搜索引擎系统学习是大学时候的毕业设计,简单整理了一下相关知识片段。
搜索引擎的原理和分析指标
(1)搜索引擎的工作原理
搜索引擎的工作原理大致可以分为:
搜集信息:搜索引擎的一个部分可以实现信息自动搜集。
整理信息:搜索引擎通过创建索引为抓取到的信息添加规则。
接受查询:用户向搜索引擎输入关键词提交查询,系统接受用户查询,并且排序后并返回查询结果。搜索引擎根据每个用户的不同关键词检查索引库,迅速找到用户需要的资料,并返回给用户。目前,搜索查询结果主要是以含有部分摘要信息的网页链接给出的,这样利用上述链接,使用者可以访问含有所需资料的站点与网页。一般情况下,搜索引擎会提供部分摘要信息在这些链接下,可以帮助用户判断此链接是否含有自己需要的内容。
(2)搜索引擎的评价及分析指标
在传统的评价体系中,衡量搜索引擎的基本指标是召回率(Recall)和准确率(Pricision)。这两项标准一直是被广泛承认的主要标准。准确率是搜索出的文档数与所有的文档数的比率;召回率为搜索出的相关文档数与实际相关文档数的比值。
相关度——专人评估每个搜索引擎的前几个结果,评价标准有是否是正态相关等,著名的指标有DCG等。
速度——就是用户输入搜索词,到得到搜索结果的时间。这是李开复老师提出的评价体系,经验告诉我们,0.2秒的速度会导致用户满意度的落差,降低未来重复使用的机会。
索引规模——搜索引擎会了解引擎自己的规模,通过了解爬虫抓取到的网页(除去重复的),通常不知道另外的搜索引擎的规模,于是我们可以根据对比两方搜索结果的爬取,得知有多少网页独有的,可以推断出搜索引擎的索引规模。
新鲜度——搜索结果的时效性,并不限于新闻内容,其他的例如促销信息等也和时效息息相关。
稳定性——称为搜索服务的系统稳定性,也是所有系统主要的评判标准。
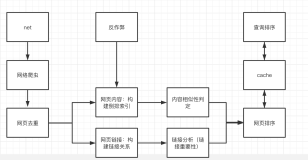
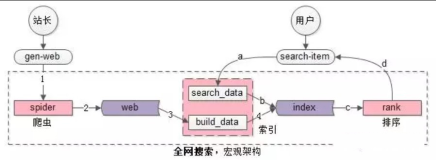
(3)搜索引擎的组成与结构
一般的,全文(文本)搜索引擎由可以细分为三个模块,分别是爬虫搜索和信息处理部分、索引处理部分、检索服务部分(用户查询部分):
爬虫搜索部分主要在互联网中通过多种搜索策略,搜集信息,。
索引处理部分是理解编排爬虫搜索部分所抓取到的信息,从中抽取出索引内容,生成文档库的索引表,同时添加摘要等。
检索服务部分是根据用户的查询在索引库中快速检索文档,进行相关度评价,对将要输出的结果排序,并能按用户的查询需求合理反馈信息。
爬虫搜索和信息处理部分的设计和实现
(1)网络爬虫设计
网络爬虫可以理解为一个简易的浏览器机器人。
爬虫可以自动抓取网页信息,按照一定的策略搜集网页,并且判断与关键词是否相关,这是整个系统的核心。网络爬虫有很多种,根据爬行策略等。最原始的是传统爬虫。也是最经典的,给传统爬虫一个或几个网页链接地址。爬虫爬取的过程中,会不断补充新的链接,获得接下来网页上的URL,理论上,一个爬虫甚至可以爬取整个互联网。除非我们设置一定的边界条件。
(1)设计基于Java网络编程的爬虫;
(2)通过IO操作等,去除待爬取URL列表对应的URL的网页代码;
(3)提取网页信息,本次设计使用的是传统爬虫。这里要说明聚焦爬虫和传统爬虫的主要区别点,聚焦爬虫可以设计匹配算法,判断网页和需要的主题是否相关,避免不必要的爬取;
(4)根据一定的搜索策略,如深度搜索,设计从第一个链接出发,依次访问该网页上的所有链接,访问完成后,可以设置递归算法访问下一层,直到达到设定的搜索策略。
(2)提取网页中的有效信息
从HTML页面提取内容所面临的主要问题是,我们必须寻找一种方法精确地识别出自己想要的那一部分内容。
以下是利用正则表达式匹配并提取网页中特定信息的方法:
|
1
2
3
4
5
|
正则匹配网页中所有URL链接:
<a[^>]*?>[\s\S]*?</a>
获取图片:
<img[^>]*?/?>
<div[^>]*?id=
"idname"
[^>]*?>[\s\S]*?</div>
|
(3)对搜集的信息进行分词
Lucene自带了多个分词器StandardAnalyzer,CJKAnalyzer,以及MMAnalyzer(极易中文分词组件)等。
目前应用比较多的是MMAnalyzer,特别是Lucene较早的版本,本次设计的系统,应用的分词组件就是极易中文分词组件。
分词算法的设计和理解需要较深入的数学和计算机科学知识,在这里不做研究,只是简单了解常见的分词算法。
现有的中文分词算法可分为三大类,这里我们主要研究基于字符串匹配的分词方法。
基于字符串匹配的分词方法最容易理解。它的实现很简单,应用却广泛,我们也可以称之为机械分词。机械分词算法通过一系列的步骤,例如通过建立词典,按照一定的策略,类似我们去查词典的行为。就可以将待分析的字符串与一个足够大的机器词典中的词条进行匹配,一旦找到某个字符串,就会输出匹配成功,我们可以理解为匹配到一个合适的关键词。
比如搜索“济南大学好不好”,则返回结果会包含很多“济南大学”,“济南””大学”等词语的网页,搜索引擎如果采用正向最大匹配去判断,就需要把“济南大学”当做一个不可拆分的词语来索引记录并返回最终结果。
索引处理部分的设计和实现
(1)索引技术及搜索的实现
倒排索引不是由具体的记录来确定属性值,和通常的认识相反,由属性值来确定记录,叫做倒排索引(inverted index)。倒排文件(inverted file)就是利用倒排索引的文件。
建立倒排索引是搜索引擎的关键步骤。倒排索引一般表示为一个关键词,然后是它的频度(出现的次数),位置(出现在哪个网页中,同时包括有关的日期,所有者等信息),相当于为互联网的上千万页网页做了一个索引,如同一本词典的目录。用户想看浏览那一个单词,根据目录索引即可找到相关的页面。
Lucene应用了倒排的思想,建立倒排文件结构,倒排的理解下面会说明。该结构及相应的生成算法如下:
设有两篇日志A和B,
日志A的内容是,“Haha,Today is sunny!”
日志B的内容为,”Oh,Today is rainning!”
(1)分析日志的关键词。Lucene类似数据库中的字段查询,是基于关键词索引和查询的,我们必须取得数据的关键词,在这里本文简单介绍一下分词:
现在有某篇日志博文,可以理解为一个字符串,最开始的操作是需要找出所有单词。英文单词比较好处理,中文的处理在下面介绍。
日志里的”Haha”等词没有什么实际意义,这些不代表概念的词需要过滤掉。
在lucene中以上措施由Analyzer类完成。 经过上面处理后,
日志1的所有关键词为:[today] [is] [sun] 。
日志2的所有关键词为:[tomorrow] [is] [rain]。
(2)建立倒排索引。得到关键词后,我们就可以建立倒排索引了。上面的对应关系是:“日志ID”去对应“日志中的关键词”。倒排索引后会变成: “日志中关键词”去对应“拥有该关键词的所有日志ID”。
日志A,B经过倒排后变成:
| 关键词 |
日志ID |
| today |
A |
| tomorrow |
B |
| is |
A/B |
| sun |
A |
| rain |
B |
定位关键词在哪些日志中还不够,还需要了解关键字在日志中出现的两种位置,出现位置和出现次数:
1)字符位置,日志中的出现位置;
2)关键词位置,该词是日志中第几个关键词(词组(phase)查询快,节约索引空间),在这里我们使用第二种位置。
| 关键词 |
日志ID[出现频率] |
出现位置 |
| today |
A[1] |
1 |
| tomorrow |
B[1] |
1 |
| is |
A[1] |
2 |
lucene索引实现中比较核心的实现就是刚才的操作。Lucene这里放弃采用数据库索引中经常应用的B+树结构,按字符顺序排列关键词,因此我们用过二分查找(Binary Search)快速获得关键词的定位。
(3)进一步压缩和实现。Lucene中引入了field的概念,用于表达信息所在位置,在《淘宝技术十年》一书中,淘宝最初的商品搜索架构Searcher就是采用这种类似的存储结构,索引创建中,域的详细信息被读写在词典文件中,一个field信息对应一个关键词,可以极大缩减了存储开支。Lucene会进一步将上面三列分别作为词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。词典文件是Lucene中重要的数据结构,文件拥有每个关键字的记录,指向其他文件的指针也可以保存。于是我们可以找到该关键字的位置频率信息。
(4)建立索引后,可以很容易的使用二分查找去定位,查询速度非常快,
而如果用普通的顺序匹配算法,耗费时间将会非常大。
(2)中文分词技术
词语是语言学中最小的,并且能够独立活动的语言成分。和英语不同,中文没有空格这一英文单词之间的自然分界符。而汉语远没有那么简单,汉语的基本书写单位是字,词语和词语之间没有特殊的区分标记,同时,存在着大量的一次多意等。中文搜索引擎中,中文分词是信息处理和检索的基础,也是关键。例如,英文句子“Today is fine.”,用中文则为:“今天真好。”。对于英文句子,计算机可以很简单通过空格区分三个单词,但是想要理解“今天”“天真”难度就比较大。如何把中文的汉字文字序列,也就说我们平时说的话,读的句子,处理一系列有意义的词,称为中文分词。
中文分词技术在人工智能中,是自然语言处理技术的一种。对于一句话,比如有意思的“前门到了,请从后门下车”,我们可以在生活中区分,但是如何让电脑像人脑一样,让计算机理解这个过程,这是人工智能的一个重要研究方向,就是分词算法。
开源社区中存在着众多中文分词工具,如盘古分词,庖丁中文分词等,应用比较广泛的是IK Analyzer。
IK Analyzer 是一个开源的中文分词工具包。从第一版开始,IKAnalyzer推出多个大版本。起初, IK Analyzer和Luence一起,作为主要的应用,结合中国分词组件字典和解析算法。但是随着进一步发展,IK Analyzer独立出来,成为面向全部系统的开放分词组件,不过,和lucene结合使用最好。IK Analyzer可以在不需要标注词性的情况下,实现较好的分词效果。IK Analyzer可以通过配置词典文件,进一步提升分词效果。
(3)分词 建立索引
下面说明常用的插件工具,CJKAnalyzer分析器的思想:
如果处理中文汉字,CJK会对读取到的两个字作为一个词条。
例如赵钱孙李,使用CJKAnalyzer分析器分词后会得到如下词条:
赵钱 钱孙 孙李。
进而程序会根据选定的词典库,进行逐个词条的匹配,这是一项很耗时的工作,具体的过程可以参考源码中的实现,这里只是简单介绍。
下面是一个CJKAnalyzer 分词的简单实验。
我们输入一段文本:“植树节,我们来到山上,大家一起新勤劳动,每个人都很高兴”。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public
class
BingoAnalyzer {
public
static
void
main(String[] args) {
try
{
File file =
new
File(
"E:\\bingo\testbingo1.txt"
);
FileReader endWords =
new
FileReader(
"E:\\bingo\testbingo2.txt"
);
Reader reader =
new
FileReader(file);
Analyzer bal =
new
CJKAnalyzer();
TokenStream ts = bal.tokenStream(
""
, reader);
Token t =
null
;
int
n =
0
;
while
((t = ts.next()) !=
null
){
n ++ ;
System.out.println(
"词条"
+n+
"分词结果 :"
+t.termText());
}
System.out.println(
"产生词条"
+n+
" 条"
);
}
catch
(Exception e) {
e.printStackTrace();
}
}
}
|
上面的程序中只是简单演示了如何分词,输出结果如下:
词条1分词结果:植树
词条2分词结果:节我
词条3分词结果:们来
词条4分词结果:到山
词条5分词结果:上大
词条6分词结果:家一
词条7分词结果:起辛
词条8分词结果:勤劳
词条9分词结果:动每
词条10分词结果:个人
词条11分词结果:都很
词条12分词结果:高兴
产生词条12条。
我们可以看到,大概会产生一定数量的垃圾词条,有些还不可用。如果使用Lucene标准分词器StandardAnalyzer,开销大概会减小一半。但是效率较低,而且两者都要对重复的词条进行一些处理。
CJKAnalyzer分析器的分词工具是CJKTokenizer核心类。对词条的过滤操作,CJKAnalyze通过stopTable类,在程序中指定。
(3)文档分析及过滤
索引建立,至关重要。例如,我们需要对d:\\test\index目录下的文件进行搜索。首先要做的是,建立索引。
在lucene中,大致可以划分为一下几个操作:
(1)创建存放索引的目录Directory
(2)创建索引器配置管理类IndexWriterConfig
(3)lucene中的索引目录等类创建索引器
(4)利用前面创建好的索引器,采用Lucene的数据结构document写入到文件中。
检索服务部分的设计与实现
(1)lucene全文检索的实现机制
Lucene的API设计的非常实用,可以理解为一个大型的数据库,通过存储结构/接口这一结构,可以方便的进行查询等操作。
索引表通过IndexWriter建立,可以理解为数据库中的table。Lucene通过Analyzer指定构建方式,Lucene提供了几种环境下使用的Analyzer:SimpleAnalyzer、StandardAnalyzer、GermanAnalyzer等,其中StandardAnalyzer是经常使用的,因为它提供了对于中文的支持。
(2)Lucene基于索引的查询
Lucene蕴含了丰富的面向对象思想,作为Apache通用的工具包,Lucene给那些需要将全文检索功能添加到系统中的软件开发人员提供了非常多的便利。
下面是学习过程中,Lucene基于索引的复合查询代码片段:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
//新建查询实例
Query query=MultiFieldQueryParser.parse(
"索引"
,
new
String[]{
"title"
,
"content"
},analyzer);
Query mquery=
new
WildcardQuery(
new
Term(
"sender"
,
"bluedavy*"
));
TermQuery tquery=
new
TermQuery(
new
Term(
"name"
,
"jerry"
));
BooleanQuery bquery=
new
BooleanQuery();
bquery.add(query,
true
,
false
);
bquery.add(mquery,
true
,
false
);
bquery.add(tquery,
true
,
false
);
//索引查询实例
Searcher searcher=
new
IndexSearcher(indexFilePath);
Hits hits=searcher.search(bquery);
for
(
int
i =
0
; i < hits.length(); i++) {
System.out.println(hits.doc(i).get(
"name"
));
}
|
搜索引擎开源框架的选型
(1)Nutch
Apache Nutch是一个高度可扩展的和可伸缩的开源网络爬虫软件项目,起源自Apache Lucene。项目多样化,现在包括两个协议的代码库:
Nutch 1.x:是一个成熟,生产就绪的爬虫。1.x依赖于Apache Hadoop。
Nutch 2.x:一个新兴的替代,直接的灵感来自1.x,但不同的一个关键:抽象存储远离任何特定的基础数据存储,采用Apache Gora处理对象持久性映射。这意味着我们可以存储都极其灵活的模型/栈的实现(提取时间,地位,内容,解析文本,类型,反向链接,等等)为多个NoSQL存储解决方案。
Nutch 提供了运行一个搜索引擎所需的全部工具,包括Web爬虫和全文搜索。
Nutch是基于Lucene的。Lucene为Nutch提供了文本索引和搜索的API。
在Nutch和Lucene的选择上,评判的标准主要是是否需要抓取数据的话,如果不需要,应该使用Lucene。
(2)Lucene
Lucene 是apache软件基金会一个开源的索引工具包,
是一个基于Java的文本搜索引擎索引工具包,提供一个全文搜索引擎的整体架构,
以及完整的查询和索引引擎,其中包含了部分文本处理工具。
Lucene的发展很快,致力于为搜索研发人员贡献了一个方便易用的组件,
使得实现全文检索的功能更加方便,同样,你也可以以此为骨骼建立起一套完备的全文搜索引擎。
(3)lucene全文检索的实现机制
Lucene的API设计的非常实用,可以理解为一个大型的数据库,通过存储结构/接口这一结构,可以方便的进行查询等操作。
索引表通过IndexWriter建立,可以理解为数据库中的table。Lucene通过Analyzer指定构建方式,Lucene提供了几种环境下使用的Analyzer:SimpleAnalyzer、StandardAnalyzer、GermanAnalyzer等,其中StandardAnalyzer是经常使用的,因为它提供了对于中文的支持。
本文转自邴越博客园博客,原文链接:http://www.cnblogs.com/binyue/p/3464052.html,如需转载请自行联系原作者