我们在MongoDB复制集上运行应用程序,有时候有报表需求。常规用途是获得用户行为的分析,还有其他商业定制指标数据。我们不能直接在生产数据库上运行报表,在后面我会列出相关原因。经过开发和运维讨论之后,在项目成立之初,计划隔断报表任务以致不会影响到生产任务。
保持报表读操作远离生产数据库
限制报表查询到专属节点是官方推荐的权威方式,贯穿在整个MongoDB复制文档中。报表基本不需要写操作,而是统计最终一致性数据。如果提取的数据有秒级或分级延时,每日的报表是不允许的。如果你的计数统计丢失了一些行为,它不会改变用户行为报表的基本含义,而这将导致报表数据不准确。
来谈谈混淆生产和报表的问题
如果对你来说已经很清楚了,请跳过这部分内容。如果你需要进一步了解原因,请阅读下面内容。
工作集(workingset),是MongoDB在任何的时间间隔读取和写入的整个数据库的一个子集。生产环境中的活跃用户操作文档数据,操作系统将它保持在物理内存中。
注意:不要让你的工作集增长大过内存!如果确实出现这个问题,你需要分片,因此容量规划是很重要的,可以作为独立的专题来讲。可以使用MongoDB的监控服务Cloud Manager(https://www.mongodb.com/cloud)监控你的实例,或者参加一次即将开始的容量规划网络研讨会(https://www.mongodb.com/webinars)。
即使你的数据库是你可用内存的数百或数千倍,如果你在前期合理规划了架构并优化了索引。MongoDB将会高效运行。因为在工作集外的数据将会保持和磁盘上一致。当用户变得空闲,他们的文档将会不再使用,他们占用的内存对于新的活跃用户的内存请求将会变得可用。
报表任务,尽管获取大量的数据,不会重复访问相同的数据,每个报表任务可能完全访问不同的数据集合。关于任何大小的数据库,这意味着这些工作需要对于当前使用的文档持续提供内存保留空间给新的文档读取。如果你在相同的实例上运行这些工作,而它同时承担着生产工作负载,你的报表任务将会与你的生产应用争夺内存,持续不断地请求活动用户的数据,而你的应用持续不断的加载它。恭喜,你构建了一个性能抖动的机器。
报表任务,将会有大量count、aggregate、mapReduce等聚合操作,这些操作对于MongoDB来说效率不高,因此将他与生产任务分开是一个好的做法。
使用专属报表实例的复制集
你可以构建专属的报表节点在MongoDB复制环境,利用隐藏的复制集成员hidden member(https://docs.mongodb.org/v3.0/tutorial/configure-a-hidden-replica-set-member)或者读偏好read preference(https://docs.mongodb.org/v3.0/core/read-preference)设置相关的标签设置tag sets(https://docs.mongodb.org/v3.0/tutorial/configure-replica-set-tag-sets)。第一种方法更简单,第二种方法更灵活。
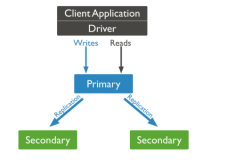
回顾MongoDB复制集
MongoDB复制集具有在线持久性,通过复制数据到一个集合中的所有节点,并对客户端提供无缝的故障转移。包含一个主节点提供写,而剩下的是只读副本。当条件需要的时候选举决定哪个节点是主。复制集应该包含一个奇数成员帮助快速选举。
判断不可达的机器是否宕机基本上不可知,或者网络被分区了,因此如果复制集中的大多数节点下线了(也就是说,3个成员中的2个下线),即使一个健康的主节点保留,他会降级为一个只读的副本。不这么做可能导致多个机器在一个网络分区的情况下定义他们自己为主节点,出现多个主节点,导致可怕的数据不一致。
因此一个复制集包含至少3个成员,提供一个机器失败的错误容忍。
本文转自UltraSQL51CTO博客,原文链接: http://blog.51cto.com/ultrasql/1751770,如需转载请自行联系原作者