LVS的全称Linux vitual system,是由目前阿里巴巴的著名工程师章文嵩博士开发的一款开源软件。LVS工作在一台server上提供Directory(负载均衡器)的功能,本身并不提供服务,只是把特定的请求转发给对应的realserver(真正提供服务的主机),从而实现集群环境中的负载均衡。
LVS的核心组件ipvs工作在kernel中,是真正的用于实现根据定义的集群转发规则把客户端的请求转发到特定的realserver。而另一个组件ipvsadm是工作在用户空间的一个让用户定义ipvs规则的工具。故我们只要在server上装了ipvsadm软件包就可以定义ipvs规则,而在linux kernel的2.6版本之后kernel是直接支持ipvs的。
注:由于ipvs是接受netfilter五个钩子函数的中的local_in函数控制的。故ipvs不能和netfilter的一些控制规则同时使用。
好了,进入正题,以下是今天所分享的主要内容:
LVS三种模型LVS-NAT2,LVS-DR,LVS-TUN的工作原理及环境搭建。
实验环境:redhat enterprise 5.4+ipvsadm+httpd(用于提供web服务)
这些为LVS环境搭建中的一些专业名词:
RIP:realserver的ip地址
DIP:director的ip地址
CIP:用户客户端的ip地址
VIP:虚拟ip地址(这个ip地址是用户请求的提供服务的ip地址)
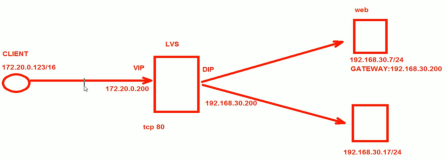
一,LVS-NAT
工作原理图:

工作原理:
图3.1:VS/NAT的体系结构
客户通过Virtual IP Address(虚拟服务的IP地址)访问网络服务时,请求报文到达调度器,调度器根据连接调度算法从一组真实服务器中选出一台服务器,将报文的目标地址Virtual IP Address改写成选定服务器的地址,报文的目标端口改写成选定服务器的相应端口,最后将修改后的报文发送给选出的服务器。同时,调度器在连接Hash表中记录这个连接,当这个连接的下一个报文到达时,从连接Hash表中可以得到原选定服务器的地址和端口,进行同样的改写操作,并将报文传给原选定的服务器。当来自真实服务器的响应报文经过调度器时,调度器将报文的源地址和源端口改为Virtual IP Address和相应的端口,再把报文发给用户。我们在连接上引入一个状态机,不同的报文会使得连接处于不同的状态,不同的状态有不同的超时值。在TCP连接中,根据标准的TCP有限状态机进行状态迁移;在UDP中,我们只设置一个UDP状态。不同状态的超时值是可以设置的,在缺省情况下,SYN状态的超时为1分钟,ESTABLISHED状态的超时为15分钟,FIN状态的超时为1分钟;UDP状态的超时为5分钟。当连接终止或超时,调度器将这个连接从连接Hash表中***。
这样,客户所看到的只是在Virtual IP Address上提供的服务,而服务器集群的结构对用户是透明的。对改写后的报文,应用增量调整Checksum的算法调整TCP Checksum的值,避免了扫描整个报文来计算Checksum的开销。
特点:
1,所有的realserver和director要在同一个网段内
2,VIP生产环境为公网ip,而DIP用于和rs通信
3,director同时处理请求和应答数据包
4,realserver的网关要指向DIP
5,可以实现端口映射
6,realserver可以是任意操作系统
7,director很可能成为系统性能瓶颈
实验拓扑:

Director这台server为双网卡eth0用于客户端的请求,而eth1用于和realserver通信。
客户端通过请求172.16.30.1提供web服务。请根据拓扑配置好网络。
1,rs1上的配置:
配置好rs1上的yum源,可以指向我们的系统安装光盘。
rs1是作为一台realserver使用,故需要安装httpd提供web服务:
# yum -y install httpd
添加测试页:
# cd /var/www/html
# vim index.html
添加如下内容:
jia's server1
启动httpd服务:
# service httpd start
测试rs1上的web服务:

路由的配置:
# route add default gw 192.168.1.1
2,rs2上的配置:
配置好rs2上的yum源,可以指向我们的系统安装光盘。
rs2是作为一台realserver使用,故需要安装httpd提供web服务:
# yum -y install httpd
添加测试页:
# cd /var/www/html
# vim index.html
添加如下内容:
jia's server2
启动httpd服务:
# service httpd start
测试rs2上的web服务:

路由的配置:
# route add default gw 192.168.1.1
3,director上的配置:
安装ipvsadm软件包:(ipvsadm在安装光盘的Cluster目录中,请确认yum源指向)
# yum -y install ipvsadm
打开本机的路由转发功能:
先查看路由转发是否打开:
# cat /proc/sys/net/ipv4/ip_forward
如果显示值为1,则打开,可以跳过此步骤。如果值为0,则开启此功能。
开启路由转发:
# sysctl -w net.ipv4.ip_forward=1 (临时生效)
可以修改配置文件使其永久生效:
# vim /etc/sysctl.conf
修改net.ipv4.ip_forward = 0此行为net.ipv4.ip_forward = 1即可
使用ipvsadm对ipvs进行配置,由于ipvs的十种算法中,wlc算法是最优算法,也是默认算法,故我们仅以此为例进行配置:
# ipvsadm -A -t 172.16.30.1:80 -s wlc
# ipvsadm -a -t 172.16.30.1:80 -r 192.168.1.10 –m –w 3
# ipvsadm -a -t 172.16.30.1:80 -r 192.168.1.11 –m –w 1
查看配置是否生效:
# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.30.1:80 wlc
-> 192.168.1.11:80 Masq 1 0 0
-> 192.168.1.10:80 Masq 3 0 0
ok,我们的LSV-NAT配置好了,下面我们来对其进行测试:
我们可以多刷新页面获取效果或换个浏览器。

为了更好的演示效果,我们可以用另一台server对httpd服务进行压力测试:
# ab -c 100 -n 10000 http://172.16.30.1/index.html (ab工具是apache自带压力测试工具)
在director上查看请求响应结果:
# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.30.1:80 wlc
-> 192.168.1.11:80 Masq 1 16 4194
-> 192.168.1.10:80 Masq 3 62 3997
由于我们使用的是wlc算法,且权重比为3:1,故活动连接数的比几乎也为3:1。使用不同的调度算法,显示的结果是不一样的。
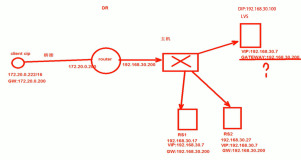
二,LVS-DR(生产环境下应用最为广泛)
工作原理图:

工作原理:基于直接路由来实现。当一个client发送一个WEB请求到VIP,LVS服务器根据VIP选择对应的real-server的Pool,根据算法,在Pool中选择一台 Real-server,LVS在hash表中记录该次连接,然后将client的请求包发给选择的Real-server,最后选择的Real- server把应答包直接传给client;当client继续发包过来时,LVS根据更才记录的hash表的信息,将属于此次连接的请求直接发到刚才选 择的Real-server上;当连接中止或者超时,hash表中的记录将被***。DR模式在转发client的包时,只修改了包目的MAC地址为选定的Real-server的mac地址,所以如果LVS和Real-server在不同的广播域内,那么Real-server就没办法接收到转发的包。这个方式是三种调度中性能最好的,也是我们生产环境中使用最多的。
特点:
1,集群节点和director必须在一个物理网络内
2,RIP可以使用公网地址或私有地址
3,director仅处理入站请求
4,集群节点网关不指向director,故出站不经过director
5,不支持端口映射
6,大多数操作系统可以作为realserver,要支持隔离arp广播
7,director服务器的压力比较小
实验拓扑:

director只需要一个网卡eth0即可,把VIP配置在eth0的别名eth0:0上即可。我们通过VIP地址192.168.1.1给用户提供web服务。
注:生产环境下VIP应该是一个公网ip地址
1,rs1上的配置:
配置好rs1上的yum源,可以指向我们的系统安装光盘。
rs1是作为一台realserver使用,故需要安装httpd提供web服务:
# yum -y install httpd
添加测试页:
# cd /var/www/html
# vim index.html
添加如下内容:
jia's server1
启动httpd服务:
# service httpd start
由于DR模型在内网中基于mac地址进行转发请求数据包,并且我们的director和realserver都配有一个VIP地址,故我们要限制realserver的arp通告和arp响应级别,以保证我们数据包能到达director指定要发送的realserver。而我们的linux系统提供了这样的功能,通过修改kernel的两个参数来控制arp的级别。
两个重要的arp参数:
arp_announce = 2
表示忽略使用要发送的ip数据包的源地址来设置ARP请求的源地址,而由系统来选择最好的接口来发送。首要是选择所有的网络接口的子网中包含该目标IP地址的本地地址。 如果没有合适的地址被发现,将选择当前的要发送数据包的网络接口或其他的有可能接受到该ARP回应的网络接口来进行发送。而Linux默认情况下,是使用要发送的ip数据包中的源ip地址作为arp请求的源地址,而默认这种方式对lvs是不是适用的,具体问题为:rs会把自己的vip作为arp请求的源地址,而路由器收到这个arp请求就会更新自己的arp缓存,修改vip对应的mac为rs的,这样就会造成ip欺骗了,正在lvs上的VIP被抢夺,所以就会有问题。
arp_ignore = 1
表示如果此server接受的arp请求的目的地址,不是该arp请求包进入的接口配置的ip地址,那么不回应此arp请求。(如果lvs的vip配置在rs的eth0:1逻辑网口,这个arp_ignore将失去作用。因为任何设备发送对vip的arp广播,数据包也会从rs的eth0进入,那么rs上的vip由于在eth0:1上,所以就会对此arp请求就行response,导致网络混乱)
配置如下:
# echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
# echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
# echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
# echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
配置lo别名,并且定义lo:0的广播域为本网卡,使VIP不能向网络内发送广播,以防止网络出现混乱:
# ifconfig lo:0 192.168.1.1 broadcast 192.168.1.1 netmask 255.255.255.255
测试rs1上的web服务:

rs2上的配置:
和rs1上的配置完全一样,这里不再阐述。
测试rs2的web服务:

director上的配置:
配置好yum源,安装ipvsadm
# yum install ipvsadm
# ifconfig eth0:0 192.168.1.1 broadcast 192.168.1.1 netmask 255.255.255.255
# route add -host 192.168.1.1 dev eth0:0
# echo 1 > /proc/sys/net/ipv4/ip_forward
以上的配置我们上边已经阐述配置理由
配置ipvs集群服务:
# ipvsadm -A -t 192.168.1.1:80 -s wlc
# ipvsadm -a -t 192.168.1.1:80 -r 192.168.1.10 –g –w 10
# ipvsadm -a -t 192.168.1.1:80 -r 192.168.1.11 –g –w 5
查看:
# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.1.1:80 wlc
-> 192.168.1.11:80 Route 5 0 0
-> 192.168.1.10:80 Route 10 0 0
好了,LVS-DR模型搭建好了,我们来测试一下:
由于我们制定的调度算法和权重不同,故我们多刷新几次就有效果了。

我们同样可以用apache的压力测试工具ab来测试httpd,从而得到调度算法的效果,方法和LVS-NAT的一样,不在阐述。
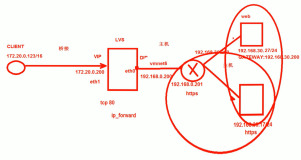
三,LVS-TUN
由于LVS-TUN的模型用的不广泛,如果网络不好会有很多瓶颈,一般没有企业使用,故这里不在探讨它的配置过程,只说一下它的工作原理。
工作原理图:

IP隧道(IP tunneling)是将一个IP报文封装在另一个IP报文的技术,这可以使得目标为一个IP地址的数据报文能被封装和转发到另一个IP地址。IP隧道技术亦称为IP封装技术(IP encapsulation)。IP隧道主要用于移动主机和虚拟私有网络(Virtual Private Network),在其中隧道都是静态建立的,隧道一端有一个IP地址,另一端也有唯一的IP地址。
工作原理:这种方法通过ip隧道技术实现虚拟服务器。
1> client 发送request包到LVS服务器的VIP上。
2> VIP按照算法选择后端的一个Real-server,并将记录一条消息到hash表中,然后将client的request包封装到一个新的IP包里,新IP包的目的IP是Real-server的IP,然后转发给Real-server。
3> Real-server收到包后,解封装,取出client的request包,发现他的目的地址是VIP,而Real-server发现在自己的 lo:0口上有这个IP地址,于是处理client的请求,然后real-server将直接relpy这个request包直接发给client。
4> 该client的后面的request包,LVS直接按照hash表中的记录直接转发给Real-server,当传输完毕或者连接超时,那么将***hash表中的记录。
由于通过IP Tunneling 封装后,封装后的IP包的目的地址为Real-server的IP地址,那么只要Real-server的地址能路由可达,Real-server在什么 网络里都可以,这样可以减少对于公网IP地址的消耗,但是因为要处理IP Tunneling封装和解封装的开销,那么效率不如DR模式。
特点:
1,realserver和director可以不在一个物理网络中
2,director要有到realserver的路由
3,director仅处理入站请求
4,realserver的网关不能指向DIP
5,不支持端口映射
6,支持ip隧道功能的操作系统才能作为realserver
由于需要Real-server支持IP Tunneling,所以设置与DR模式不太一样,LVS不需要设置tunl设备,LVS本身可以进行封装
rs的配置:
只需要配置VIP在tunl设备上即可:(vip:172.16.1.1)
# ifconfig tunl0 172.16.1.1 netmask 255.255.255.255
# ifconfig tunl0
tunl0 Link encap:IPIP Tunnel HWaddr
inet addr:172.16.1.1 Mask:255.255.255.255
UP RUNNING NOARP MTU:1480 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
四,lvs简单调优
1,调整ipvs connection hash表的大小
IPVS connection hash table size,取值范围:[12,20]。该表用于记录每个进来的连接及路由去向的信息。连接的Hash表要容纳几百万个并发连接,任何一个报文到达都需要查找连接Hash表,Hash表是系统使用最频繁的部分。Hash表的查找复杂度为O(n/m),其中n为Hash表中对象的个数,m为Hash表的桶个数。当对象在Hash表中均匀分布和Hash表的桶个数与对象个数一样多时,Hash表的查找复杂度可以接近O(1)。
连接跟踪表中,每行称为一个hash bucket(hash桶),桶的个数是一个固定的值CONFIG_IP_VS_TAB_BITS,默认为12(2的12次方,4096)。这个值可以调整,该值的大小应该在 8 到 20 之间,详细的调整方法见后面。每一行都是一个链表结构,包含N列(即N条连接记录),这个N是无限的,N的数量决定了决定了查找的速度。
LVS的调优建议将hash table的值设置为不低于并发连接数。例如,并发连接数为200,Persistent时间为200S,那么hash桶的个数应设置为尽可能接近200x200=40000,2的15次方为32768就可以了。当ip_vs_conn_tab_bits=20 时,哈希表的的大小(条目)为 pow(2,20),即 1048576,对于64位系统,IPVS占用大概16M内存,可以通过demsg看到:IPVS: Connection hash table configured (size=1048576, memory=16384Kbytes)。对于现在的服务器来说,这样的内存占用不是问题。所以直接设置为20即可。
关于最大“连接数限制”:这里的hash桶的个数,并不是LVS最大连接数限制。LVS使用哈希链表解决“哈希冲突”,当连接数大于这个值时,必然会出现哈稀冲突,会(稍微)降低性能,但是并不对在功能上对LVS造成影响。
调整 ip_vs_conn_tab_bits的方法:
新版的linux kernel中的IPVS代码,允许调整 ip_vs_conn_bits 的值。而老kernel中的的IPVS代码则需要通过重新编译内核来进行调整。
在linux kernel发行版里,IPVS通常是以模块的形式编译的。
确认能否调整使用命令 modinfo -p ip_vs(查看 ip_vs 模块的参数),看有没有 conn_tab_bits 参数可用。假如可以用,那么说时可以调整,调整方法是加载时通过设置 conn_tab_bits参数:
在/etc/modprobe.d/目录下添加文件ip_vs.conf,内容为:
options ip_vs conn_tab_bits=20
查看
ipvsadm -l
如果显示IP Virtual Server version 1.2.1 (size=4096),则前面加的参数没有生效
modprobe -r ip_vs
modprobe ip_vs
重新查看
IP Virtual Server version 1.2.1 (size=1048576)
假如没有 conn_tab_bits 参数可用,则需要重新调整编译选项,重新编译。
Centos6.2,内核版本2.6.32-220.13.1.el6.x86_64,仍然不支持这个参数,只能自定义编译了。
另外,假如IPVS支持调整 ip_vs_conn_tab_bits,而又将IPVS集成进了内核,那么只能通过重启,向内核传递参数来调整了。在引导程序的 kernel 相关的配置行上,添加:ip_vs.conn_tab_bits=20 ,然后,重启。
或者重新编译内核。
2,linux系统参数优化
关闭网卡LRO和GRO
现在大多数网卡都具有LRO/GRO功能,即 网卡收包时将同一流的小包合并成大包 (tcpdump抓包可以看到>MTU 1500bytes的数据包)交给 内核协议栈;LVS内核模块在处理>MTU的数据包时,会丢弃;
因此,如果我们用LVS来传输大文件,很容易出现丢包,传输速度慢;
解决方法,关闭LRO/GRO功能,命令:
ethtool -k eth0 查看LRO/GRO当前是否打开
ethtool -K eth0 lro off 关闭GRO
ethtool -K eth0 gro off 关闭GRO
禁用ARP,增大backlog并发数
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
net.core.netdev_max_backlog = 500000 (在每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目)
3,lvs自身配置
尽量避免sh算法
一些业务为了支持会话保持,选择SH调度算法,以实现 同一源ip的请求调度到同一台RS上;但 SH算法本省没有实现一致性hash,一旦一台RS down,,当前所有连接都会断掉;如果配置了inhibit_on_failure,那就更悲剧了,调度到该RS上的流量会一直损失;
实际线上使用时,如需 会话保持,建议配置 persistence_timeout参数,保证一段时间同一源ip的请求到同一RS上。
4,手动绑定linux系统网卡中断
lvs的并发过大,对网卡的利用很频繁,而对网卡的调优,也能增加lvs的效率。当前大多数系统网卡都是支持硬件多队列的,为了充分发挥多核的性能,需要手动将网卡中断(流量)分配到所有CPU核上去处理。默认情况下,网卡的所有的中断都是发送到一个默认的cpu上去处理的,而cpu中断需要等待时间,这样对于使用网卡频繁的服务,网卡性能就会成为瓶颈。
1,查看网卡中断:
# cat /proc/interrupts
2,绑定网卡中断到cpu
例如将中断52-59分别绑定到CPU0-7上:
[plain] view plaincopy
echo "1" > /proc/irq/52/smp_affinity
echo "2" > /proc/irq/53/smp_affinity
echo "4" > /proc/irq/54/smp_affinity
echo "8" > /proc/irq/55/smp_affinity
echo "10" > /proc/irq/56/smp_affinity
echo "20" > /proc/irq/57/smp_affinity
echo "40" > /proc/irq/58/smp_affinity
echo "80" > /proc/irq/59/smp_affinity
/proc/irq/${IRQ_NUM}/smp_affinity为中断号为IRQ_NUM的中断绑定的CPU核的情况。以十六进制表示,每一位代表一个CPU核。
1(00000001)代表CPU0
2(00000010)代表CPU1
3(00000011)代表CPU0和CPU1
3,关闭系统自动中断平衡:
# service irqbalance stop
4,如果网卡硬件不支持多队列,那就采用google提供的软多队列RPS;
配置方法同硬中断绑定,例:
# echo 01 > /sys/class/net/eth0/queues/rx-0/rps_cpus
# echo 02 > /sys/class/net/eth0/queues/rx-1/rps_cpus