前言
LTP语言云平台
不支持离线调用;
支持分词、词性标注、命名实体识别、依存句法分析、语义角色标注;
不支持自定义词表,但是你可以先用其他支持自定义分词的工具(例如中科院的NLPIR)把文本进行分词,再让ltp帮你标注
支持C#、Go、Java、JavaScript、Nodejs、PHP、Python、R、Ruby等语言调用;
还有一些错误响应、频率限制、重要说明(这几个我至今也没用到);
正文
官方网址:http://www.ltp-cloud.com/
使用文档:http://www.ltp-cloud.com/document/
在线演示:http://www.ltp-cloud.com/demo/
各种语言调用实例可以到Github上下载:https://github.com/HIT-SCIR/ltp-cloud-api-tutorial
例如Python版本的:https://github.com/HIT-SCIR/ltp-cloud-api-tutorial/tree/master/Python
Step1:注册
在这个网址申请一个API key,稍后会用到;
Step2:一个简单的例子(Python版)
(1)复制代码:从Github上复制一段代码(取决于你使用的语言和所需的功能)
(2)修改代码:
<1>把 api_key = "YourApiKey" 中的 "YourApiKey" 修改成你Step1申请的API Key;
<2>把 text = "我爱北京天安门" 修改成你要处理的文本;
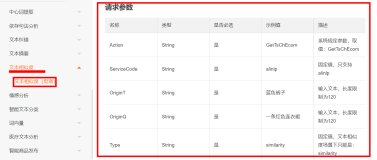
<3>根据需求设置不同的参数(其实只需要api_key,text,pattern,format四个参数就够了,仔细看下pattern):


# -*- coding: utf-8 -*- #!/usr/bin/env python # This example shows how to use Python to access the LTP API to perform full # stack Chinese text analysis including word segmentation, POS tagging, dep- # endency parsing, name entity recognization and semantic role labeling and # get the result in specified format. import urllib2, urllib import sys if __name__ == '__main__': if len(sys.argv) < 2 or sys.argv[1] not in ["xml", "json", "conll"]: print >> sys.stderr, "usage: %s [xml/json/conll]" % sys.argv[0] sys.exit(1) uri_base = "http://ltpapi.voicecloud.cn/analysis/?" api_key = "YourApiKey" text = "我爱北京天安门" # Note that if your text contain special characters such as linefeed or '&', # you need to use urlencode to encode your data text = urllib.quote(text) format = sys.argv[1] pattern = "all" url = (uri_base + "api_key=" + api_key + "&" + "text=" + text + "&" + "format=" + format + "&" + "pattern=" + "all") try: response = urllib2.urlopen(url) content = response.read().strip() print content except urllib2.HTTPError, e: print >> sys.stderr, e.reason
Step3:运行
如果要批量处理txt或者xml文件,需要自己写一段批量处理的代码,下边是我之前项目中用到的一段批量处理某一目录下txt文件代码(就是加了一层循环和设置了一个输出):
1 # -*- coding: utf-8 -*- 2 #!/usr/bin/env python 3 4 # This example shows how to use Python to access the LTP API to perform full 5 # stack Chinese text analysis including word segmentation, POS tagging, dep- 6 # endency parsing, name entity recognization and semantic role labeling and 7 # get the result in specified format. 8 9 import urllib2, urllib 10 import sys 11 12 if __name__ == '__main__': 13 uri_base = "http://ltpapi.voicecloud.cn/analysis/?" 14 api_key = "7132G4z1HE3S********DSxtNcmA1jScSE5XumAI" 15 16 f = open("E:\\PyProj\\Others\\rite_sentence.txt") 17 fw = open("E:\\PyProj\\Others\\rite_pos.txt",'w') 18 19 line = f.readline() 20 while(line): 21 text = line 22 # Note that if your text contain special characters such as linefeed or '&', 23 # you need to use urlencode to encode your data 24 text = urllib.quote(text) 25 format = "plain" 26 pattern = "pos" 27 28 url = (uri_base 29 + "api_key=" + api_key + "&" 30 + "text=" + text + "&" 31 + "format=" + format + "&" 32 + "pattern=" + pattern) 33 34 try: 35 response = urllib2.urlopen(url) 36 content = response.read().strip() 37 print content 38 fw.write(line+content+'\n') 39 except urllib2.HTTPError, e: 40 print >> sys.stderr, e.reason 41 line = f.readline() 42 fw.close() 43 f.close()
'
本文转自ZH奶酪博客园博客,原文链接:http://www.cnblogs.com/CheeseZH/p/4585176.html,如需转载请自行联系原作者