Don’t confuse error 823 and error 832
本文大意:
错误832:
A page that should have been constant has changed (expected checksum: 1dcb28a7, actual checksum: 68c626bb, database 13, file 'E:\Program Files\microsoft sql server\MSSQL\data\BlahBlah.mdf', page (1:112644)). This usually indicates a memory failure or other hardware or OS corruption.
当一个页从磁盘读入,被标记为干净,如果被修改,变成脏页,检查checksum,发现checksum不再可用,832错误发生,发生这个错误一般出现在:1.内存问题,2.操作系统内存管理器问题,或者流氓程序写入到sql server。
1.通过微软产品支持,跟踪内存
2.通过替换法,替换内存
本文大意:
windows是支持大数据页的,关于windows大数据页的支持可以看Microsoft windows internal,X64支持2MB的大数据页。
有3个条件决定了是否使用大数据页:
1.sql server企业版
2.内存在8G以上
3.Lock Page in Memory权限
这个检查Lock Page in Memory和buffer pool使用AWE API没有关系,因为Large Page 也是不在work set中,也是不能被page out的。
如果Large Page启用会在error log中有一下信息:
2009-06-04 12:21:08.16 Server Large Page Extensions enabled.
2009-06-04 12:21:08.16 Server Large Page Granularity: 2097152
2009-06-04 12:21:08.21 Server Large Page Allocated: 32MB
但是有人会怀疑,明明没有开启TF 834为什么会用large page,因为TF834只限制buffer pool用不用large page。
开启834之后,buffer pool使用large page,因为large page通过virtualalloc()分配内存,比较慢所以会在开机时一次性分配。
启动时,分配算法:
1.会根据max server memory 和物理内存的最小值,若没有设置max server memory那么会分配所有内存。所以max server memeory的设置很总要
2.当使用large page的时候最让是sql server专用服务器。
3.如果不能分配,那么会分配的少一点,还是不能分配就会报错,服务无法启动。
注意:
内存size必须是连续的,并且在使用过程中buffer pool 不会自动增长。
使用large page导致开机时间变成,因为virtualalloc分配内存比较慢,并且时间不单单是分配内存的时间
总结
1.large page在内存>8gb,并有lock page权限
2.需要开启TF834,擦能让buffer pool使用large page
2.需要启动TF834,64操作系统并且已经启动了large page
3.large page 并不适用所有场景应该测试后再决定
本文大意:
作者在64BIT环境下看到一个错误,并且被问是否和MemToLeave有关。
作者解释了在64bit下并没有MemToLeave。
当32bit的年代,虚拟地址空间只有4个g,内核2g,用户2g,也可以通过4g选项调整为内核1g,用户3g,反正就是很少,设计者会为buffer pool保留地址,buffer pool有地址了,才不会影响内存的使用。buffer pool尽量大的保留地址空间了,但还是没有用完地址空间,因为有记下几个也需要用内存的:
1.线程stack,2.heap,3.SQL Server多页分配,4.其他DDL分配。
MemToLeave的意思就是留下来用来做别的事情,比如上面的,当服务启动的时候sql server 会先保留一部分地址空间,然后buffer pool保留地址空间,保留完之后,memtoleave释放地址空间。保留的地址的大小如下:线程堆栈大小*线程数+g参数的大小(默认256M)。
当64位来临,带来了大量的地址空间,所以没有必要在再服务启动时去保留地址空间,直接在需要用的时候分配就好了。
本文大意:
1.sql server 2005启动的时候发现一致性检查信息,但是不管数据库大小,检查都很快,为什么?
其实这些并不是实际上的检查,只是把上次最后一次检查的信息输出出来。当dbcc checkdb运行完之后会写入到boot page 上。启动服务的检查只是把boot page的信息print出来。
2.如何确定内存被使用在那个数据库?
sql server会占用大量内存,并且在没必要的时候是不会释放啊内存,除非os有内存压力。sql server主要的内存都使用在buffer pool中,还有一部分是使用在plan cache中,内存多可以减少io,可以减少编译所占用的时间。可以通过sys.dm_os_buffer_descriptors是buffer pool的信息,来确定是那个数据库占用了内存。当然也可以使用 dbcc memorystatus 来确定实例内存的使用。
3.数据库偶尔会出现SUSPECT和RECOVERY_PENDING的情况,就会需要通过被备份恢复,会有数据丢失的问题,如何解决?
这2个状态都是由故障恢复的时候出现的,当crash 恢复,读不到日志的时候会出现RECOVERY_PENDING。当日志可读,但是日志可以访问,但是无法完成恢复,一致性不对的时候会出现SUSPECT。有2个原因会导致恢复无法完成,1.日志数据问题,2.数据文件有问题。
还有一个会进入SUSPECT状态就是,当事务回滚,在回滚时出现错误。
可以使用备份来恢复数据,如果没有备份可以转入应急模式,来恢复。
4.高安全的数据库镜像使用witness是如何识别错误的?
错误识别有一下几种:
1.sql server实例级crash,每秒ping,能ping通但是发现sql server没有监听端口,立即报告
2.服务器级别crash,每秒ping 不能ping通马上报告
3.事务磁盘问题,当日志写入的队列太高,20秒后会写入到error log,40秒后认为log 磁盘offline,触发切换
4.数据库页出错,数据库会变成suspect状态,马上触发切换
5.如果文件或者文件组offline,primary正常,当碰到错误是切换。
本文大意:
内存浪费是可耻,特别是对于数据库来说,内存不足有一下几个特点:
1.物理io变多,不管读还是写
2.Lazy write变多
3.RESOURCE_SEMAPHORE等待变多,因为查询需要内存
4.大量的plan重编译,因为没有地方放plan cache
低数据密度:
使用sys.dm_os_buffer_descriptors可以看,到底buffer pool 里面有多少是空的,也就是浪费的。
低数据密度引起的原因一般就怎么几个:
1.宽行,那么就使用小的数据类型
2.分页,合理设置填充因子
3.行删除,导致内部碎片
低数据密度也会有一下几个代价:
1.io变多,因为空间被浪费了
2.磁盘空间被浪费
3.内存被浪费
低数据密度解决办法:
1.小数据类型
2.使用顺序的key,不要用随机降低分页
3.调整填充因子,填充因子本身就是一种浪费,所以要合理不能太大
4.重建索引
5.数据压缩
作者各处了一些脚本,自己去原文看,个人觉得还是蛮有用的。
本文大意:
在镜像服务器出现不能获取LOCK资源,很有趣,镜像是不会动的,为什么会出现这个错误?
原因很简单,比如一个事务主体回顾的时候,镜像也回滚,会滚就会产生事务,不信自己试试看。
LOCK结构是需要内存的,尽管很小,但是量大的时候,也是很可怕的,作者就认为,主体内存和镜像内存不太一致,导致主体上的lock大量,但是镜像上无法达到这个量导致的问题。那么把2边的内存搞成一样,更有甚者,很多回滚事务同时到镜像,也是会报这个错误,那么就继续加内存。
作者的意思是加内存。
本文大意:
作者给出了一个sql用来跟踪sql server 对虚拟内存的保存和使用。
本文大意:
VAS也就是虚拟地址,一般处理问题的时候很少去关注虚拟地址,虚拟地址使用VirtualAlloc*/VirtualFree*分配和释放,可以保留空间,也可以分配内存。
分配内存的方式是:先保留空间然后马上分配内存,绑定。VAS最小块为64KB,并以64KB为分配单元。
每个进程都有VAS,为了方便使用,在VAS分配之后会分配一个VAS,用来描述VAS。VirtualQuery API和sys.dm_virtual_address_dump都是使用VAD查信息。
VAS是很重要的资源,所以要跟踪这些资源,有2个工具:VASUMP,可以查看VAS利用但是没办法查看是哪个组件分配的。还有一个LEAKDIAG可以跟踪到组件级别的信息。
本文大意:
作者给出了一个跟踪线程stack的例子,来说明。可以使用sys.dm_os_threads,sys.dm_os_load_modules,sys.dm_os_virtual_address_dump连接获取VAS信息
SELECT
*
FROM
sys
.
dm_os_virtual_address_dump
a
INNER
JOIN
sys
.
dm_os_loaded_modules
b
ON
a
.
region_allocation_base_address
=
b
.
base_address
SELECT
*
FROM
sys
.
dm_os_virtual_address_dump
a
INNER
JOIN
sys
.
dm_os_threads
b
ON
a
.
region_allocation_base_address
=
b
.
thread_address
本文大意:
VAS绑定page是按需的,当page第一次被访问,绑定发生,一次只能一个页(绑定和提交有什么区别?绑定主要做些什么事情)。若第一次访问出现硬件页错误,那么OS严重VAD,VAS是否提交,若已经提交,OS会在内存中找一个空的页,初始化,并且把页绑定到虚拟地址,并填入数据结构。
当内存使用紧张,会启动回收机制,把进程中的要释放的页,page 到磁盘上,并修改数据结构,下次访问的时候就会找到,page 完成后,清零并放到free list中。
错误页,页错误有3种,最被人说道的是2种1:软错误,2.硬错误:
软错误出现在,第一次访问的时候,因为mmu中没有记录,但是数据页在内存中存在所以会出现。
硬错误,在内存中不存在在页面文件中有
物理页能够映射到不同的VAS,若值映射到一个VAS,我们就称私有的,否则就是共享的。使用virtualalloc都不能共享。
为了不让内存不切换的页面文件,可以使用page lock,page lock会打破系统内内存的平衡,可以使用lock page in memory权限打开。
4G调整和AWE是对虚拟地址的应用,4G调整,让内核模式只占用1G的内存空间,其他3G为用户模式地址。
为了能够访问4G以上内存,windows出了一个PAE,物理地址扩展,从32扩展到36能让windows 访问64G物理内存,相应出了AWE,通过virtualalloc分配地址并映射到物理内存的方式访问。AWE的内存os不能page,但是如果滥用,会导致性能问题,只能通过重启进程来释放。
本文大意:
内存压力分为2种,1.内部压力,2外部压力
外部内存压力又分为,静态内存压力:系统运行超出页面文件,导致系统内存不足,动态内存压力:os可用内存不足。
windows会通知进程当前内存是否有压力,或者你内存太多,应用程序实施的开辟内存或者收缩内存。
内部内存压力分为:1.内存压力,2.VAS压力。
外部内存压力导致内存收缩就可能英气内部内存压力。或者使用内存的限制也可能导致内存压力。处理方法:收缩stack,pool,把内存返回给内存管理器
造成VAS压力的情况2中:1.VAS碎片导致,无法开辟联系的VAS空间,2.VAS地址空间不够消耗的。VAS不足会导致,系统变慢,甚至进程终止。处理方法:收缩stack,pool。
以下几点要在实现,内存通知的时候注意:
外部内存压力出现:内存被page out,内存压力通知,释放内存,内存变多,有开辟,又有内存压力通知以此循环
当页面文件变小,没有通知,而是在下次分配的时候直接报out of memory
本文大意:
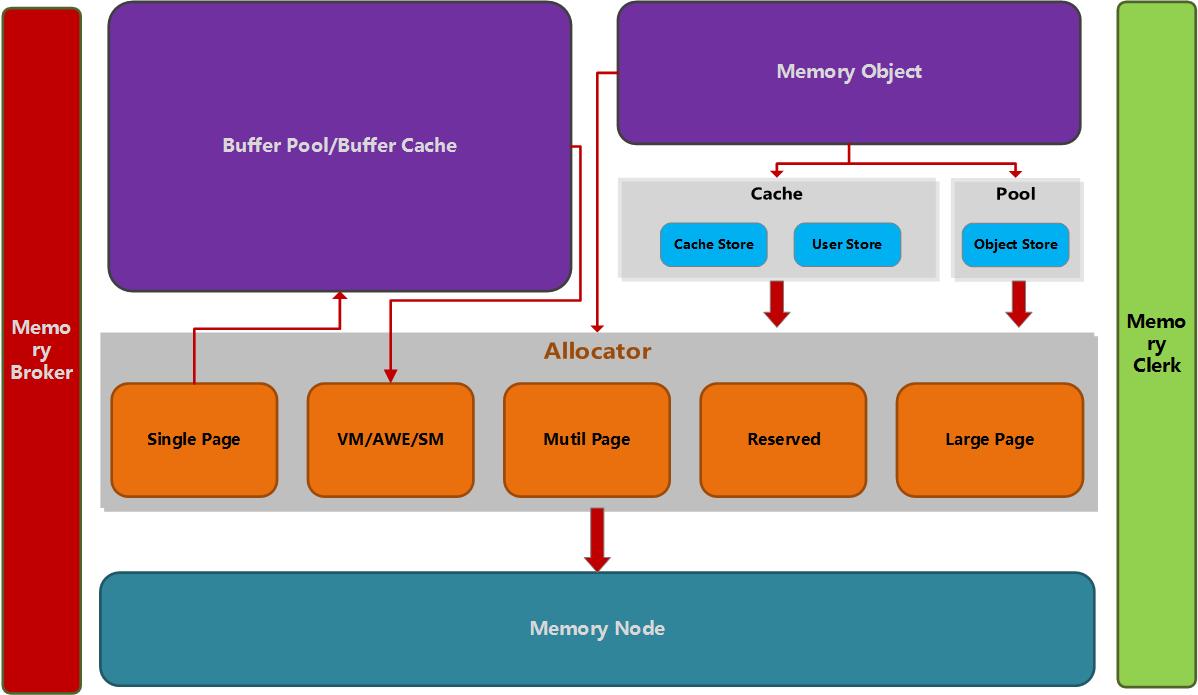
内存节点:主要提供本地内存的分配,由一些分配器组成。
内存clerk:clerk有4中类型,generic,cache store,user store,object store,可以用来跟踪内存的使用。
内存对象:内存对象的内存分配会被记录到clerk中。对象分为3种:1.可变内存对象常规heap,2.自增内存对象,是mark/shrink heap 3.固定长度的内存对象(内存对象内部还没有研究),内存对象和clerk都有页分配器地址,可以使用这个,查看对象对应的clerk。
buffer pool:sp_configure,有2个参数,最大服务内存,最小服务内存,用来控制buffer pool,但是不能控制其他组件。在服务启动的时候,sql server 会先保留一部分地址空间,是g参数+最大线程数*512KB(32位,64位为2M)就是MemtoLeave。然后再为buffer pool保留地址空间。buffer pool是根据内部内存和外部内存状况按需分配,计算目标内存,根据实际状况计算,并不引起内存压力,为了避免page,target经常被重新计算。buffer pool分配单元大小是8kb,其他组件需要内存时可以用buffer pool作为底层内存管理。在sql server 启动的时候buffer pool被设置为sqlos的单页分配器。对于大的组件都有自己的clerk,buffer pool也一样通过VM/AWE/SM分配内存。所有组件从buffer pool分配内存最好,所以小内存分配首选buffer pool,当需要大内存的时候从Mutil Page等分配。
buffer pool和AWE机制:有几个注意点:1.buffer pool通过clerk来记录VAS和物理页的分配,2.buffer pool使用4mb的VAS而不是大的,因为4MB容易对内存压力做出反应。3.2000中BP是一次性分配的,2005则是按需分配的。AWE不算workset,所以当启动AWE是,内存分配很难在里面发现。只有buffer pool能够map,unmap内存,所以其他组件不能使用AWE。
本文大意:
内存压力实际上可以分为VAS,物理内存,物理内存压力可能是外部压力,也可能是内部压力。
RM运行一些监控的指标,来判断是否有内存压力。一旦有问题就会广播到memory clerk。RM位于cpu节点上,所以可能有多个RM在运行。
多数内存的消耗,在clerk中都有记录,而且每个cpu节点都有一份clerk,RM先计算通知,然后通过list广播通知。
有几个注意点:1、RM有自己的调度器,2.RM运行在非抢占模式下,3.DAC节点没有RM
外部内存压力,RM,Buffer pool:BP被当做一个单页分配器,当出现外部内存压力,RM广播到clerk,BP重新计算可用内存,然后shrink,一直循环知道压力消失。但是不低于最小服务内存。
内部内存压力,RM,Buffer Pool:当buffer pool出现内存压力,sqlos通过一些机制打开RM内部内存压力的标识符,然后通知clerk,buffer pool并不对内部内存压力作出反应。动态修改最大服务内存,BP中75%的页被steal也会触发内部内存压力
VAS压力:当virtual或者shared memory分配4MB的地址空间失败,或者扫描VAS不存在4MB的连续空间时,通知VAS不足。2000中很难对VAS压力处理,在2005中会通知所有的clerk所有会有机会去shrink:1.shrink thread,2.卸载CLR,3.network lib收缩buffers。当buffer pool使用AWE时,发现有4MB的地址空间没有被使用的,也会被释放。
通过查看DMV:
SELECT
*
FROM
sys
.
dm_os_ring_buffers
WHERE
ring_buffer_type
=
'RING_BUFFER_RESOURCE_MONITOR'
随着时间,就很容易看出尽力了哪些内存压力。
本文大意:
2000中,cache主要是2种:data page cache:buffer pool,procedure cache:plan cache,plan cache通过buffer pool来完成对cache大小的控制,但是随着2005,cache变得越来越多,所以通过buffer pool控制是不太可以理解的,所以使用了通用的框架。
2005中有3总主要的cache 类型:cache store,user store,object store,其中又分为cache 和pool,其中 cache strore 和user store是cache,object cache 是pool
cache最主要的特点是:存放各种不同的数据,使用cost,结合lru来实现算法。pool:没有cost,也不需要做lru算法。并且有2个概念:生命周期控制,和可见性控制
生命周期的算法可以自己实现,也可以用框架的,比如cache store 是使用框架的,user store是自己一部分,框架一部分。生命周期通过应用计数管理,
可见性通过pin count管理
SQLOS 通过LRU算法实现了可见性和生命周期的控制,模拟LRU算法实现了时钟策略,外部时钟指针,和内部时钟指针。
外部时钟指针:通过RM而移动用来控制sql server 整体内存
内部时钟指针:用来控制cache 的大小,避免单个cache占用过大的内存。
时钟指针移动并不会影响存储,并且只有当2个指针都运行过的时候,内存块才会被回收。
本文大意:
64位中还是可以使用AWE的,AWE使用的步骤2步:1.分配内存(PFN),2.映射到VAS中。但是AWE分配的内存释放1.终止进程,2.程序控制释放。
通过页表项(PTE)来表示用来描述物理内存和VAS的映射,内部物理也通过PFN表示。OS有个库用来保存PFN,AWE分配后的PFN也保存在这里,一旦屋里也绑定到VAS,PFN会指回PTE。AWE分配的内存一旦与VAS绑定就是lock的不会被换出。
在64位下使用AWE有2个好处:1.不会被换出,对于NUMA有显示的驻留信息,当被page后很难再回到,原来的处理器,这样做显然会增加访问内存的消耗。2.锁定是workset和PFN锁定。这样可以让应用程序运行的较快,并且扩展性也较好。numa中buffer pool通过queryworkingsetex函数来查询内存所在的节点信息,因为是lock的所以只需要执行一次即可,提高了性能。唯一要注意的是内存不足时,lock的内存没办法被换出,获取可能内存。
本文大意:
Q:plan cache太大,会不会造成查找plan的瓶颈,如何控制cache大小?
A:内部指针用来控制内部单个cache的大小,以免出现性能问题,当框架预测过程最大cache到达了就会移动内部指针。还有当有一些项进入cache,具体多少项根据最大服务内存来确定,还有就是机器上的内存状态。
本文大意:
NUMA有2中方式,1:纯NUMA,2:交错是NUMA。NUMA是每个节点都有自己管理的内存,本地访问代价比远程访问代价小。交错numa是当成SMP访问,适合对NUMA没有优化的程序。
当配置成纯NUMA然后重启,windows就会识别,通过观察发现大多数内存都是开辟在第一个节点上,开辟的数量和可用内存数量,要启动的进程有关。这样的开辟方式会让内存出现不均衡的状况。
SQL Server Node有自己的内存管理和调度个数,io和其他组件,node的在线和离线通过affinity设置。在没有显示规定指定那个节点是,是通过环形的方式分配。
在SQL变慢,但是plan没有变化,造成性能下降,往往可能是内存的问题引起:
1.Node 0,系统启动过程中都是使用node 0的内存,方法是把node 0 offline
2.其他node,查看SFC,其他进程内存的内存消耗,和SQL Server的内存消耗。方法:在启动其他进程前,为sql server通过设置min,max一样来保留内存。
3.错误的配置SFC,导致内存的大量消耗。
本文大意:
Memory Broker:用来调整buffer pool,query execution,query优化,cache之间的内存分配,让内存更有效的使用。根据组件的内存需求调整内存分配,计算最优分配方案,然后广播到clerk。
SELECT
*
FROM
sys
.
dm_os_ring_buffer
WHERE
ring_buffer_type
=
'RING_BUFFER_MEMORY_BROKER'
NUMA:SQL Server 当本地无法分配内存的时候会从其他有内存的节点分配内存。每个节点内存分配为max/Nodes 如果设置了affinity那么就是 max/affinity Nodes
本文大意:
Q1:经常提到保留但是没有提交是讲的是VAS吗?
A1:是讲的是VAS,如当查询执行需要内存,那么就会去buffer pool里面保留内存,这个和VAS的保留和提交时2回事。
Q2:为什么不在保留的时候直接提交内存,而是需要先保留然后再提交
A2:先保留的理由有2个1:因为有很多的提交方式,如:AWE,file map等。2:VAS有限,以免发生不必要的争用。
Q3:保留的VAS能收缩或者增长吗?
A3:一旦被保留就不能grow,收缩,只能一起释放。
Q4:当VAS保留了,但是分配不到内存会发生什么情侣:
A4:造成这个往往是内存不足引起,会记录在错误日志上面,ring_buffer也会有一些错误,会有OOM通知。
本文大意:
Q1:时钟指针到底是干嘛用的?和lazywrite有关系吗?
A1:2005把cache分为2部分,BP和其他cache,lazywrite还是会控制数据页的内存消耗。在2005中引入了通用的cache框架,除了buffer pool之外都会使用这个,这个框架是由RM和一系列store组成,有3中store:cache,user,object。cache,user使用通用的基于cost的LRU算法,object只是一个pool不需要LRU算法和Cost。时钟指针所过之处,cost减半,当cost变0,就可以销毁了,当要重用的时候重新设置cost。指针分为2中:1.全局(外部),以全局内存做LRU算法。2.本地(内部):以本组件内存做LRU算法。尽管每个cache都有外部,但是都是同时运行的,就是为了模拟全局指针。RM通过通知内存压力来驱动外部指针。内部指针在cache需要被裁剪的时候运行,保证cache的内存占用的合理大小。
本文大意:
Q1:在sql server2000的MemToLeave的概念是否在64Bit下是否继续可用?
A1:是的,当组件需求大于8kb的时候还是会从MemToleave中分配。
Q2:大于8KB在MEMToLeave分配,那么在64位下还是如此吗?
A2:还是一样的8KB一样的会从MemToLeave分配,但是有的时候如果数据结构过大的,也会直接从MemToLeave分配
本文大意:
Q: 在我的2005中,开启了Page Lock碰到了一个问题,我怀疑是内存都没2005占用没有释放,倒是可用内存不足,导致服务器僵死。如何能和2000一样当出现内存压力的时候可以释放呢?
A: 在2005中不管是不是Page lock都会对内存压力做出反应。没有释放内存可能是没有cpu时钟去运行释放的问题造成。对于page lock的要设置max server memory,有几个max server memory的建议配置:
< 4GB 512MB - 1GB
4-32GB 1GB - 2GB
32GB - 128GB 2GB-4GB
128GB - 4GB-
有记下几点要注意:
1.当服务器运行在内存的边界,需要设置max server memroy
2.在高峰期的时候,注意,你的max server memory是否设置在一个合理的值中
3.内存越多max的设置越重要
4.通过测试,或者基线寻址自己的max server memory
5.max worker thread,stacj 在32为512KB,在64为2MB,在IA64中为4mb,所以设置的时候注意是否会引起内存问题
6.max server memory 只对BP起作用,对其他组件没有作用
7.对于外部组件,如xps,com的内存分配不受max server memory控制