找出相同单词的所有单词。现在,是拿取部分数据集(如下)来完成本项目。
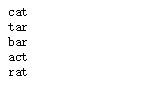
项目需求
一本英文书籍包含成千上万个单词或者短语,现在我们需要在大量的单词中,找出相同字母组成的所有anagrams(字谜)。
思路分析
基于以上需求,我们通过以下几步完成:
1、在 Map 阶段,对每个word(单词)按字母进行排序生成sortedWord,然后输出key/value键值对(sortedWord,word)。
2、在 Reduce 阶段,统计出每组相同字母组成的所有anagrams(字谜)。
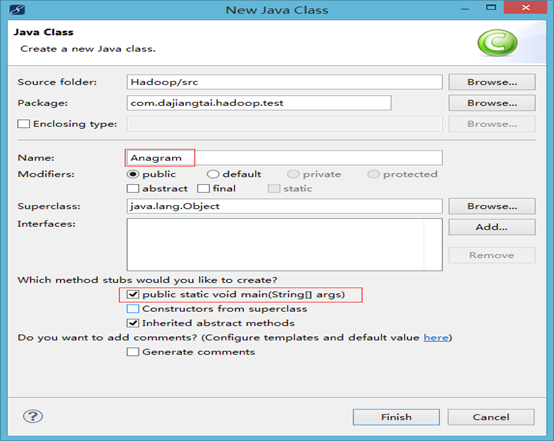
1 、首先,打开MyEclipse,
在com.dajiangtai.hadoop.test包下,新建Anagram类。添加main方法。
2 、在如下文件夹下,新建anagram文件夹
3、 上传数据源anagram.txt
在anagram文件夹的位置,右键,upload fles to DFS,


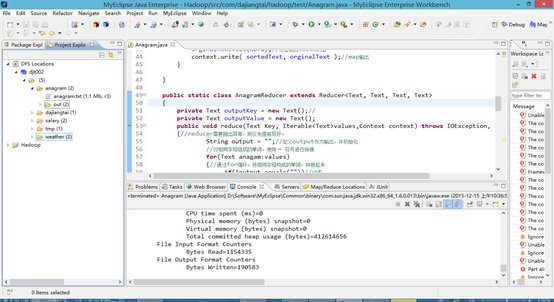
4 、编写Anagram.java里的代码。
见如下的*************Anagram.java******************
代码编写完成后,然后就可以进行Run as -> 1 java application 。
刷新后,如下。
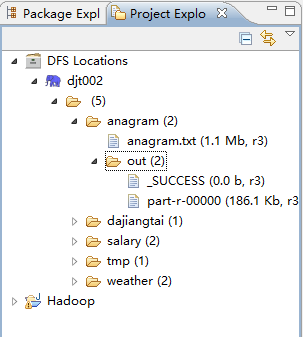
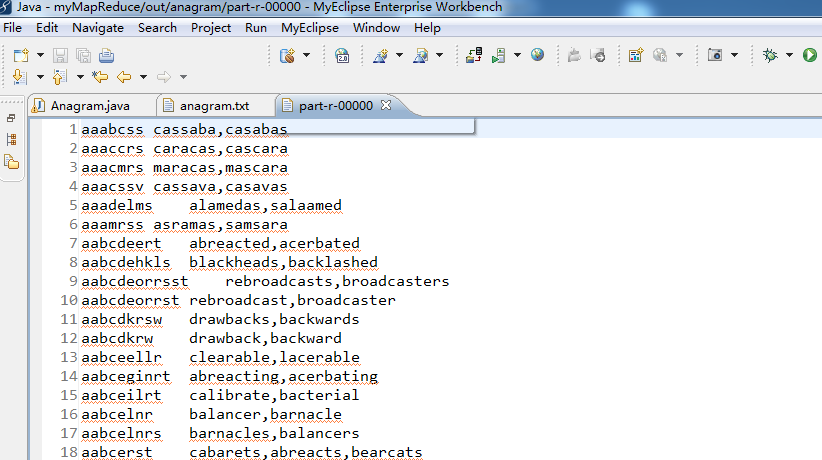
5 、接下来,点击part-r-00000(186.1 kb,r3),则出现。
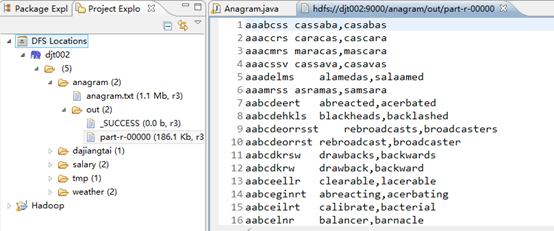
那么,此刻,在本地上已经成功运行。
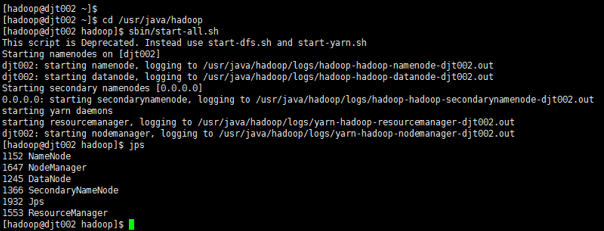
6 、现在,需要到集群上去成功运行,这该怎么做呢?
Hadoop -> Export -> Export,
Java -> JAR file -> next
7 、因为,在hadoop里,这些依赖的架包是存在的,所以我们就不需要再多此一举再打包了。
为架包取一个名称,为anagram.jar,先在D盘新建文件夹JAR,存放在D:\JAR\anagram.jar,点击finish。

8、 接下来,用xshell来连接CentOS。

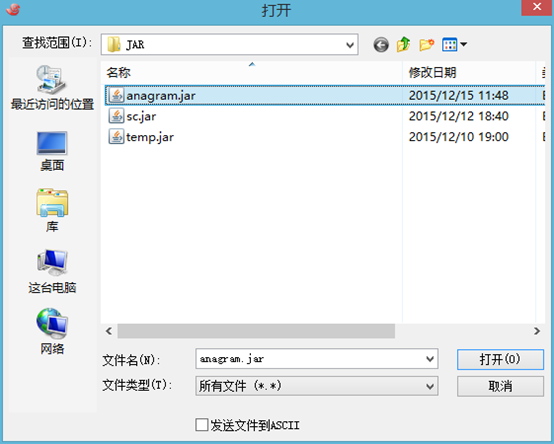
9 、rz,打开D:\JAR\anagram.jar ,上传至CentOS

10、执行命令
hadoop jar anagram.jar com.dajiangtai.hadoop.test.Anagram /anagram/ /anagram/out/


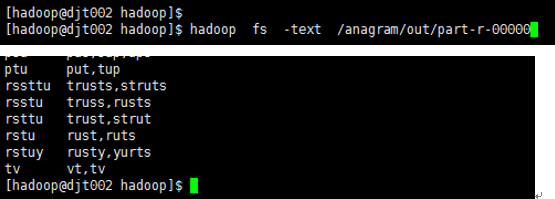
11、 查看结果
hadoop fs -text /anagram/out/part-r-00000
***********************************anagram.txt************************************

a
aah
aahed
aahing
aahs
aardvark
aardvarks
aardwolf
ab
abaci
aback
bents
bentwood
bentwoods
benumb
citers
cites
cithara
cithern
citherns
cithers
citicorp
dovecote
dovecotes
dovecots
dover
doves
exaggerator
exaggerators
exalt
exaltation
exaltations
flavonoid
flavonol
flavonols
glooming
gloomings
glooms
highth
highths
highting
hights
highway
indochina
indochinese
indoctrinate
indoctrinated
indoctrinates
indoctrinating
jackals
jackanapes
jackanapeses
kafir
kafirs
kafka
leucocyte
leucoma
leukaemia
leukaemic
mammal
mammalia
mammalian
mammalians
mammals
nims
nincompoop
nincompoops
nine
ninefold
ninepin
ninepins
onions
onionskin
onionskins
onlooker
onlookers
past
pasta
pastas
paste
pasteboard
queasily
queasiness
queasy
queaziest
queazy
quebec
reddening
reddens
redder
reddest
reddish
scared
scarer
scarers
scares
tetrasaccharide
tetravalent
tetryl
teuton
urethral
urethras
uretic
vocalizing
vocally
vocals
wheedling
wheel
wheelbarrow
wheelbarrows
wheelbase
xerophyte
xerosis
xerox
yammerers
yammering
yammers
yams
yamun
zymolysis
zymoplastic
zymoscope
zymurgy
Anagram.java代码版本1
1 package com.dajiangtai.hadoop.test; 2 3 import java.io.IOException; 4 import java.util.Arrays; 5 import java.util.StringTokenizer; 6 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Mapper; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import org.apache.hadoop.conf.Configuration; 12 import org.apache.hadoop.conf.Configured; 13 import org.apache.hadoop.fs.FileSystem; 14 import org.apache.hadoop.fs.Path; 15 //import org.apache.hadoop.io.Text; 16 import org.apache.hadoop.mapreduce.Job; 17 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 18 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 19 import org.apache.hadoop.util.Tool; 20 import org.apache.hadoop.util.ToolRunner; 21 /** 22 * @统计相同字母组成的单词 23 * 1、编写map()函数 24 * 2、编写reduce()函数 25 * 3、编写run()函数 26 * 4、编写main() 27 */ 28 29 public class Anagram extends Configured implements Tool 30 { 31 public static class AnagramMapper extends Mapper<LongWritable, Text, Text, Text> 32 { 33 private Text sortedText = new Text();//存放排序好了的单词 34 private Text orginalText = new Text();//存放原始单词本身 35 36 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException 37 { //因为map输出需要抛出异常,所以提前先写好 38 String word = value.toString();//将value转化为String类型 39 char[] wordChars = word.toCharArray();//单词word转化为字符数组 40 Arrays.sort(wordChars);//对字符数组按字母升序排序 41 String sortedWord = new String(wordChars);//字符数组转化为字符串 42 sortedText.set(sortedWord);//设置输出key的值 43 orginalText.set(word);//设置输出value的值 44 context.write( sortedText, orginalText );//map输出 45 } 46 47 } 48 49 public static class AnagramReducer extends Reducer<Text, Text, Text, Text> 50 { 51 private Text outputKey = new Text();// 52 private Text outputValue = new Text(); 53 public void reduce(Text Key, Iterable<Text>values,Context context) throws IOException, InterruptedException 54 {//reducer需要抛出异常,所以先提前写好。 55 String output = "";//定义output作为输出,并初始化 56 //对相同字母组成的单词,使用 ~ 符号进行拼接 57 for(Text anagam:values) 58 {//通过for循环,将相同字母构成的单词,拼接起来 59 if(!output.equals(""))//过滤 60 { 61 output = output + "~" ;//用~来连接 62 } 63 output = output + anagam.toString();//进行累加 64 } 65 StringTokenizer outputTokenizer = new StringTokenizer(output,"~" ); 66 //通过 StringTokenizer来解析拼接的单词 67 //输出anagrams(字谜)大于2的结果 68 if(outputTokenizer.countTokens()>=2) 69 { 70 output = output.replace( "~", ",");//将~替换成, 71 outputKey.set(Key.toString());//设置key的值 72 outputValue.set(output);//设置value的值 73 context.write( outputKey, outputValue);//reduce输出 74 } 75 } 76 77 } 78 public int run(String[] arg0) throws Exception 79 { 80 //1 81 Configuration conf = new Configuration(); 82 83 //2删除已经存在的输出目录 84 Path mypath = new Path(arg0[1]);//下标为1,即是输出路径 85 FileSystem hdfs = mypath.getFileSystem(conf);//获取文件系统 86 if (hdfs.isDirectory(mypath)) 87 {//如果文件系统中存在这个输出路径,则删除掉 88 hdfs.delete(mypath, true); 89 } 90 Job job = new Job(conf, "anagram");//构建一个job对象,取名为testAnagram 91 job.setJarByClass(Anagram.class);//设置主类 92 93 job.setMapperClass(AnagramMapper.class); //Mapper 94 job.setReducerClass(AnagramReducer.class); //Reducer 95 96 job.setOutputKeyClass(Text. class); 97 job.setOutputValueClass(Text. class); 98 99 100 FileInputFormat.addInputPath(job, new Path(arg0[0]));// 文件输入路径 101 FileOutputFormat.setOutputPath(job, new Path(arg0[1]));// 文件输出路径 102 job.waitForCompletion(true); 103 104 return 0; 105 106 } 107 108 public static void main(String[] args) throws Exception 109 {//定义数组来保存输入路径和输出路径 110 String[] args0 = { "hdfs://djt002:9000/anagram", 111 "hdfs://djt002:9000/anagram/out"}; 112 int ec = ToolRunner.run( new Configuration(), new Anagram(), args0); 113 System. exit(ec); 114 } 115 116 117 } 118 119
Anagram.java代码版本2


Anagram.java代码版本2
1 package zhouls.bigdata.myMapReduce.Anagram; 2 3 import java.io.IOException; 4 import java.util.Arrays; 5 import java.util.StringTokenizer; 6 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Mapper; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import org.apache.hadoop.conf.Configuration; 12 import org.apache.hadoop.conf.Configured; 13 import org.apache.hadoop.fs.FileSystem; 14 import org.apache.hadoop.fs.Path; 15 //import org.apache.hadoop.io.Text; 16 import org.apache.hadoop.mapreduce.Job; 17 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 18 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 19 import org.apache.hadoop.util.Tool; 20 import org.apache.hadoop.util.ToolRunner; 21 /** 22 * @统计相同字母组成的单词 23 * 1、编写map()函数 24 * 2、编写reduce()函数 25 * 3、编写run()函数 26 * 4、编写main() 27 */ 28 29 public class Anagram extends Configured implements Tool 30 { 31 public static class AnagramMapper extends Mapper<LongWritable, Text, Text, Text> 32 { 33 private Text sortedText = new Text();//存放排序好了的单词 34 private Text orginalText = new Text();//存放原始单词本身 35 36 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException 37 { //因为map输出需要抛出异常,所以提前先写好 38 String word = value.toString();//将value转化为String类型 39 char[] wordChars = word.toCharArray();//单词word转化为字符数组 40 Arrays.sort(wordChars);//对字符数组按字母升序排序 41 String sortedWord = new String(wordChars);//字符数组转化为字符串 42 sortedText.set(sortedWord);//设置输出key的值 43 orginalText.set(word);//设置输出value的值 44 context.write( sortedText, orginalText );//map输出 45 } 46 47 } 48 49 public static class AnagramReducer extends Reducer<Text, Text, Text, Text> 50 { 51 private Text outputKey = new Text();// 52 private Text outputValue = new Text(); 53 public void reduce(Text Key, Iterable<Text>values,Context context) throws IOException, InterruptedException 54 {//reducer需要抛出异常,所以先提前写好。 55 String output = "";//定义output作为输出,并初始化 56 //对相同字母组成的单词,使用 ~ 符号进行拼接 57 for(Text anagam:values) 58 {//通过for循环,将相同字母构成的单词,拼接起来 59 if(!output.equals(""))//过滤 60 { 61 output = output + "~" ;//用~来连接 62 } 63 output = output + anagam.toString();//进行累加 64 } 65 StringTokenizer outputTokenizer = new StringTokenizer(output,"~" ); 66 //通过 StringTokenizer来解析拼接的单词 67 //输出anagrams(字谜)大于2的结果 68 if(outputTokenizer.countTokens()>=2) 69 { 70 output = output.replace( "~", ",");//将~替换成, 71 outputKey.set(Key.toString());//设置key的值 72 outputValue.set(output);//设置value的值 73 context.write( outputKey, outputValue);//reduce输出 74 } 75 } 76 77 } 78 public int run(String[] arg0) throws Exception { 79 80 //1 81 Configuration conf = new Configuration(); 82 83 //2删除已经存在的输出目录 84 Path mypath = new Path(arg0[1]);//下标为1,即是输出路径 85 FileSystem hdfs = mypath.getFileSystem(conf);//获取文件系统 86 if (hdfs.isDirectory(mypath)) 87 {//如果文件系统中存在这个输出路径,则删除掉 88 hdfs.delete(mypath, true); 89 } 90 Job job = new Job(conf, "anagram");//构建一个job对象,取名为testAnagram 91 job.setJarByClass(Anagram.class);//设置主类 92 93 job.setMapperClass(AnagramMapper.class); //Mapper 94 job.setReducerClass(AnagramReducer.class); //Reducer 95 96 job.setOutputKeyClass(Text. class); 97 job.setOutputValueClass(Text. class); 98 99 100 FileInputFormat.addInputPath(job, new Path(arg0[0]));// 文件输入路径 101 FileOutputFormat.setOutputPath(job, new Path(arg0[1]));// 文件输出路径 102 job.waitForCompletion(true); 103 104 return 0; 105 106 } 107 108 public static void main(String[] args) throws Exception 109 {//定义数组来保存输入路径和输出路径 110 //集群路径 111 // String[] args0 = { "hdfs://HadoopMaster:9000/anagram.txt", 112 // "hdfs://HadoopMaster:9000/out/anagram/"}; 113 114 //本地路径 115 String[] args0 = { "./data/anagram.txt", 116 "out/anagram/"}; 117 118 int ec = ToolRunner.run( new Configuration(), new Anagram(), args0); 119 System. exit(ec); 120 } 121 122 123 }
Anagram.java代码版本3

1 // 2 //package zhouls.bigdata.myMapReduce.Anagram; 3 // 4 //import java.io.IOException; 5 //import java.util.Arrays; 6 //import java.util.StringTokenizer; 7 // 8 //import org.apache.hadoop.io.LongWritable; 9 //import org.apache.hadoop.io.Text; 10 //import org.apache.hadoop.mapreduce.Mapper; 11 //import org.apache.hadoop.mapreduce.Reducer; 12 //import org.apache.hadoop.conf.Configuration; 13 //import org.apache.hadoop.conf.Configured; 14 //import org.apache.hadoop.fs.FileSystem; 15 //import org.apache.hadoop.fs.Path; 16 ////import org.apache.hadoop.io.Text; 17 //import org.apache.hadoop.mapreduce.Job; 18 //import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 19 //import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 20 //import org.apache.hadoop.util.Tool; 21 //import org.apache.hadoop.util.ToolRunner; 22 ///** 23 // * @统计相同字母组成的单词 24 // * 1、编写map()函数 25 // * 2、编写reduce()函数 26 // * 3、编写run()函数 27 // * 4、编写main() 28 // */ 29 // 30 //public class Anagram extends Configured implements Tool 31 //{ 32 // public static class AnagramMapper extends Mapper<LongWritable, Text, Text, Text> 33 // { 34 // private Text sortedText = new Text();//存放排序好了的单词 35 // private Text orginalText = new Text();//存放原始单词本身 36 // 37 // public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException 38 // { //因为map输出需要抛出异常,所以提前先写好 39 // String word = value.toString();//将value转化为String类型 40 // char[] wordChars = word.toCharArray();//单词word转化为字符数组 41 // Arrays.sort(wordChars);//对字符数组按字母升序排序 42 // String sortedWord = new String(wordChars);//字符数组转化为字符串 43 // sortedText.set(sortedWord);//设置输出key的值 44 // orginalText.set(word);//设置输出value的值 45 // context.write( sortedText, orginalText );//map输出 46 // } 47 // 48 // } 49 // 50 // public static class AnagramReducer extends Reducer<Text, Text, Text, Text> 51 // { 52 // private Text outputKey = new Text();// 53 // private Text outputValue = new Text(); 54 // public void reduce(Text Key, Iterable<Text>values,Context context) throws IOException, InterruptedException 55 // {//reducer需要抛出异常,所以先提前写好。 56 // String output = "";//定义output作为输出,并初始化 57 // //对相同字母组成的单词,使用 ~ 符号进行拼接 58 // for(Text anagam:values) 59 // {//通过for循环,将相同字母构成的单词,拼接起来 60 // if(!output.equals(""))//过滤 61 // { 62 // output = output + "~" ;//用~来连接 63 // } 64 // output = output + anagam.toString();//进行累加 65 // } 66 // StringTokenizer outputTokenizer = new StringTokenizer(output,"~" ); 67 // //通过 StringTokenizer来解析拼接的单词 68 // //输出anagrams(字谜)大于2的结果 69 // if(outputTokenizer.countTokens()>=2) 70 // { 71 // output = output.replace( "~", ",");//将~替换成, 72 // outputKey.set(Key.toString());//设置key的值 73 // outputValue.set(output);//设置value的值 74 // context.write( outputKey, outputValue);//reduce输出 75 // } 76 // } 77 // 78 //} 79 // public int run(String[] arg0) throws Exception { 80 // 81 // //1 82 // Configuration conf = new Configuration(); 83 // 84 // //2删除已经存在的输出目录 85 // Path mypath = new Path(arg0[1]);//下标为1,即是输出路径 86 // FileSystem hdfs = mypath.getFileSystem(conf);//获取文件系统 87 // if (hdfs.isDirectory(mypath)) 88 // {//如果文件系统中存在这个输出路径,则删除掉 89 // hdfs.delete(mypath, true); 90 // } 91 // Job job = new Job(conf, "anagram");//构建一个job对象,取名为testAnagram 92 // job.setJarByClass(Anagram.class);//设置主类 93 // 94 // job.setMapperClass(AnagramMapper.class); //Mapper 95 // job.setReducerClass(AnagramReducer.class); //Reducer 96 // 97 // job.setOutputKeyClass(Text. class); 98 // job.setOutputValueClass(Text. class); 99 // 100 // 101 // FileInputFormat.addInputPath(job, new Path(arg0[0]));// 文件输入路径 102 // FileOutputFormat.setOutputPath(job, new Path(arg0[1]));// 文件输出路径 103 // job.waitForCompletion(true); 104 // 105 // return 0; 106 // 107 // } 108 // 109 // public static void main(String[] args) throws Exception 110 // {//定义数组来保存输入路径和输出路径 111 ////集群路径 112 //// String[] args0 = { "hdfs://HadoopMaster:9000/anagram.txt", 113 //// "hdfs://HadoopMaster:9000/out/anagram/"}; 114 // 115 ////本地路径 116 // String[] args0 = { "./data/anagram.txt", 117 // "out/anagram/"}; 118 // 119 // int ec = ToolRunner.run( new Configuration(), new Anagram(), args0); 120 // System. exit(ec); 121 // } 122 // 123 // 124 //} 125 126 127 128 129 130 131 132 133 134 135 136 package zhouls.bigdata.myMapReduce.Anagram; 137 138 import java.io.IOException; 139 import java.util.Arrays; 140 import java.util.StringTokenizer; 141 142 import org.apache.hadoop.io.LongWritable; 143 import org.apache.hadoop.io.Text; 144 import org.apache.hadoop.mapreduce.Mapper; 145 import org.apache.hadoop.mapreduce.Reducer; 146 import org.apache.hadoop.conf.Configuration; 147 import org.apache.hadoop.conf.Configured; 148 import org.apache.hadoop.fs.FileSystem; 149 import org.apache.hadoop.fs.Path; 150 //import org.apache.hadoop.io.Text; 151 import org.apache.hadoop.mapreduce.Job; 152 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 153 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 154 import org.apache.hadoop.util.Tool; 155 import org.apache.hadoop.util.ToolRunner; 156 /** 157 * @统计相同字母组成的单词 158 * 1、编写map()函数 159 * 2、编写reduce()函数 160 * 3、编写run()函数 161 * 4、编写main() 162 */ 163 164 public class Anagram 165 { 166 public static class AnagramMapper extends Mapper<LongWritable, Text, Text, Text> 167 { 168 private Text sortedText = new Text();//存放排序好了的单词 169 private Text orginalText = new Text();//存放原始单词本身 170 171 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException 172 { //因为map输出需要抛出异常,所以提前先写好 173 String word = value.toString();//将value转化为String类型 174 char[] wordChars = word.toCharArray();//单词word转化为字符数组 175 Arrays.sort(wordChars);//对字符数组按字母升序排序 176 String sortedWord = new String(wordChars);//字符数组转化为字符串 177 sortedText.set(sortedWord);//设置输出key的值 178 orginalText.set(word);//设置输出value的值 179 context.write( sortedText, orginalText );//map输出 180 } 181 182 } 183 184 public static class AnagramReducer extends Reducer<Text, Text, Text, Text> 185 { 186 private Text outputKey = new Text();// 187 private Text outputValue = new Text(); 188 public void reduce(Text Key, Iterable<Text>values,Context context) throws IOException, InterruptedException 189 {//reducer需要抛出异常,所以先提前写好。 190 String output = "";//定义output作为输出,并初始化 191 //对相同字母组成的单词,使用 ~ 符号进行拼接 192 for(Text anagam:values) 193 {//通过for循环,将相同字母构成的单词,拼接起来 194 if(!output.equals(""))//过滤 195 { 196 output = output + "~" ;//用~来连接 197 } 198 output = output + anagam.toString();//进行累加 199 } 200 StringTokenizer outputTokenizer = new StringTokenizer(output,"~" ); 201 //通过 StringTokenizer来解析拼接的单词 202 //输出anagrams(字谜)大于2的结果 203 if(outputTokenizer.countTokens()>=2) 204 { 205 output = output.replace( "~", ",");//将~替换成, 206 outputKey.set(Key.toString());//设置key的值 207 outputValue.set(output);//设置value的值 208 context.write( outputKey, outputValue);//reduce输出 209 } 210 } 211 212 } 213 214 215 public static void main(String[] args) throws Exception{ 216 217 218 //1 219 Configuration conf = new Configuration(); 220 221 222 Job job = new Job(conf, "anagram");//构建一个job对象,取名为testAnagram 223 job.setJarByClass(Anagram.class);//设置主类 224 225 job.setMapperClass(AnagramMapper.class); //Mapper 226 job.setReducerClass(AnagramReducer.class); //Reducer 227 228 job.setOutputKeyClass(Text. class); 229 job.setOutputValueClass(Text. class); 230 231 232 233 // //指定要处理的输入数据存放路径 234 // FileInputFormat.setInputPaths(job, new Path("hdfs://HadoopMaster:9000/anagram.txt/")); 235 // 236 // //指定处理结果的输出数据存放路径 237 // FileOutputFormat.setOutputPath(job, new Path("hdfs://HadoopMaster:9000/out/anagram/")); 238 239 //指定要处理的输入数据存放路径 240 FileInputFormat.setInputPaths(job, new Path("./data/anagram.txt")); 241 242 //指定处理结果的输出数据存放路径 243 FileOutputFormat.setOutputPath(job, new Path("out/anagram/")); 244 245 246 //将job提交给集群运行 247 job.waitForCompletion(true); 248 249 } 250 251 }
代码版本3的写法,可以看看这篇博客
Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
Anagram.java代码版本4
1 package com.dajiangtai.Hadoop.MapReduce; 2 3 import java.io.IOException; 4 import java.util.Arrays; 5 import java.util.StringTokenizer; 6 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Mapper; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import org.apache.hadoop.conf.Configuration; 12 import org.apache.hadoop.conf.Configured; 13 import org.apache.hadoop.fs.FileSystem; 14 import org.apache.hadoop.fs.Path; 15 //import org.apache.hadoop.io.Text; 16 import org.apache.hadoop.mapreduce.Job; 17 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 18 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 19 import org.apache.hadoop.util.Tool; 20 import org.apache.hadoop.util.ToolRunner; 21 22 23 /** 24 * @统计相同字母组成的单词 25 * 1、编写map()函数 26 * 2、编写reduce()函数 27 * 3、编写run()函数 28 * 4、编写main() 29 */ 30 31 public class Anagram extends Configured implements Tool { 32 // 为什么写mapreduce程序时,看不懂使用extends Configured implements Tool的方式,为什么要这样写,不写难道不可以吗? 33 // 答:Tool接口可以支持处理通用的命令行选项,它是所有Map-Reduce程序的都可用的一个标准接口 34 35 36 // public static class AnagramMapper extends Mapper<Object, Text, Text, Text> { 37 // 为什么k1是Object?用LongWritable也可以,Object包括很多具体类型。 38 39 40 public static class AnagramMapper extends Mapper<LongWritable, Text, Text, Text> { 41 // a 42 // aah 43 // aahed 44 45 // a是1,aahed是5,这就是k1,偏移量,所以为LongWritable 46 47 48 //定义两个对象或说变量 49 private Text sortedText = new Text();//存放排序好了的单词map 50 private Text orginalText = new Text();//存放原始单词本身 51 52 // public void map(Object key, Text value, Context context) throws IOException, InterruptedException{ 53 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{ 54 // 刚开始,key是0,value是0 55 56 //因为map输出需要抛出异常,所以提前先写好 57 58 // stomachache 59 // stomachaches 60 // stomached 61 // stomacher 62 63 64 65 //现在有单词如下: 66 // cat 67 // tar 68 // bar 69 // act 70 // rat 71 72 // <abr bar> abr是升序排序好后的字符数组,转化为字符串,作为k2 73 // bar是原单词本身,作为v2 74 75 76 77 String word = value.toString();//将value转化为String类型 78 // value是aardwolf word是"aardwolf" 79 80 char[] wordChars = word.toCharArray();//单词word转化为字符数组 81 // wordChars是[a, a, r, d, w, o, l, f] 82 83 // "aardwolf" 输出 aardwolf 依次放入wordChars字符数组里,并标记下标从0开始 84 85 Arrays.sort(wordChars);//对字符数组按字母升序排序 86 87 String sortedWord = new String(wordChars);//升序排序好后的字符数组,转化为字符串 88 // wordChars是[a, a, d, f, l, o, r, w] 89 // sortedWord是"aadflorw" 90 91 sortedText.set(sortedWord);//设置输出key的值 92 // 将sortedWord的赋给sortedText 93 // sortedWord是"aadflorw",是String类型 94 // sortedText是aadflorw,是Text类型 95 96 orginalText.set(word);//设置输出value的值 97 // 将word的赋给orginalText 98 // word是"aardwolf",是String类型 99 // orginalText是aardwolf,是Text类型 100 101 102 context.write(sortedText,orginalText);//map输出 写入sortedText是k2,orginalText是v2 103 // 即是aadflow,aardwolf 104 105 //现在有单词如下: 106 // cat 107 // tar 108 // bar 109 // act 110 // rat 111 112 // <abr bar> abr是升序排序好后的字符数组,转化为字符串,作为k2,即sortedText 113 // bar是原单词本身,作为v2,即orginalText 114 115 116 117 } 118 } 119 120 121 122 123 124 125 126 127 128 public static class AnagramReducer extends Reducer<Text, Text, Text, Text> { 129 private Text outputKey = new Text();//k3 作为reduce的输出 130 private Text outputValue = new Text();//v3 131 132 public void reduce(Text anagramKey, Iterable<Text> anagramValues,Context context) throws IOException, InterruptedException{ 133 134 // Iterable<Text> values和Text values这样有什么区别? 135 // 前者是iterable(迭代器)变量,后者是Text(utf-8格式的文本的封装)变量 136 137 // 为什么断点出来之后,是这样的,因为啊,输出文件hdfs:djt002:9000/outData/anagram/part-00000的第一行就是如下啊 138 // aaabcss cassaba,casabas 139 140 // 是这个单词,aaabcss, 141 // 然后,字典里,有cassaba和cassaba 142 // 匹配到,即这aaabcss、cassaba和casabas。这三个其实都是字典里的 143 144 //reducer需要抛出异常,所以先提前写好。 145 String output = "";//定义output作为输出,并初始化 146 // output是"cassaba,casabas" 147 148 149 //其实啊,由后面可以看出,output就是outputValue。anagramKey.toString()就是outputKey 150 151 //对相同字母组成的单词,使用 ~ 符号进行拼接 152 for(Text anagam:anagramValues){//星型for循环来循环values,即将values的值一一传给Text anagam 153 // values是Iterable<Text> values 154 // Text anagam 155 156 //通过for循环,将相同字母构成的单词,拼接起来 157 if(!output.equals("")){//过滤 158 // output是"cassaba,casabas" 159 160 output = output + "-" ;//用~来连接组成单词 161 // 右边的output是"cassaba,casabas" 162 // 左边的output是"cassaba,casabas" 163 164 } 165 output = output + anagam.toString();//进行累加 166 // 右边的output是"cassaba,casabas" 167 // 左边的output是"cassaba,casabas" 168 169 } 170 171 172 StringTokenizer outputTokenizer = new StringTokenizer(output,"-"); 173 ////StringTokenizer是字符串分隔解析类型,StringTokenizer 用来分割字符串,你可以指定分隔符,比如',',或者空格之类的字符。 174 //通过 StringTokenizer来解析用~来拼接的单词 175 // 右边的output是"cassaba,casabas" 176 177 178 //输出anagrams(字谜)大于2的结果,因为是找不同单词,至少是2个 179 if(outputTokenizer.countTokens()>=2){//java.util.StringTokenizer.countTokens() 180 //countTokens() 方法是用于计算此标记生成的nextToken方法之前的数量,可以通过调用产生一个异常。 181 182 output = output.replace( "-", ",");//将~替换成, 183 // 比如是 cassaba-casabas 变成 cassaba,casabas 184 185 // 右边的output是"cassaba,casabas" 186 // 左边的output是"cassaba,casabas" 187 188 189 outputKey.set(anagramKey.toString());//设置key的值 190 // 将Key.toString()设值给outputKey 191 // Key是aaabcss,是Text类型 192 // outputKey是aaabcss,是Text类型 193 194 outputValue.set(output);//设置value的值 195 // 将output设值给outputValue 196 // output是cassaba,casabas 197 // outputValue是cassaba,casabas 198 199 200 context.write( outputKey, outputValue);//reduce输出 201 // outputKey是aaabcss 202 // outputValue是cassaba,casabas 203 204 } 205 } 206 207 } 208 209 210 public int run(String[] arg0) throws Exception { 211 //1 212 Configuration conf = new Configuration(); 213 214 //2删除已经存在的输出目录 215 Path mypath = new Path(arg0[1]);//下标为1,即是输出路径 216 FileSystem hdfs = mypath.getFileSystem(conf);//获取文件系统 217 if (hdfs.isDirectory(mypath)) 218 {//如果文件系统中存在这个输出路径,则删除掉 219 hdfs.delete(mypath, true); 220 } 221 Job job = new Job(conf, "anagram");//构建一个job对象,取名为Anagram 222 job.setJarByClass(Anagram.class);//设置主类 223 224 job.setMapperClass(AnagramMapper.class); //Mapper 225 job.setReducerClass(AnagramReducer.class); //Reducer 226 227 job.setOutputKeyClass(Text. class); 228 job.setOutputValueClass(Text. class); 229 230 231 FileInputFormat.addInputPath(job, new Path(arg0[0]));// 文件输入路径 232 FileOutputFormat.setOutputPath(job, new Path(arg0[1]));// 文件输出路径 233 job.waitForCompletion(true); 234 235 return 0; 236 237 } 238 239 240 241 public static void main(String[] args) throws Exception{ 242 //定义数组来保存输入路径和输出路径 243 //集群路径 244 String[] args0 = { "hdfs://djt002:9000/inputData/anagram/anagram.txt", 245 "hdfs://djt002:9000/outData/anagram/"}; 246 247 ////本地路径 248 // String[] args0 = { "./data/anagram/anagram.txt", 249 // "./out/anagram/"}; 250 251 int ec = ToolRunner.run( new Configuration(), new Anagram(), args0); 252 // ToolRunner要处理的Configuration,Tool通过ToolRunner调用ToolRunner.run时,传入参数Configuration 253 254 255 System. exit(ec); 256 } 257 } 258 259 260 261 262 263 264 265 266 267 268 269 //写法版本2 270 //package zhouls.bigdata.myMapReduce.Anagram; 271 // 272 //import java.io.IOException; 273 //import java.util.Arrays; 274 //import java.util.StringTokenizer; 275 // 276 //import org.apache.hadoop.io.LongWritable; 277 //import org.apache.hadoop.io.Text; 278 //import org.apache.hadoop.mapreduce.Mapper; 279 //import org.apache.hadoop.mapreduce.Reducer; 280 //import org.apache.hadoop.conf.Configuration; 281 //import org.apache.hadoop.conf.Configured; 282 //import org.apache.hadoop.fs.FileSystem; 283 //import org.apache.hadoop.fs.Path; 284 ////import org.apache.hadoop.io.Text; 285 //import org.apache.hadoop.mapreduce.Job; 286 //import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 287 //import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 288 //import org.apache.hadoop.util.Tool; 289 //import org.apache.hadoop.util.ToolRunner; 290 ///** 291 // * @统计相同字母组成的单词 292 // * 1、编写map()函数 293 // * 2、编写reduce()函数 294 // * 3、编写run()函数 295 // * 4、编写main() 296 // */ 297 // 298 //public class Anagram 299 //{ 300 // public static class AnagramMapper extends Mapper<LongWritable, Text, Text, Text> 301 // { 302 // private Text sortedText = new Text();//存放排序好了的单词 303 // private Text orginalText = new Text();//存放原始单词本身 304 // 305 // public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException 306 // { //因为map输出需要抛出异常,所以提前先写好 307 // String word = value.toString();//将value转化为String类型 308 // char[] wordChars = word.toCharArray();//单词word转化为字符数组 309 // Arrays.sort(wordChars);//对字符数组按字母升序排序 310 // String sortedWord = new String(wordChars);//字符数组转化为字符串 311 // sortedText.set(sortedWord);//设置输出key的值 312 // orginalText.set(word);//设置输出value的值 313 // context.write( sortedText, orginalText );//map输出 314 // } 315 // 316 // } 317 // 318 // public static class AnagramReducer extends Reducer<Text, Text, Text, Text> 319 // { 320 // private Text outputKey = new Text();// 321 // private Text outputValue = new Text(); 322 // public void reduce(Text Key, Iterable<Text>values,Context context) throws IOException, InterruptedException 323 // {//reducer需要抛出异常,所以先提前写好。 324 // String output = "";//定义output作为输出,并初始化 325 // //对相同字母组成的单词,使用 ~ 符号进行拼接 326 // for(Text anagam:values) 327 // {//通过for循环,将相同字母构成的单词,拼接起来 328 // if(!output.equals(""))//过滤 329 // { 330 // output = output + "~" ;//用~来连接 331 // } 332 // output = output + anagam.toString();//进行累加 333 // } 334 // StringTokenizer outputTokenizer = new StringTokenizer(output,"~" ); 335 // //通过 StringTokenizer来解析拼接的单词 336 // //输出anagrams(字谜)大于2的结果 337 // if(outputTokenizer.countTokens()>=2) 338 // { 339 // output = output.replace( "~", ",");//将~替换成, 340 // outputKey.set(Key.toString());//设置key的值 341 // outputValue.set(output);//设置value的值 342 // context.write( outputKey, outputValue);//reduce输出 343 // } 344 // } 345 // 346 //} 347 // 348 // 349 // public static void main(String[] args) throws Exception{ 350 // 351 // 352 // //1 353 // Configuration conf = new Configuration(); 354 // 355 // 356 // Job job = new Job(conf, "anagram");//构建一个job对象,取名为testAnagram 357 // job.setJarByClass(Anagram.class);//设置主类 358 // 359 // job.setMapperClass(AnagramMapper.class); //Mapper 360 // job.setReducerClass(AnagramReducer.class); //Reducer 361 // 362 // job.setOutputKeyClass(Text. class); 363 // job.setOutputValueClass(Text. class); 364 // 365 // 366 // 367 // 368 // 369 //// //指定要处理的输入数据存放路径 370 //// FileInputFormat.setInputPaths(job, new Path("hdfs://djt002:9000/inputData/anagram.txt/")); 371 // // 372 //// //指定处理结果的输出数据存放路径 373 //// FileOutputFormat.setOutputPath(job, new Path("hdfs://djt002:9000/outData/anagram/")); 374 // 375 // //指定要处理的输入数据存放路径 376 // FileInputFormat.setInputPaths(job, new Path("./data/anagram.txt")); 377 // 378 // //指定处理结果的输出数据存放路径 379 // FileOutputFormat.setOutputPath(job, new Path("out/anagram/")); 380 // 381 // 382 // //将job提交给集群运行 383 // job.waitForCompletion(true); 384 // 385 // } 386 // 387 // 388 // 389 // 390 // 391 // 392 // 393 //}
最清晰的版本(博主推荐)
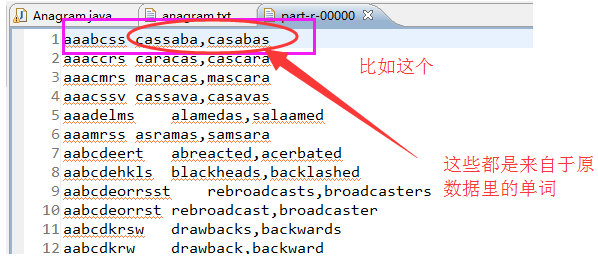
以下是原始数据里的单词cassaba
package com.dajiangtai.hadoop.test; import java.io.IOException; import java.util.Arrays; import java.util.StringTokenizer; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; //import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * @统计相同字母组成的单词 * 1、编写map()函数 * 2、编写reduce()函数 * 3、编写run()函数 * 4、编写main() */ public class Anagram extends Configured implements Tool { public static class AnagramMapper extends Mapper<LongWritable, Text, Text, Text> { private Text sortedText = new Text();//存放排序好了的单词 private Text orginalText = new Text();//存放原始单词本身 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //因为map输出需要抛出异常,所以提前先写好 String word = value.toString();//将value转化为String类型 //比如value是cassaba //经过value.toString()下来,得到word是"cassaba" char[] wordChars = word.toCharArray();//单词word转化为字符数组 //经过word.toCharArray()下来,得到'c','a','s','s','a','b','a' Arrays.sort(wordChars);//对字符数组按字母升序排序 //得到'a','a','a','b','c','s','s' String sortedWord = new String(wordChars);//字符数组转化为字符串 //得到"aaabcss" sortedText.set(sortedWord);//设置输出key的值 //sortedText是aaabcss orginalText.set(word);//设置输出value的值 //orginalText是cassaba context.write( sortedText, orginalText );//map输出 } } public static class AnagramReducer extends Reducer<Text, Text, Text, Text> { private Text outputKey = new Text();// private Text outputValue = new Text(); public void reduce(Text Key, Iterable<Text>values,Context context) throws IOException, InterruptedException //key是anagramKey,即aaabcss values是orginalText,即cassaba {//reducer需要抛出异常,所以先提前写好。 String output = "";//定义output作为输出,并初始化 //对相同字母组成的单词,使用 ~ 符号进行拼接 for(Text anagam:values) //即把values的值,即orginalText的值,一一赋值给anagam。 即"cassaba",一一拆成"c" "a" "s" "s" "a" "b" "a" {//通过for循环,将相同字母构成的单词,拼接起来 if(!output.equals(""))//过滤 ,即这里为什么要过滤,即这个"casabas"读取完了,读到"k"之后的位置即算读完了 { output = output + "~" ;//用~来连接 //等号左边的output是 "cassaba" } output = output + anagam.toString();//进行累加 //左边的output是cassaba~casabas } StringTokenizer outputTokenizer = new StringTokenizer(output,"~" ); //outputTokenizer是按照~被切分割后的字符串,为cassaba casabas //通过 StringTokenizer来解析拼接的单词 //输出anagrams(字谜)大于2的结果。因为输出anagrams(字谜)大于2的结果,因为是找不同单词,至少是2个。 if(outputTokenizer.countTokens()>=2) { output = output.replace( "~", ",");//将~替换成, //即output为cassaba,casabas outputKey.set(Key.toString());//设置key的值 //outputKey为sortedText,为aaabcss outputValue.set(output);//设置value的值 //outputValue为相同单词组成的字谜 context.write( outputKey, outputValue);//reduce输出 } } } public int run(String[] arg0) throws Exception { //1 Configuration conf = new Configuration(); //2删除已经存在的输出目录 Path mypath = new Path(arg0[1]);//下标为1,即是输出路径 FileSystem hdfs = mypath.getFileSystem(conf);//获取文件系统 if (hdfs.isDirectory(mypath)) {//如果文件系统中存在这个输出路径,则删除掉 hdfs.delete(mypath, true); } Job job = new Job(conf, "anagram");//构建一个job对象,取名为testAnagram job.setJarByClass(Anagram.class);//设置主类 job.setMapperClass(AnagramMapper.class); //Mapper job.setReducerClass(AnagramReducer.class); //Reducer job.setOutputKeyClass(Text. class); job.setOutputValueClass(Text. class); FileInputFormat.addInputPath(job, new Path(arg0[0]));// 文件输入路径 FileOutputFormat.setOutputPath(job, new Path(arg0[1]));// 文件输出路径 job.waitForCompletion(true); return 0; } public static void main(String[] args) throws Exception {//定义数组来保存输入路径和输出路径 String[] args0 = { "hdfs://djt002:9000/anagram", "hdfs://djt002:9000/anagram/out"}; int ec = ToolRunner.run( new Configuration(), new Anagram(), args0); System. exit(ec); } }
以下是原始数据里的单词 casabas
package com.dajiangtai.hadoop.test; import java.io.IOException; import java.util.Arrays; import java.util.StringTokenizer; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; //import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * @统计相同字母组成的单词 * 1、编写map()函数 * 2、编写reduce()函数 * 3、编写run()函数 * 4、编写main() */ public class Anagram extends Configured implements Tool { public static class AnagramMapper extends Mapper<LongWritable, Text, Text, Text> { private Text sortedText = new Text();//存放排序好了的单词 private Text orginalText = new Text();//存放原始单词本身 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //因为map输出需要抛出异常,所以提前先写好 String word = value.toString();//将value转化为String类型 //比如value是casabas //经过value.toString()下来,得到word是"casabas" char[] wordChars = word.toCharArray();//单词word转化为字符数组 //经过word.toCharArray()下来,得到'c','a','s','a','b','a','s' Arrays.sort(wordChars);//对字符数组按字母升序排序 //得到'a','a','a','b','c','s','s' String sortedWord = new String(wordChars);//字符数组转化为字符串 //得到"aaabcss" sortedText.set(sortedWord);//设置输出key的值 //sortedText是aaabcss orginalText.set(word);//设置输出value的值 //orginalText是casabas context.write( sortedText, orginalText );//map输出 } } public static class AnagramReducer extends Reducer<Text, Text, Text, Text> { private Text outputKey = new Text();// private Text outputValue = new Text(); public void reduce(Text Key, Iterable<Text>values,Context context) throws IOException, InterruptedException //key是anagramKey,即aaabcss values是orginalText,即casabas {//reducer需要抛出异常,所以先提前写好。 String output = "";//定义output作为输出,并初始化 //对相同字母组成的单词,使用 ~ 符号进行拼接 for(Text anagam:values) //即把values的值,即orginalText的值,一一赋值给anagam。 即"casabas",一一拆成"c" "a" "s" "a" "b" "a" "s" {//通过for循环,将相同字母构成的单词,拼接起来 if(!output.equals(""))//过滤 ,即这里为什么要过滤,即这个"casabas"读取完了,读到"k"之后的位置即算读完了 { output = output + "~" ;//用~来连接 //等号左边的output是 c~a~s~a~b~a~s } output = output + anagam.toString();//进行累加 } StringTokenizer outputTokenizer = new StringTokenizer(output,"~" ); //outputTokenizer是按照~被切分割后的字符串,为aardvark //通过 StringTokenizer来解析拼接的单词 //输出anagrams(字谜)大于2的结果。因为输出anagrams(字谜)大于2的结果,因为是找不同单词,至少是2个。 if(outputTokenizer.countTokens()>=2) { output = output.replace( "~", ",");//将~替换成, outputKey.set(Key.toString());//设置key的值 outputValue.set(output);//设置value的值 context.write( outputKey, outputValue);//reduce输出 } } } public int run(String[] arg0) throws Exception { //1 Configuration conf = new Configuration(); //2删除已经存在的输出目录 Path mypath = new Path(arg0[1]);//下标为1,即是输出路径 FileSystem hdfs = mypath.getFileSystem(conf);//获取文件系统 if (hdfs.isDirectory(mypath)) {//如果文件系统中存在这个输出路径,则删除掉 hdfs.delete(mypath, true); } Job job = new Job(conf, "anagram");//构建一个job对象,取名为testAnagram job.setJarByClass(Anagram.class);//设置主类 job.setMapperClass(AnagramMapper.class); //Mapper job.setReducerClass(AnagramReducer.class); //Reducer job.setOutputKeyClass(Text. class); job.setOutputValueClass(Text. class); FileInputFormat.addInputPath(job, new Path(arg0[0]));// 文件输入路径 FileOutputFormat.setOutputPath(job, new Path(arg0[1]));// 文件输出路径 job.waitForCompletion(true); return 0; } public static void main(String[] args) throws Exception {//定义数组来保存输入路径和输出路径 String[] args0 = { "hdfs://djt002:9000/anagram", "hdfs://djt002:9000/anagram/out"}; int ec = ToolRunner.run( new Configuration(), new Anagram(), args0); System. exit(ec); } }
总结
若是将map、combiner、shuffle、reduce等全放在同一个.java里。则采用上述这样的编程写法。直接是 new Anagram()。
若是将map、combiner、shuffle、reduce等分开放一个.java里。则需要实现Tool。见下面这篇博客
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5078072.html,如需转载请自行联系原作者

