字符类,也称作字符集,你可以让正则表达式匹配除了几个字符之外的一个字符。只需要把字符放在方括号里就可以了。如果你要匹配一个a或者e。使用[ae],你能使用gr[ae]y 匹配gray或者grey。在你不知道文本是美国英语还是英国英语的情况下搜索文本,这招是很有用的。
字符集仅匹配单个字符。gr[ae]y不会匹配graay, graey。字符集中的顺序没有关系。这个结果是一样的。你可以在字符集里使用‘-’指定范围。[0-9]匹配0-9之间的单个数字。也可以使用多个范围。[0-9a-fA-F]匹配单个16进制的数字,大小写敏感的。你可以联合单个字符和范围,比如,[0-9a-fxA-FX] 匹配了单个16进制的数字或者字母x,同样的,范围中字符的顺序也是无所谓的。
有用的场合查找单词,即使是拼写错误的。比如sep[ae]r[ae]te或者 li[cs]en[cs]e.
从程序代码证找出标示符[A-Za-z_][A-Za-z_0-9]*.
查找出C风格的16进制数字0[xX][A-Fa-f0-9]+。
取反字符集在方括号后面输入插入符号^表示对字符集取反。这表示这个字符集将匹配任何字符除了在这个字符集中的。和.不一样,取反的字符集同样匹配换行字符。
一个取反的字符集必须匹配一个字符。 q[^u]不是指一个后面不跟u的q,它的意思是一个q后面跟一个字符,且这个字符不是u。它不会匹配Iraq。但是会匹配Iraq is a country中的那个q。这个空格也是匹配的一部分,因为这个字符不是u。如果你想在上面的示例字符串中匹配q,并且只是q,你需要使用否定性预查。q(?!u)这在后面会讨论的。
字符集内部的元字符注意,在字符集内部,只有 ],\,^,- 是特殊字符或者元字符。通常的元数据在字符集内部算是正常字符,不需要再加斜杠转义。如果需要查询星号或者加号,使用[+*]。加入转义符号,正在表达式也会正常运行,但是会减少可读性。
要在字符集中包含一个\,作为普通字符,你需要对这个\转义。[\\x] 匹配一个斜杠或者x,],^和-也可以通过转义符号,或者把他们放在不会有特殊意思的位置上。我建议使用后者,因为这增加了可读性。要包含^,只要把它放置在除了[右边的任何位置。[x^] 匹配一个x或者^。你可以把关闭括号直接放在开始括号,或者^的后面,比如[]x] 匹配 ] 或者 x. [^]x] 匹配了任何一个不是]的字符或者一个x.-可以放在[、^的 后面或者] 的前面,[-x] 和[x-] 都匹配了一个x或者-.
你可以在字符集中使用所有空白字符,就行在字符集外边使用他们一样。比如,如果你的正则表达式支持unicode,那么[$\u20AC]匹配一个美元符号或者一个欧元符号。 JGsoft engine, Perl 和PCRE 支持使用在字符集中使用 \Q...\E 转义符。POSIX 正则表达式把字符集里出现的 \ 看作普通的字符 ,这就意味着你不能使用反斜杠来转义],^和-。要使用这些字符,就必须入之前叙述的那样,放置在特别的位置。 这意味着一些特殊字符比如速记字符在POSIX正则表达式中不能使用.
速记字符集由于某些字符集会经常使用,我们可以使用一些速记字符集。\d 是[0-9]的简写方式,\w 表示 "word character", 也就是[A-Za-z0-9_]. 注意下划线和数字。
\s 表示 空白字符. 再次强调,哪些字符算空白字符实际由正则表达式的风格,决定。在本教程中讨论的正则表达式中,空白字符包括[ \t\r\n].也就是说: \s 匹配一个空格,一个tab 或一个换行符. 一些其他风格的正则表达式包含一些额外的,很少使用的空白字符集,比如垂直制表符和换页符。
在下面的屏幕截图中,可以看到\w匹配的字符。
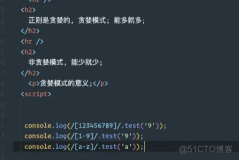
速记字符集可以在[ ] 内部和外部使用。\s\d匹配。匹配空白字符跟着一个数字。[\s\d]匹配一个空白字符或一个数字。当应用到1 + 2= 3这个字符串是,\s\d匹配 2(空格2)。[\s\d]匹配1。[\da-fA-F] 匹配十六进制数字,等价于[0-9a-fA-F].
反义的速记字符集上面3种速记字符有着反义的版本,\D等价于 [^\d], \W 等价于[^\w] ,\S 等价于 [^\s]。
在方括号内使用反义的速记字符要细心了。[\D\S] 不等价于[^\d\s]. 后者匹配任何不是空白符或者空格的字符,所以他可以匹配x,但是不能匹配8,而前者匹配任何不是数字或者不是空白符。Repeating Character Classes
如果通过?*或者+重复一个字符集,那么你重复的是整个字符集,并不仅仅是匹配的那个字符。[0-9]+ 可以匹配 837 也可以匹配 222.
如果需要重复匹配的字符,而不是字符集,你就需要用到后向引用。 ([0-9])\1+ 匹配222 但不匹配837.当应用于833337时,可以匹配3333。 如果需要重复匹配的字符,而不是字符集,你就需要用到后向引用。 ([0-9])\1+ 匹配222 但不匹配837.当应用于833337时,可以匹配3333。 如果你需要这样,就需要使用预测先行和回溯
正则引擎的内部之前提起过,字符在字符集中的顺序是无关紧要的。 gr[ae]y 在Is his hair grey or gray?中匹配grey,遵循最左匹配原则。之前12个字符可以忽略,引擎每一步尝试匹配g都会失败,然后继续尝试下一个字符。当引擎达到第十三个字符,g匹配了。引擎会试着匹配余下的正则表达式,下一个字符是r,匹配了文本中的字符。所以第三个字符[ae]禅师匹配下一个文本字符e。此时字符集给引擎2个选择,匹配a或者匹配e。首先它会匹配a,然后失败。
但是由于我们使用的是正则导向引擎,在决定能不能匹配接下来字符之前,的他必须继续尝试所有的组合。所以他从其他位置继续,并且匹配了e,最后一个字符是y,也能正好匹配。引擎在字符串的第13个字符处发现了一个完整的匹配。返回grey作为结果。不在往下寻找了。再一次。最左匹配白返回了,即使我们把a置于字符集的第一个位置,gray也能匹配该正则表达式。但是引擎不考虑那么多,因为在更左边的地方,找到了一个同样有效的匹配。
本文转自cnn23711151CTO博客,原文链接: http://blog.51cto.com/cnn237111/713666,如需转载请自行联系原作者