在transactional replication中,在publication中执行了一个更新,例如:update table set col=? Where ?,如果table中含有大量的数据行,那么该操作会产生大量数据更新操作。在subscription端,这个更新操作会分解成多条command(默认情况下产生一个Transaction,每个数据行产生一个Command)。
Distribution Agent包含两个子进程,Reader和Writer。 Reader负责从 Distribution 数据库中读取数据,Writer负责将reader读取的数据写入到订阅数据库。Reader是通过 sys.sp_MSget_repl_commands 来读取Distribution数据库中(读取Msrepl_transactions表和Msrepl_Commands表)的数据。
Distribution Reader thread executes sp_MSget_repl_commands query to retrieve pending commands from the Distribution database and storing in an internal queue.
Distribution Writer thread writing queue commands to the Subscriber via parameterized stored procedures prefixed with sp_MSupd…, sp_MSins…, sp_MSdel… to apply individual row changes to each article at the subscriber.

CREATE PROCEDURE sys.sp_MSget_repl_commands ( @agent_id int, @last_xact_seqno varbinary(16), @get_count tinyint = 0, -- 0 = no count, 1 = cmd and tran (legacy), 2 = cmd only @compatibility_level int = 7000000, @subdb_version int = 0, @read_query_size int = -1 )
1,在Distribution Agent同步数据到Subscriber中时,发现Subscriber中有很多Session处于 ASYNC_NETWORK_IO,说明该Session返回的数据集太大,导致Writer不能及时将Command读取,使用Distribution Latency增加,该Session正在执行的sp是:sys.sp_MSget_repl_commands,正在执行的语句如下,这条查询用于返回Distribution Agent读取的Commands。
select rc.xact_seqno, rc.partial_command, rc.type, rc.command_id, rc.command, rc.hashkey, -- extra columns for the PeerToPeer resultset -- originator_id, srvname, dbname, originator_publication_id, originator_db_version, originator_lsn NULL, NULL, NULL, NULL, NULL, NULL, rc.article_id from MSrepl_commands rc with (nolock, INDEX(ucMSrepl_commands)) JOIN dbo.MSsubscriptions s with (INDEX(ucMSsubscriptions)) -- At end, we use the FASTFIRSTROW option which tends to force -- a nested inner loop join driven from MSrepl_commands ON (rc.article_id = s.article_id) where s.agent_id = @agent_id and rc.publisher_database_id = @publisher_database_id and rc.xact_seqno > @last_xact_seqno and rc.xact_seqno <= @max_xact_seqno and (rc.type & @snapshot_bit) <> @snapshot_bit and (rc.type & ~@snapshot_bit) not in ( 37, 38 ) and (@compatibility_level >= 9000000 or (rc.type & ~@postcmd_bit) not in (47)) order by rc.xact_seqno, rc.command_id asc OPTION (FAST 1)
通过SQL Server Profile抓取当前正在执行的SQL,从抓取的大量语句中发现,一般只会用到前四个参数,第三个和第四个参数的值是固定不变的,分别是0和10000000。
exec sp_MSget_repl_commands 74,0x0008ECE200307E10014C00000000,0,10000000
2,Distribution Agent 读取的Commnd数量
sys.sp_MSget_repl_commands 返回的Result Set的大小跟变量 @max_xact_seqno 有关
rc.xact_seqno > @last_xact_seqno and rc.xact_seqno <= @max_xact_seqno
对变量 @max_xact_seqno 的赋值,是由 @read_query_size 参数控制的,在调用该sp时,其值是默认值-1。下面代码表示 将 dbo.MSrepl_commands 最大的 xact_seqno 赋值给变量@max_xact_seqno,那么Distribution Agent 每次都会读取所有的Command。
--Note4: The max_xact_seqno is calculated based on the @read_query_size parameter -
-- this parameter limit the number of commands retrieved by this call.
if(@read_query_size <= 0) begin select @max_xact_seqno = max(xact_seqno) from MSrepl_commands with (READPAST) where publisher_database_id = @publisher_database_id and command_id = 1 and type <> -2147483611 end else begin -- calculate the @max_xact_seqno from the next @read_query_size commands. declare @GetMaxCommand nvarchar(1024) select @GetMaxCommand = N'select top ' + convert(nvarchar(1024),@read_query_size)+ N' @max_xact_seqno = xact_seqno from MSrepl_commands with (READPAST) where publisher_database_id = @publisher_database_id and type <> -2147483611 and xact_seqno > @last_xact_seqno order by xact_seqno, command_id asc' exec sys.sp_executesql @GetMaxCommand, N'@max_xact_seqno varbinary(16) output ,@last_xact_seqno varbinary(16),@publisher_database_id int', @publisher_database_id = @publisher_database_id, @max_xact_seqno = @max_xact_seqno output, @last_xact_seqno=@last_xact_seqno if(@max_xact_seqno is null) select @max_xact_seqno = @last_xact_seqno end
3,为@read_query_size传递一个参数值,而不是使用默认值 -1,由于该sp是system stored procedure,不能直接修改,而Distribution Agent profile中也没有参数能够控制Reader读取的Command数量。
其实,需要换种角度来思考,长时间出现ASYNC_NETWORK_IO,根本原因是产生的Trasaction和Command过多,而Disk IO跟不上。如果Log Reader将big transaction 拆分成小的Transaction写入到Distribution中。同时,Distribution Reader很快将数据读取,写入到in-memory queue中,然后Distribution Writer将Queued Commands 写入到Subscriber中,完成数据的一次同步。只要Distribution Reader的读取速度能够跟上Log Reader写入的速度,而Distribution Writer的写入速度也能跟上Distribution Reader的读取速度,这样Distribution Latency 就会很小。
4,调整Log Reader Profile 参数
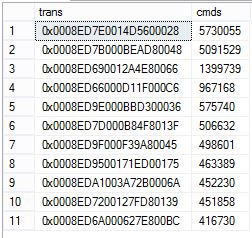
在DW中,Transaction的数量少,但是每个Transaction包含的Comman数量极大,调整 -ReadBatchSize 的数据,在每个processing cycle中,只处理少量的Transaction,默认值是500;查看 MSrepl_transactions,每日的Transaction数量在300左右,将 -ReadBatchSize =10。
参考《调整Replication Agent Profile的参数》,-MaxCmdsInTran 参数必须在Agent中,通过Job Step Properties 修改Command 参数来实现。
使用-MaxCmdsInTran 参数,使每个Transaction包含的Command不能超过一定的数量,对于过大的Command,将其拆分成多个Transaction,默认值是0,表示不限制Transaction中Command的数量,保留Transaction的原始边界。查看 MSrepl_commands,每日的每日的Command数量在2千万左右,将 -MaxCmdsInTran=10万,能满足大多少Transaction的需求。
select top 11 t.xact_seqno as trans, count(0) as cmds from dbo.MSrepl_transactions t with(nolock) inner join dbo.MSrepl_commands c with(nolock) on t.xact_seqno=c.xact_seqno where entry_time between '20160806' and '20160807' group by t.xact_seqno order by cmds desc
Appendix:
1,Log Reader Profile 参数:《Replication Log Reader Agent》
-ReadBatchSize number_of_transactions
Is the maximum number of transactions read out of the transaction log of the publishing database per processing cycle, with a default of 500. The agent will continue to read transactions in batches until all transactions are read from the log. This parameter is not supported for Oracle Publishers.
-MaxCmdsInTran number_of_commands
Specifies the maximum number of statements grouped into a transaction as the Log Reader writes commands to the distribution database. Using this parameter allows the Log Reader Agent and Distribution Agent to divide large transactions (consisting of many commands) at the Publisher into several smaller transactions when applied at the Subscriber. Specifying this parameter can reduce contention at the Distributor and reduce latency between the Publisher and Subscriber. Because the original transaction is applied in smaller units, the Subscriber can access rows of a large logical Publisher transaction prior to the end of the original transaction, breaking strict transactional atomicity. The default is 0, which preserves the transaction boundaries of the Publisher.
2,《Transactional Replication - Slow running sp_MSget_repl_commands》
ASYNC_NETWORK_IO doesn't actually mean network, it's a bit of a lie. It means that it's simply waiting for something external to SQL... Probably a response from your disks.
Therefore the only thing I can think is that either the drive with your distribution database is a bottleneck, or maybe your distribution tables are getting too large. You could also check your indexes on the replication tables for fragmentation. I've had issues with these before... The underlying problem is different to yours, but the cause could well be the same... SQL Server "Distribution clean up: distribution" Job Failing Large MSRepl_commands
3,《Transactional Replication Conversations》
The Reader-Thread conversation is responsible for querying the Distribution database for the list of transactions to apply at the subscriber. It first queries the subscriber metadata table to find the last successfully replicated transactions. Next the Reader-Thread executes sp_MSget_repl_commands to begin reading rows from the Distribution database and populates this rows into an in-memory queue. As the rows get queued, the Distribution Agent Writer-Thread conversation begins writing these rows to the Subscriber.
参考文档:
Performance Tuning SQL Server Transactional Replication – Part 1
Transactional Replication Conversations