2013年的年初设立了一个目标,年末了把各项目标的完成情况总结一下,准备制订2014计划继续前行。

一、访问学者英语培训
这件事情是从4月份突然冒出来的,一学就是近5个月(4月10到8月31日),由于在年度计划时根本没有预料到,所以对其它项目造成了很大的影响。
院里给了一个机会参加了2013中石化英语分级测试。由于用Supermemo背了6年的单词,并在51talk上匆匆恶补了20节口语课,结果取得了参加英语集训的资格。
在近5个月的时间内,仿佛又回到了学生时代,每天全是听说读写,为了达到结业考试所要求的2B青年标准(听说70分和读写70分),在这个年龄学习英语还真有点吃力。除了阅读与跑步之外,其它时间基本上都是学习英语了。这是结业时写的中石化访问学者英语培训班总结。
知道考试成绩后,把以前荒废的linkedin页面![]() 完善了一下,作为联系国外导师的一张名片。
完善了一下,作为联系国外导师的一张名片。
二、工作与金钱
1、勘探决策支持系统推广
在油田里有一个软件研发团队是多么的不容易,勘探决策支持系统走过了10个年头,软件框架和功能都发生了巨大变化,我自己简单总结了勘探决策支持系统所用到的一些技术点。突然发现团队用GeoToolkit.NET开发了多年的底图、剖面、井身等模块,做了太长时间已经没有什么感觉了,但如果没有基础的人想短期内实现一个专业的剖面或井筒程序,还是相当有难度的。
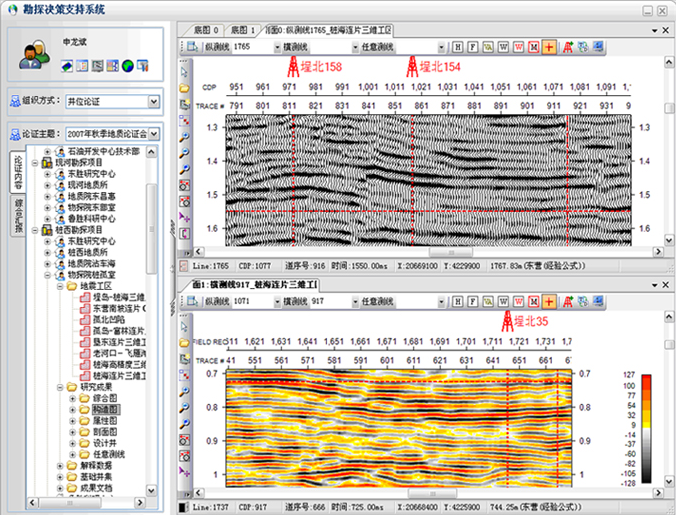
今年系统在西南做到了三期,又推广到了西北油田和吉林油田,团队几个成员真是一会忙东,一会忙西,各单位的数据情况与我们都不一样,在数据方面什么情况都会发生,所以推广一个与数据密切相关的勘探软件,定制化的工作量真是不小。好在团队的成员们都成长起来了,我的任务也轻松了许多,只是12月份到2个地方各忙活了1周多,挑战了底图、剖面中几个编程任务,捡回来了一些以前编程的感觉。
2、科研立项
最近大数据火得不行,看了2本大数据的书,听了2小时的Hadoop,看了一些参考资料,就写了一份勘探决策大数据立项材料,分为大数据存储、大数据分析和大数据可视化三个部分,可惜大数据在能源行业应用前景不明,所以该立项也是希望渺茫。
刚忙完了大数据,又被抓着编写智能勘探立项材料,在勘探工作上达到智能化,感觉写得内容越来越脱离了实际,越来越摸不着头脑。现在的科研立项都是怎么了?
3、勘探数字工作室
在这个项目里主要起草了一份数字工作室的协同环境设计方案。

4、LDM统一存储
勘探决策中为了性能需求目前要存3份SEGY,另外还要存一份LDM(Large Data Management)用于三维可视化,把数据体统一用LDM存储是多年的心愿。9月多开始研究LDM,通过制造一个特殊的SEGY文件,转换成LDM后一点一点地查找各地震道的存储位置,慢慢地弄明白了LDM的内部八叉树存储机制,整理出了一份LDM的格式说明,下一步只剩一些工作量方面的任务,用于从LDM抽测线和各功能改造了。

5、Eclipse解析
把以前的Eclipse油藏数值模拟模型解析程序ecl2txt升级了,可以读取GRID格式的文件了,并把解析过程写了一篇论文,投到《计算机应用研究》的2013年12月的增刊上。在EclipseModel类中加了一个GetSliceK(int k)的方法,可以直接取出一层的模型数据。集成了SW的三维代码,初步直接打开EGRID文件显示在OIV的三维窗口了。

6、iOS立项
给院里报了一个勘探移动服务平台的材料,没有任何反馈,据说总部在移动系统的开发方面有统一安排,不过今年也没有时间和精力弄这个项目了。
三、自我管理
1、读书
今年总共读了18本书,读书笔记在这里。
![image_thumb[5]](https://images0.cnblogs.com/blog/3787/201312/21003904-048ed39297244e0990a69bb1a6dc8072.png "image_thumb[5]")
2、搞定GTD
2013年1月份的时候画了一张年度梦想图,将主要的目标量化后画在这张图上,后来发现这个梦想图与个人的职责范围是对应的,所以按照《搞定3》的第232页重新梳理了职责范围。

看了《拖延心理学》后,写了一篇博文:为什么GTDer不再拖延了?
6月2日,在北京学习期间参加了一个北京的"易GTD"活动,有些失望,一点也没有提到GTD的几个精华:五步流程、六个高度、Next Action、每周回顾等,只是讲了关于如何培养习惯和晨间日记,原来他们的GTD不是Get Things Done的缩写。个人感觉GTD的实践还需要从五步流程慢慢开始,一上来就制定五年规划和目标,然而执行力严重不足,会产生强烈的挫败感,从收集开始GTD实践的第一步会慢慢体会到GTD的强大,这种不断学习、实践、体会、改进的过程本身就是GTD所倡导的。相比较而言,还是上海的GTD演讲俱乐部组织得更加有序,时间和内容控制得都相当出色。
7月7日在北邮旁观了张永锡的GTD幸福行动家活动,晚上吃饭时认识了一些GTD爱好者,还与《小强升职记》的作者周鑫聊得火热。
从2011年开始,GTD已经实践了2周年,写了这篇《GTD两周年的一些体会》。
在访问学者英语培训班上给同学们用英语介绍了GTD。
3、学习Haskell编程语言
完成了《Two Dozen Short Lessons in Haskell》这本书第13章到第24章的习题。
四、家庭
英语培训使我无法脱身,只是在8月时全家一起玩了北京的科技馆、故宫等地方,可惜我没有陪媳妇和孩子去成都。
感觉现在的中考比我以前的高考还压力大,孩子比以前学习更刻苦了,已经进行了四次月考。
经常给父母打个电话问问那边的情况。

五、健康
年初设立的500公里目标虽然只完成了425公里,但重要的还是坚持每周至少锻炼3-4次。在办公室的时候还能坚持跳绳,体重基本上保持在66KG。

年底前Fitbit到货,明年计划用Fitbit来记录运动情况。

六、朋友与同学
回母校参加了本科同学毕业20周年聚会,又比上次聚会大了10岁,时间过得真快啊。
一位好友终于移民加拿大了,去北京机场给他一家送行,祝他在外面发展顺利。
七、业余爱好与娱乐
1、象棋引擎
参加英语培训后,此事情受到很大影响。程序改用C#实现,采用17*14=238棋盘表示的新架构,不再使用位棋盘。单元测试比以前方便多了,但确实比C++慢了不少。可以简单支持主要的Ucci协议,并完成了一个对战的测试程序PonderGame。后来发现置换表的算法有问题,对于negamax形式的算法并没有真正了解,于是看了一些资料,仔细调试看各个结点的变化情况,后来又简单地进行了长将检测。毕竟是个爱好,只有明年抽时间摆弄了。第七届全国计算机博弈锦标赛8月14日在哈尔滨工程大学举行,我当然没能去成。
2、桥牌
经常用iPhone上的Bridge Baron或电脑上的Bridge Master 2000练练做庄水平,一些笔记都记在博客的这个桥牌笔记专栏里了。


本文转自申龙斌的程序人生博客园博文,原文链接:http://www.cnblogs.com/speeding/p/3483022.html,如需转载请自行联系原作者
http://www.cnblogs.com/speeding/