背景:
图数据库对于表现和遍历复杂的实体之间关系是很有效果的。而这些在传统的关系型数据库中尤其是对于报表而言很难实现。如果把传统关系型数据库比做火车的话,那么到现在大数据时代,图数据库可比做高铁。它已成为NoSQL中关注度最高,发展趋势最明显的数据库。伴随SQL Server 2017的出现,在SQL Server上面有了专门的图数据库,那么以往需要其他数据库或者效率低下地处理这些工作,现在是否可以让我们容易的实现了那?
接下来我会用三个篇幅介绍SQLServer 图数据库以及它的优缺点。
介绍:
简单定义:图数据库是NoSQL数据库的一种类型,它应用图形理论存储实体之间的关系信息。图形数据库是一种非关系型数据库,它应用图形理论存储实体之间的关系信息。最常见例子就是社会网络中人与人之间的关系。关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷。
SQL Server 2017将带来新的功能之一就是图数据库。图数据库不像关系型数据库在一张“图”内将数据表现为节点,边和属性,而是一种抽象的数据类型,通过一组顶点节点、点和边来表现关系和连接,就像一个缠结的渔网。使我们用简单的方式来表现和遍历实体间的关系。图对象被用来表示复杂的关系。一层就是一个特定的图,记录如论坛帖子和回复之间的关系,以及人与人之间的关系。多层有一个根节点(例如,论坛中的帖子和回复),但是多个图不一定有根节点(例如人们之间的关系)
本文中,我们一起使用一个论坛数据例子,使用新型的图模型。也会比较图和关系型模型的查询复杂度。
演示环境
SQL Server 2017 CTP 2.1下载地址: https://www.microsoft.com/en-us/sql-server/sql-server-2017
使用SSMS 17.0,下载地址: https://docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
创建模型
下图是一个关系型实体的模型,以此作为比较:
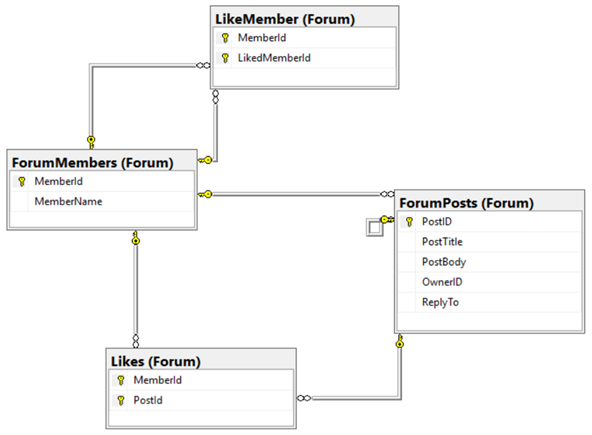
如果想要比较,可以使用下面的脚本创建,或者直接创建图模型。但是,需要用SSMS创建一个新的数据库“GraphExample”。代码如下:
create database GraphExample
go
-- Trying an entire graph model
use GraphExample
go
create schema Forum
go
create table Forum.ForumMembers
(MemberId int not null primary key Identity(1,1),
MemberName varchar(100))
go
create table Forum.ForumPosts
([PostID] int not null primary key,
PostTitle varchar(100),
PostBody varchar(100),
OwnerID int,
ReplyTo int)
go
Create table Forum.Likes
(MemberId int,
PostId int)
go
create table Forum.LikeMember
(MemberId int,
LikedMemberId int)
go
INSERT Forum.ForumMembers values('Mike'),('Carl'),('Paul'),('Christy'),('Jennifer'),('Charlie')
go
INSERT INTO [Forum].[ForumPosts]
(
[PostID]
,[PostTitle]
,[PostBody],OwnerID, ReplyTo
)
VALUES
(4,'Geography','Im Christy from USA',4,null),
(1,'Intro','Hi There This is Carl',2,null)
INSERT INTO [Forum].[ForumPosts]
(
[PostID]
,[PostTitle]
,[PostBody],OwnerID, ReplyTo
)
VALUES
(8,'Intro','nice to see all here!',1,1),
(7,'Intro','I''m Mike from Argentina',1,1),
(6,'Re:Geography','I''m Mike from Argentina',1,4),
(5,'Re:Geography','I''m Jennifer from Brazil',5,4),
(3,'Re: Intro','Hey Paul This is Christy',4,2),
(2,'Intro','Hello I''m Paul',3,1)
go
INSERT Forum.Likes VALUES (1,4),
(2,7),
(2,8),
(2,2),
(4,5),
(4,6),
(1,2),
(3,7),
(3,8),
(5,4)
go
Insert Forum.LikeMember VALUES (2,1),
(2,3),
(4,1),
(4,5)
图模型
图模型的计划与关系型模型完全不同。表在图模型中可能是边或者节点。我们需要决定哪些表是边,哪些表是节点。
图具有如下特征:
-
- 包含节点和边;
- 节点上有属性(键值对);
- 边有名字和方向,并总是有一个开始节点和一个结束节点;
- 边也可以有属性。
下图表现了图模型:
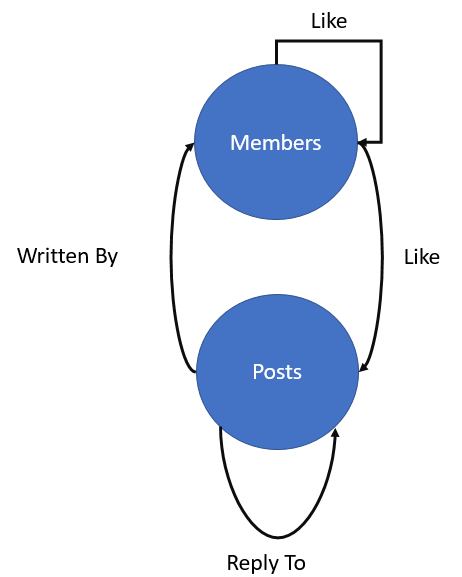
如图所示,在模型中节点和边很容易确定:逻辑模型中的所有实体就是节点,而所有关系就是边。这里有“Posts”和“Members”两个实体, ‘Reply To’, ‘Like’ 和 ‘Written By’三个边。
注意
节点和边不过是带有特殊字段的表。没有任何限制禁止我们创建常规的表之间的关系,以便将模型转化为关系和图模型的组合。
例如,‘Written By’ 是 ‘Posts’ 和 ‘Members’的关系,可以转化为一个一对多的关系。通过创建一个边的关系表,我们可以用常规的关系表来表现所谓的图模型中的表。也就是组合模式了。
当我们创建一个根节点实体,这个实体接收一个叫做‘$node_id’的计算字段。我们可以使用这个字段作为主键,SQL Server 允许计算字段作为主键:如果这个主键是一个JSON字段,就不适合作为主键了。因此我们的节点必须包含两个键:业务键,整型字段,以及‘$node_id’ 键,包含整型字段自增长的JSON键。
下面为节点实体的脚本:
Use GraphExample
go
CREATE TABLE [dbo].[ForumMembers](
[MemberID] [int] IDENTITY(1,1) NOT NULL,
[MemberName] [varchar](100) NULL
)
AS NODE
GO
CREATE TABLE [dbo].[ForumPosts](
[PostID] [int] NULL,
[PostTitle] [varchar](100) NULL,
[PostBody] [varchar](1000) NULL
)
AS NODE
注意
在创建对象后,在对象浏览器中检查对象。或许此时注意到一个新的文件夹在‘Tables’文件夹里面叫做‘Graph’。同时也注意到自增字段的名字,尽管我们可以用简称来引用这些字段,例如$node_id,但是真实的字段名称包含了GUID。这个简称字段其实是一个假的名字,称之为“伪列”(可以理解为别名),我们能在查询中使用。
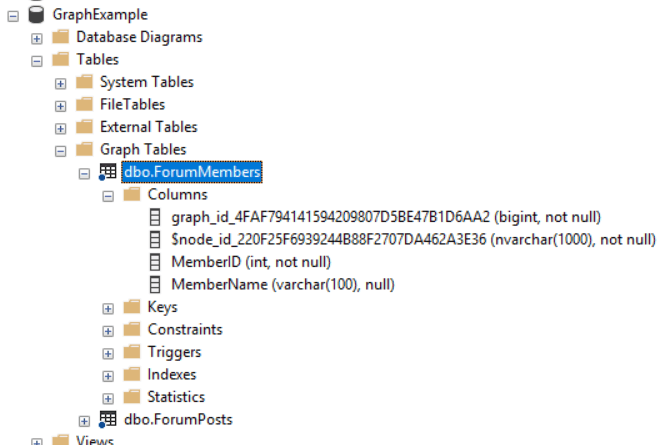
如图,插入数据到节点表:我们只需要忽略$node_id,写出插入其他字段的语句即可,语句如下:
INSERT ForumMembers values ('Mike'),('Carl'),('Paul'),('Christy'),('Jennifer'),('Charlie')
INSERT INTO [dbo].[ForumPosts]
(
[PostID]
,[PostTitle]
,[PostBody]
)
VALUES
(8,'Intro','nice to see all here!'),
(7,'Intro','I''m Mike from Argentina'),
(6,'Re:Geography','I''m Mike from Argentina'),
(5,'Re:Geography','I''m Jennifer from Brazil'),
(4,'Geography','Im Christy from USA'),
(3,'Re: Intro','Hey Paul This is Christy'),
(1,'Intro','Hi There This is Carl')
(2,'Intro','Hello I''m Paul')
使用查询语句可以看到ForumPosts表的结果。你会发现$node_id字段,是一个JSON字段包含了实体类型和一个自增整型ID,它就是自增长ID。

创建边表
这个操作很简单,边表有属性,属性就是表中的常规字段。脚本如下:
Create table dbo.[Written_By] as EDGE CREATE TABLE [dbo].[Likes] AS EDGE CREATE TABLE [dbo].[Reply_To] AS EDGE
每个边表有三个伪列,我们需要处理:
- $edge_id: 边记录的ID
- $from_id:在边中记录的节点ID
- $to_id:在边中记录的其他节点ID
注意这个定义,最为重要的一点就是:我们需要用一种合乎逻辑的方式定义 $to_id and $from_id 字段对于每条边意味着什么?你可以观察之前定义的边表如何定义的边,这是一种双向的合理选择,使得我们更容易使用和理解。
以下是我们的合理定义:
Written_By:
$from_id will be the post
$to_id will be the member
Likes:
$from_id will be who likes
$to_id will be who/what is liked
Reply_To:
$from_id will be the reply to the main post
$to_id will be the main post
这些选择没有技术限制,但我们需要在插入新记录时保留它们,永远不要混淆关系的每一方的含义。
注意
除了三个伪列以外,所有的表表都有额外字段,并且全是隐藏字段。我们可以在字段属性中看到隐藏的定义,并且这些隐藏字段不会出现在查询结果中。


插入边记录
插入边表的语句需要边的两端ID,$From_id and $To_id。这些字段需要用$node_id的值来填充。例如,对于一个帖子的成员,‘Written_By’包含post 的$node_id 作为$From_id 并且有member的$node_id作为$To_id字段。
下面是插入语句:
Insert into Written_By ($to_id,$from_id) values ( (select $node_id from dbo.ForumMembers where MemberId= 1 ), (select $node_id from dbo.ForumPosts where PostID=8 ) ), ( (select $node_id from dbo.ForumMembers where MemberId=1 ), (select $node_id from dbo.ForumPosts where PostID=7 ) ), ( (select $node_id from dbo.ForumMembers where MemberId= 1 ), (select $node_id from dbo.ForumPosts where PostID= 6) ), ( (select $node_id from dbo.ForumMembers where MemberId=5 ), (select $node_id from dbo.ForumPosts where PostID=5 ) ), ( (select $node_id from dbo.ForumMembers where MemberId=4 ), (select $node_id from dbo.ForumPosts where PostID=4 ) ), ( (select $node_id from dbo.ForumMembers where MemberId=3 ), (select $node_id from dbo.ForumPosts where PostID=3 ) ), ( (select $node_id from dbo.ForumMembers where MemberId=3 ), (select $node_id from dbo.ForumPosts where PostID=1 ) ), ( (select $node_id from dbo.ForumMembers where MemberId=3 ), (select $node_id from dbo.ForumPosts where PostID=2 ) )
注意
这样插入是不是感觉很麻烦?未来我们可以使用一个对象框架用以支持图对象,目前还不支持这个功能。
插入Reply_To脚本如下:
INSERT Reply_To ($to_id,$from_id)
VALUES
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 6)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 1),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 1),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 1),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 5)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2),
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 3))
最后,再插入Likes:
INSERT Likes ($to_id,$from_id)
VALUES
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 5),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 6),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 3)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 3)),
((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4),
(SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 5))
Likes 边很好的说明了边的功能作用。仅仅插入几个menbers和post表的关系,但是我们可以确定在应用中成员也可能喜欢另一个成员。当然,我们也能用这个边去关联这个成员和其他成员的关系。在关系型模型中我们需要两个表完成这个操作,在图数据库我们只需要一个边。
下面我们在论坛的成员之间插入更多的Like:
INSERT Likes ($to_id,$from_id) VALUES ((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)), ((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 3), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)), ((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4)), ((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 5), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4))
小结
本篇介绍了图数据库的一些简单定义和理解,概述了SQLServer2017中如何创建图数据库的基本步骤和语句。这只是一个初步版本必然有很多缺点,当然也有一些优点,下一篇我将先介绍优点再说一下有哪些不足。
参考文献:https://www.red-gate.com/simple-talk/sql/t-sql-programming/sql-graph-objects-sql-server-2017

