 | put ‘表名’, ‘rowKey’, ‘列族 : 列‘ ,'值' |
| 查看记录rowkey下的所有数据 | get '表名','rowKey' |
| 查看表中的记录总数 | count '表名' |
| 获取某个列族 | get '表名','rowkey','列族' |
| 获取某个列族的某个列 | get '表名','rowkey','列族:列’ |
| 删除记录 | delete ‘表名’ ,‘行名’ , ‘列族:列' |
| 删除整行 | deleteall '表名','rowkey' |
| 删除一张表 | 先要屏蔽该表,才能对该表进行删除。第一步 disable ‘表名’ ,第二步 drop '表名' |
| 清空表 | truncate '表名' |
| 查看所有记录 | scan "表名" |
| 查看某个表某个列中所有数据 | scan "表名" , {COLUMNS=>'列族名:列名'} |
| 更新记录 | 就是重写一遍,进行覆盖,hbase没有修改,都是追加 |
到这里 hbase 的基本原理,和使用命令就写完了。
本文转自 SimplePoint 51CTO博客,原文链接:http://blog.51cto.com/2226894115/2061521,如需转载请自行联系原作者