在今天的文章里我想谈下SQL Server里现存的各种事务隔离级别的神话和误解。主要我会谈谈下列话题:
- 什么是事务隔离级别(Transaction Isolation Levels)?
- NOLOCK从不阻塞!?
- 提交读(Read Committed)不会持锁!?
- Key Range Locks只针对可串行化?!
好,让我们从第1个开始奠定SQL Server里事务隔离级别的基础。
什么是事务隔离级别(Transaction Isolation Levels)?
每次当我站在客户角度,处理各类乱七八糟的SQL Server问题(或进行SQL Server体检),有时问题的根源是躲在数据库里的锁/阻塞行为。当你有一个糟糕的查询(可能是丢失一个非常重要的索引),整个数据库的性能都会下降。
你是否尝试过启动一个新的事务(却不曾提交它),它会获取你生产数据库主数据表的排它锁(exclusive lock)?相信我:你数据库的性能和生产力就会挂掉——就在你面前!!!因此听我老人言:不要这样做!
当我们在任何关系数据库里谈论锁和阻塞,我们也要谈到那个数据库管理系统(DBMS)所支持的各种事务隔离级别(这里我们指的是SQL Server)。SQL Server支持2中并发模式:“老”的悲观并发控制,还有自SQL Server 2005起引入“新”的乐观并发控制——一晃就是10年前的事了……
今天我想专心讲下“老”的悲观并发控制。在老的悲观并发控制模式里,SQL Server支持4个不同的事务隔离级别:
- 未提交读/脏读(Read Uncommitted)
- 提交读(Read committed)
- 可重复读(Repeatable Read)
- 可串行化(Serializable)
我不想深入讲解每个事务隔离级别,但我会给你每个隔离级别内部操作的概况,因为接下来的文章会用到那些信息。
当我们站在SQL Server的高度来看,你的事务包括读取数据(SELECT查询),还有修改数据(INSERT,UPDATE,DELETE,MERGE)。每次当你读取数据时,SQL Server需要获得共享锁(Shared Locks (S))。每次当你修改数据时,SQL Server需要获得排它锁(Exclusive Locks (X))。这2个锁是相互排斥的,就是说读操作会阻塞写操作,写操作会阻塞读操作。
现在使用事务隔离级别你就可以进行控制,读操作可以持共享(S)锁多少时间。写操作总要获得排它(X)锁,你不能影响它。SQL Server默认使用的是提交读(Read Committed)隔离级别,这意味着当你读取一条记录时,SQL Server需要获得共享(S)锁,当记录读取完成,共享(S)锁就会释放。当你逐行读取时,共享(S)锁也是逐行获取与释放。
当你不想读取操作获得共享(S)锁(事实并不推荐这样做),你可以使用未提交读/脏读(Read Uncommitted)隔离级别。未提交读/脏读意味着你可以读取脏数据——尚未提交的数据。这是贼快的(每人可以阻塞你),但是另一方面是非常危险的,因为这是未提交的数据。想下,如果未提交的事务在你读到数据后又撤销了:在你手里的数据在数据库里逻辑上并不存在。现在你的手非常的脏。在我处理SQL Server问题里,我看到很多用户使用未提交读/脏读或NOLOCK查询提示来避免SQL Server里的阻塞。那不是首选处理阻塞的方法。接下来你会看到,即使NOLOCK也会阻塞……
在提交读里你会有所谓的不可重复读(Non Repeatable Reads),因为当你在你的事务里2次读取数据时,其他人可以修改数据。如果你想避免不可重复读,你可以使用可重复读(Repeatable Read)隔离级别,在可重复读里,SQL Server持有共享(S)锁,直到你用COMMIT或ROLLBACK来结束你的事务。这意味这没有人可以修改你读取的数据,对于你的事务,你是可以重复读的。
到目前为止在每个我们讨论的隔离级别里,你都会得到所谓的虚影记录(Phantom Records)——在你的记录集里可以出现又消失的记录。如果你想避免这些虚影记录,你必须使用可串行化(Serializable)隔离级别,最有限制的隔离级别。在可串行化里SQL Server使用所谓的Key Range Locking来消除虚影记录:你锁定整个范围的数据,因此没有其他并发的事务可以插入其它记录来阻止虚影记录。
从这个介绍可以看到,你的隔离级别越多限制,你数据库的并发操作会更受影响。因此你要正确选择对的隔离级别。一直使用提交读没有意义,一直使用可串行化也没有意义。和往常一样,依具体情况而定。
现在我已经奠定了SQL Server里事务隔离级别的基础,现在我会给你展示3个不同的情况,和我上述介绍的情况不会符合。在一些特定情况下,SQL Server会通过对特定SQL语句在底层(Under the Hood)改变事务隔离级别来保证你事务的准确性。我们开始吧……
NOLOCK从不阻塞!?
在简介里我已经描述了,对于特定的SQL语句,在数据读取时,NOLOCK查询提示会阻止需要的共享(S)锁。这会让你的SQL语句非常快,因为SQL查询不会被任何其他事务阻塞。我把NOLOCK称为SQL Server里的加速器。
但遗憾的是,当你使用并发的像ALTER TABLE的DDL语句(数据定义语言(Data Definition Language,DDL))。在我们理解这个行为前,我们需要详细看下DDL语句,当我们执行简单SELECT查询时,在SQL Server内部发生了什么。
当你使用ALTER TABLE的DDL语句修改表时,SQL Server在那个表上获得所谓架构修改锁(Schema Modification Lock (Sch-M)) 。当你现在对同个表同时运行SELECT查询时,SQL Server第1步需要编译物理执行计划。在SQL Server编译阶段需要所谓的架构修改锁(Schema Modification Lock (Sch-M))。
这2个锁(Sch-M和Sch-S)是彼此互斥的!这意味着即使NOLOCK语句也会阻塞,因为在第1步你需要编译执行计划。因此在SQL Server知道物理执行计划前,你的NOLOCK语句会阻塞。当你在生产系统里升级你的数据库架构时,你有考虑过这个行为么?好好考虑下……让我们用一个简单的例子演示下这个行为。在第1步我会创建一个新表并往里插入一些记录:

1 -- Create a new test table 2 CREATE TABLE TestTable 3 ( 4 Column1 INT, 5 Column2 INT, 6 Column3 INT 7 ) 8 GO 9 10 -- Insert some test data 11 DECLARE @i INT = 0 12 13 WHILE (@i < 10000) 14 BEGIN 15 INSERT INTO TestTable VALUES (@i, @i + 1, @i + 2) 16 SET @i += 1 17 END 18 GO
然后我们通过执行一个ALTER TABLE的DDL语句来开始一个新的事务,给我们的表增加一个新列:
1 -- Begin a new transaction and do some work 2 BEGIN TRANSACTION 3 4 -- Add a new column 5 -- DDL statements require a Sch-M lock on the objects that are modified. 6 -- In this case, the table "TestTable" gets a Sch-M lock (Schema modification lock)! 7 ALTER TABLE TestTable ADD Column4 INT
从刚才的代码可以看到,这个事务还在进行中,尚未提交。因此让我们在SSMS里打开新的会话来执行下列代码:
1 -- The statement is now blocking, even with the NOLOCK query hint! 2 -- SQL Server has to compile the query, and requests a Sch-S lock (Schema Stability lock). 3 -- This lock is incompatible with the Sch-M lock! 4 SELECT * FROM TestTable WITH (NOLOCK) 5 GO
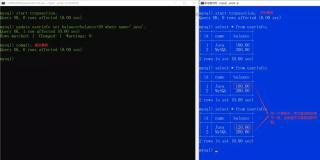
你会马上看到,这个SQL语句并没有返回一条记录,因为它被其它活动的事务阻塞——即使使用NOLOCK查询提示!对这2个会话,你可以通过查询DMV sys.dm_tran_locks对这个阻塞情况进一步故障排除。你会看到Sch-M锁阻塞了Sch-S锁。
使用NOLOCK查询提示或未提交读/脏读事务隔离级别不能保证你的SQL语句马上执行。在过去里很多用户都在与此特定问题斗争。
提交读(Read Committed)不会持锁!?
在简介里你已经学到提交读事务隔离级别,共享(S)锁只在记录读取期间把持。这意味着只要记录被读取,那个锁就会被立即释放。因此当你从一个表读取数据,针对当前被处理的记录,在这个时间点只有共享(S)锁。这个描述只在你的执行计划没有阻塞运算符——例如排序(sort)运算符是对的。当你的执行计划有这样的运算符,意味着SQL Server需要创建你数据的副本。
在数据副本完成后,原始的表/索引数据就不需要保留。但当你处理小量数据时,创建数据副本不会影响你的性能。假设当你有VARCHAR(MAX)列定义的表时。在那个情况下每行的那列可以保存最大2GB的数据。创建数据副本只会吹干你的内存和TempDb。
为了避免这个问题,SQL Server只持共享(S)锁到你语句的结束。因此在此同时不存在有人改变数据的可能(共享(S)锁阻塞排它(X)锁),SQL Server只引用原始,稳定,未改变的数据。因此,你的事务运行起来像在可重读隔离级别,这会伤及你数据库的扩展性。让我们创建下列数据库架构来演示这个行为:
1 -- Create a new table 2 CREATE TABLE TestTable 3 ( 4 ID INT IDENTITY(1, 1) NOT NULL PRIMARY KEY, 5 Col2 INT, 6 Col3 VARCHAR(MAX) 7 ) 8 GO 9 10 -- Insert some records into the table 11 INSERT INTO TestTable VALUES (1, 'abc'), (2, 'def'), (3, 'ghi') 12 GO 13 14 -- Begin a new transaction, so that we are blocking some records in the table 15 BEGIN TRANSACTION 16 17 UPDATE TestTable SET Col2 = 1 WHERE ID = 3
从代码里你可以看到,我创建一个聚集表,有3条聚集键值为1,2,3的记录。下一步我会开始一个新的事务,我们在聚集索引里锁定第3条记录。现在我们搭建好演示。在独立的会话里,我们尝试从表读取记录——显然这个SELECT语句会阻塞:
1 -- This statement only acquires a key lock on the current record 2 SELECT Col3 FROM TestTable 3 GO
当我们从DMV sys.dm_tran_locks里查看,你会清楚看到那个SELECT语句在等待在聚集键值为3的第3个锁。这是提交读隔离级别的典型行为,因为在我们的执行计划里没有阻塞运算符。但只要我们引入一个阻塞运算符(并读取一个LOB数据类型),事情就会发生改变:
1 -- This statement only acquires a key lock on the current record 2 SELECT Col3 FROM TestTable 3 ORDER BY Col2 4 GO
如你所见,现在我们使用了ORDER BY字句,在执行计划里会给我们排序(sort)运算符。当然,这个SELECT语句会再次阻塞。但当我们查看DMV sys.dm_tran_locks时,你会看到提交读隔离级别完全不同的行为:SQL Server现在在前2行(聚集键值为1,2)获得共享(S)锁,但不再释放它们了!SQLServer把持这些锁直到我们的SELECT语句完成,这是为了阻止对潜在数据的并发改变。
在可重读隔离级别里,我们的SELECT语句会高效运行。当你设计你的下个表架构时,考虑下这点,还有在你主要事务表里包含LOB数据类型时也是。
Key Range Locks只针对序列化?!
前段时间我碰到一个问题(在数据库体检期间),在提交读事务这个默认隔离级别里碰到Key Range Locks。从这个文章的开始,我们就知道在可串行化隔离级别才会用到Key Range Locks。因此问题是这些Key Range Locks从哪里来的。
当我们进一步分析数据架构时,我们发现表用了外键约束,在那里级联删除(Cascading Deletes)被启用。只要你对外键启用级联删除,当你从父表里删除记录时,SQL Server就会在子表上使用Key Range Locks。这是对的,因为在级联删除期间,Key Range Locks可以阻止新记录的插入。因此表的引用完整性被保持。我们来看一个具体的例子。在第1步我们创建2个表,在2个表之间定义外键,并启用级联删除。
1 -- Create a new parent table 2 CREATE TABLE Parent 3 ( 4 Parent1 INT PRIMARY KEY NOT NULL, 5 Parent2 INT NOT NULL 6 ) 7 GO 8 9 -- Create a new child table 10 CREATE TABLE Child 11 ( 12 Child1 INT PRIMARY KEY NOT NULL, 13 Child2 INT NOT NULL, 14 -- The following column will contain a Foreign Key constraint 15 Parent1 INT NOT NULL 16 ) 17 GO 18 19 -- Create a foreign key constraint between both tables, 20 -- and enable Cascading Deletes on it 21 ALTER TABLE Child 22 ADD CONSTRAINT FK_Child_Parent 23 FOREIGN KEY (Parent1) REFERENCES Parent(Parent1) 24 ON DELETE CASCADE 25 GO 26 27 -- Insert some test data 28 INSERT INTO Parent VALUES (1, 1), (2, 2), (3, 3) 29 INSERT INTO Child VALUES (1, 1, 1), (2, 2, 1), (3, 3, 1) 30 GO
现在当你开始新的事务,你从父表里删除值为1的记录,SQL Server也会从子表里删除对应的记录(在这里是3条),因为我们启用了级联删除:
1 -- Start a new transaction and analyze the acquired locks 2 BEGIN TRANSACTION 3 4 -- This statement deletes the record from the parent table, 5 -- and the 3 records from the child table 6 DELETE FROM Parent 7 WHERE Parent1 = 1 8 9 -- SQL Server uses 3 RangeX-X locks, even with the default 10 -- Isolation Level of Read Committed 11 SELECT * FROM sys.dm_tran_locks 12 WHERE request_session_id = @@SPID 13 14 COMMIT 15 GO
在事务执行期间,你可以查看下DMV sys.dm_tran_locks,你可以看到你的会话需要获取3个RangeX-X锁——Key Range Locks!在删除期间,SQL Server需要这些锁来阻止新记录的插入。我们在这里可以看到,SQL Server明显把你的事务隔离级别提升到可串行化来保证你事务的准确性。
小结
从这个文章可以看出,在SQL Server是没有任何保证的。我经常问用户,在SQL Server里,你们知道各个隔离级别,锁行为的具体信息
本文转自Woodytu博客园博客,原文链接:http://www.cnblogs.com/woodytu/p/4633351.html,如需转载请自行联系原作者