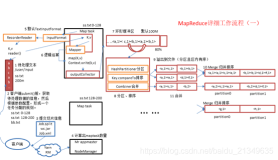
一:简单认识InputFormat类
InputFormat主要用于描述输入数据的格式,提供了以下两个功能:
1)、数据切分,按照某个策略将输入数据且分成若干个split,以便确定Map Task的个数即Mapper的个数,在MapReduce框架中,一个split就意味着需要一个Map Task;2)为Mapper提供输入数据,即给定一个split,(使用其中的RecordReader对象)将之解析为一个个的key/value键值对。
下面我们先来看以下1.0版本中的老的InputFormat接口:
- public interface InputFormat<K,V>{
- //获取所有的split分片
- public InputSplit[] getSplits(JobConf job,int numSplits) throws IOException;
- //获取读取split的RecordReader对象,实际上是由RecordReader对象将
- //split解析成一个个的key/value对儿
- public RecordReader<K,V> getRecordReader(InputSplit split,
- JobConf job,
- Reporter reporter) throws IOException;
- }
getSplit(...)方法主要用于切分数据,它会尝试浙江输入数据且分成numSplits个InputSplit的栓皮栎split分片。InputSplit主要有以下特点:
1)、逻辑分片,之前我们已经学习过split和block的对应关系和区别,split只是在逻辑上对数据分片,并不会在磁盘上讲数据切分成split物理分片,实际上数据在HDFS上还是以block为基本单位来存储数据的。InputSplit只记录了Mapper要处理的数据的元数据信息,如起始位置、长度和所在的节点;

2)、可序列化,在Hadoop中,序列化主要起两个作用,进程间通信和数据持久化存储。在这里,InputSplit主要用于进程间的通信。
在作业被提交到JobTracker之前,Client会先调用作业InputSplit中的getSplit()方法,并将得到的分片信息序列化到文件中,这样,在作业在JobTracker端初始化时,便可并解析出所有split分片,创建对象应的Map Task。
InputSplit也是一个interface,具体返回什么样的implement,这是由具体的InputFormat来决定的。InputSplit也只有两个接口函数:
- public interface InputSplit extends Writable {
- /**
- * 获取split分片的长度
- *
- * @return the number of bytes in the input split.
- * @throws IOException
- */
- long getLength() throws IOException;
- /**
- * 获取存放这个Split的Location信息(也就是这个Split在HDFS上存放的机器。它可能有
- * 多个replication,存在于多台机器上
- *
- * @return list of hostnames where data of the <code>InputSplit</code> is
- * located as an array of <code>String</code>s.
- * @throws IOException
- */
- String[] getLocations() throws IOException;
- }
在MapReduce框架中最常用的FileInputFormat为例,其内部使用的就是FileSplit来描述InputSplit。我们来看一下FileSplit的一些定义信息:
- /** A section of an input file. Returned by {@link
- * InputFormat#getSplits(JobConf, int)} and passed to
- * {@link InputFormat#getRecordReader(InputSplit,JobConf,Reporter)}.
- */
- public class FileSplit extends org.apache.hadoop.mapreduce.InputSplit
- implements InputSplit {
- // Split所在的文件
- private Path file;
- // Split的起始位置
- private long start;
- // Split的长度
- private long length;
- // Split所在的机器名称
- private String[] hosts;
- FileSplit() {}
- /** Constructs a split.
- * @deprecated
- * @param file the file name
- * @param start the position of the first byte in the file to process
- * @param length the number of bytes in the file to process
- */
- @Deprecated
- public FileSplit(Path file, long start, long length, JobConf conf) {
- this(file, start, length, (String[])null);
- }
- /** Constructs a split with host information
- *
- * @param file the file name
- * @param start the position of the first byte in the file to process
- * @param length the number of bytes in the file to process
- * @param hosts the list of hosts containing the block, possibly null
- */
- public FileSplit(Path file, long start, long length, String[] hosts) {
- this.file = file;
- this.start = start;
- this.length = length;
- this.hosts = hosts;
- }
- /** The file containing this split's data. */
- public Path getPath() { return file; }
- /** The position of the first byte in the file to process. */
- public long getStart() { return start; }
- /** The number of bytes in the file to process. */
- public long getLength() { return length; }
- public String toString() { return file + ":" + start + "+" + length; }
- ////////////////////////////////////////////
- // Writable methods
- ////////////////////////////////////////////
- public void write(DataOutput out) throws IOException {
- UTF8.writeString(out, file.toString());
- out.writeLong(start);
- out.writeLong(length);
- }
- public void readFields(DataInput in) throws IOException {
- file = new Path(UTF8.readString(in));
- start = in.readLong();
- length = in.readLong();
- hosts = null;
- }
- public String[] getLocations() throws IOException {
- if (this.hosts == null) {
- return new String[]{};
- } else {
- return this.hosts;
- }
- }
- }
从上面的代码中我们可以看到,FileSplit就是InputSplit接口的一个实现。InputFormat使用的RecordReader将从FileSplit中获取信息,解析FileSplit对象从而获得需要的数据的起始位置、长度和节点位置。
RecordReader
对于getRecordReader(...)方法,它返回一个RecordReader对象,该对象可以讲输入的split分片解析成一个个的key/value对儿。在Map Task的执行过程中,会不停的调用RecordReader对象的方法,迭代获取key/value并交给map()方法处理:
- //调用InputFormat的getRecordReader()获取RecordReader<K,V>对象,
- //并由RecordReader对象解析其中的input(split)...
- K1 key = input.createKey();
- V1 value = input.createValue();
- while(input.next(key,value)){//从input读取下一个key/value对
- //调用用户编写的map()方法
- }
- input.close();
RecordReader主要有两个功能:
●定位记录的边界:由于FileInputFormat是按照数据量对文件进行切分,因而有可能会将一条完整的记录切成2部分,分别属于两个split分片,为了解决跨InputSplit分片读取数据的问题,RecordReader规定每个分片的第一条不完整的记录划给前一个分片处理。
●解析key/value:定位一条新的记录,将记录分解成key和value两部分供Mapper处理。
InputFormat
MapReduce自带了一些InputFormat的实现类:

下面我们看几个有代表性的InputFormat:
FileInputFormat
FileInputFormat是一个抽象类,它最重要的功能是为各种InputFormat提供统一的getSplits()方法,该方法最核心的是文件切分算法和Host选择算法:
- /** Splits files returned by {@link #listStatus(JobConf)} when
- * they're too big.*/
- @SuppressWarnings("deprecation")
- public InputSplit[] getSplits(JobConf job, int numSplits)
- throws IOException {
- FileStatus[] files = listStatus(job);
- // Save the number of input files in the job-conf
- job.setLong(NUM_INPUT_FILES, files.length);
- long totalSize = 0; // compute total size
- for (FileStatus file: files) { // check we have valid files
- if (file.isDir()) {
- throw new IOException("Not a file: "+ file.getPath());
- }
- totalSize += file.getLen();
- }
- long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
- long minSize = Math.max(job.getLong("mapred.min.split.size", 1),
- minSplitSize);
- // 定义要生成的splits(FileSplit)的集合
- ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
- NetworkTopology clusterMap = new NetworkTopology();
- for (FileStatus file: files) {
- Path path = file.getPath();
- FileSystem fs = path.getFileSystem(job);
- long length = file.getLen();
- BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);
- if ((length != 0) && isSplitable(fs, path)) {
- long blockSize = file.getBlockSize();
- //获取最终的split分片的大小,该值很可能和blockSize不相等
- long splitSize = computeSplitSize(goalSize, minSize, blockSize);
- long bytesRemaining = length;
- while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
- //获取split分片所在的host的节点信息
- String[] splitHosts = getSplitHosts(blkLocations,
- length-bytesRemaining, splitSize, clusterMap);
- //最终生成所有分片
- splits.add(new FileSplit(path, length-bytesRemaining, splitSize,
- splitHosts));
- bytesRemaining -= splitSize;
- }
- if (bytesRemaining != 0) {
- splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining,
- blkLocations[blkLocations.length-1].getHosts()));
- }
- } else if (length != 0) {
- //获取split分片所在的host的节点信息
- String[] splitHosts = getSplitHosts(blkLocations,0,length,clusterMap);
- //最终生成所有分片
- splits.add(new FileSplit(path, 0, length, splitHosts));
- } else {
- //Create empty hosts array for zero length files
- //最终生成所有分片
- splits.add(new FileSplit(path, 0, length, new String[0]));
- }
- }
- LOG.debug("Total # of splits: " + splits.size());
- return splits.toArray(new FileSplit[splits.size()]);
- }
1)、文件切分算法
文件切分算法主要用于确定InputSplit的个数以及每个InputSplit对应的数据段,FileInputSplit以文件为单位切分生成InputSplit。有三个属性值来确定InputSplit的个数:
●goalSize:该值由totalSize/numSplits来确定InputSplit的长度,它是根据用户的期望的InputSplit个数计算出来的;numSplits为用户设定的Map Task的个数,默认为1。
●minSize:由配置参数mapred.min.split.size决定的InputFormat的最小长度,默认为1。
●blockSize:HDFS中的文件存储块block的大小,默认为64MB。
这三个参数决定一个InputFormat分片的最终的长度,计算方法如下:
splitSize = max{minSize,min{goalSize,blockSize}}
计算出了分片的长度后,也就确定了InputFormat的数目。
2)、host选择算法
InputFormat的切分方案确定后,接下来就是要确定每一个InputSplit的元数据信息。InputSplit元数据通常包括四部分,<file,start,length,hosts>其意义为:
●file标识InputSplit分片所在的文件;
●InputSplit分片在文件中的的起始位置;
●InputSplit分片的长度;
●分片所在的host节点的列表。
InputSplit的host列表的算作策略直接影响到运行作业的本地性 。我们知道,由于大文件存储在HDFS上的block可能会遍布整个Hadoop集群,而一个InputSplit分片的划分算法可能会导致一个split分片对应多个不在同一个节点上的blocks,这就会使得在Map Task执行过程中会涉及到读其他节点上的属于该Task的block中的数据,从而不能实现数据本地性,而造成更多的网络传输开销。
一个InputSplit分片对应的blocks可能位于多个数据节点地上,但是基于任务调度的效率,通常情况下,不会把一个分片涉及的所有的节点信息都加到其host列表中,而是选择包含该分片的数据总量的最大的前几个节点,作为任务调度时判断是否具有本地性的主要凭证。
FileInputFormat使用了一个启发式的host选择算法:首先按照rack机架包含的数据量对rack排序,然后再在rack内部按照每个node节点包含的数据量对node排序,最后选取前N个(N为block的副本数)node的host作为InputSplit分片的host列表。当任务地调度Task作业时,只要将Task调度给host列表上的节点,就可以认为该Task满足了本地性。
从上面的信息我们可以知道,当InputSplit分片的大小大于block的大小时,Map Task并不能完全满足数据的本地性,总有一本分的数据要通过网络从远程节点上读数据,故为了提高Map Task的数据本地性,减少网络传输的开销,应尽量是InputFormat的大小和HDFS的block块大小相同。
TextInputFormat
默认情况下,MapReduce使用的是TextInputFormat来读分片并将记录数据解析成一个个的key/value对,其中key为该行在整个文件(注意而不是在一个block)中的偏移量,而行的内容即为value。
CombineFileInputFormat
CombineFileInputFormat的作用是把许多文件合并作为一个map的输入,它的主要思路是把输入目录下的大文件分成多个map的输入, 并合并小文件, 做为一个map的输入。适合在处理多个小文件的场景。
SequenceFileInputFormat
SequenceFileInputFormat是一个顺序的二进制的FileInputFormat,内部以key/value的格式保存数据,通常会结合LZO或Snappy压缩算法来读取或保存可分片的数据文件。