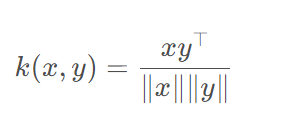项向量在Lucene中属于高级话题。利用项向量能实现很多很有意思的功能,比如返回跟当前商品相似的商品。当你需要实现返回与xxxxxxxx类似的东西时,就可以考虑使用项向量,在Lucene中是使用MoreLikeThis来实现。
项向量其实就是根据Term在文档中出现的频率和文档中包含Term的频率建立的数学模型,计算两个项向量的夹角的方式来判断他们的相似性。而Lucene5中内置的MoreLikeThis的实现方式却是使用打分的方式计算相似度,根据最终得分高低放入优先级队列,评分高的自然在队列最高处。
- /**
- * Create a PriorityQueue from a word->tf map.
- *
- * @param words a map of words keyed on the word(String) with Int objects as the values.
- */
- private PriorityQueue<ScoreTerm> createQueue(Map<String, Int> words) throws IOException {
- // have collected all words in doc and their freqs
- int numDocs = ir.numDocs();
- final int limit = Math.min(maxQueryTerms, words.size());
- FreqQ queue = new FreqQ(limit); // will order words by score
- for (String word : words.keySet()) { // for every word
- int tf = words.get(word).x; // term freq in the source doc
- if (minTermFreq > 0 && tf < minTermFreq) {
- continue; // filter out words that don't occur enough times in the source
- }
- // go through all the fields and find the largest document frequency
- String topField = fieldNames[0];
- int docFreq = 0;
- for (String fieldName : fieldNames) {
- int freq = ir.docFreq(new Term(fieldName, word));
- topField = (freq > docFreq) ? fieldName : topField;
- docFreq = (freq > docFreq) ? freq : docFreq;
- }
- if (minDocFreq > 0 && docFreq < minDocFreq) {
- continue; // filter out words that don't occur in enough docs
- }
- if (docFreq > maxDocFreq) {
- continue; // filter out words that occur in too many docs
- }
- if (docFreq == 0) {
- continue; // index update problem?
- }
- float idf = similarity.idf(docFreq, numDocs);
- float score = tf * idf;
- if (queue.size() < limit) {
- // there is still space in the queue
- queue.add(new ScoreTerm(word, topField, score, idf, docFreq, tf));
- } else {
- ScoreTerm term = queue.top();
- if (term.score < score) { // update the smallest in the queue in place and update the queue.
- term.update(word, topField, score, idf, docFreq, tf);
- queue.updateTop();
- }
- }
- }
- return queue;
- }
其实就是通过similarity来计算IDF-TF从而计算得分。
Lucene5中获取项向量的方法:
1.根据document id获取
- reader.getTermVectors(docID);
2.根据document id 和 FieldName
- Terms termFreqVector = reader.getTermVector(i, "subject");
下面是一个有关Lucene5中TermVector项向量操作的示例代码:
- package com.yida.framework.lucene5.termvector;
- import java.io.IOException;
- import java.nio.file.Paths;
- import org.apache.lucene.document.Document;
- import org.apache.lucene.index.DirectoryReader;
- import org.apache.lucene.index.IndexReader;
- import org.apache.lucene.index.Term;
- import org.apache.lucene.index.Terms;
- import org.apache.lucene.index.TermsEnum;
- import org.apache.lucene.search.BooleanClause;
- import org.apache.lucene.search.BooleanClause.Occur;
- import org.apache.lucene.search.BooleanQuery;
- import org.apache.lucene.search.IndexSearcher;
- import org.apache.lucene.search.TermQuery;
- import org.apache.lucene.search.TopDocs;
- import org.apache.lucene.store.Directory;
- import org.apache.lucene.store.FSDirectory;
- import org.apache.lucene.util.BytesRef;
- import org.apache.lucene.util.CharsRefBuilder;
- /**
- * 查找类似书籍-测试
- * @author Lanxiaowei
- *
- */
- public class BookLikeThis {
- public static void main(String[] args) throws IOException {
- String indexDir = "C:/lucenedir";
- Directory directory = FSDirectory.open(Paths.get(indexDir));
- IndexReader reader = DirectoryReader.open(directory);
- IndexSearcher searcher = new IndexSearcher(reader);
- // 最大的索引文档ID
- int numDocs = reader.maxDoc();
- BookLikeThis blt = new BookLikeThis();
- for (int i = 0; i < numDocs; i++) {
- System.out.println();
- Document doc = reader.document(i);
- System.out.println(doc.get("title"));
- Document[] docs = blt.docsLike(reader, searcher, i, 10);
- if (docs.length == 0) {
- System.out.println(" -> Sorry,None like this");
- }
- for (Document likeThisDoc : docs) {
- System.out.println(" -> " + likeThisDoc.get("title"));
- }
- }
- reader.close();
- directory.close();
- }
- public Document[] docsLike(IndexReader reader, IndexSearcher searcher,
- int id, int max) throws IOException {
- //根据文档id加载文档对象
- Document doc = reader.document(id);
- //获取所有的作者
- String[] authors = doc.getValues("author");
- BooleanQuery authorQuery = new BooleanQuery();
- //遍历所有的作者
- for (String author : authors) {
- //包含所有作者的书籍
- authorQuery.add(new TermQuery(new Term("author", author)),Occur.SHOULD);
- }
- //authorQuery权重乘以2
- authorQuery.setBoost(2.0f);
- //获取subject域的项向量
- Terms vector = reader.getTermVector(id, "subject");
- TermsEnum termsEnum = vector.iterator(null);
- CharsRefBuilder spare = new CharsRefBuilder();
- BytesRef text = null;
- BooleanQuery subjectQuery = new BooleanQuery();
- while ((text = termsEnum.next()) != null) {
- spare.copyUTF8Bytes(text);
- String term = spare.toString();
- //System.out.println("term:" + term);
- // if isNoiseWord
- TermQuery tq = new TermQuery(new Term("subject", term));
- //使用subject域中的项向量构建BooleanQuery
- subjectQuery.add(tq, Occur.SHOULD);
- }
- BooleanQuery likeThisQuery = new BooleanQuery();
- likeThisQuery.add(authorQuery, BooleanClause.Occur.SHOULD);
- likeThisQuery.add(subjectQuery, BooleanClause.Occur.SHOULD);
- //排除自身
- likeThisQuery.add(new TermQuery(new Term("isbn", doc.get("isbn"))),
- BooleanClause.Occur.MUST_NOT);
- TopDocs hits = searcher.search(likeThisQuery, 10);
- int size = max;
- if (max > hits.scoreDocs.length) {
- size = hits.scoreDocs.length;
- }
- Document[] docs = new Document[size];
- for (int i = 0; i < size; i++) {
- docs[i] = reader.document(hits.scoreDocs[i].doc);
- }
- return docs;
- }
- }
通过计算项向量夹角的方式判定相似度的代码示例:
- package com.yida.framework.lucene5.termvector;
- import java.io.IOException;
- import java.nio.file.Paths;
- import java.util.Iterator;
- import java.util.Map;
- import java.util.TreeMap;
- import org.apache.lucene.document.Document;
- import org.apache.lucene.index.DirectoryReader;
- import org.apache.lucene.index.IndexReader;
- import org.apache.lucene.index.Terms;
- import org.apache.lucene.index.TermsEnum;
- import org.apache.lucene.search.IndexSearcher;
- import org.apache.lucene.store.Directory;
- import org.apache.lucene.store.FSDirectory;
- import org.apache.lucene.util.BytesRef;
- import org.apache.lucene.util.CharsRefBuilder;
- /**
- * 利用项向量自动书籍分类[项向量夹角越小相似度越高]
- *
- * @author Lanxiaowei
- *
- */
- public class CategoryTest {
- public static void main(String[] args) throws IOException {
- String indexDir = "C:/lucenedir";
- Directory directory = FSDirectory.open(Paths.get(indexDir));
- IndexReader reader = DirectoryReader.open(directory);
- //IndexSearcher searcher = new IndexSearcher(reader);
- Map<String, Map<String, Integer>> categoryMap = new TreeMap<String, Map<String,Integer>>();
- //构建分类的项向量
- buildCategoryVectors(categoryMap, reader);
- getCategory("extreme agile methodology",categoryMap);
- getCategory("montessori education philosophy",categoryMap);
- }
- /**
- * 根据项向量自动判断分类[返回项向量夹角最小的即相似度最高的]
- *
- * @param subject
- * @return
- */
- private static String getCategory(String subject,
- Map<String, Map<String, Integer>> categoryMap) {
- //将subject按空格分割
- String[] words = subject.split(" ");
- Iterator<String> categoryIterator = categoryMap.keySet().iterator();
- double bestAngle = Double.MAX_VALUE;
- String bestCategory = null;
- while (categoryIterator.hasNext()) {
- String category = categoryIterator.next();
- double angle = computeAngle(categoryMap, words, category);
- // System.out.println(" -> angle = " + angle + " (" +
- // Math.toDegrees(angle) + ")");
- if (angle < bestAngle) {
- bestAngle = angle;
- bestCategory = category;
- }
- }
- System.out.println("The best like:" + bestCategory + "-->" + subject);
- return bestCategory;
- }
- public static void buildCategoryVectors(
- Map<String, Map<String, Integer>> categoryMap, IndexReader reader)
- throws IOException {
- int maxDoc = reader.maxDoc();
- // 遍历所有索引文档
- for (int i = 0; i < maxDoc; i++) {
- Document doc = reader.document(i);
- // 获取category域的值
- String category = doc.get("category");
- Map<String, Integer> vectorMap = categoryMap.get(category);
- if (vectorMap == null) {
- vectorMap = new TreeMap<String, Integer>();
- categoryMap.put(category, vectorMap);
- }
- Terms termFreqVector = reader.getTermVector(i, "subject");
- TermsEnum termsEnum = termFreqVector.iterator(null);
- addTermFreqToMap(vectorMap, termsEnum);
- }
- }
- /**
- * 统计项向量中每个Term出现的document个数,key为Term的值,value为document总个数
- *
- * @param vectorMap
- * @param termsEnum
- * @throws IOException
- */
- private static void addTermFreqToMap(Map<String, Integer> vectorMap,
- TermsEnum termsEnum) throws IOException {
- CharsRefBuilder spare = new CharsRefBuilder();
- BytesRef text = null;
- while ((text = termsEnum.next()) != null) {
- spare.copyUTF8Bytes(text);
- String term = spare.toString();
- int docFreq = termsEnum.docFreq();
- System.out.println("term:" + term + "-->docFreq:" + docFreq);
- // 包含该term就累加document出现频率
- if (vectorMap.containsKey(term)) {
- Integer value = (Integer) vectorMap.get(term);
- vectorMap.put(term, new Integer(value.intValue() + docFreq));
- } else {
- vectorMap.put(term, new Integer(docFreq));
- }
- }
- }
- /**
- * 计算两个Term项向量的夹角[夹角越小则相似度越大]
- *
- * @param categoryMap
- * @param words
- * @param category
- * @return
- */
- private static double computeAngle(Map<String, Map<String, Integer>> categoryMap,
- String[] words, String category) {
- Map<String, Integer> vectorMap = categoryMap.get(category);
- int dotProduct = 0;
- int sumOfSquares = 0;
- for (String word : words) {
- int categoryWordFreq = 0;
- if (vectorMap.containsKey(word)) {
- categoryWordFreq = vectorMap.get(word).intValue();
- }
- dotProduct += categoryWordFreq;
- sumOfSquares += categoryWordFreq * categoryWordFreq;
- }
- double denominator = 0.0d;
- if (sumOfSquares == words.length) {
- denominator = sumOfSquares;
- } else {
- denominator = Math.sqrt(sumOfSquares) * Math.sqrt(words.length);
- }
- double ratio = dotProduct / denominator;
- return Math.acos(ratio);
- }
- }
MoreLikeThis使用示例:
- package com.yida.framework.lucene5.termvector;
- import java.io.IOException;
- import java.nio.file.Paths;
- import org.apache.lucene.analysis.standard.StandardAnalyzer;
- import org.apache.lucene.document.Document;
- import org.apache.lucene.index.DirectoryReader;
- import org.apache.lucene.index.IndexReader;
- import org.apache.lucene.queries.mlt.MoreLikeThis;
- import org.apache.lucene.search.IndexSearcher;
- import org.apache.lucene.search.Query;
- import org.apache.lucene.search.ScoreDoc;
- import org.apache.lucene.search.TopDocs;
- import org.apache.lucene.store.Directory;
- import org.apache.lucene.store.FSDirectory;
- /**
- * MoreLikeThis[更多与此相似]
- *
- * @author Lanxiaowei
- *
- */
- public class MoreLikeThisTest {
- public static void main(String[] args) throws IOException {
- String indexDir = "C:/lucenedir";
- Directory directory = FSDirectory.open(Paths.get(indexDir));
- IndexReader reader = DirectoryReader.open(directory);
- IndexSearcher searcher = new IndexSearcher(reader);
- MoreLikeThis moreLikeThis = new MoreLikeThis(reader);
- moreLikeThis.setAnalyzer(new StandardAnalyzer());
- moreLikeThis.setFieldNames(new String[] { "title","author","subject" });
- moreLikeThis.setMinTermFreq(1);
- moreLikeThis.setMinDocFreq(1);
- int docNum = 1;
- Query query = moreLikeThis.like(docNum);
- //System.out.println(query.toString());
- TopDocs topDocs = searcher.search(query, Integer.MAX_VALUE);
- ScoreDoc[] scoreDocs = topDocs.scoreDocs;
- //文档id为1的书
- System.out.println(reader.document(docNum).get("title") + "-->");
- for (ScoreDoc sdoc : scoreDocs) {
- Document doc = reader.document(sdoc.doc);
- //找到与文档id为1的书相似的书
- System.out.println(" more like this: " + doc.get("title"));
- }
- }
- }
MoreLikeThisQuery使用示例:
- package com.yida.framework.lucene5.termvector;
- import java.io.IOException;
- import java.nio.file.Paths;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.analysis.standard.StandardAnalyzer;
- import org.apache.lucene.document.Document;
- import org.apache.lucene.index.DirectoryReader;
- import org.apache.lucene.index.IndexReader;
- import org.apache.lucene.queries.mlt.MoreLikeThis;
- import org.apache.lucene.queries.mlt.MoreLikeThisQuery;
- import org.apache.lucene.search.IndexSearcher;
- import org.apache.lucene.search.Query;
- import org.apache.lucene.search.ScoreDoc;
- import org.apache.lucene.search.TopDocs;
- import org.apache.lucene.store.Directory;
- import org.apache.lucene.store.FSDirectory;
- /**
- * MoreLikeThisQuery测试
- * @author Lanxiaowei
- *
- */
- public class MoreLikeThisQueryTest {
- public static void main(String[] args) throws IOException {
- String indexDir = "C:/lucenedir";
- Directory directory = FSDirectory.open(Paths.get(indexDir));
- IndexReader reader = DirectoryReader.open(directory);
- IndexSearcher searcher = new IndexSearcher(reader);
- String[] moreLikeFields = new String[] {"title","author"};
- MoreLikeThisQuery query = new MoreLikeThisQuery("lucene in action",
- moreLikeFields, new StandardAnalyzer(), "author");
- query.setMinDocFreq(1);
- query.setMinTermFrequency(1);
- //System.out.println(query.toString());
- TopDocs topDocs = searcher.search(query, Integer.MAX_VALUE);
- ScoreDoc[] scoreDocs = topDocs.scoreDocs;
- //文档id为1的书
- //System.out.println(reader.document(docNum).get("title") + "-->");
- for (ScoreDoc sdoc : scoreDocs) {
- Document doc = reader.document(sdoc.doc);
- //找到与文档id为1的书相似的书
- System.out.println(" more like this: " + doc.get("title"));
- }
- }
- }
注意MoreLikeThisQuery需要指定分词器,因为你需要指定likeText(即相似参照物),并对likeText进行分词得到多个Term,然后计算每个Term的IDF-TF最终计算得分。涉及到分词那就需要知道域的类型,比如你还必须指定一个fieldName即域名称,按照这个域的类型来进行分词,其他的参数moreLikeFields表示从哪些域里提取Term计算相似度。你还可以通过setStopWords去除likeText中的停用词。
最后说一点小技巧,reader.document(docId)根据docid可以加载索引文档对象,这个你们都知道,但它还有一个重载方法得引起你们的重视:

后面的Set集合表示你需要返回那些域值,不指定默认是返回所有Store.YES的域,这样做的好处就是减少内存占用,比如你确定某些域的值在你本次查询中你不需要返回给用户展示,那你可以在Set中不包含该域,就好比SQL里的select * from table 和 select id,name from table。
上面介绍了通过计算向量夹角和IDF-TF打分两种方式来计算相似度,你也可以实现自己的相似度算法,这个就超出了Lucene范畴了,那是算法设计问题了,好的算法决定了匹配的精准度。
如果你还有什么问题请加我Q-Q:7-3-6-0-3-1-3-0-5,
或者加裙 一起交流学习!
一起交流学习!
转载:http://iamyida.iteye.com/blog/2201196