数据类型差不多是接触mysql一开始就了解的内容,最近遇到几个现象如varchar自动转mediumtext,blob存储性能的问题,不得不回头明确一下关于MySQL常用数据类型的选择。
mysql手册这里 已经讲的很清楚了。它们都是定义字符串型字段时常用的类型,但它们存储和检索的方式有不同,最大长度和尾部的空格是否保留也有差别。
char类型是使用固定长度空间进行存储,范围0-255。比如CHAR(30)能放30个字节,存放abcd时,尾部会以空格补齐,实际占用空间 30bytes 。检索它的时候尾部空格会被去除。
char善于存储经常改变的值,或者长度相对固定的值,比如type、ip地址或md5之类的数据,不容易产生碎片。关于它的效率可以参考这里。
varchar类型保存可变长度字符串,范围0-65535(但受到单行最大64kb的限制)。比如用varchar(30)去存放abcd,实际使用5个字节,因为还需要使用额外1个字节来标识字串长度(0-255使用1个字节,超过255需要2个字节)。
varchar善于存储值的长短不一的列,也是用的最多的一种类型,节省磁盘空间。update时varchar列时,如果新数据比原数据大,数据库需要重新开辟空间,这一点会有性能略有损耗,但innodb引擎下查询效率比char高一点。这也是innodb官方推荐的类型。
如果存储时真实长度超过了char或者varchar定义的最大长度呢?
-
在SQL严格模式下,无论char还是varchar,如果尾部要被截断的是非空格,会提示错误,即插入失败
-
在SQL非严格模式下,无论char还是varchar,如果尾部要被截断的是非空格,会提示warning,但可以成功
-
如果尾部要被截断的是空格,无论SQL所处模式,varchar都可以插入成功但提示warning;char也可以插入成功,并且无任何提示
这里特意提到SQL的严格模式,是因为在工作中也遇到过一些坑,参考[MySQL的sql_mode严格模式注意点]()。
贴上官方的一个表格:
| Value | CHAR(4) | Storage Required | VARCHAR(4) | Storage Required |
|---|---|---|---|---|
| '' | ' ' | 4 bytes | '' | 1 byte |
| 'ab' | 'ab ' | 4 bytes | 'ab' | 3 bytes |
| 'abcd' | 'abcd' | 4 bytes | 'abcd' | 5 bytes |
| 'abcdefgh' | 'abcd' | 4 bytes | 'abcd' | 5 bytes |
另外,mysql字段值比较时默认是不区分大小写的,这是由于他们的校对规则(一般是 utf8_general_ci)决定的,按字符比较,所以查询时 值尾部 的空格也是被忽略的,除非建表时对列指定 BINARY (校对字符集变成utf8_bin)或者select * from vc where binary v='ab ';,就会按字节比较,即比较时区分大小写和尾部空格。
需要注意的是,使用varchar不能因为长度可变就随意分大空间,比如90个字节能放够的列定义成varchar(200),因为开辟内存时是以200字节进行的,遇到需要filesort或tmp table作业可能会带来不利影响。
最后研究一下字符集对存储长度影响,以 create table tc_utf8(c1 int primary key auto_increment, c2 char(30), c3 varchar(N)) charset=utf8; 为例:
字符集为utf8,于是中文每个字符占3个字节,英文还是1个字节,所以N最大为 (65535-1-2-4-303)/3 = 21812,即最多能存放21812个英文、数字、汉字。其中65535是单行最大限制,减1是NULL标识位,减2的是头部的2个字节标识长度,减303的原因是char(30)占用90个字节,最后除以3还是因为utf8最长用3个字节表示一个字符。
但有人会说,utf8的英文字符只需要1个字节表示,并不占用3个字节,在存ASCII字符的情况下N是不是可以更大呢。答案是否定的,因为定义表的时候mysql事先并不知道c3要存的是英文还在中文,只能以最大来计。mysql也是以这种方式来确保行最大65535bytes限制:数据行只要出现一个ascii字符(如英文字母、数字),就永远达不到65535,数据行全中文则刚好满。
还有一种特殊情况:
mysql> show variables like "char%";
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.12 sec)
mysql> select @@sql_mode;
+------------------------+
| @@sql_mode |
+------------------------+
| NO_ENGINE_SUBSTITUTION |
+------------------------+
1 rows in set (0.13 sec)
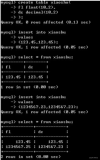
mysql> create table tc_utf8_21812(c1 int primary key auto_increment, c2 char(30), c3 varchar(21812)) charset=utf8;
Query OK, 0 rows affected (0.10 sec)
mysql> create table tc_utf8_21813(c1 int primary key auto_increment, c2 char(30), c3 varchar(21845)) charset=utf8;
Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
mysql> create table tc_utf8_21846(c1 int primary key auto_increment, c2 char(30), c3 varchar(21846)) charset=utf8;
Query OK, 0 rows affected, 1 warnings (0.10 sec)
mysql> show warnings;
+-------+------+---------------------------------------------+
| Level | Code | Message |
+-------+------+---------------------------------------------+
| Note | 1246 | Converting column 'c3' from VARCHAR to TEXT |
+-------+------+---------------------------------------------+
1 rows in set (0.14 sec)
即在非严格模式下,因为N=21813 > 21812,所以报 Row size too large 错误。但N=21846 > (65535/3)时,只是出现warnings,varchar自动变成了mediumtext 类型。
细心的朋友可能注意到上面开始我看了一下字符集 show variabels like "char%";,因为接下来要说明另外一个问题:客户端字符集与database不一样的情况。
我们回到 N<=21812 的正常情况:
CREATE TABLE `tc_utf8` (
`c1` int(11) NOT NULL AUTO_INCREMENT,
`c2` char(30) DEFAULT NULL,
`c3` varchar(30) DEFAULT NULL,
PRIMARY KEY (`c1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;插入一些数据:
mysql> set names utf8;
mysql> insert into tc_utf8(c2,c3) values('en_30',repeat('a',30));
Query OK, 1 rows affected (17.87 sec)
mysql> insert into tc_utf8(c2,c3) values('en_31',repeat('b',31));
Query OK, 1 rows affected, 1 warnings (0.10 sec)
mysql> show warnings;
+---------+------+-----------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------+
| Warning | 1265 | Data truncated for column 'c3' at row 1 |
+---------+------+-----------------------------------------+
1 rows in set (0.14 sec)
mysql> insert into tc_utf8(c2,c3) values('zh_30',repeat('中',30));
Query OK, 1 rows affected (0.18 sec)
mysql> insert into tc_utf8(c2,c3) values('zh_31',repeat('文',31));
Query OK, 1 rows affected, 1 warnings (0.09 sec)
意料之中,汉字同样被截断
ysql> select c2,c3,length(c3),char_length(c3) from tc_utf8;
+-------+------------+-----------------+------------------------------------------------------------------------+
| c2 | length(c3) | char_length(c3) | c3 |
+-------+------------+-----------------+------------------------------------------------------------------------+
| en_30 | 30 | 30 | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa |
| en_31 | 30 | 30 | bbbbbbbbbbbbbbbbbbbbbbbbbbbbbb |
| zh_30 | 90 | 30 | 中中中中中中中中中中中中中中中中中中中中中中中中中中中中中中 |
| zh_31 | 90 | 30 | 文文文文文文文文文文文文文文文文文文文文文文文文文文文文文文 |
+-------+------------+-----------------+------------------------------------------------------------------------+
4 rows in set (0.00 sec)上面的en_30代表insert的时候存入30个英文字符。可以看到30个a占用30个字节,30个汉字占用90个字节,大于30的会被截断,证实了文章一开头的说法。
mysql> set names latin1;
mysql> insert into tc_utf8(c2,c3) values('zh_30_latin1',repeat('中',30));
Query OK, 1 rows affected, 1 warnings (0.10 sec)
mysql> show warnings;
+---------+------+-----------------------------------------+
| Level | Code | Message |
+---------+------+-----------------------------------------+
| Warning | 1265 | Data truncated for column 'c3' at row 1 |
+---------+------+-----------------------------------------+
1 rows in set (0.14 sec)
mysql> insert into tc_utf8(c2,c3) values('zh_10_latin1',repeat('中',10));
Query OK, 1 rows affected (0.10 sec)
mysql> insert into tc_utf8(c2,c3) values('zh_10_latin1',repeat('文',10));
Query OK, 1 rows affected (0.11 sec)
mysql> insert into tc_utf8(c2,c3) values('zh_11_latin1',repeat('文',11));
Query OK, 1 rows affected, 1 warnings (0.12 sec)
截断上面的实验显示,db table是utf8,但客户端连接时使用latin1,在非严格模式下 varchar(30) 只能存10个汉字,多余的尾部被截断了
我们来看一下占用字节的情况:(2,3行的乱码是意料之中的)
mysql> select c1,c2,c3,length(c3),char_length(c3) from tc_utf8;
+----+--------------+--------------------------------+------------+-----------------+
| c1 | c2 | c3 | length(c3) | char_length(c3) |
+----+--------------+--------------------------------+------------+-----------------+
| 1 | en_30 | aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa | 30 | 30 |
| 2 | en_31 | bbbbbbbbbbbbbbbbbbbbbbbbbbbbbb | 30 | 30 |
| 3 | zh_30 | ?????????????????????????????? | 90 | 30 |
| 4 | zh_31 | ?????????????????????????????? | 90 | 30 |
| 5 | zh_30_latin1 | 中中中中中中中中中中 | 60 | 30 |
| 6 | zh_10_latin1 | 中中中中中中中中中中 | 60 | 30 |
| 7 | zh_10_latin1 | 文文文文文文文文文文 | 80 | 30 |
| 9 | zh_11_latin1 | 文文文文文文文文文文 | 80 | 30 |
+----+--------------+--------------------------------+------------+-----------------+
8 rows in set (0.14 sec)看到char_length函数算出的中、英文字符个数都是30,但一个“中”占6字节,一个“文”占8字节,是不是很诧异,这中间有数次的编码转换过程,有兴趣 可以参考 http://mysql.rjweb.org/doc.php/charcoll ,是可以模拟出来的。
在严格模式下就没这么复杂了,所以尽量使用 STRICT_TRANS_TABLES ,避免意外的情况带入生产环境。早期设计的时候就要保持客户端与数据库字符集一致。