大数据应用之双色球算奖平台总体设计数据规模估算篇
作者:张子良
版权所有,转载请注明出处
引子:什么才算大数据?
自从写了上一篇《大数据应用之双色球算奖平台总体设计大纲篇一》,受到许多园友的关注和指导,在此表示感谢,尤其是园友个人知识管理给出的一个评论,让我深思,原文如下“双色球算奖这么简单的活,也称大数据。先生:不是数据多,叫大数据。双色球算奖,用Oracle数据库的索引,1分钟内就算完。关键是人家不想这么快”。话不太好听,尤其是称我为先生那句,但却发人深思,是啊:到底什么是大数据呢?选择双色球算奖作为大数据应用的切入点是否合适呢?然后就是让我诧异的1分钟理论很是吓了我一跳的。
说一下自己的理解吧,大数据是指那些很大的数据集,大到传统的数据库软件工具已经无法采集、存储、管理和分析。大数据既有存储规模方面的考虑,同时也涉及到分析计算规模的考虑。之所以选择双色球算奖平台作为大数据应用的案例,也正是考虑到这两个方面的问题。其一,历史投注明细信息的存储,如果采用传统的关系型数据库,肯定是不合适,无论是分区还是分表,都无法解决根本问题。其二、当前投注规模的情况下,进行快速算奖,所要进行的计算规模肯定也不是一个传统方式能轻易解决的问题。
当然关于具体多大规模的数据才算大数据,目前为止尚未有一个官方的界定阈值的存在,规定超过多少算大数据,低于多少不算大数据的说法。既然没有标准,也就无所谓是与不是,见仁见智,不一而足。
一、概述 业务规则
双色球奖项设置和兑奖规则如下所示:
“双色球”彩票以投注者所选单注投注号码(复式投注按所覆盖的单注计)与当期开出中奖号码相符的球色和个数确定中奖等级:
一等奖:7个号码相符(6个红色球号码和1个蓝色球号码)(红色球号码顺序不限,下同)
二等奖:6个红色球号码相符;
三等奖:5个红色球号码和1个蓝色球号码相符;
四等奖:5个红色球号码或4个红色球号码和1个蓝色球号码相符;
五等奖:4个红色球号码或3个红色球号码和1个蓝色球号码相符;
六等奖:1个蓝色球号码相符(有无红色球号码相符均可)。
二、数据对象分析
既然是数据规模的评估,我们要解决的首先就是数据对象的确认。针对双色球算奖平台,我们需要关注那些数据对象呢?按照矛盾论的观点,事物的矛盾分为主要矛盾和次要矛盾,其中主要矛盾起决定性作用。所以在这里我们只考虑双色球算奖平台涉及的最主要的数据对象,而不考虑其他细节问题。
数据对象主要包括以下几个方面:
(1)销量统计:包括全国、分省市、销售网点的销量汇总统计数据。
(2)中奖统计:包括全国、分省市、销售网点的各奖项的中奖注数汇总统计数据。
(3)开奖号码:包括每一期开奖号码信息。
(4)奖金信息:包括每一期次各奖项奖金多少的统计数据。
(5)选注明细:当前期次选注明细数据。
(6)选注历史明细:历史期次选注明细数据。
(7)中奖选注明细:当前期中奖选注明细数据。
(8)中奖选注历史明细:历史中奖选注明细数据。
如果从存储规模和计算规模两个维度分别考虑,针对销量统计、中奖统计和奖金信息,我们需要关注的是计算规模;针对选注明细、选注历史我们要关注的则是存储规模。
三、存储规模评估
3.1 数据结构
针对双色球算奖平台而言,所有需要存储的数据中,选注历史明细信息的存储是规模最大的,根据目前双色球每一期次的平均销量来看,需要存储的每一期次选注明细信息约为2亿条记录。每一选注需要存储的信息包括:站号、操作员、流水号、销售期、有效期、销售时间、金额、投注明细(多条)、开奖时间和附加码。具体如下图所示:

为简化我们的分析,我们将复式投注和胆拖投注明细拆分成单式投注进行存储,具体数据结构如下:
| 序号 |
字段名称 |
类型 |
长度 |
| 1 |
期次 |
Char |
7(YYYYMMN) |
| 2 |
站号 |
Char |
8(全国唯一) |
| 3 |
流水号 |
Char |
6(右侧补零) |
| 4 |
Red1 |
char |
2(左侧补零) |
| 5 |
Red2 |
Char |
2(左侧补零) |
| 6 |
Red3 |
Char |
2(左侧补零) |
| 7 |
Red4 |
Char |
2(左侧补零) |
| 8 |
Red5 |
Char |
2(左侧补零) |
| 9 |
Red6 |
Char |
2(左侧补零) |
| 10 |
Blue |
char |
2(左侧补零) |
按照简化后的数据存储,单注明细需要的存储空间=35字节,每一期次需要存储的绝对数据规模=200000000*35/1024/1024=6675.7M。如果单从这个角度来看,数据存储规模还真的不算大。但是考虑到RDMS表的存储和访问,无论是采用分区,还是分表,能够实现的其实只是把数据塞进去,至于,读出来,如何读出来则将会是一个悲剧。不要告诉我用索引,用索引需要付出的代价是什么,我想有更多的人比我清楚。
3.2 测试环境
| 项 |
值 |
备注 |
| 操作系统 |
Windows XP |
|
| 数据库 |
Sybase15.7 |
|
| CPU |
T5550 |
双核1.83 |
| 内存 |
2G |
|
| 硬盘 |
200G |
|
3.3 测试结果-无索引插入
| 轮次 |
插入记录数 |
耗时 |
| 第一轮 |
200w |
15分03秒 |
| 第二轮 |
200w |
18分05秒 |
| 第三轮 |
200w |
19分04秒 |
3.4 数据库空间-1000w记录数据库空间
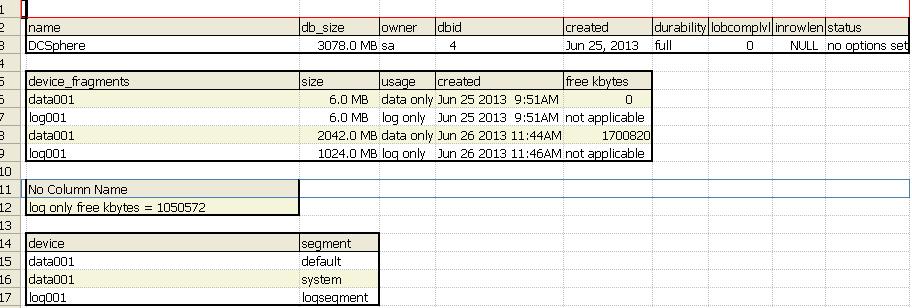
四、计算规模评估
这部分设计到具体采用的算法,但是无论采用何种算法,2亿次规模的数据遍历是必须的,之前园友提到的方法其实很好,根据开奖号码,设计中奖选注表,利用待兑奖数据进行组合ID比较,然后得出目标选注。然后进行奖项层次的细分,思路很好,可是有没有想到过2亿次乘以目标中奖选注表项个数的计算规模有是多少次呢。如果采用SQL的方式,时间呢,又需要多少的时间?有数据有真相,正在跑相关的测试案例。至少目前看到的结果,很不理想。
正在跑测试数据,持续更新中,有图有真相,有数据才有说服力!敬请关注、支持!求推荐!
作者:张子良
出处:http://www.cnblogs.com/hadoopdev
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。




