https://wenku.baidu.com/view/ee9d9800cdbff121dd36a32d7375a417866fc131.html 使用kmeans算法做流量异常检测 明确指出数据预处理需要规范化
例如网络流量异常检测方法,对网络流量样本数据进行归一化和均值化处理,得到网络流量样本数据向量vk,1≤k≤M,M代表网络流量样本数据的类别数,对识别的网络流量测试数据进行归一化和均值化处理,得到网络流量测试数据向量。
http://blog.csdn.net/sinat_31726559/article/details/52016652 含网络流量异常检测完整代码 其找异常点代码:

//度量新数据点到最近簇质心的距离 val distances = normalizedData.map(datum => distToCenter(datum, model)) //设置阀值为已知数据中离中心点最远的第100个点到中心的距离 val threshold = distances.top(100).last //检测,若超过该阀值就为异常点 (datum: Vector) => distToCenter(normalizeFunction(datum), model) > threshold
另外一个文章,kmeans聚类后会这样找出异常点,我靠,貌似和上面的本质一样:
//距离中心最远的第100个点的距离 JavaDoubleRDD distances = labelsAndData.map(f -> f._2).mapToDouble(datum -> distToCentroid(datum, modelF)); Double threshold = distances.top(100).get(99); JavaRDD<Tuple2<String, Vector>> result = labelsAndData.filter(t -> distToCentroid(t._2, modelF) > threshold); System.out.println("result:---------"); result.foreach(f -> System.out.println(f._2));
代码摘自 http://blog.csdn.net/zdy0_2004/article/details/52304771 其中还包括对k的最优选取等。
另外一个文章里是另外一种思路:http://blog.csdn.net/qq1010885678/article/details/51354486
使用历史数据模型对全体数据进行聚类,使用这个聚类模型可以将数据中离质心最远的点找出来。将这个点到质心的距离设置为阈值 当有新的数据进来时,判断这个数据到其质心的距离是否超过这个阈值 超过就发出警报。给人感觉是历史数据都是正常数据???
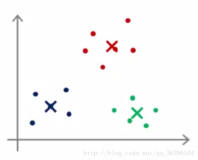
通过把数据聚成类,将那些不属于任务一类的数据作为异常值。比如,使用基于密度的聚类DBSCAN,如果对象在稠密区域紧密相连,它们将被分组到一类。因此,那些不会被分到任何一类的对象就是异常值。
http://www.360doc.com/content/16/0827/21/20558639_586383718.shtml 也可以使用k-means算法来检测异常。使用k-means算法,数据被分成k组,通过把它们分配到最近的聚类中心。然后,我们能够计算每个对象到聚类中心的距离(或相似性),并且选择最大的距离作为异常值。
http://blog.csdn.net/and_w/article/details/56481864 使用高斯聚类来做的 如下文
Anomaly Detection
我们的第一个任务是使用高斯模型来检测数据集中一个未标记(unlabeled)的样本是否应被视为异常。 我们从一个简单的 2 维数据集开始,因此我们可以很容易地可视化这算法的工作原理。 让我们 导入数据并画出散点图。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt import seaborn as sb from scipy.io import loadmat %matplotlib inline data = loadmat('data/ex8data1.mat') X = data['X'] X.shape (307L, 2L)
- 1
- 2
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(X[:,0], X[:,1]) - 1
- 2

看起来该聚类的中心十分紧密,只有几个值远离聚类中心。 在这个简单的例子中,这些可以被认为是异常。 为了弄清楚这些,我们的任务是,估计数据中每个特征的高斯分布。 你可能还记得,为了定义概率分布,我们需要两个东西——均值和方差。 为了实现这一点,我们将创建一个简单的函数来计算数据集中每个特征的均值和方差。
def estimate_gaussian(X):
mu = X.mean(axis=0) sigma = X.var(axis=0) return mu, sigma mu, sigma = estimate_gaussian(X) mu, sigma (array([ 14.11222578, 14.99771051]), array([ 1.83263141, 1.70974533])) 现在有了我们模型的参数,我们需要确定概率阈值,其指示一个样本是否应该被认为是异常。 为此,我们需要使用一组已被标记的验证数据(其中真正的异常已经被标记出来了),并在不同阈值条件下测试模型识别异常的能力。
Xval = data['Xval']
yval = data['yval']
Xval.shape, yval.shape ((307L, 2L), (307L, 1L))
我们还需要一种方法能够在给定参数下计算数据点属于一个正态分布的概率。幸运的是, SciPy 已经内置了。
from scipy import stats
dist = stats.norm(mu[0], sigma[0])
dist.pdf(X[:,0])[0:50]array([ 0.183842 , 0.20221694, 0.21746136, 0.19778763, 0.20858956, 0.21652359, 0.16991291, 0.15123542, 0.1163989 , 0.1594734 , 0.21716057, 0.21760472, 0.20141857, 0.20157497, 0.21711385, 0.21758775, 0.21695576, 0.2138258 , 0.21057069, 0.1173018 , 0.20765108, 0.21717452, 0.19510663, 0.21702152, 0.17429399, 0.15413455, 0.21000109, 0.20223586, 0.21031898, 0.21313426, 0.16158946, 0.2170794 , 0.17825767, 0.17414633, 0.1264951 , 0.19723662, 0.14538809, 0.21766361, 0.21191386, 0.21729442, 0.21238912, 0.18799417, 0.21259798, 0.21752767, 0.20616968, 0.21520366, 0.1280081 , 0.21768113, 0.21539967, 0.16913173])在不清楚的情况下,我们只计算了数据集的第一维的前 50 个样本中的每一个属于该分布的概率。 本质上,它计算的是每个实例与均值的距离,以及从均值角度比较这一“典型”距离。
让我们在给定高斯模型参数情况下(上面计算过的)计算并保存数据集中每个值的概率密度.
p = np.zeros((X.shape[0], X.shape[1]))
p[:,0] = stats.norm(mu[0], sigma[0]).pdf(X[:,0]) p[:,1] = stats.norm(mu[1], sigma[1]).pdf(X[:,1]) p.shape (307L, 2L)
我们需要对验证集进行相同的操作(使用相同的模型参数)。我们将使用这些概率再结合真标签来确定指定为异常点的概率阈值。
pval = np.zeros((Xval.shape[0], Xval.shape[1]))
pval[:,0] = stats.norm(mu[0], sigma[0]).pdf(Xval[:,0]) pval[:,1] = stats.norm(mu[1], sigma[1]).pdf(Xval[:,1]) - 1
- 2
- 3
接下来,我们需要一个只要给定概率密度值和真标签就能找出最佳阈值的函数。 为此,我们需要计算不同的 ϵ 值的 F1 范数。 F1 范数 是真正( true positive)、假正(false positive)、假负(false negative)的函数。
def select_threshold(pval, yval):
best_epsilon = 0 best_f1 = 0 f1 = 0 step = (pval.max() - pval.min()) / 1000 for epsilon in np.arange(pval.min(), pval.max(), step): preds = pval < epsilon tp = np.sum(np.logical_and(preds == 1, yval == 1)).astype(float) fp = np.sum(np.logical_and(preds == 1, yval == 0)).astype(float) fn = np.sum(np.logical_and(preds == 0, yval == 1)).astype(float) precision = tp / (tp + fp) recall = tp / (tp + fn) f1 = (2 * precision * recall) / (precision + recall) if f1 > best_f1: best_f1 = f1 best_epsilon = epsilon return best_epsilon, best_f1 epsilon, f1 = select_threshold(pval, yval) epsilon, f1
(0.0095667060059568421, 0.7142857142857143)
最后,我们将阈值应用到数据集并观察结果。
# indexes of the values considered to be outliers
outliers = np.where(p < epsilon)
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(X[:,0], X[:,1]) ax.scatter(X[outliers[0],0], X[outliers[0],1], s=50, color='r', marker='o') - 1
- 2
- 3
- 4
- 5
- 6

不错! 红色的点是被标记为异常值的点。 从视觉上来看这很合理。 右上那一点有一些分离(但没有被标记)可能也是一个异常值,这已经很接近正确结果了。 应用其到高维数据集是练习文本的另一个例子,但由于它是二维情形的琐碎扩展,我们将进入最后一节。
本文转自张昺华-sky博客园博客,原文链接:http://www.cnblogs.com/bonelee/p/7776565.html,如需转载请自行联系原作者