回到最初的Ceph运维工程师的问题,本系列讲述的是传统运维向新一代云运维转型之软件定义存储部分的转型,运维是企业业务系统从规划、设计、实施、交付到运维的最后一个步骤,也是重要的步骤。运维小哥最初的梦想搭建一个Ceph存储集群,对接云服务,底层存储实现高可用的数据访问架构。其中运维小哥经历了硬件选型、部署、调优、测试、高可用架构设计等的一系列转型的关卡学习,终于就要到最后的应用上线了。但是往往在生产环境中除了无单点、高可用的架构设计之外还需要平时做一些预案演练,比如:服务器断电、拔磁盘等问题,避免出现灾难故障影响业务正常运行。
关卡六:Ceph运维
重要度:五颗星
Ceph运维常用命令
一、集群
1、查看Ceph集群的状态
[root@node1 ~]# ceph health
2、查看Ceph的实时运行状态
[root@node1 ~]# ceph -w
3、检查信息状态信息
[root@node1 ~]# ceph -s
5、查看ceph存储空间
[root@node1 ~]# ceph df
二、mon
1、查看mon的状态信息
[root@@node1 ~]# ceph mon stat
2、查看mon的选举状态
[root@@node1 ~]# ceph quorum_status
3、删除一个mon节点
[root@node1 ~]# ceph mon remove node1
三、osd
1、查看ceph osd运行状态
[root@node1 ~]# ceph osd stat
2、查看osd映射信息&并从中可以得知副本数、pg数等等
[root@node1 ~]# ceph osd dump
3、查看osd的目录树
[root@node1 ~]# ceph osd tree
4、在集群中删除一个osd的host节点
[root@node1 ~]# ceph osd crush rm node2
5、把一个osd节点逐出集群
[root@node1 ~]# ceph osd out osd.3
6、把逐出的osd加入集群
[root@node1 ~]# ceph osd in osd.3
四、PG组
1、查看pg组的映射信息
[root@node1 ~]# ceph pg dump
#其中的[A,B]代表存储在osd.A、osd.B节点,osd.A代表主副本的存储位置
2、查看PG状态
[root@node1 ~]# ceph pg stat
3、查询一个pg的详细信息
[root@node1 ~]# ceph pg 0.26 query
4、查看pg中stuck的状态
[root@node1 ~]# ceph pg dump_stuck unclean
[root@node1 ~]# ceph pg dump_stuck inactive
[root@node1 ~]# ceph pg dump_stuck stale
5、恢复一个丢失的pg
[root@node1 ~]# ceph pg {pg-id} mark_unfound_lost revert
五、pool
1、查看ceph集群中的pool数量
[root@node1 ~]# ceph osd lspools
2、在ceph集群中创建一个pool
[root@node1 ~]# ceph osd pool create devin 100
#这里的100指的是PG组
3、在集群中删除一个pool
[root@node1 ~]# ceph osd pool delete devin devin –yes-i-really-really-mean-it #集群名字需要重复两次
具体详情可以查看:http://sangh.blog.51cto.com/6892345/1609290
Ceph运维必备技能
一技能:集群扩展
技能描述:
由于原集群存储空间不足或某种原因需要扩展集群,本技能主要是添加OSD节点和MON节点。
1.给新增OSD节点进行配置hosts文件
2.配置yum源
3.设置免密码登录
4.在admin节点开始进行安装
5.blabla….
有没有觉得上面操作很熟悉,是的没错,跟开始安装Ceph的时候步骤是一样的。
唯一需要注意的就是,安装完之后需要更新Crush Map信息。例如:
root@lnode1 ~# ceph osd crush add-bucket node4 host
root@node1 ~# ceph osd crush move node4 root=default
root@node1 ~# ceph osd crush add osd.$i 1.0 host=node4
#标注此处osd.$i的$i代表osd序号,1.0代表osd的权重
具体操作可以查看官网,这里就不在赘述了。
二技能:集群维护
技能描述:
随着集群和磁盘的增多会给运维带来很多烦恼和压力,本技能主要是易于管理磁盘和集群。
1.利用udev增强对Ceph存储设备的有效管理
默认情况下磁盘可以使用by-id/by-partlabel/by-parttypeuuid/by-partuuid/by-path/by-uuid等多种形式的名称对磁盘设备进行管理,但是在Ceph中,如果磁盘数量过多,加上为了更好区别每一个OSD对应的磁盘分区用途(比如filestore or journal),同时确保物理磁盘发生变更(故障盘替换后)后对应的名称不变,对OSD对应的磁盘设备命名提出新的管理需求。
2.OSD状态管理
这里简单讲述下OSD的各个状态,OSD状态的描述分为两个维度:up或者down(表明OSD是否正常工作),in或者out(表明OSD是否在至少一个PG中)。因此,对于任意一个OSD,共有四种可能的状态:
—— Up且in:说明该OSD正常运行,且已经承载至少一个PG的数据。这是一个OSD的标准工作状态;
—— Up且out:说明该OSD正常运行,但并未承载任何PG,其中也没有数据。一个新的OSD刚刚被加入Ceph集群后,便会处于这一状态。而一个出现故障的OSD被修复后,重新加入Ceph集群时,也是处于这一状态;
—— Down且in:说明该OSD发生异常,但仍然承载着至少一个PG,其中仍然存储着数据。这种状态下的OSD刚刚被发现存在异常,可能仍能恢复正常,也可能会彻底无法工作;
—— Down且out:说明该OSD已经彻底发生故障,且已经不再承载任何PG。
3.时间同步
不同节点间时钟应该同步,否则一些超时和时间戳相关的机制将无法正确运行,Ceph也会报出时钟偏移警告等,所以在开始之前我一直强调要安装NTP来同步时钟。
三技能:集群监控
技能描述:
任何一个软件都无法回避的一个问题,监控是运维人员必备的技能,可以随时掌握系统是否出现问题,以及如何定位问题。本技能主要是集群方面的监控。
1.集群监控状态
2.查看Ceph的实时运行状态
3.blabla…
这些命令我在文章开始就已经讲述了,这里不再赘述。
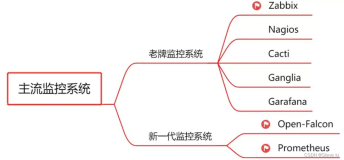
下面说下监控软件,目前主流的Ceph开源监控软件有:Calamari、VSM、Inkscope、Ceph-Dash、Zabbix等,下面简单介绍下各个开源组件。
Calamari对外提供了十分漂亮的Web管理和监控界面,以及一套改进的REST API接口(不同于Ceph自身的REST API),在一定程度上简化了Ceph的管理。最初Calamari是作为Inktank公司的Ceph企业级商业产品来销售,红帽2015年收购 Inktank后为了更好地推动Ceph的发展,对外宣布Calamari开源,秉承开源开放精神的红帽着实又做了一件非常有意义的事情。

优点:
q 轻量级
q 官方化
q 界面友好
缺点:
q 不易安装
q 管理功能滞后
Virtual Storage Manager (VSM)是Intel公司研发并且开源的一款Ceph集群管理和监控软件,简化了一些Ceph集群部署的一些步骤,可以简单的通过WEB页面来操作。

优点:
q 管理功能好
q 界面友好
q 可以利用它来部署Ceph和监控Ceph
缺点:
q 非官方
q 依赖OpenStack某些包
Inkscope 是一个 Ceph 的管理和监控系统,依赖于 Ceph 提供的 API,使用 MongoDB 来存储实时的监控数据和历史信息。

优点:
q 易部署
q 轻量级
q 灵活(可以自定义开发功能)
缺点:
q 监控选项少
q 缺乏Ceph管理功能
Ceph-Dash 是用 Python 开发的一个Ceph的监控面板,用来监控 Ceph 的运行状态。同时提供 REST API 来访问状态数据。

优点:
q 易部署
q 轻量级
q 灵活(可以自定义开发功能)
ZABBIX的Ceph插件可以在github上查找“Ceph-zabbix”
例如:Ceph中国社区群友磨磨的最新版插件https://github.com/zphj1987/ceph-zabbix-jewel
Ceph运维常见错误
问题一:
借用Ceph中国社区群友的截图,出现以下问题”error connecting to the cluster”一般都是因为Ceph集群节点时间、网络、Key等问题。

解决办法:
调整集群节点时间或提前设置好NTP服务,查看节点网络通信、网卡等是否有问题以及Ceph的Key。
问题二:
机器更换IP地址重启后,Ceph mon进程出现异常,无法启动
解决办法:
通过命令得到新的monmap,具体可以查看Ceph中国社区群友西昆仑的博客:https://my.oschina.net/myspaceNUAA/blog/534188
问题三:
很多新手在 初次搭建Ceph集群环境时,由于限于节点数和OSD资源的限制,集群状态未能达到完全收敛状态,即所有PG保持active+clean。排除OSD故障原因,此类问题,主要还是crush rule 耍了小把戏,只要我们看清本质,Ceph就服帖了。
因为默认的Crush Rule 设置的隔离是host 级,即多副本(如3副本)情况下,每一副本都必须分布在不同的节点上。如此一来,当节点数不满足大于或等于副本数时,PG的状态自然就不能 active+clean ,而会显示为“degraded”(降级)状态。
解决办法:
解决这个问题,可以从两方面入手:一是修改副本数,二是修改Crush Rule。
1.通过tell 命令在线修pool的副本数,并修改配置文件且同步到所有节点。 #保险起见,最好把MON和OSD关于副本数的选项都修改。
2. 修改默认crush rule,把隔离域换成 OSD。 #也就是Crush Map里面的rules选项。
好了,最后一篇文章到此结束,在本系列开头讲到随着云计算、大数据以及新兴的区块链等技术体系的迅猛发展,数据中心的扩容建设进入高峰期,云数据中心运维需求应运而生。传统的运维人员,以往接触的更多是硬件,如服务器、设备和风火水电;但是在云数据中心时代,运维人员已经从面向物理设备,转变为面向虚拟化、云的管理方式。
因此,云数据中心的运维对于传统的运维人员提出了新的能力要求——不仅要熟悉传统硬件设备,同时要掌握虚拟化、云系统的部署、监控和管理等运维能力。
通过九篇文章简单介绍了下传统运维向云运维或者说是传统运维向SDS运维的转型之路。文章涉及的比较基础,主要讲述了 一般企业使用Ceph经历几个难度关卡:硬件选型–>部署调优–>性能测试–>架构灾备设计–>部分业务上线测试–>运行维护(故障处理、预案演练等),加上作者水平有限,希望本系列文章能够给予Ceph新手参考。