#####编辑器依旧那么难用 难用 难用~~################
##################################################
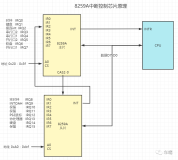
CPU亲缘性及网卡中断绑定
每个CPU的每个核心都会被识别成一个逻辑CPU,由一个核心会存在超线程的功能,所以一个物理核心会表现成为多个cpu
多个cpu之间是如何通信的:
首先了解几个概念
smp: 对等的访问内存空间,事实上cpu访问内存是通过内存控制器的芯片进行的
numa: 非一致性内存访问机制
http://yijiu.blog.51cto.com
numa体系
简单来讲是每个物理cpu,非物理核心
每个socket上所插入的cpu都被称为本地节点,而所有非本地节点,都称为远程节点,而距离彼此cpu比较近的节点被称为邻居节点
如果cpu相对比较多,从一个节点到另一个节点距离比较长,简单来讲每个内存都有内存控制器来控制,所以如果有4颗cpu ,每个cpu如果都本地内存,每个cpu在使用数据向所属的本地cpu内存发起请求,同时在本地内存中获取数据
http://yijiu.blog.51cto.com
但是,如果没有数据,也很可能被其他cpu占用了,所以很有可能有这样的结果:
当一个进程被从cpu2 调到cpu0上来执行的时候,那么它的数据则在cpu2上,所以cpu0不得向自己的内存控制器发送请求,而自己的内存控制器则去联系对方的内存控制器 ,对方的控制器再从而取得数据,从而返回数据
htt~p:/ /yi jiu.b log.51 cto.com
所以这样性能会下降,因此需要对cpu的使用需要关注
#每一段内存都被称为一个节点 node
以上为numa体系,因此在numa结构中,为了保证一个进程在cpu上运行时,保证数据读取都在本地节点上进行,那么则将进程绑定在cpu上;如果仅有一颗cpu也应该将进程绑定在cpu上,因为内部可能有多个核心,这些核心使用的数据有可能也是一段一段
上下文切换也是需要使用资源的对于某些执行频率特别高的服务,比如Nginx
这里考虑的仅是多核心,如果是单核心则无所谓
.blog.51cto.com
CPU跟外部某一设备通讯时,如何知道是否存在数据
通过三种方式:
1.轮询 忙等待,每隔一定时间就去扫描所有已注册的io端口
2.中断 事实上是一个电信号,如果发生变化的时候都会通知cpu,cpu接到信号之后立即切换中断上下文,说白了就是切换到内核模式,由内核来指挥cpu处理过程事件
因此,必须有一种方式让cpu自我感知有事件发生,而且可以立即切换中断上下文,让内核马上处理
如果多个cpu的话,意味着注册信号使用中断cpu时,只需中断其中某一颗就可以了
·cpu如何知道是哪个中断发生
在cpu中,存在一个特殊的物理芯片:可中断控制器
中断控制器中有很多针脚,每个针脚,表示一个中断线,简单来讲是可以引用一个中断,但是中断线非常有限,所以使得一个针脚来标识一个中断导致io过多不够使用。
事实上可以通过中断向量来标识不同中断的,因此每个io设备发送中断时不再通过针脚,而是通过中断号(中断请求)来标识的,cpu正式通过这个标识来判断哪个发生中断,接下来通知内核,由内核来控制cpu进行切换中断上下文
·中断通常必须立即切换
中断分为上半部和下半部,一旦中断发送,内核被唤醒之后立即着手分配一个能够找到此中断请求的中断处理程序来尝试处理中断,比如一个网卡所传来的数据加载到内核的某个内存区域中,比如网卡缓冲或者内核缓冲区当中,而后是否立即处理需要看其紧急程序,如果不是非常紧急一旦处理结束,cpu继续运行之前中断时被打断的进程,当进程处理完了再由内核着手
无论等待的时间与否,只要时间消耗完必须切换回去,让其他进程运行,等其他进程执行完成之后再由这个没有执行完的请求继续
·现在的问题是,当运行完后是否处理中断:
需要取决于内核调度,所以下半部并不是立即执行的而是由内核调度决定的
http://
例:
假如io是个网卡,有人发起了ping请求,或者web服务上传的请求,这个请求包含多个报文,报文不能立即全部被接受进来,那么来一个报文,网卡则接收到一个信号,接收到一个信号则发起一个中断,那cpu则切换到中断上下文由内核将数据读取到缓冲区中,来一个报文中断一次,很显然cpu会频繁中断,因此生产能力受到影响,因此有了第三种方式 DMA
3.DMA
事实上多信号或报文进行处理时,内核指定cpu告知DMA 内存访问控制器,由他来指挥,将数据都放到已经分配到内存区域中某个连续的空间中,所以DMA取得了总线控制权,将数据都读取到内存中,当某一事件结束后,中断控制器自动向cpu发起请求,告知任务已完成,接下来由内核进行处理
实际中的io设备不止一个,硬盘可能有多快 键盘 网卡等,因此这些io设备的中断注册的时候,有可能被分配到多个cpu中,以避免cpu被频繁打断的
·这样就有另外的问题,比如:
如果有多个核心的话,打断的有2个nginx的进程,为了保证nginx避免进程切换,于是将两个核心隔离出来,不让其他进程使用,但是并不意味着cpu不处理中断,所以很有可能某些io硬件设备在其中断注册时仍然分配至这两个cpu进行处理,也就是说这两个进程仍然会被打断,避免这类情况可以将某些中断从这里隔离出来,不让cpu处理中断即可
网络IO
对于网络来讲,比如一个web服务,有很多用户对web服务器发送请求,当一个用户请求介入进来的时候,如何确保哪些是维持的
很显然哪些用户请求来临之后需要进行响应,因此第一个用户请求接入进来还没来得及响应第二个用户又接入进来,在处理时有可能先处理先来的请求,那如何知道有多少个请求,每个请求都是谁的:
在内存中使用特定的内存数据结构来维持每个链接,因此简单的说当用户请求接入进来之后内核要为其创建一个套接字文件,这个套接字建立两段: 源地址源端口 以及 目标地址目标端口,而后将绘话转交服务进行处理,当处理结束之后内核要重新封装一个响应报文发送给用户,这里标记是要考内存中标识的信息进行追踪的,这就是为什么此前说到的套接字文件,它需要占据一个文件描述符,为了保证当前系统上能够公平的使用多个文件,所以系统默认设定了单个进程能够打开单个文件描述符的数量是有上限的,因此某进程非常繁忙,需要大量处理请求,需要调整文件描述符
yijiu
参数的调整

如图所示,当cpu有多颗时,因此两颗cpu 8个核心,cpu 0-3 在第一颗 ,cpu4-7 在第二颗cpu上
yijiu
实现本地内存访问,有三个步骤:
1.给出本地内存控制器的地址
2.内存控制器设置对内存地址的访问
3.cpu执行操作
如果跨节点访问,需要多出一个步骤,而这多出的步骤则花费的时间多的多
使用taskset设置亲缘性
如何标识处理器
处理器是由掩码进行标志,通常是16进制的,因此0x00000001 表示处理器0
0x00000003 代表处理器 0 和 1
#盗贴死全家
执行以下命令,使用处理器或者您要捆绑到的处理器掩码替换 mask ,使 用您要更改亲和性的进程的进程 ID 替换 pid。
taskset -p mask pid
#盗贴死全家
列:
使用 -c 参数指定绑定在哪个cpu上:
taskset -c 0,5,7-9 mask pid
如下所示:
将httpd进程进行绑定
[root@test ~]# /etc/init.d/httpd start
Starting httpd: [ OK ]
[root@test ~]# ps -aux | grep httpd
Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ
root 2071 0.1 1.0 297764 10772 ? Ss 18:52 0:00 /usr/sbin/httpd
apache 2073 0.0 0.5 297764 5876 ? S 18:52 0:00 /usr/sbin/httpd
apache 2074 0.0 0.5 297764 5876 ? S 18:52 0:00 /usr/sbin/httpd
apache 2075 0.0 0.5 297764 5876 ? S 18:52 0:00 /usr/sbin/httpd
apache 2076 0.0 0.5 297764 5876 ? S 18:52 0:00 /usr/sbin/httpd
apache 2077 0.0 0.5 297764 5876 ? S 18:52 0:00 /usr/sbin/httpd
apache 2078 0.0 0.5 297764 5876 ? S 18:52 0:00 /usr/sbin/httpd
apache 2079 0.0 0.5 297764 5876 ? S 18:52 0:00 /usr/sbin/httpd
apache 2080 0.0 0.5 297764 5876 ? S 18:52 0:00 /usr/sbin/httpd
root 2084 0.0 0.0 105300 840 pts/0 S+ 18:52 0:00 grep httpd
httpd有很多进程其中有个进程id号位2073
那此时2073到底运行在哪个cpu上:
使用ps -axo pid,psr 进行观测,psr是进程运行在哪个处理器上
当前我们系统只有2颗cpu
[root@test ~]# grep processor /proc/cpuinfo
processor : 0
processor : 1
[root@test ~]# ps -axo pid,psr | grep 2073
2073 0
可以看到是运行在第0颗cpu上的 #盗 贴 死全家
如果没有做调度,它会一直工作在这个cpu上,如果被大量访问,有可能被调度到不同的cpu上去
那么我们想将这个进程运行在cpu1上:
[root@test ~]# taskset -pc 1 2073
pid 2073's current affinity list: 0,1 #表示2073id号可以在 0-1进行调度
pid 2073's new affinity list: 1 #表示这个id绑定在cpu1上
激活进程不然处于休眠状态,需要对其作ab压测即可
当然也可以在执行某一进程的时候明确指定使用哪个cpu
将参数加上mask 即可
taskset mask --program(启动程序)
直接运行在指定的cpu上
例:
taskset -c 0,2 httpd
然后查看进程
ps -aux | grep httpd
ps axo pid,psr | grep -E "pid|pid"
对其作压力测试页不会发生改变,只在两个cpu上进行调度
中断和IRQ调节 #盗贴死全家
IRQ : 为中断请求
查看当前系统有哪些中断,而这些中断都绑定在哪些cpu上
中断在/proc/interrupts #盗贴死全家 可以看到:
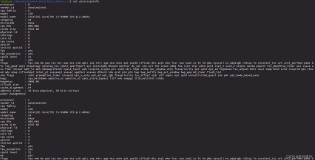
[root@test ~]# cat /proc/interrupts
CPU0 CPU1
0: 148 0 IO-APIC-edge timer
1: 7 1 IO-APIC-edge i8042
3: 0 1 IO-APIC-edge
4: 1 0 IO-APIC-edge
7: 0 0 IO-APIC-edge parport0
8: 0 0 IO-APIC-edge rtc0
9: 0 0 IO-APIC-fasteoi acpi
12: 105 1 IO-APIC-edge i8042
14: 212 159 IO-APIC-edge ata_piix
15: 84 24 IO-APIC-edge ata_piix
16: 0 0 IO-APIC-fasteoi Ensoniq AudioPCI
17: 25409 1042 IO-APIC-fasteoi ehci_hcd:usb1, ioc0
18: 39 0 IO-APIC-fasteoi uhci_hcd:usb2
19: 32792 2651 IO-APIC-fasteoi eth0, eth1
24: 0 0 PCI-MSI-edge pciehp
25: 0 0 PCI-MSI-edge pciehp
26: 0 0 PCI-MSI-edge pciehp
27: 0 0 PCI-MSI-edge pciehp
28: 0 0 PCI-MSI-edge pciehp
29: 0 0 PCI-MSI-edge pciehp
30: 0 0 PCI-MSI-edge pciehp
31: 0 0 PCI-MSI-edge pciehp
32: 0 0 PCI-MSI-edge pciehp
33: 0 0 PCI-MSI-edge pciehp
34: 0 0 PCI-MSI-edge pciehp
35: 0 0 PCI-MSI-edge pciehp
36: 0 0 PCI-MSI-edge pciehp
37: 0 0 PCI-MSI-edge pciehp
38: 0 0 PCI-MSI-edge pciehp
39: 0 0 PCI-MSI-edge pciehp
40: 0 0 PCI-MSI-edge pciehp
41: 0 0 PCI-MSI-edge pciehp
42: 0 0 PCI-MSI-edge pciehp
43: 0 0 PCI-MSI-edge pciehp
44: 0 0 PCI-MSI-edge pciehp
45: 0 0 PCI-MSI-edge pciehp
46: 0 0 PCI-MSI-edge pciehp
47: 0 0 PCI-MSI-edge pciehp
48: 0 0 PCI-MSI-edge pciehp
49: 0 0 PCI-MSI-edge pciehp
50: 0 0 PCI-MSI-edge pciehp
51: 0 0 PCI-MSI-edge pciehp
52: 0 0 PCI-MSI-edge pciehp
53: 0 0 PCI-MSI-edge pciehp
54: 0 0 PCI-MSI-edge pciehp
55: 0 0 PCI-MSI-edge pciehp
NMI: 0 0 Non-maskable interrupts
LOC: 85179 56618 Local timer interrupts
SPU: 0 0 Spurious interrupts
PMI: 0 0 Performance monitoring interrupts
IWI: 0 0 IRQ work interrupts
RES: 5023 5078 Rescheduling interrupts
CAL: 60 8613 Function call interrupts
TLB: 1608 2010 TLB shootdowns
TRM: 0 0 Thermal event interrupts
THR: 0 0 Threshold APIC interrupts
MCE: 0 0 Machine check exceptions
MCP: 18 18 Machine check polls
ERR: 0
MIS: 0
可以看到每个中断号,中断是由哪个硬件设备发出的都有线上
[root@test ~]# cat /proc/interrupts | grep eth
19: 32928 2736 IO-APIC-fasteoi eth0, eth1
/proc/interrupts显示了每个io设备中的每个cpu曾经处理过的设备的中断数
可以看到17号中断被处理的比较多:
17: 25409 1042 IO-APIC-fasteoi ehci_hcd:usb1, ioc0
因此不同的硬件设备,由哪个cpu处理是分配好的
IRQ中有类似于 smp_affinity属性,用于定义通过某个中断绑定在cpu上
当接收到一个中断以后,这个中断该由中断路由进行处理(ISR)
因此IRQ的数值中断近似性值是保存的相关的 /proc/irq/某个中断号/smp_affinity文件中
以eth0为例:
[root@test ~]# grep eth0 /proc/interrupts
19: 33226 2915 IO-APIC-fasteoi eth0, eth1
里面定义了eth0和eth1 的网卡中断号是19,然后找irq为19的smp_affinity文件:
[root@test ~]# cat /proc/irq/19/smp_affinity
03
其中 f为所有cpu,如果是0是第0个cpu , 1就为1号cpu
有些特定的硬件,在启动的时候就已经注册在cpu上,但是在公共硬件,比如网卡或硬盘,有可能是由内核进行调度的并且是不断进行调度的
如果想设定一个特定cpu的话,将其隔离出来,要保证没有被任何中断被处理
去扫描每个目录的中断号,只要它的值对应的是这个cpu编号的话,就挑出来再调整到其他cpu上去
只需要echo 一个 cpu的编号直接到对应的中断号的smp_affinity文件里即可
[root@test ~]# echo 0 > /proc/irq/19/smp_affinity
这样的过程被称为隔离中断,也可以叫中断的亲缘性
#盗贴死全家
本文转自zuzhou 51CTO博客,原文链接:http://blog.51cto.com/yijiu/1702204