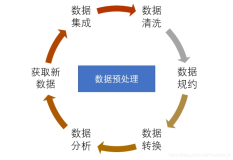
1
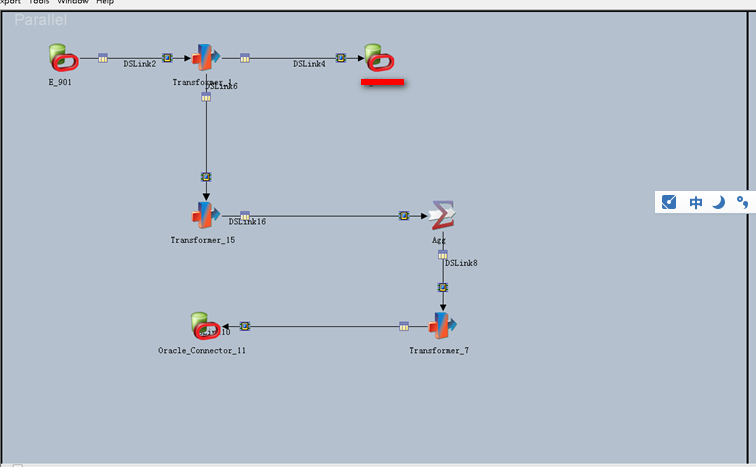
三个控件:
TRANSFORMER:对于任何需要转换的数据集合进行转化并负责传入到其他活动的STAGE
SELECT XM XM_BM,XB XB_BM, F_15TO18(SFZH) SFZH,AGE AGE_BM
FROM XXX
ORACLE CONNECTOR:连接Oracle数据,传送或者被写入数据。
INSERT
UPDATE
SELECT
DELETE
AGGREGATOR:对于单一的输入数据进行分组并且计算每一组的合计和总计
ASH:最好自定义,这样子数据就比较全面
SELECT MAX(AGE_BM) ,ASH FROM XXX GROUP BY ASH;
A经过转换出来 将符合的字段传入B中,其中在转换过程中,取出A的最大时间戳并将其传入到时间戳表中。
A下次活动时取出时间戳之后的值将其存入到B中
这样的话就需给A赋值
右击方案的PROPERTIES
添加时间戳类型一般默认为STRING
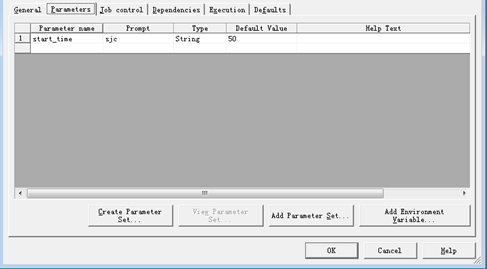
上面的方案主要解决存入数据并将最大时间戳存入到数据库中
现在如何将变量传送进去
2
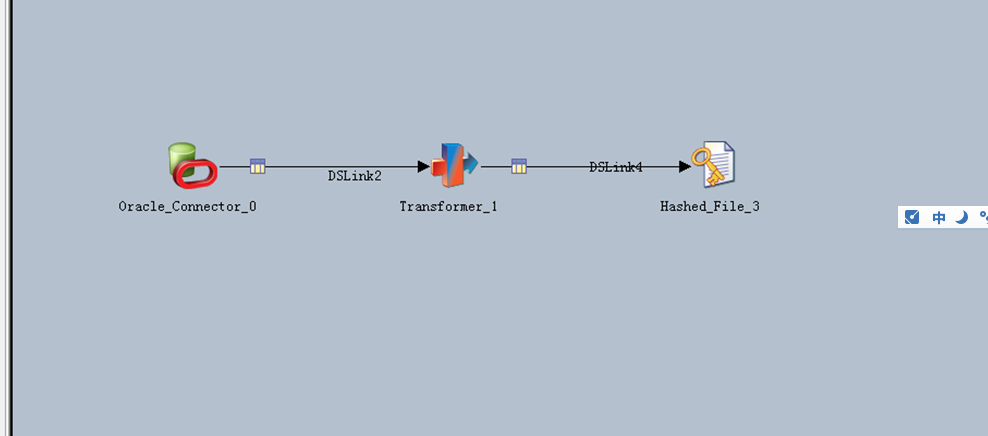
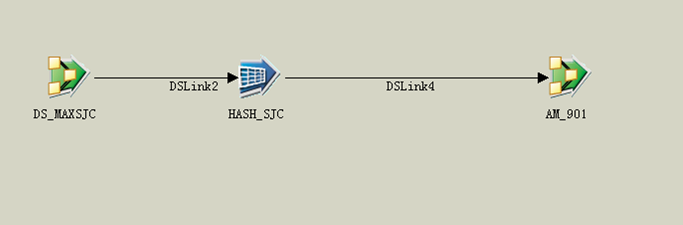
HASH FILE:可以认为是一个txt文件存储关键字和时间戳
A的时间戳值存入到HASH_FILE中
3、
JOB ACTIVITY:类似Oraclejob
从HASH_FILE读取数据并传入1中