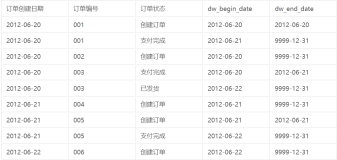
此种方式是缓慢变化维中最简单的一种,它用于保证数据仓库中的数据为当前的最新值,不保留历史数据,如发现数据仓库中当前数据已为旧数据,则对当前已有记录进行值更新,主键值不变,如发现有新数据,则把新数据加载到数据仓库中,并赋予新的代理主键值。
3.3实现
3.3.1 覆盖( Type 1 Dimension -- keep most recent values in target )
3.3.1.1 原理
此种方式是缓慢变化维中最简单的一种,它用于保证数据仓库中的数据为当前的最新值,不保留历史数据,如发现数据仓库中当前数据已为旧数据,则对当前已有记录进行值更新,主键值不变,如发现有新数据,则把新数据加载到数据仓库中,并赋予新的代理主键值。通俗地说,就是指对于源表中的同一条数据,目标(数据仓库)中始终只会保留一条,也就是最新的一条,一旦第一次插入后,数据就存在了,其在维表中的 ID(代理主键)就不再改变了,发生数据改变时,只对其字段作 Update操作。
这种方式在确认数据的历史不需要记录,只需保留当前最新信息的时候使用。
CREATE TABLE t_dem_xxx
(
ID VARCHAR(20) NOT NULL,
Name1 VARCHAR(50),
Name2 VARCHAR(50),
CONSTRAINT PK_t_dem_xxx PRIMARY KEY (ID)
)
go
CREATE TABLE t_tmp_xxx
(
ID VARCHAR(20) NOT NULL,
Name1 VARCHAR(50),
Name2 VARCHAR(50),
CONSTRAINT PK_t_tmp_xxx PRIMARY KEY (ID)
)
go
CREATE PROCEDURE p_dem_xxx
AS
-- 维度抽取存储过程
BEGIN
DECLARE
@num NUMERIC(10,0)
SELECT @num = COUNT(*) FROM t_dem_xxx
-- 如果原表为空,构造缺省值
IF @num = 0
BEGIN
INSERT INTO t_dem_xxx (ID,Name1,Name2) SELECT '-2','NULL 值 ',''
INSERT INTO t_dem_xxx (ID,Name1,Name2) SELECT '-1',' 缺失外键 ',''
END
-- 根据主键插入在维度表中找不到的基础数据
INSERT INTO t_dem_xxx
(
ID ,
Name1 ,
Name2
)
SELECT a.ID,a.Name1,a.Name2
FROM t_tmp_xxx a LEFT OUTER JOIN t_dem_xxx b
ON a.ID = b.ID
WHERE b.ID IS NULL
-- 根据主键更新原基础表中变化的各属性字段
UPDATE t_dem_xxx
SET Name1 = a.Name1,
Name2 = a.Name2
FROM t_tmp_xxx A,t_dem_xxx B
WHERE a.ID = b.ID
AND b.ID NOT IN ('-1','-2')
END
本文转自baoqiangwang51CTO博客,原文链接:http://blog.51cto.com/baoqiangwang/310378,如需转载请自行联系原作者