MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
使用索引的目的在于提高查询效率,这篇文章梳理一下索引的实现原理和应用。
1.不同的存储引擎索引实现的数据结构不同
MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如B-Tree索引,哈希索引,全文索引等,
主要存储引擎有MyISAM、InnoDB、MEMORY和MERGE等,在创建表到时候通过engine=或type=来指定所要使用到引擎,
|
1
|
show table status from DBname
|
来查看指定表的引擎。
MyISAM不支持事务,也不支持外键,访问速度快,对事务完整性没有要求或者以SELECT、INSERT为主的应用可以使用这个引擎来创建表,memory数据表使用散列索引,
InnoDB存储引擎则提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM的存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
这里只关注应用最广泛的InnoDB的B-Tree索引。
2.索引实现的B-Tree结构
数据库索引是通过B-Tree实现的,但是为什么使用B-Tree而不是使用红黑树或者其他的查找数据结构呢,
通过对树结构的回顾分析一下。
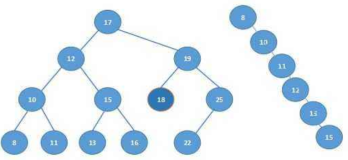
红黑树(Red-Black Tree)是二叉搜索树(Binary Search Tree)的一种改进。我们知道二叉搜索树在最坏的情况下可能会变成一个链表(当所有节点按从小到大的顺序依次插入后)。而红黑树在每一次插入或删除节点之后都会花O(log N)的时间来对树的结构作修改,以保持树的平衡。也就是说,红黑树的查找方法与二叉搜索树完全一样;插入和删除节点的的方法前半部分节与二叉搜索树完全一样,而后半部分添加了一些修改树的结构的操作。
红黑树的每个节点上的属性除了有一个key、3个指针:parent、lchild、rchild以外,还多了一个属性:color。它只能是两种颜色:红或黑。而红黑树除了具有二叉搜索树的所有性质之外,还具有以下4点性质:
1. 根节点是黑色的。
2. 空节点是黑色的(红黑树中,根节点的parent以及所有叶节点lchild、rchild都不指向NULL,而是指向一个定义好的空节点)。
3. 红色节点的父、左子、右子节点都是黑色。
4. 在任何一棵子树中,每一条从根节点向下走到空节点的路径上包含的黑色节点数量都相同。
B-Tree又叫平衡多路查找树。B-树是为了磁盘或其它存储设备而设计的一种多叉平衡查找树,相对于二叉,B树每个内结点有多个分支,即多叉。与红黑树很相似,但在降低磁盘I/0操作方面要更好一些。
为什么使用B-Tree而不是使用红黑树或者其他的查找数据结构,红黑树多用在内部排序,即全部在内存中的,C++的STL中map和set的内部实现就是红黑树,Java集合框架里HashSet和HashTree也是使用红黑树实现,
B树多用在内存里放不下,大部分数据存储在外存上时。因为B树层数少,因此可以确保每次操作,读取磁盘的次数尽可能的少。
3.索引创建的几个原则
(1)适合索引的列是出现在WHERE 子句中的列
最适合索引的列是出现在WHERE 子句中的列,或连接子句中指定的列,而不是出现在SELECT 关键字后的选择列表中的列。
(2)使用惟一索引
考虑某列中值的分布。对于惟一值的列,索引的效果最好,而具有多个重复值的列,其索引效果最差。例如,存放年龄的列具有不同值,很容易区分 各行。而用来记录性别的列,只含有“ M”和“F”,则对此列进行索引没有多大用处。
(3)使用短索引
如果对串列进行索引,应该指定一个前缀长度,只要有可能就应该这样做。例如,如果有一个CHAR(200) 列,如果在前10 个或20 个字符内,多数值是惟一的,那么就不要对整个列进行索引。对前10 个或20 个字符进行索引能够节省大量索引空间,也可能会使查询更快。较小的索引涉及的磁盘I/O 较少,较短的值比较起来更快。更为重要的是,对于较短的键值,索引高速缓存中的块能容纳更多的键值,因此,MySQL也可以在内存中容纳更多的值。这增加 了找到行而不用读取索引中较多块的可能性。(当然,应该利用一些常识。如仅用列值的第一个字符进行索引是不可能有多大好处的,因为这个索引中不会有许多不 同的值。)
(4)利用最左前缀
在创建一个n 列的索引时,实际是创建了MySQL可利用的n 个索引。多列索引可起几个索引的作用,因为可利用索引中最左边的列集来匹配行。这样的列集称为最左前缀。(这与索引一个列的前缀不同,索引一个列的前缀是利用该的前n 个字符作为索引值。)
(5)不要过度索引
不要以为索引“越多越好”,什么东西都用索引是错的。每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能,这一点我们前面已经介绍 过。在修改表的内容时,索引必须进行更新,有时可能需要重构,因此,索引越多,所花的时间越长。如果有一个索引很少利用或从不使用,那么会不必要地减缓表 的修改速度。此外,MySQL在生成一个执行计划时,要考虑各个索引,这也要费时间。创建多余的索引给查询优化带来了更多的工作。索引太多,也可能会使 MySQL选择不到所要使用的最好索引。只保持所需的索引有利于查询优化。如果想给已索引的表增加索引,应该考虑所要增加的索引是否是现有多列索引的最左 索引。如果是,则就不要费力去增加这个索引了,因为已经有了。
(6)考虑在列上进行的比较类型。
索引可用于“ <”、“ < = ”、“ = ”、“ > =”、“ > ”和BETWEEN 运算。在模式具有一个直接量前缀时,索引也用于LIKE 运算。如果只将某个列用于其他类型的运算时(如STRCMP( )),对其进行索引没有价值。
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
4.创建索引的时机
(1)什么时候创建索引
较频繁地作为查询条件的字段,也就是说最适合索引的列是出现在WHERE 子句中的列,或连接子句中指定的列,而不是出现在SELECT 关键字后的选择列表中的列。
(2)什么时候不创建索引
表记录太少:
如果一个表只有5条记录,采用索引去访问记录的话,那首先需访问索引表,再通过索引表访问数据表,一般索引表与数据表不在同一个数据块,这种情况下ORACLE至少要往返读取数据块两次。而不用索引的情况下ORACLE会将所有的数据一次读出,处理速度显然会比用索引快。
唯一性太差的字段:如状态字段、类型字段。那些只存储固定几个值的字段,例如用户登录状态、消息的status等。
这个涉及到了索引扫描的特性。例如:通过索引查找键值为A和B的某些数据,通过A找到某条相符合的数据,这条数据在X页上面,然后继续扫描,又发现符合A的数据出现在了Y页上面,那么存储引擎就会丢弃X页面的数据,然后存储Y页面上的数据,一直到查找完所有对应A的数据,然后查找B字段,发现X页面上面又有对应B字段的数据,那么他就会再次扫描X页面,等于X页面就会被扫描2次甚至多次。以此类推,所以同一个数据页可能会被多次重复的读取,丢弃,在读取,这无疑给存储引擎极大地增加了IO的负担。
更新太频繁地字段不适合创建索引:
当你为这个字段创建索引时候,当你再次更新这个字段数据时,数据库会自动更新他的索引,所以当这个字段更新太频繁地时候那么就是不断的更新索引。
如果一个字段同一个时间段内被更新多次,那么不能为他建立索引。
5.索引失效的几种情况
(1)尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
(2)尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
(3)尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,
|
1
|
select
id
from
t
where
num=10
or
num=20
|
可以这样查询:
|
1
2
3
|
select
id
from
t
where
num=10
union
all
select
id
from
t
where
num=20
|
(4)in 和 not in 也要慎用,否则会导致全表扫描,如:
|
1
|
select
id
from
t
where
num
in
(1,2,3)
|
对于连续的数值,能用 between 就不要用 in 了:
|
1
|
select
id
from
t
where
num
between
1
and
3
|
下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
若要提高效率,可以考虑全文检索。
(5)尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
|
1
2
|
select
id
from
t
where
substring
(
name
,1,3)=
'abc'
--name以abc开头的id
select
id
from
t
where
datediff(
day
,createdate,
'2005-11-30'
)=0
--‘2005-11-30’生成的id
|
应改为:
|
1
2
|
select
id
from
t
where
name
like
'abc%'
select
id
from
t
where
createdate>=
'2005-11-30'
and
createdate<
'2005-12-1'
|
索引失效的情况还有很多,其他的还有使用<>或者单独的单独的>,<;当变量采用的是times变量,而表的字段采用的是date变量时等
6.使用explains优化慢查询
MySQL的Explain命令用于查看执行效果,显示了mysql如何使用索引来处理select语句以及连接表。
可以帮助选择更好的索引和写出更优化的查询语句。
explain的语法如下,在select语句前加上explain就可以:
|
1
|
explain
select
xx
from
tb
where
xx;
|
EXPLAIN列的解释:

table:显示这一行的数据是关于哪张表的
type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
rows:MYSQL认为必须检查的用来返回请求数据的行数
Extra:关于MYSQL如何解析查询的额外信息。