sql执行机制
1.对于普通的sql语句只有where条件的执行机制
首先我们要了解一下SQL语句的执行过程。SELECT字段FROM表名WHERE条件表达式那它们是按什么顺序执行呢?
分析器会先看语句的第一个词,当它发现第一个词是SELECT关键字的时候,它会跳到FROM关键字,然后通过FROM关键字找到表名并把表装入内存。接着是找WHERE关键字,如果找不到则返回到SELECT找字段解析,如果找到WHERE,则分析其中的条件,完成后再回到SELECT分析字段。最后形成一张我们要的虚表。其它的先不说了,只说WHERE。WHERE关键字后面的是条件表达式。
如果学过C语言等编程语言就会知道,条件表达式计算完成后,会有一个返回值,即非0或0,非0即为真(true),0即为假(false)。同理WHERE后面的条件也有一个返回值,真或假,来确定接下来执不执行SELECT。
例:SELECT*FROM STUDENT WHERE SNO='1';分析器先找到关键字SELECT, 然后跳到FROM关键字将STUDENT表导入内存,并通过指针p1找到第一条记录,接着找到WHERE关键字计算它的条件表达式,如果为真那么把这条记录装到一个虚表当中,p1再指向下一条记录。如果为假那么p1直接指向下一条记录,而不进行其它操作。一直检索完整个表,关把虚表返回给用户。
2.对于嵌套的sql语句
再说EXISTS谓词,EXISTS谓词也是条件表达式的一部分。当然它也有一个返回值(true或false)。例:SELECT Sname FROM Student WHERE EXISTS(SELECT*FROM SC WHERE SC.Sno=Student.Sno AND SC.Cno='1');这是一个SQL语句的嵌套使用,但和上面说的SQL语句的执行过程也是相同的。嵌套的意思也就是说当分析主SQL语句(外面的那个SELECT,我们权且先这么叫它)到WHERE关键字的时候,又进入了另一个SQL语句中。那么也就是说,分析器先找到表Student并装入内存,一个指针(例如p1)指向Student表中的第一条记录。然后进入WHERE里分析里面的SQL语句,再把SC表装入内存,另一个指针(例如p2)指向SC表中的第一条记录,分析WHERE后面的条件表达式,依次进行分析,最后分析出一个虚表2,也就变成SELECT Sname FROM Student WHERE EXISTS虚表2如果虚表为空表,EXISTS虚表2也就为false,不返回到SELECT,而p1指向下一条记录。
3.示列分析
select distinct(a.s_cid),SUM(N_JE),count(a.S_CID) from zw_yingyez a inner join KG_BiaoKaXX b on a.S_CID=b.S_CID
where a.I_XiaoZhang=0
group by a.S_CID
having SUM(N_JE)>100
order by a.S_CID
执行顺序:
(8) SELECT (9) DISTINCT (11) <TOP_specification> <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) WITH {CUBE | ROLLUP}
(7) HAVING <having_condition>
(10) ORDER BY <order_by_list>
以上每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只有最后一步生成的表才会会给调用者。如果没有在查询中指定某一个子句,将跳过相应的步骤。
逻辑查询处理阶段简介:
1、 FROM:对FROM子句中的前两个表执行笛卡尔积(交叉联接),生成虚拟表VT1。
2、 ON:对VT1应用ON筛选器,只有那些使为真才被插入到TV2。
3、 OUTER (JOIN):如果指定了OUTER JOIN(相对于CROSS JOIN或INNER JOIN),保留表中未找到匹配的行将作为外部行添加到VT2,生成TV3。如果FROM子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1到步骤3,直到处理完所有的表位置。
4、 WHERE:对TV3应用WHERE筛选器,只有使为true的行才插入TV4。
5、 GROUP BY:按GROUP BY子句中的列列表对TV4中的行进行分组,生成TV5。
6、 CUTE|ROLLUP:把超组插入VT5,生成VT6。
7、 HAVING:对VT6应用HAVING筛选器,只有使为true的组插入到VT7。
8、 SELECT:处理SELECT列表,产生VT8。
9、 DISTINCT:将重复的行从VT8中删除,产品VT9。
10、ORDER BY:将VT9中的行按ORDER BY子句中的列列表顺序,生成一个游标(VC10)。
11、TOP:从VC10的开始处选择指定数量或比例的行,生成表TV11,并返回给调用者。
总结 :
执行顺序
FROM
JOIN
WHERE
GROUP
HAVING
SELECT
ORDER
SQL是按照这个顺序来的
Sql语句优化
1.WHERE后面的条件顺序影响
WHERE子句后面的条件顺序对大数据量表的查询会产生直接的影响,如
Select * from zl_yhjbqk where dy_dj = '1KV以下' and xh_bz=1
Select * from zl_yhjbqk where xh_bz=1 and dy_dj = '1KV以下'
以上两个SQL中dy_dj(电压等级)及xh_bz(销户标志)两个字段都没进行索引,所以执行的时候都是全表扫描,如果dy_dj = '1KV以下'条件在记录集内比率为99%,而xh_bz=1的比率只为0.5%,在进行第一条SQL的时候99%条记录都进行dy_dj及xh_bz的比较,而在进行第二条SQL的时候0.5%条记录都进行dy_dj及xh_bz的比较,以此可以得出第二条SQL的CPU占用率明显比第一条低。所以尽量将范围小的条件放在前面。
2.使用in时,在IN后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,这样可以减少判断的次数
3. exists 和 in 的效率 当两个表大小差不多的时候,效率差不多,但是当一个表大一个表小的时候,子查询表大的用exists,子查询表小的用in
in是把外表和内表作hash连接,而exists 是对外表作loop循环,每次loop循环再对内表进行查询。
列于表A(小表),表B(大表)
select * from A where cc in(select cc from B) 效率低
select * from A where where exists (select cc from B where cc=A.cc) 效率高
4.效率对比
createtime between '2011-7-4 0:00:00' AND '2011-8-4 23:59:59'
convert(varchar(10),createtime,112) between '20110704' and '20110804'
sql执行机制
2016-05-19
1705
版权
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《
阿里云开发者社区用户服务协议》和
《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写
侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介:
特别说明:尊重作者的劳动成果,转载请注明出处哦~~~

目录
相关文章
|
SQL
Java
数据库连接
springboot-maven项目+jpa 运行过程中执行resources下sql脚本文件-ClassPathResource和ScriptUtils.executeSqlScript的使用
springboot-maven项目+jpa 运行过程中执行resources下sql脚本文件-ClassPathResource和ScriptUtils.executeSqlScript的使用
487
0
0
|
SQL
存储
缓存
|
SQL
Java
|
SQL
IDE
开发工具
|
SQL
Java
关系型数据库
|
SQL
存储
算法
|
SQL
存储
关系型数据库
|
SQL
|
SQL
存储
缓存
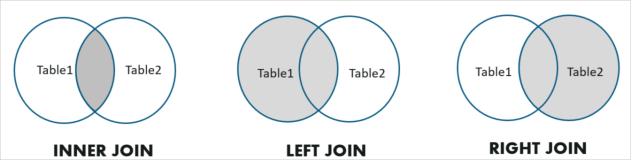
SQL调优指南—SQL调优进阶—JOIN优化和执行
本文主要介绍如何使用JOIN。JOIN将多个表以某个或某些列为条件进行连接操作而检索出关联数据的过程,多个表之间以共同列而关联在一起。
112
0
0
|
SQL
关系型数据库
开发者
热门文章
最新文章
1
一文搞懂SQL优化——如何高效添加数据
2
Seata常见问题之服务端 error日志没有输出,客户端执行sql报错如何解决
3
【软件设计师备考 专题 】数据库语言(SQL)
4
【SQL server】玩转SQL server数据库:第三章 关系数据库标准语言SQL(二)数据查询
5
【SQL server】玩转SQL server数据库:第二章 关系数据库
6
SQL常见面试题总结2
7
NL2SQL进阶系列(5):论文解读业界前沿方案(DIN-SQL、C3-SQL、DAIL-SQL)、新一代数据集BIRD-SQL解读
8
NL2SQL实践系列(2):2024最新模型实战效果(Chat2DB-GLM、书生·浦语2、InternLM2-SQL等)以及工业级案例教学
9
数据库管理与电脑监控软件:SQL代码优化与实践
10
SQL,Group By 真扎心,原来是这样