一直在想,假如有一天我们生活中的机器人像在很多科幻电影里面看到的那样,能够理解人类的语言,并能完成与人类的自然对话,是多爽的事情。语音的研究一直在试图解决这个问题。例如,语音到文字,即通常所说的语音识别,就试图将语音转换为文字,然后交给计算机进行后续的理解;而文字到语音,即语音合成,则试图将文字转换为声音,让人类可以听到。也许通过全世界语音界的科研和工程人员的努力,在不久的将来,我们真的可以和机器进行自由的对话(其实我一直很期待这一天的到来)。
语音识别有狭义的概念和广义的概念两种。狭义的语音识别,就是语音到文字的转换,即人对着机器说一句话,机器将其翻译为其对应的文字内容。而广义的语音识别,则包含了狭义的语音识别,并且也包含了哼唱搜索,说话人识别,说话人确认等等的技术领域。百度在9月初的时候,曾经推出过一个实验性的哼唱搜索功能,运气比较好的网友可能已经哼唱搜索有感性的认识了。实际上哼唱搜索,就是指我们在计算机或者某些设备前哼唱了某段歌曲,然后计算机根据哼唱的内容找到其对应的歌曲的功能。而说话人识别,则是利用人说的语音来识别人的身份。说话人确认则是根据人说的话确认此人所声称的身份。
语音识别经过几十年的发展,并伴随着计算机硬件的高速发展,已经从最初的只能识别若干个数字,发展到可以识别大词汇量,连续语音,并且说话人无关的语音识别技术。由于互联网和移动互联网发展的驱动,世界各大的互联网公司,手机厂商都在进行语音识别的应用,推出语音搜索,语音拨号,语音输入法等等的应用产品。可以说,语音识别已经迎来了新一轮的发展高潮。
按照识别的形式看,语音识别大体都可以划为孤立词识别,带语法规则的连接词识别,以及连续语音识别。孤立词识别,指的是每次只能说一个词或者一小段固定的话,并且在其配置的词表外的词,全部都不能识别。而连接词识别,则可以识别根据其配置规则生成的句子,比如“请 呼叫 ×××”。连续语音识别,则可以认为能识别任意词搭配的短句,或者完整的句子。按照说话人是否有关来分,则分为说话人相关的语音识别和说话人无关的语音识别。从总体上看,限制条件越少,其难度越大。
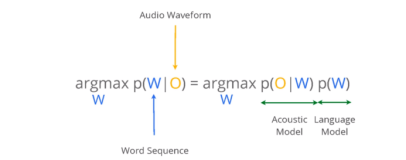
限于当前技术的发展水平,计算机并不能凭空识别语音,而是需要相当多的知识源。按照识别的形式看,语音识别大体都可以划为孤立词识别,带语法规则的连接词识别,以及连续语音识别。拿连续语音识别来说,需要描述语音发音特性的知识源,也需要描述人类语言搭配习惯的知识源。具体说,就是需要对人类语音的发音单元进行建模并估计出其相关参数,由此得到描述发音单元的模型,简称声学模型。而描述人类语言搭配的知识源,则可以是人工总结和构造的某些规则,也可以是从大量的文本资料统计出来的参数。当前连续语音识别中使用比较多的是从文本资料统计出来的n元文法模型,即常说的ngram语言模型。这种模型假设第N个词出现的概率,只和其前面的N-1个词有关。声学模型和语言模型是语音识别中最重要的两个知识源,而根据声学模型发音单元选择的不同,,可能需要一个从发音单元到词的对照表,比如我们选择的是声母和韵母作为建模单元,则需要知道某个字或某个词是由哪些声韵母组合的,我们一般把这个对照表成为发音字典。
再说说中文语音识别的一些与英文识别不同的难点。虽然语音识别是从西方国家起源的,但是随着语音识别学者对中文语音识别的研究的深入,当前我们已经可以看到中文的语音识别产品,包括百度的语音搜索,以及智能手机中内嵌的语音识别产品等等,都是对此很好的说明(我们需要感谢前辈们做出的贡献)。但是中文识别和英文毕竟是不同的,感谢我们的祖先,中文词汇是封闭的,即任何词都可以用字来组成,这给中文识别提供了方便,使得中文识别不像英文那样,只要没在发音词典中配置的词都不能识别。不过这同时也给我们带来一定的麻烦,使得我们做语言模型的时候选择其词集合相当困难。想象中,使用所有的单字即可,可惜的是,我们的实验告诉我们,使用单字的识别率不高,所以词典选择很重要。另外,由于中文是由字组成的,所以识别过程中使用的一些技术对中文不太好用,甚至会导致错误,这个问题可以以后再慢慢探讨。还有就是中文的方言实在是太丰富了,这使得我们做语音识别系统的时候倍感困难,其原因就是尽管我们可以做到说话人无关,但是由于声学模型却是和方言发音直接相关的。不过我相信,这些困难我们都可以克服,并且希望在不久的将来,全国人民都能用上我们的语音识别产品。
技术是为了方便人类生活和工作的,语音技术也不例外,所有需要文字输入,但是不能让人方便使用的地方,都是语音识别技术未来应用的地方,比如手机,比如对不习惯使用键盘的人群等等。此外,语音识别除了作为输入外,还可以在呼叫中心,语音翻译等等地方得到广泛的应用。
让我们一起迎接语音识别光明的未来吧。
By liangweiwen