前言:在数据挖掘领域,.NET基本上是空白,除了分词程序外,啥都没有,大量的招聘显示数据挖掘目前是Java, C++和Python的天下。作为微软阵营的一份子,我始终认为我们不该坐以待毙,与其坐着被人看笑话,还不如勇敢的站出来,创造一个崭新的.NET未来。(话说昨天的吐槽贴不知道大家玩的尽兴不尽兴,不是有人让我给点实战的玩意来证明.NET的牛X嘛,没问题啊,我如约而至。)
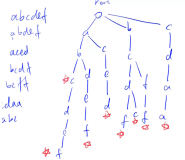
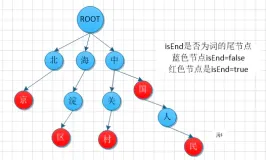
Trie Tree(字典树)对很多人显得有些陌生,用一句话来概括,它可以有效加速字符串匹配速度,并且应用极其广泛,如分词、搜索、脏字过滤等。曾经写过一篇介绍TrieTree的文章,不熟悉的同学可以看一下《Trie Tree介绍及其C#实现》。
TrieTree之所以快速,和它树形存储结构很有关系,由于所有的查找都是走结点的,所以速度会比普通字符串匹配快很多,传统匹配的问题在于即使匹配不成功,每次还是要去匹配前面这些字符,而且要与每一个字典项去匹配。
举个简单的例子,假设字典里面有两句整句,如“这里是我们的地盘”,“这里是你们的”,假设我现在要匹配
“这里是他们的”,传统存储会把字典保存在List<string>中,但这就意味着,“这里是”三个字每次都要匹配一遍,即使最终结果是没找到“这里是他们的”。但如果是TrieTree结构,我们只需要匹配一次“这里是”就能知道存不存在,随着字典中词数的增加,这种性能提升愈加明显。
这么好的东西怎么能没有一个通用的框架,于是我便考虑设计了TrieTree Service。TrieTree Service是一个基于Windows Service的服务,采用socket与客户端进行通讯,通讯部分使用了江大鱼的SuperSocket。(这玩意确实好用,上手也很快,我大概用了2天就把通讯部分全搞定了。)之所以采用Windows Service,主要考虑了分布式部署、以及内存空间的需求。由于TrieTree Service采用内存作为缓存空间,所以对内存是有很大需求的,如果与其他应用共享空间,在32位系统上估计很快就3GB了,根本没法用,但做成Windows Service以后,3GB至少是独享的。而且理论上我可以部署n个service,加载不同的字典,比如Service 1我加载盘古分词词典、Service 2我加载MongoDB的字典,以此类推,客户端会根据需要去访问不同的Service,从而获得足够的数据支持。

Trie Tree服务还有一个很明显的优势那就是字典资源的整合,以往如果我们要调用第三方字典库或者扩展字典库,可能必须重新写一个类来实现读,然后调用不同的接口来加载不同的字典库,现在有了Trie Tree服务,你就可以做到把几个库合并在一起,比如盘古分词的库可以和细胞词库混用,如果词重复,Trie Tree服务不会重复添加,而是在现有结点上把频率相加。例如,我本地的TrieTree服务就把盘古分词、IKAnalyzer词典、还有我自己的多个MongoDB的字典库一起加载起来运行,那效果绝对是只可意会不可言传啊,哈哈。我看了下,内存占用也不高,只有400M左右。
Trie Tree服务支持POS (Part of Speech)枚举,说通俗点就是某个词的词性,如名词、动词、代词等。目前的POSType采用了盘古分词的类型,以后会考虑扩充,目前足够了。(话说清华和北大都有一套自己的POS分类,比盘古要详细,以后会考虑支持这两个标准,因为POS的细粒度决定了最终的分词结果。)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
|
[Flags]
public
enum
POSType :
int
{
/// <summary>
/// 形容词 形语素
/// </summary>
D_A = 0x40000000,
/// <summary>
/// 区别词 区别语素
/// </summary>
D_B = 0x20000000,
/// <summary>
/// 连词 连语素
/// </summary>
D_C = 0x10000000,
/// <summary>
/// 副词 副语素
/// </summary>
D_D = 0x08000000,
/// <summary>
/// 叹词 叹语素
/// </summary>
D_E = 0x04000000,
/// <summary>
/// 方位词 方位语素
/// </summary>
D_F = 0x02000000,
/// <summary>
/// 成语
/// </summary>
D_I = 0x01000000,
/// <summary>
/// 习语
/// </summary>
D_L = 0x00800000,
/// <summary>
/// 数词 数语素
/// </summary>
A_M = 0x00400000,
/// <summary>
/// 数量词
/// </summary>
D_MQ = 0x00200000,
/// <summary>
/// 名词 名语素
/// </summary>
D_N = 0x00100000,
/// <summary>
/// 拟声词
/// </summary>
D_O = 0x00080000,
/// <summary>
/// 介词
/// </summary>
D_P = 0x00040000,
/// <summary>
/// 量词 量语素
/// </summary>
A_Q = 0x00020000,
/// <summary>
/// 代词 代语素
/// </summary>
D_R = 0x00010000,
/// <summary>
/// 处所词
/// </summary>
D_S = 0x00008000,
/// <summary>
/// 时间词
/// </summary>
D_T = 0x00004000,
/// <summary>
/// 助词 助语素
/// </summary>
D_U = 0x00002000,
/// <summary>
/// 动词 动语素
/// </summary>
D_V = 0x00001000,
/// <summary>
/// 标点符号
/// </summary>
D_W = 0x00000800,
/// <summary>
/// 非语素字
/// </summary>
D_X = 0x00000400,
/// <summary>
/// 语气词 语气语素
/// </summary>
D_Y = 0x00000200,
/// <summary>
/// 状态词
/// </summary>
D_Z = 0x00000100,
/// <summary>
/// 人名
/// </summary>
A_NR = 0x00000080,
/// <summary>
/// 地名
/// </summary>
A_NS = 0x00000040,
/// <summary>
/// 机构团体
/// </summary>
A_NT = 0x00000020,
/// <summary>
/// 外文字符
/// </summary>
A_NX = 0x00000010,
/// <summary>
/// 其他专名
/// </summary>
[Description(
"其他专名"
)]
A_NZ = 0x00000008,
/// <summary>
/// 前接成分
/// </summary>
D_H = 0x00000004,
/// <summary>
/// 后接成分
/// </summary>
D_K = 0x00000002,
/// <summary>
/// 未知词性
/// </summary>
UNKNOWN = 0x00000000,
}
|
同时TrieTree还支持POS并集查询,如D_N|D_V,表示查词性是名词或者动词的词。、
目前TrieTree支持三种匹配命令,它们是MMFetch(Maximum Match,正向最大匹配)、 RMMFetch(Reverse Maximum Match, 反向最大匹配)、 ExactMatch(全字匹配)。
例如你要使用MMFetch命令搜索“我们”,直接通过socket向TrieTree Service发送“MMFetch 我们”即可。如果你想搜索词性,可以发送“MMFetch 我们<SOH>512”,这表示搜索词性为语气词D_Y(0x200=512)的“我们”,其中<SOH>是一个自定义字符0x01,用作分隔符。其他两个命令的用法类似。
由于定义了IDataProvider接口,你可以根据需要定制自己的DataProvider。目前TrieTree Service自带了PanguDictProvider, TxtDictProvider, IKAnaylzerDictProvider。以下是IDataProvider的定义
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
public
interface
IDataNode
{
/// <summary>
/// word text
/// </summary>
string
Word
{
get
;
set
;
}
/// <summary>
/// Part of Speech Tag Value
/// </summary>
POSType POS
{
get
;
set
;
}
/// <summary>
/// frequency of the word
/// </summary>
double
Frequency
{
get
;
set
;
}
}
public
interface
IDataProvider
{
List<IDataNode> Load();
}
|
这里的IDataNode代表导入的一条条词条,当然你必须先实现这个接口。其中的POS是之前提到的词性,Frequency是频率,Word是词本身。对于没有词性和没有频率的导入项,直接忽略这两项就行了。
在BluePrint.Dictionary命名空间下面定义了一个客户端封装类DictionaryServiceClient,提供了对命令的基本封装,这样你就不用直接去和SendCommand打交道了。
|
1
2
3
|
public
TrieTreeResult ExactMatch(
string
word){...}
public
TrieTreeResult MaximumMatch(
string
word){...}
public
TrieTreeResult ReverseMaximumMatch(
string
word){...}
|