数据库使用Table来存储海量的数据,细分Table结构,数据最终存储在Table Column中,因此,在设计Table Schema时,必须慎重选择Table Column的Data Type,数据类型不仅决定了Column能够存储的数据范围和能够进行的操作,而且合适的数据类型还能提高查询和修改数据的性能。数据类型的选择标准既要满足业务和扩展性的需求,又要使行宽最小(行宽是一行中所有column占用的Byte)。最佳实践:使用与Column最大值最接近的数据类型。
例如,bit 类型只能存储1和0,能够对bit进行逻辑比较(=或<>),不能对进行算术运算(+,-,*,/,%),不要对其进行>或<的比较,虽然bit类型支持,但是,这不 make sense。

declare @b1 bit declare @b2 bit set @b1=1 set @b2=0 -- right,return 0 select iif(@b1=@b2,1,0) --error,The data types bit and bit are incompatible in the add operator. select @b1+@b2
在设计Table Schema时,要实现三大目标:占用空间少,查询速度快,更新速度快。这三个目标有些千丝万缕的关联,设计良好的Table Schema,都会实现,反之,设计差的Table Schema,都不能实现。
内存是访问速度最快的存储介质,如果数据全部存储在内存中,那会极大的提高数据库系统的吞吐量,但是,每个数据库系统能够使用的内存有限,为了提高查询性能,SQL Server将最近使用过的数据驻留在内存中。SQL Server 查询的数据必须在内存中,如果目标数据页不在内存中,那么SQL Server会将数据从Disk读取到内存中。SQL Server 响应时间跟数据加载很大的关系,如果加载的数据集占用的空间小,数据页分布集中,那么SQL Server使用预读机制,能够很快将数据加载到内存,相应地,SQL Server的响应时间会很小。
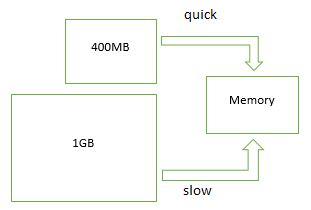
创建索引能够提高查询性能,其实是因为,索引字段比Base Table的字段少,索引结构占用的存储空间小,SQL Server 加载索引结构的耗时少。由于索引结构是有序的,避免了全表扫描,也能提高查询性能。使用窄的数据类型,使用数据压缩,创建BTree索引,创建ClumnStore 索引,都能减少数据集占用的存储空间,提高数据加载到内存的速度。SQL Server在执行用户的查询请求时,每一行数据都必须在内存中,因此,数据集占用的空间越少,加载的过程越快,SQL Server的查询性能越高。
一,窄的数据行会节省存储空间,减少IO次数
使用窄的数据类型,使行的宽度达到最小,在存储相同数据量时,能够节省存储空间,减少Disk IO的次数。
在存储日期数据时,Date占用3Byte,DateTime占用8Byte,DateTime2(2)占用6Byte,DateTime2(4)占用7Byte,DateTime2(7)占用8Byte。不管从表示的精度上,还是从占用的存储空间上来看,DateTime2(N)都完胜DateTime。
例如,存储‘yyyy-mm-dd MM:HH:SS’格式的日期数据,有以下4中选择:
- 使用字符串 varchar(19) 或 nvarchar(19)存储,十分不明智,前者占用19Byte后再占用38Byte;
- 使用数据类型 datetime2(7)存储,占用8Byte,虽然精度更高,但是毫秒都是0,浪费存储空间;
- 使用数据类型 datetime存储,占用8Byte,如果需要存储毫秒,datetime不满足;
- 使用数据类型 datetime2(2)存储,占用6Byte,相比较是最理想的。
由于SQL Server存储数据是按照row存储数据的,每个Page能够存储的数据行是有限的。在查询同等数量的数据行时,如果row宽度窄,那么每个page会容纳更多的数据行,不仅减少IO次数,而且节省存储空间。
二,在窄的数据列上创建index,能够提高查询性能
在窄的数据列上创建Index,索引结构占用的存储空间更小,SQL Server消耗更少的Disk IO就能将索引结构加载到内存中,能够提高查询性能。
在创建Index时,必须慎重选择聚集索引键,主要有两个原因
1,聚集索引其实就是表本身,SQL Server必须保持物理存储顺序和逻辑存储顺序一致
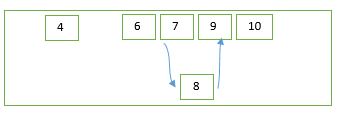
在SQL Server中,Clustered Index能够确定Table的物理存储,使Table的物理存储顺序和聚集索引键的逻辑顺序保持一致。在对Table数据进行update时,如果更新聚集索引键,导致数据行所在聚集索引键必须移动,此时,SQL Server不能“原地更新”数据行,必须将数据行移动到其应有的物理位置上,Table的物理存储顺序和聚集索引键的逻辑顺序才能保持一致。SQL Server将Update命令拆分成等价的delete命令和insert 命令。
示例:聚集索引键4被修改为8,那么,SQL Server将数据行5删除,然后再相应的位置上插入数据行8。

如果插入的位置上没有多余的存储空间,那么,插入操作会导致页拆分,产生索引碎片,影响查询性能。
2,NonClustered Index的叶子节点中,都包含Clustered Index键。
例如,在表上有两个索引:Clustered Index(c1,c2),Nonclustered Index(c2,c3),实际上,Nonclustered index的索引定义(c2,c3)include(c1),即,在Nonclustered Index的叶子节点中,包含Clustered Index所有的Index Key。包含列和Index Key的区别在于,Index Key用于路由索引结构,而包含列用于返回数据,不提供搜索功能。
由于Clustered Index“无所不在”,Clustered Index的索引键最好创建在窄的,不变的,唯一的和只增长的数据列上。在创建Clustered Index时,最好是唯一索引(Unique Index)。窄的数据行会使每一个Index page存储更多的index key,SQL Server Engine定位到某一行所经过的节点数更少,即导航的Path更短,加载和查询速度更快。
由于每一个nonclustered index的Index pages或index key columns中都会包含Clustered Index key columns,如果Clustered Index key columns的宽度比较大,这会导致所有nonclustered index的索引树占用较大的存储空间,Disk IO更多,更新和查询操作都会变慢。
In general, it is best practice to create a clustered index on narrow, static, unique, and ever-increasing columns. This is for numerous reasons. First, using an updateable column as the clustering key can be expensive, as updates to the key value could require the data to be moved to another page. This can result in slower writes and updates, and you can expect higher levels of fragmentation. Secondly, the clustered key value is used in non-clustered indexes as a pointer back into the leaf level of the clustered index. This means that the overhead of a wide clustered key is incurred in every index created.
三,使用正确的数据类型,减少转换的次数
在SQL Server中,对数据进行强制类型转换或隐式类型转换都需要付出代价,所以,使用正确的数据类型,避免类型转换是十分必要的。例如,如果存储的数据格式是‘yyyy-mm-dd MM:HH:SS’,虽然字符串类型和Datetime类型能够隐式转换,但是使用字符串类型 varchar(19)或 nvarchar(19)存储是十分不明智的,不仅浪费存储空间,而且隐式转换对性能有负作用。
四,常见数据类型所占用的字节数
数据类型大致分为四种:数值类型,日期和时间类型,字符串类型,GUID,使用DataLength()能够查看任意数据类型的变量所占用的字节数量
1,数值类型
对于整数类型,TinyInt 占用1Byte,表示的整数范围是:0-255;SmallInt,int和bigint 分别占用2B,4B和8B。
对于小数类型,decimal(p,s)表示精确的小数类型,float(n)表示近似的小数类型,常用于表示百分比,除法的结果,有两种类型float(24)占用4B,float(53)占用8B,参考《SQL Server的小数数值类型(float 和 decimal)用法》。
2,日期和时间类型
- date表示日期,占用3B;
- Datetime2(n),根据时间的毫秒部分来确定占用的字节数量:当n是1,或2时,占用6B;当n是3,或4时,占用7B;当n是5,6,或7时,占用8B;
- datetime占用8B,建议使用datetime2(n)来替代datetime;
3,字符类型
建议使用变长字符类型,varchar和nvarchar,后者占用的字节是前者一倍;如果数据中都是拉丁字母,使用varchar更好。对于LOB数据类型,建议使用varchar(max) 和 nvarchar(max),单列能够存储最大2GB的数据。
变长字符类型 varchar(n) 和 nvarchar(n),N值的最大值是多少?例如:
declare @nv_max varchar(9000) declare @nv_min varchar(0) select @nv_max select @nv_min
赋予 类型 'varchar' 的大小(9000)超出了任意数据类型的最大允许值(8000)。 指定的长度或精度 0 无效。
由此可见,对于varchar(N),N的取值范围的上限是8000,下限是1,可变长度单字节字符类型的取值范围是[1-8000];
- 对于varchar(n),n的最大值是8000;
- 对于nvarchar(n),n的最大值是4000;
- 不管用于变量,还是用于table column,都不能超过8000Bytes,这种限制是由SQL Server的一个Page=8KB决定的。
如果存储的数据占用的字节数超过8000,那么必须使用LOB类型:varchar(max) 和 nvarchar(max),max突破长度8000Byte的限制,达到LOB的最大值2GB。
The size of values specified with MAX can reach the maximum size supported by LOB data, which is currently 2GB. Because the max data types can store LOB data as well as regular row data, you are recommanded to use these data types in future development in place of the text, ntext, or image tyes, which MS has indicated will be removed in a future version.
4,UniqueIdentifier数据类型
UniqueIdentifier数据类型占用16B,GUID的格式是8-4-4-4-12,即'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx',不要使用varchar来存储GUID。
例如,使用varchar来存储GUID,将会浪费20B
declare @ui uniqueidentifier declare @vc varchar(max) set @ui=newid() set @vc=cast(@ui as varchar(max)) select @ui,@vc,datalength(@ui),datalength(@vc)
如果表的数据行总量是5千万,那么使用varchar来存储GUID将会浪费:953MB。在数据类型的选择上,必须锱铢必较,能省就省。
五,示例
模拟一个场景:业务人员需要分析帖子,需要存储的字段:PostID,AuthorName,PostTitle,PostURL,PostContent,PostedTime。
在使用ETL同步社区爬虫数据时,通常会额外增加两个Column:DataCreatedTime和DataUpdatedTime,用于存储新建数据行的时间和最后一次更新数据行的时间。
1,社区分析,通常涉及海量的数据,使用数据压缩(data_compression=page),提高查询性能。
2,增加代理键,使用代理键作为主键。
3,URL使用varchar类型,对于AuthorName,Title和Content需要使用unicode类型来存储。
4,对于时间类型,精度不会很高,使用最节省的数据类型 datetime2(2)来存储,锱铢必较。
5,将最占空间的PostContent和主表Posts分开,实际上是垂直分区,便于快速对主表Posts进行查询和分析。
create table dbo.Posts ( PostID bigint identity(1,1) not null, OriginalPostID bigint not null, AuthorID int not null, Title nvarchar(256) not null, url varchar(2048) not null, PostedTime datetime2(2) not null, IsDeleted bit not null, DataCreatedTime datetime2(2) not null, DataUpdatedTime datetime2(2) not null, constraint PK__Posts_ID primary key clustered(PostID) ) with(data_compression=page); create table dbo.Authors ( AuthorID int Identity(1,1) not null, OriginalAuthorID int not null, Name nvarchar(128) not null, DataCreatedTime datetime2(2) not null, DataUpdatedTime datetime2(2) not null, constraint PK__Authors_AuthorID primary key clustered(AuthorID) ) with(data_compression=page); create table dbo.PostContent ( PostID int not null, Content nvarchar(max) not null, DataCreatedTime datetime2(2) not null, DataUpdatedTime datetime2(2) not null, constraint PK__PostContent_PostID primary key clustered(PostID) ) with(data_compression=page);
推荐阅读《Performance Considerations of Data Types》:
A clustered index created as part of a primary key will, by definition, be unique. However, a clustered index created with the following syntax,
CREATE CLUSTERED INDEX <index_name> ON <schema>.<table_name> (<key columns>);
will not be unique unless unique is explicitly declared, i.e.
CREATE UNIQUE CLUSTERED INDEX <index_name> ON <schema>.<table_name> (<key columns>);
In order for SQL Server to ensure it navigates to the appropriate record, for example when navigating the B-tree structure of a non-clustered index, SQL Server requires every row to have an internally unique id. In the case of unique clustered index, this unique row id is simply the clustered index key value. However, as SQL Server will not require a clustered index to be unique - that is, it will not prevent a clustered index
from accepting duplicate values - it will ensure uniqueness internally by adding a 4-byte uniquifier to any row with a duplicate key value.
In many cases, creating a non-unique clustered index on a unique or mostly unique column will have little-to-no impact. This is because the 4-byte overhead is only added to duplicate instances of an existing clustered key value. An example of this would be creating a non-unique clustered index on an identity column. However, creating a non-unique clustered index on a column with many duplicate values, perhaps on a column of date data type where you might have thousands of records with the same clustered key value, could result in a significant amount of internal overhead.
Moreover, SQL Server will store this 4-byte uniquifier as a variable-length column. This is significant in that a table with all fixed columns and a large number of duplicate clustered values will actually incur 8 bytes of overhead per row, because SQL Server requires 4 bytes to manage this variable column (2 bytes for the count of variable-length columns in the row and 2 bytes for the offset of the the variable-length column of the uniquifier column). If there are already variable-length columns in the row, the overhead is only 6 bytes—two for the offset and four for the uniquifier value. Also, this value will be present in all nonclustered indexes too, as it is part of the clustered index key.