1. HBase概述
先来看下HBase在Hadoop生态中的位置
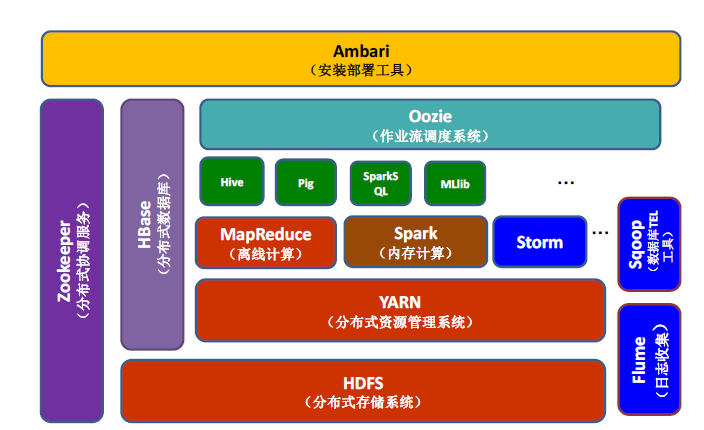
HBase是Apache Hadoop⽣态系统中的重要⼀员,主要⽤于海量结构化数据存储。
HBase是一个构建在HDFS上的分布式列存储系统(严格的来说应该是列族存储),数据保存在HDFS上。
HBase与MapReduce良好的集成,使用MapReduce来处理数据。
HBase利用Zookeeper做分布式协同。
从逻辑上讲,HBase将数据按照表、⾏和列进⾏存储,它是⼀个分布式的、稀疏的、持久化存储的多维度排序表。
相对于Hive来说,HBase适合实时数据访问,Hive则适合批处理数据分析。
HBase的应用场景很多,百度的页面库,淘宝的商品库,小米的云存储服务等。
2. HBase数据模型
(Table, RowKey, Family, Qualifier, TimeStamp) -->Value
在HBase中,一行数据由行健RowKey作为键,包含多个列族(Famliy),列族由可同时访问的多个列组成(Qualifier),
时间戳作为索引(TimeStamp)。

表
--可以是稀疏的,空值在HBase中不会被存储。
Row Key
--行健,数据在表中的唯一标实
--所有的操作都是基于主键的。
--数据安照行健来排序。
特点
--大:⼀个表可以有数⼗亿⾏,上百万列
--⾯向列:⾯向列(族)的存储,列(族)独⽴检索
--稀疏:对于空(null)的列,并不占⽤存储空间,表可以设计的非常稀疏
--数据多版本:每个单元中的数据可以有多个版本(时间戳不同)
--数据类型单⼀:HBase中的数据都是字节,没有类型
3. 物理模型

--以列族为单位存储
--每个cell中会存储以下信息
• Row key
• Column family name
• Column name
• Timestamp
• Value
数据表中所有行,安照Row Key字典序排列,Table在行的方向上分为多个region,


Region按⼤⼩分割的,每个表开始只有⼀个Region,随着数据增多,Region不断增⼤,当增⼤到⼀个阀值的时候,
Region就会等分会两新的Region,之后会有越来越多的Region。Region是HBase中分布式存储和负载均衡的最⼩单元,
不同Region分布到不同RegionServer上。
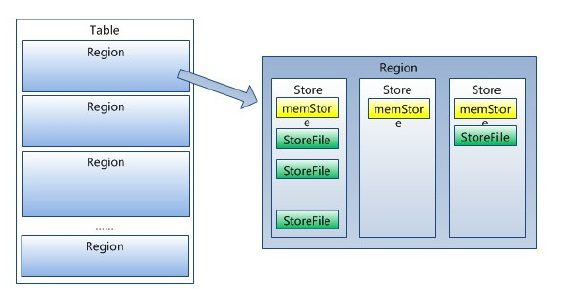
Region虽然是分布式存储的最⼩单元,但并不是存储的最⼩单元。
--Region由⼀个或者多个Store组成,每个Store保存⼀个columns family
--每个Strore又由⼀个MemStore和0至多个StoreFile组成
--MemStore存储在内存中,StoreFile存储在HDFS上
4. HBase架构
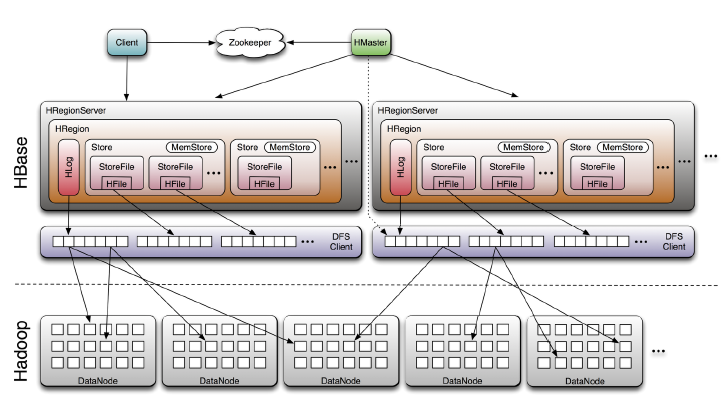
HRegion
--HBase 会⾃动地将表划分为不同的区域
-- 每个区域包含所有⾏的⼀个⼦集
--对⽤户来说,每个表是⼀堆数据的集合,靠主键来区分
--从物理上来说,⼀张表被拆分成了多块,每⼀块是⼀个HRegion
-- 我们⽤表名+ 开始和结束主键,来区分每⼀个HRegion
-- ⼀个HRegion 会保存⼀个表⾥⾯某段连续的数据,从开始主键到结束主键
--⼀张完整的表格是保存在多个HRegion上⾯
HRegionServer
--所有的数据库数据都保存在HDFS上⾯
-- ⽤户通过访问HRegionServer获取这些数据
--⼀台机器上⾯⼀般只运⾏⼀个HRegionServer
-- ⼀个HRegionServer上⾯有多个HRegion,⼀个HRegion 也只会被⼀个HRegionServer维护
--HRegionServer主要负责响应⽤户I/O请求,从HDFS读写数据,是HBase中最核⼼的模块
-- HRegionServer内部管理了⼀系列HRegion对象
-- 每个HRegion对应了Table中的⼀个Region,HRegion中由多个HStore组成
-- 每个HStore 对应了Table中的⼀个Column Family的存储
-- 最好将具备共同IO特性的Column放在⼀个Column Family中
HMaster
--每个HRegionServer都会与HMaster通信
-- HMaster的主要任务就是给HRegionServer分配HRegion
-- HMaster指定HRegionServer 要维护哪些HRegion
-- 当⼀台HRegionServer宕机时,HMaster会把它负责的HRegion标记为未分配,然后再把它们分配到其他HRegionServer 中
5. HBase Shell
启动HBase shell
$./bin/hbase shell
建表:表名scores,有两个列族:‘grade’和‘course’
>create 'scores' ,'grade','course'查看HBase中的表
>list查看表结构
>describe 'scores'put: 写⼊数据,格式如下:
>put 't1', 'r1', 'c1', 'value', ts1t1指表名,r1指⾏键(key),c1指列名,value指值,ts1指数据戳,
⼀般都省略不设置。
向scores表中插⼊数据
> put 'scores', 'Tom', 'grade', 6
> put 'scores', 'Tom', 'course:math', 89
> put 'scores', 'Tom', 'course:art', 63
> put 'scores', 'Jim', 'grade', 7
> put 'scores', 'Jim', 'course:math', 75
> put 'scores', 'Jim', 'course:science', 48get随机查找数据
格式
>get 't1', 'r1'
>get 't1', 'r1', 'c1'
>get 't1', 'r1', 'c1', 'c2'
>get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => ts1}
>get 't1', 'r1', {COLUMN => 'c1', TIMERANGE => [ts1, ts2],
VERSIONS => 4}
>get 'sources', 'Tom'
>get 'sources', 'Tom', 'grade'
>get 'sources', 'Tom', 'grede' , 'course'scan 范围查找数据,scan命令格式如下
>scan 't1'
>scan 't1', {COLUMNS => 'c1:q1'}
>scan 't1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW
=> 'xyz'}
>scan 't1', {REVERSED => true}
> scan 'scores'
> scan 'scores',{COLUMNS =>'course:math'}
> scan 'scores',{COLUMNS =>'course'}
> scan 'scores',{COLUMNS =>'course', LIMIT => 1, STARTROW => 'Jim'}delete删除数据
delete命令格式如下
>delete 't1', 'r1', 'c1', ts1
> delete 'scores', 'Jim', 'course:math'Truncate删除全表数据
> truncate 'scores'alter修改表结构
为scores表增加⼀个family列族,名为profile
> alter 'scores', NAME => 'profile'删除profile列族
> alter 'scores', NAME => 'profile', METHOD => 'delete'删除表
> drop 'scores'上述所写如有不对之处,还请各位前辈指出赐教。--五维空间
