1 前言
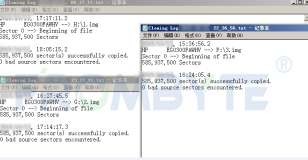
笔者公司内有一套GlusterFS分布式存储,最近数据分区的文件系统提示错误,群集有一个Brick需要替换掉。
基于稳妥操作的原则,笔者要先搭建测试环境并通过测试后才能在真实环境中执行,以下是笔者的测试文档,给有需要的博友参阅,另外笔者在发表本文时已经在生产环境通过验证。
服务器的故障日志(有修复文件系统方法的博友欢迎指教):
|
1
|
cat
/var/log/messages
|
可以看到如下信息:
|
1
|
Mar 21 14:58:04 GH01 kernel: XFS (dm-5): xfs_log_force: error 5 returned.
|
2 实践部分
2.1 环境信息
2.1.1 主机信息
GlusterH0[1-5]:
hostname=GlusterH0[1-5].cmdschool.org
ipaddress=10.168.0.19[1-5]
2.1.2 名称解析配置
In GlusterH0[1-6]
|
1
2
3
4
5
|
echo
"10.168.0.191 GlusterH01.cmdschool.org GH01"
>>
/etc/hosts
echo
"10.168.0.192 GlusterH02.cmdschool.org GH02"
>>
/etc/hosts
echo
"10.168.0.193 GlusterH03.cmdschool.org GH03"
>>
/etc/hosts
echo
"10.168.0.194 GlusterH04.cmdschool.org GH04"
>>
/etc/hosts
echo
"10.168.0.195 GlusterH05.cmdschool.org GH05"
>>
/etc/hosts
|
2.1.3 配置YUM源
In GlusterH0[1-6]
|
1
|
yum
install
-y centos-release-gluster38
|
2.1.4 关闭防火墙
In GlusterH0[1-6]
|
1
2
|
/etc/init
.d
/iptables
stop
chkconfig iptables off
|
2.2 配置数据存储根目录
In GlusterH0[1-5]
2.2.1 新建分区
|
1
|
fdisk
/dev/sdb
|
详细向导如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel with disk identifier 0x089fd1ab.
Changes will remain
in
memory only,
until
you decide to write them.
After that, of course, the previous content won't be recoverable.
Warning: invalid flag 0x0000 of partition table 4 will be corrected by w(rite)
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (
command
'c'
) and change display
units
to
sectors (
command
'u'
).
Command (m
for
help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-26108, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-26108, default 26108):
Using default value 26108
Command (m
for
help): w
The partition table has been altered!
Calling ioctl() to re-
read
partition table.
Syncing disks.
|
2.2.2 发现并校验
|
1
2
|
partx
/dev/sdb
ls
/dev/sdb
*
|
2.2.3 创建文件系统
|
1
|
mkfs.xfs -i size=512
/dev/sdb1
|
2.2.4 配置挂载
|
1
2
3
|
mkdir
-p
/data
echo
'/dev/sdb1 /data xfs defaults 1 2'
>>
/etc/fstab
mount
-a &&
mount
|
2.3 配置glusterfs服务端
In GlusterH0[1-5] :
2.3.1 安装yum源
|
1
|
yum
install
-y glusterfs-server
|
2.3.2 启动服务
|
1
2
|
/etc/init
.d
/glusterd
start
chkconfig glusterd on
|
2.4 配置信任池
In GlusterH01:
|
1
2
3
|
gluster peer probe GH02
gluster peer probe GH03
gluster peer probe GH04
|
显示如成功信息:
|
1
|
peer probe: success.
|
检查信任池状态
|
1
|
gluster peer status
|
显示如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
Number of Peers: 3
Hostname: GH02
Uuid: e935be20-6157-4bc6-804b-a6901850211f
State: Accepted peer request (Connected)
Hostname: GH03
Uuid: d91cf978-71d7-4734-b395-fae7ccf4c040
State: Accepted peer request (Connected)
Hostname: GH04
Uuid: e05ea224-72f7-48c5-a73a-eeeb253d171d
State: Accepted peer request (Connected)
|
检查本与其他服务器的连接状态
|
1
|
netstat
-antp |
grep
glusterd
|
显示如下:
|
1
2
3
4
5
6
7
|
tcp 0 0 0.0.0.0:24007 0.0.0.0:* LISTEN 1213
/glusterd
tcp 0 0 10.168.0.191:24007 10.168.0.192:49150 ESTABLISHED 1213
/glusterd
tcp 0 0 10.168.0.191:49149 10.168.0.193:24007 ESTABLISHED 1213
/glusterd
tcp 0 0 10.168.0.191:24007 10.168.0.193:49149 ESTABLISHED 1213
/glusterd
tcp 0 0 10.168.0.191:49151 10.168.0.192:24007 ESTABLISHED 1213
/glusterd
tcp 0 0 10.168.0.191:49150 10.168.0.194:24007 ESTABLISHED 1213
/glusterd
tcp 0 0 10.168.0.191:24007 10.168.0.194:49151 ESTABLISHED 1213
/glusterd
|
注:以上可以看出本机与其他的每个brick都有两个TCP连接,一共6个。
2.5 配置GlusterFS卷
2.5.1 配置存储位置
In GlusterH0[1-4] :
|
1
|
mkdir
-p
/data/brick1/gv0
|
2.5.2 创建Gluster卷
In GlusterH01 :
|
1
|
gluster volume create gv0 replica 2 transport tcp GH01:
/data/brick1/gv0
GH02:
/data/brick1/gv0
GH03:
/data/brick1/gv0
GH04:
/data/brick1/gv0
|
显示如成功信息:
|
1
|
volume create: gv0: success: please start the volume to access data
|
2.5.3 启动GlusterFS卷
In GlusterH01 :
|
1
|
gluster volume start gv0
|
显示如成功信息:
|
1
|
volume start: gv0: success
|
2.5.4 验证卷的信息
In GlusterH01 :
|
1
|
gluster volume info
|
显示如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
Volume Name: gv0
Type: Distributed-Replicate
Volume ID: cfea514c-cdce-4ae4-bcd9-bf56f4173271
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-
type
: tcp
Bricks:
Brick1: GH01:
/data/brick1/gv0
Brick2: GH02:
/data/brick1/gv0
Brick3: GH03:
/data/brick1/gv0
Brick4: GH04:
/data/brick1/gv0
Options Reconfigured:
transport.address-family: inet
performance.readdir-ahead: on
nfs.disable: on
|
2.6 配置Gluster客户端
In GlusterH01 :
2.6.1 安装客户端相关包
|
1
|
yum
install
-y glusterfs-fuse
|
2.6.2 手动挂载卷gv0到本地
|
1
|
mount
-t glusterfs GH01:
/gv0
/mnt
|
2.7 测试Gluster卷
2.7.1 写入测试
In GlusterH01 :
|
1
|
for
i
in
`
seq
-w 1 100`;
do
cp
-rp
/var/log/messages
/mnt/copy-test-
$i;
done
|
2.7.2 写入确认
In GlusterH01 :
|
1
|
ls
-lA
/mnt/
|
wc
-l
|
In GlusterH0[1-4] :
|
1
|
ls
-lA
/data/brick1/gv0/
|
2.8 模拟brick故障
2.8.1 查看当前存储状态
In GlusterH01 :
|
1
|
gluster volume status
|
显示如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
Status of volume: gv0
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick GH01:
/data/brick1/gv0
49153 0 Y 1447
Brick GH02:
/data/brick1/gv0
49153 0 Y 1379
Brick GH03:
/data/brick1/gv0
49153 0 Y 1281
Brick GH04:
/data/brick1/gv0
49153 0 Y 1375
Self-heal Daemon on localhost N
/A
N
/A
Y 1506
Self-heal Daemon on GH02 N
/A
N
/A
Y 1440
Self-heal Daemon on GH04 N
/A
N
/A
Y 1430
Self-heal Daemon on GH03 N
/A
N
/A
Y 1430
Task Status of Volume gv0
------------------------------------------------------------------------------
There are no active volume tasks
|
注:注意到Online项全部为“Y”
2.8.2 制造故障
In GlusterH01 :
|
1
|
vim
/etc/fstab
|
注释掉如下行:
|
1
|
#/dev/sdb1 /data xfs defaults 1 2
|
重启服务器
|
1
|
reboot
|
2.8.3 查看当前存储状态
In GlusterH01 :
|
1
|
gluster volume status
|
显示如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
Status of volume: gv0
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick GH01:
/data/brick1/gv0
N
/A
N
/A
N N
/A
Brick GH02:
/data/brick1/gv0
49153 0 Y 1379
Brick GH03:
/data/brick1/gv0
49153 0 Y 1281
Brick GH04:
/data/brick1/gv0
49153 0 Y 1375
Self-heal Daemon on localhost N
/A
N
/A
Y 1484
Self-heal Daemon on GH02 N
/A
N
/A
Y 1453
Self-heal Daemon on GH03 N
/A
N
/A
Y 1443
Self-heal Daemon on GH04 N
/A
N
/A
Y 1444
Task Status of Volume gv0
------------------------------------------------------------------------------
There are no active volume tasks
|
注:注意到GH01的Online项为“N”
注:文件系统故障,假设物理硬盘没有问题或已经更换阵列中的硬盘
2.9 恢复故障brick方法
2.9.1 结束故障brick的进程
In GlusterH01 :
|
1
|
gluster volume status
|
显示如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
Status of volume: gv0
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick GH01:
/data/brick1/gv0
N
/A
N
/A
N N
/A
Brick GH02:
/data/brick1/gv0
49153 0 Y 1379
Brick GH03:
/data/brick1/gv0
49153 0 Y 1281
Brick GH04:
/data/brick1/gv0
49153 0 Y 1375
Self-heal Daemon on localhost N
/A
N
/A
Y 1484
Self-heal Daemon on GH02 N
/A
N
/A
Y 1453
Self-heal Daemon on GH03 N
/A
N
/A
Y 1443
Self-heal Daemon on GH04 N
/A
N
/A
Y 1444
Task Status of Volume gv0
------------------------------------------------------------------------------
There are no active volume tasks
|
注:如果状态Online项为“N”的GH01存在PID号(不显示N/A)应当使用如下命令结束掉进程方可继续下面步骤。
|
1
|
kill
-15 pid
|
2.9.2 创建新的数据目录
In GlusterH01:
|
1
|
mkfs.xfs -i size=512
/dev/sdb1
|
编辑fstab
|
1
|
vim
/etc/fstab
|
去掉注释:
|
1
|
/dev/sdb1
/data
xfs defaults 1 2
|
重新挂载文件系统:
|
1
|
mount
-a
|
增加新的数据存放文件夹(不可以与之前目录一样)
|
1
|
mkdir
-p
/data/brick1/gv1
|
2.9.3 查询故障节点的备份节点(gh02)目录的扩展属性
In GlusterH01:
|
1
|
ssh
gh02 getfattr -d -m. -e hex
/data/brick1/gv0
|
显示如下:
|
1
2
3
4
5
6
|
getfattr: Removing leading
'/'
from absolute path names
# file: data/brick1/gv0
security.selinux=0x756e636f6e66696e65645f753a6f626a6563745f723a686f6d655f726f6f745f743a733000
trusted.gfid=0x00000000000000000000000000000001
trusted.glusterfs.dht=0x0000000100000000000000007ffffffe
trusted.glusterfs.volume-
id
=0xcfea514ccdce4ae4bcd9bf56f4173271
|
2.9.4 挂载卷并触发自愈
In GlusterH01:
1)将卷挂到mnt目录下
|
1
|
mount
-t glusterfs GH01:
/gv0
/mnt
|
2)新建一个卷中不存在的目录并删除
|
1
2
|
mkdir
/mnt/testDir001
rmdir
/mnt/testDir001
|
3)设置扩展属性触发自愈
|
1
2
|
setfattr -n trusted.non-existent-key -
v
abc
/mnt
setfattr -x trusted.non-existent-key
/mnt
|
2.9.5 检查当前节点是否挂起xattrs
In GlusterH01:
1)再次查询故障节点的备份节点(gh02)目录的扩展属性
|
1
|
ssh
gh02 getfattr -d -m. -e hex
/data/brick1/gv0
|
发现如下:
|
1
2
3
4
5
6
7
8
9
|
# file: data/brick1/gv0
security.selinux=0x756e636f6e66696e65645f753a6f626a6563745f723a686f6d655f726f6f745f743a733000
trusted.afr.dirty=0x000000000000000000000000
trusted.afr.gv0-client-0=0x000000000000000200000002
trusted.gfid=0x00000000000000000000000000000001
trusted.glusterfs.dht=0x0000000100000000000000007ffffffe
trusted.glusterfs.volume-
id
=0xcfea514ccdce4ae4bcd9bf56f4173271
getfattr: Removing leading
'/'
from absolute path names
|
注:留意第4行,表示xattrs已经将源标记为gh02:/data/brick1/gv0
2)检查卷的状态是否显示需要替换
In GlusterH01:
|
1
|
gluster volume heal gv0 info
|
显示如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
Brick GH01:
/data/brick1/gv0
Status: Transport endpoint is not connected
Number of entries: -
Brick GH02:
/data/brick1/gv0
/
Status: Connected
Number of entries: 1
Brick GH03:
/data/brick1/gv0
Status: Connected
Number of entries: 0
Brick GH04:
/data/brick1/gv0
Status: Connected
Number of entries: 0
|
注:状态提示传输端点未连接(第2行)
2.9.6 使用强制提交完成操作
In GlusterH01:
|
1
|
gluster volume replace-brick gv0 GH01:
/data/brick1/gv0
GH01:
/data/brick1/gv1
commit force
|
提示如下表示正常完成:
|
1
|
volume replace-brick: success: replace-brick commit force operation successful
|
注:也可以将数据恢复到另外一台服务器,详细命令如下(可选):
|
1
2
|
gluster peer probe GH05
gluster volume replace-brick gv0 GH01:
/data/brick1/gv0
GH05:
/data/brick1/gv0
commit force
|
2.9.7 检查存储的在线状态
In GlusterH01:
|
1
|
gluster volume status
|
显示如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
Status of volume: gv0
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick GH01:
/data/brick1/gv1
49153 0 Y 1658
Brick GH02:
/data/brick1/gv0
49153 0 Y 1406
Brick GH03:
/data/brick1/gv0
49153 0 Y 1371
Brick GH04:
/data/brick1/gv0
49153 0 Y 1406
Self-heal Daemon on localhost N
/A
N
/A
Y 1663
Self-heal Daemon on GH04 N
/A
N
/A
Y 1703
Self-heal Daemon on GH03 N
/A
N
/A
Y 1695
Self-heal Daemon on GH02 N
/A
N
/A
Y 1726
Task Status of Volume gv0
------------------------------------------------------------------------------
There are no active volume tasks
|
另外,如果更换到其他服务器状态显示如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
Status of volume: gv0
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick GH05:
/data/brick1/gv0
49152 0 Y 1448
Brick GH02:
/data/brick1/gv0
49153 0 Y 1270
Brick GH03:
/data/brick1/gv0
49153 0 Y 1328
Brick GH04:
/data/brick1/gv0
49153 0 Y 1405
Self-heal Daemon on localhost N
/A
N
/A
Y 1559
Self-heal Daemon on GH02 N
/A
N
/A
Y 1489
Self-heal Daemon on GH03 N
/A
N
/A
Y 1479
Self-heal Daemon on GH04 N
/A
N
/A
Y 1473
Self-heal Daemon on GH05 N
/A
N
/A
Y 1453
Task Status of Volume gv0
------------------------------------------------------------------------------
There are no active volume tasks
|