【日志格式】
在 之前 确定好通信所用的 json 数据格式后,到 确定 最终生成的 日志内容的时候了。之前提到日志内容至少要包括下面几点:
关于时间戳如何获取,在各类开源项目中具有类似的程序可参考,无外乎使用 C 库中定义的标准 API进行组合。具体的获取方式可以参考:《C语言时间函数简介》。
关于 json 数据的解析使用的是 jansson 开源项目。关于各种开源 json 项目的简单比较可以参考:《各种 JSON 解析库的功能简介》。
而写日志的相关代码,参考了 Redis 中实现的 log 机制并与 Atlas 中采用的 log 机制进行了比较,在此基础上改写出了 modb 使用的 logger 。 细节:Redis 中的日志记录行为是,针对每一条日志打开文件、写日志、关闭文件。支持 syslog 的使用。
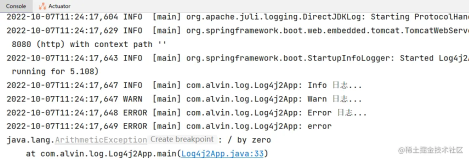
modb 最终产生的 log 内容示例如下:
【业务执行流程】
这里描述下可能出现的日志执行流程。
1. 公有云本地业务 A 更新数据库;
2. 公有云本地业务 A 发送 rabbitmq 消息通知本地其他业务数据库更新成功,同时要求 modb 进行跨机房同步。消息中 "state" 必须为 "transfer"。
3. 公有云 modb 收到上述 rabbitmq 消息后检测其 "state" 字段的值,若为 "transfer",则先记录日志(此时本地数据库已经更新成功)再进行转发;若为 "notify" ,则不进行处理。
4. 私有云 modb 收到转发来的 rabbitmq 消息后,先提取其中的 sql 语句更新本地数据库(无论成功还是失败均要记录日志),若执行成功,则将 rabbitmq 消息中的 "state" 字段值变为 "notify" 后通知本地的其他业务更新成功。
5. 私有云 modb 此时也会收到上述消息,可以通过提取 "state" 的值来判定是否需要进行转发,若为 "notify" 则表明不需要进行转发处理。
一个小知识点:
===========
【使用 fprintf 和 fwrite 写文件有何区别?】
======
博客一:
fprintf(fp, "%d", buffer); 是将格式化的数据写入文件
fprintf(文件指针,格式字符串,输出表列);
fwrite(&buffer, sizeof(int), 1, fp);是以二进制位方式写入文件
fwrite(数据,数据类型大小(字节数),写入数据的最大数量,文件指针);
由于fprintf写入时,对于整数来说,一位占一个字节,比如1,占1个字节;10,占2个字节;100,占3个字节,10000,占5个字节
所以文件的大小会随数据的大小而改变,对大数据空间占用很大。
而fwrite是按二进制写入,所以写入数据所占空间是根据数据类型来确定,比如int的大小为4个字节(一般32位下),那么整数10所占空间为4个字节,100、10000所占空间也是4个字节。所以二进制写入比格式化写入更省空间。
因此,
对于1 2 3 4 5 6 7 8 9 0 十个整数,用fprintf写入时,占10个字节;而用fwrite写入时,占40个字节。
对于100 101 102 103 104 105 106 107 108 109 110 这十个整数,用fprintf写入时,占30个字节;而用fwrite写入时,占40个字节。
对于10000 10100 10200 10300 10400 10500 10600 10700 10800 10900 11000 这十个整数,用fprintf写入时,占50个字节;而用fwrite写入时,还是占40个字节。
======
======
博客二 :
C语言把文件看作一个字符(字节)的序列,即由一个一个字符(字节)的数据顺序组成。根据数据的组织形式,可分为ASCII文件和二进制文件。ASCII文件又称为文本(text)文件,它的每个字节放一个ASCII代码,代表一个字符。二进制文件是把内存中的数据按其在内在中的存储形式原样输出到磁盘上存放。
fprintf(fp, "%d", buffer); 是将格式化的数据写入文件
fprintf(文件指针,格式字符串,输出表列);
fwrite(&buffer, sizeof(int), 1, fp);是以二进位位方式写入文件
fwrite(数据,数据类型大小(字节数),写入数据的最大数量,文件指针);
======
======
博客三:
一句话表述:fwrite 是将数据不经转换直接以二进制的形式写入文件,而 fprintf 是将数据转换为字符(ASCII码)后再写入文件。
这样就导致:
当使用 fwrite 将一个 int 型数字 65 写入文本文件时,由于 65 对应的二进制数是 1000001,十六进制数是 0x41 ,存储的内容以二进制的形式表示为 1000001 。在 notepad++ 中使用十六进制方式打开显示的是:0x0041 ,转换为十进制则为 65 ,使用记事本打开这个文本文件后显示的是 A ,因为记事本程序默认为存储在文本文件中的数据都是 ASCII 码形式存储,它把 65 当做 ASCII 码翻译为字符 A 。
当使用 fpintf 将一个 int 型数字 65 写入文本文件时,将 65 每一位转换为 ASCII 码存储,6、5 分别对应 ASCII 码 54、53 ,存储的是 ASCII 码 54、53 。在 notepad++ 中使用十六进制方式打开显示的是:3635 ,转换为十进制则为 54、53,这正是数字 6、5 的 ASCII 码。使用记事本打开这个文本文件时,记事本将存储在其中的 54、53 当做 ASCII 码翻译为字符 6、5 显示,我们看到的是便是字符 65 。
======
在 之前 确定好通信所用的 json 数据格式后,到 确定 最终生成的 日志内容的时候了。之前提到日志内容至少要包括下面几点:
- 日志记录的时间戳(在本地生成)
- 日志的“流向”(从哪里来,到哪里去)->(从本地各种 app 来,到外部云去)
- sql 语句本身(JSON 数据中携带)
- sql 语句的执行情况(分成:直接在 MySQL 上执行成功后在 modb 上记录;通过 modb 向 MySQL 发送执行命令后记录)->(OK/ERR)
关于时间戳如何获取,在各类开源项目中具有类似的程序可参考,无外乎使用 C 库中定义的标准 API进行组合。具体的获取方式可以参考:《C语言时间函数简介》。
关于 json 数据的解析使用的是 jansson 开源项目。关于各种开源 json 项目的简单比较可以参考:《各种 JSON 解析库的功能简介》。
而写日志的相关代码,参考了 Redis 中实现的 log 机制并与 Atlas 中采用的 log 机制进行了比较,在此基础上改写出了 modb 使用的 logger 。 细节:Redis 中的日志记录行为是,针对每一条日志打开文件、写日志、关闭文件。支持 syslog 的使用。
modb 最终产生的 log 内容示例如下:
|
1
|
[10643] 11 Dec 11:11:12 * src:172.16.80.111 rk:pc_1 app:Ejabberd sql:
'set names utf8'
OK
'Current Query affect [0] rows!'
|
【业务执行流程】
这里描述下可能出现的日志执行流程。
1. 公有云本地业务 A 更新数据库;
2. 公有云本地业务 A 发送 rabbitmq 消息通知本地其他业务数据库更新成功,同时要求 modb 进行跨机房同步。消息中 "state" 必须为 "transfer"。
|
1
2
3
4
5
6
7
8
|
{
"src"
:
"172.16.80.111"
,
"rk"
:
"pc_1"
,
"app"
:
"Ejabberd"
,
"state"
:
"transfer"
,
"sql"
:
"set names utf8"
"desc"
:
"update database success"
}
|
4. 私有云 modb 收到转发来的 rabbitmq 消息后,先提取其中的 sql 语句更新本地数据库(无论成功还是失败均要记录日志),若执行成功,则将 rabbitmq 消息中的 "state" 字段值变为 "notify" 后通知本地的其他业务更新成功。
|
1
2
3
4
5
6
7
8
|
{
"src"
:
"172.16.80.111"
,
"rk"
:
"pc_1"
,
"app"
:
"Ejabberd"
,
"state"
:
"notify"
,
"sql"
:
"set names utf8"
"desc"
:
"update database success"
}
|
一个小知识点:
===========
【使用 fprintf 和 fwrite 写文件有何区别?】
======
博客一:
fprintf(fp, "%d", buffer); 是将格式化的数据写入文件
fprintf(文件指针,格式字符串,输出表列);
fwrite(&buffer, sizeof(int), 1, fp);是以二进制位方式写入文件
fwrite(数据,数据类型大小(字节数),写入数据的最大数量,文件指针);
由于fprintf写入时,对于整数来说,一位占一个字节,比如1,占1个字节;10,占2个字节;100,占3个字节,10000,占5个字节
所以文件的大小会随数据的大小而改变,对大数据空间占用很大。
而fwrite是按二进制写入,所以写入数据所占空间是根据数据类型来确定,比如int的大小为4个字节(一般32位下),那么整数10所占空间为4个字节,100、10000所占空间也是4个字节。所以二进制写入比格式化写入更省空间。
因此,
对于1 2 3 4 5 6 7 8 9 0 十个整数,用fprintf写入时,占10个字节;而用fwrite写入时,占40个字节。
对于100 101 102 103 104 105 106 107 108 109 110 这十个整数,用fprintf写入时,占30个字节;而用fwrite写入时,占40个字节。
对于10000 10100 10200 10300 10400 10500 10600 10700 10800 10900 11000 这十个整数,用fprintf写入时,占50个字节;而用fwrite写入时,还是占40个字节。
======
======
博客二 :
C语言把文件看作一个字符(字节)的序列,即由一个一个字符(字节)的数据顺序组成。根据数据的组织形式,可分为ASCII文件和二进制文件。ASCII文件又称为文本(text)文件,它的每个字节放一个ASCII代码,代表一个字符。二进制文件是把内存中的数据按其在内在中的存储形式原样输出到磁盘上存放。
fprintf(fp, "%d", buffer); 是将格式化的数据写入文件
fprintf(文件指针,格式字符串,输出表列);
fwrite(&buffer, sizeof(int), 1, fp);是以二进位位方式写入文件
fwrite(数据,数据类型大小(字节数),写入数据的最大数量,文件指针);
======
======
博客三:
一句话表述:fwrite 是将数据不经转换直接以二进制的形式写入文件,而 fprintf 是将数据转换为字符(ASCII码)后再写入文件。
这样就导致:
当使用 fwrite 将一个 int 型数字 65 写入文本文件时,由于 65 对应的二进制数是 1000001,十六进制数是 0x41 ,存储的内容以二进制的形式表示为 1000001 。在 notepad++ 中使用十六进制方式打开显示的是:0x0041 ,转换为十进制则为 65 ,使用记事本打开这个文本文件后显示的是 A ,因为记事本程序默认为存储在文本文件中的数据都是 ASCII 码形式存储,它把 65 当做 ASCII 码翻译为字符 A 。
当使用 fpintf 将一个 int 型数字 65 写入文本文件时,将 65 每一位转换为 ASCII 码存储,6、5 分别对应 ASCII 码 54、53 ,存储的是 ASCII 码 54、53 。在 notepad++ 中使用十六进制方式打开显示的是:3635 ,转换为十进制则为 54、53,这正是数字 6、5 的 ASCII 码。使用记事本打开这个文本文件时,记事本将存储在其中的 54、53 当做 ASCII 码翻译为字符 6、5 显示,我们看到的是便是字符 65 。
======