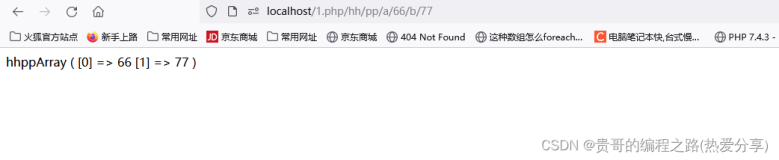
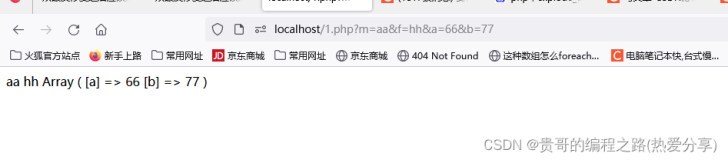
下面我们来上代码
数据库采用PDO 主要用到了预处理 关于预处理的内容
参考:PHP5中PDO(PHP DATA OBJECT)模块基础详解
还有一个phpquery 源码下载 这个稍后在给出具体的教程
第一步:
基本的配置 数据库文件在第一讲里面
数据库连接:conn.php
- <?php
- define('DB_USER', 'root');
- define('DB_PASSWORD', '');
- define('DB_CHARSET', 'utf8');
- try {
- $DBH = new PDO('mysql:host=localhost;dbname=shopyijia', DB_USER, DB_PASSWORD);
- $DBH->exec('SET CHARACTER SET '.DB_CHARSET);
- $DBH->exec('SET NAMES '.DB_CHARSET);
- /*
- * 如果想要在脚本结束的时候不释放链接那么在参数里面加上array(PDO::ATTR_PERSISTENT => true)不过一般情况下可以不用常链接
- $dbh = new PDO('mysql:host=localhost;dbname=test', $user, $pass, array(
- PDO::ATTR_PERSISTENT => true
- ));
- */
- } catch (PDOException $e) {
- print "Error!: " . $e->getMessage() . "<br/>";
- die();
- }
第二步:
手动添加一级分类的信息地址

第三步:
爬取二级分类
- <?php
- /*
- * 获取所有商家目录信息
- */
- header("Content-type:text/html;charset=utf8");
- set_time_limit(0);
- define('SHOP_BASE_URL', 'http://shop.yijia.com');
- require_once 'conn.php'; //数据库初始化
- require('phpQuery/phpQuery.php'); //采集器初始化
- $Sql = 'SELECT * FROM yj_shop_category WHERE is_grab=\'0\' AND sc_parent_id=0';
- $un_grab_cat = $DBH->query($Sql)->fetchAll(); //爬取一级分类下面的二级分类页面
- //预处理SQL
- $stmt = $DBH->prepare('INSERT INTO yj_shop_category(sc_name,sc_parent_id,sc_url,sc_add_time) VALUES (:sc_name,:sc_parent_id,:sc_url,:sc_add_time)');
- $sc_name = $sc_parent_id = $sc_url = $sc_add_time = null;
- $stmt->bindParam(':sc_name', $sc_name); //
- $stmt->bindParam(':sc_parent_id', $sc_parent_id);
- $stmt->bindParam(':sc_url', $sc_url);
- $stmt->bindParam(':sc_add_time', $sc_add_time);
- foreach ($un_grab_cat as $_key => $_value){
- $sc_url = $_value['sc_url'];
- $sc_parent_id = $_value['sc_id'];//父分类id
- $file = file_get_contents($sc_url);
- $dom = phpQuery::newDocument($file); //初始化对象
- foreach(pq("#dd_open_1 ul > li") as $item){
- $sc_name = pq($item)->text();
- $sc_url = SHOP_BASE_URL.pq($item)->find('a:first')->attr('href');
- $sc_add_time = time();
- $stmt->execute();
- }
- phpQuery::$documents = array();
- }
- echo 'over';
- die();
第四步:
爬取二级分类的页面更新对应的分页
- <?php
- header("Content-type:text/html;charset=utf8");
- set_time_limit(0);
- define('SHOP_BASE_URL', 'http://shop.yijia.com');
- require_once 'conn.php'; //数据库初始化
- require('phpQuery/phpQuery.php'); //采集器初始化
- $Sql = 'SELECT sc_id,sc_url FROM yj_shop_category WHERE is_grab=\'0\' AND sc_parent_id!=0';
- $un_grab_cat = $DBH->query($Sql)->fetchAll(); //爬取一级分类下面的二级分类页面
- //预处理SQL
- $stmt = $DBH->prepare('UPDATE yj_shop_category SET sc_page_num = :sc_page_num WHERE sc_id = :sc_id');
- $sc_page_num = $sc_id = null;
- $stmt->bindParam(':sc_page_num', $sc_page_num); //
- $stmt->bindParam(':sc_id', $sc_id);
- foreach ($un_grab_cat as $_key => $_value){
- $sc_id = $_value['sc_id'];
- $sc_url = $_value['sc_url'];
- $file = file_get_contents($sc_url);
- $dom = phpQuery::newDocument($file); //初始化对象
- $last_a = pq('div.pager > a:last');
- $A_parm = explode('_', pq($last_a)->attr('href'));
- $sc_page_num = intval($A_parm[5]);
- $stmt->execute();
- phpQuery::$documents = array();
- sleep(1);
- }
- echo 'over';
- die();
第五步:
爬取二级分类所有分页的商家信息
- <?php
- /*
- * 获取所有商家信息
- */
- header("Content-type:text/html;charset=utf8");
- set_time_limit(0);
- error_reporting(E_ALL);
- define('SHOP_BASE_URL', 'http://shop.yijia.com');
- require_once 'conn.php'; //数据库初始化
- require('phpQuery/phpQuery.php'); //采集器初始化
- $Sql = 'SELECT sc_id,sc_url,sc_page_num,sc_current_page_num FROM yj_shop_category WHERE is_grab=\'0\' AND sc_parent_id!=0';
- $un_grab_cat = $DBH->query($Sql)->fetchAll(); //获取所有的未被抓取的二级分类信息
- foreach ($un_grab_cat as $_key => $_value){
- $sc_url = $_value['sc_url'];
- $sc_id = $_value['sc_id'];//父分类id
- if($_value['sc_page_num'] == '0'){ //如果只有一页
- $sc_tmp_url = $sc_url;
- if(getPageShopInfo($sc_tmp_url,$sc_id)){
- $DBH->exec('UPDATE yj_shop_category SET is_grab=1 WHERE sc_id='.$sc_id);
- }
- }else{ //如果有多页
- for($i=$_value['sc_current_page_num'];$i<=$_value['sc_page_num'];$i++){
- $A_param = explode('_', $sc_url);
- $A_param[2] = intval($A_param[2]).'_0_0_'.$i.'/';
- $sc_tmp_url = implode('_',$A_param);//拼接出来一个的url 要符合当前的规则哦 以后可能会有变动哦
- if(getPageShopInfo($sc_tmp_url, $sc_id)){
- $DBH->exec('UPDATE yj_shop_category SET sc_current_page_num='.$i.' WHERE sc_id='.$sc_id);
- $last_page = $i;
- }
- }
- if($last_page == $_value['sc_page_num']){ //如果后一个分页爬取完成 那么更新当前 这个分类的状态为已抓取
- $DBH->exec('UPDATE yj_shop_category SET is_grab=1 WHERE sc_id='.$sc_id);
- }
- }
- }
- function getPageShopInfo($url,$sc_parent_id){
- global $DBH;
- $stmt = $DBH->prepare('INSERT INTO yj_shop_information(si_name,si_cat_id,si_yijia_url,si_logo_url,si_front_desc,si_add_time) VALUES (:si_name,:si_cat_id,:si_yijia_url,:si_logo_url,:si_front_desc,:si_add_time)');
- $si_name = $si_cat_id = $si_yijia_url = $si_logo_url = $si_front_desc = $si_add_time = null;
- $stmt->bindParam(':si_name', $si_name);
- $stmt->bindParam(':si_cat_id', $si_cat_id);
- $stmt->bindParam(':si_yijia_url', $si_yijia_url);
- $stmt->bindParam(':si_logo_url', $si_logo_url);
- $stmt->bindParam(':si_front_desc', $si_front_desc);
- $stmt->bindParam(':si_add_time', $si_add_time);
- $file = file_get_contents($url);
- $dom = phpQuery::newDocument($file); //初始化对象
- foreach ($dom->find('div.shopping_list') as $item){ //循环节点
- $si_name = pq($item)->find('h2:first > a:first')->text(); //店铺名称
- $si_cat_id = $sc_parent_id; //分类名称
- $si_yijia_url = SHOP_BASE_URL.pq($item)->find('h2:first > a:first')->attr('href'); //一家网中商家介绍页面
- $si_logo_url = pq($item)->find('div.fl > a > img:first')->attr('src');
- $si_front_desc = pq($item)->find('div.shopping_description:first')->text();
- $si_add_time = time();
- $stmt->execute();
- }
- phpQuery::$documents = array();
- sleep(1);//休息一秒 友情点 不要给他们太大压力是吧
- return true;
- }
- echo 'over';
- die();
第六步:获取商家的真实url 和具体的描述
- <?php
- /*
- * 获取商家的具体信息
- */
- header("Content-type:text/html;charset=utf8");
- set_time_limit(0);
- define('SHOP_BASE_URL', 'http://shop.yijia.com');
- require_once 'conn.php'; //数据库初始化
- require('phpQuery/phpQuery.php'); //采集器初始化
- $Sql = 'SELECT si_id,si_yijia_url FROM yj_shop_information WHERE si_shop_url =\'\' ';
- $un_grab_cat = $DBH->query($Sql)->fetchAll(); //所有的没有被重新爬取的商家url
- //更新预处理SQL
- $stmt = $DBH->prepare('UPDATE yj_shop_information SET si_shop_url=:si_shop_url,si_true_url=:si_true_url,si_desc=:si_desc WHERE si_id=:si_id');
- $si_true_url = $si_shop_url = $si_desc = $si_id = $sc_add_time = null;
- $stmt->bindParam(':si_true_url', $si_true_url); //
- $stmt->bindParam(':si_shop_url', $si_shop_url); //
- $stmt->bindParam(':si_desc', $si_desc);
- $stmt->bindParam(':si_id', $si_id);
- $i=1;
- foreach ($un_grab_cat as $_key => $_value){
- $si_yijia_url = $_value['si_yijia_url'];
- $si_id = $_value['si_id'];//id
- $file = file_get_contents($si_yijia_url);
- $dom = phpQuery::newDocument($file); //初始化对象
- $si_shop_url = SHOP_BASE_URL.pq('div.shop_logo > a:first')->attr('href');
- $http_info = getContents($si_shop_url);
- $si_true_url = $http_info['url'];
- $si_desc = pq('div.shop_detailinfo > strong:first')->text();
- $stmt->execute();
- if(fmod($i,3) == 0)
- sleep(1);
- $i++;
- phpQuery::$documents = array();
- }
- function getContents($url){
- $header = array("Referer:http://www.tx29.com/");
- $ch = curl_init();
- curl_setopt($ch, CURLOPT_URL, $url);
- curl_setopt($ch, CURLOPT_TIMEOUT, 30);
- curl_setopt($ch, CURLOPT_HTTPHEADER,$header);
- curl_setopt($ch, CURLOPT_FOLLOWLOCATION,1);
- ob_start();
- curl_exec($ch);
- ob_end_clean();
- $x = curl_getinfo($ch);
- curl_close($ch);
- return $x;
- }
- echo 'over';
- die();
最后算了下时间 如果友情爬取的话需要48个小时。可以分几个ip多个脚本跑没问题。 那个我 这里爬取好的数据如果非同行需要的话 留言联系.....同行的就自己抓取把
这里最后说下不要暴力爬取哦
本文转自kefirking 51CTO博客,原文链接:http://blog.51cto.com/phpzf/799555,如需转载请自行联系原作者