我想得到按流量来排序,而且还是倒序,怎么达到实现呢?
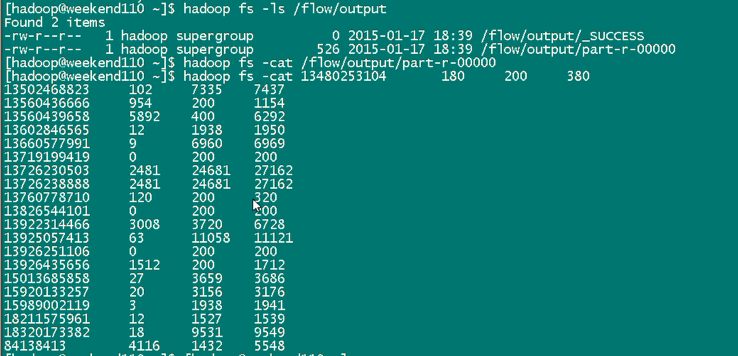
达到下面这种效果,
默认是根据key来排,
我想根据value里的某个排,
解决思路:将value里的某个,放到key里去,然后来排
下面,开始weekend110的hadoop的自定义排序实现
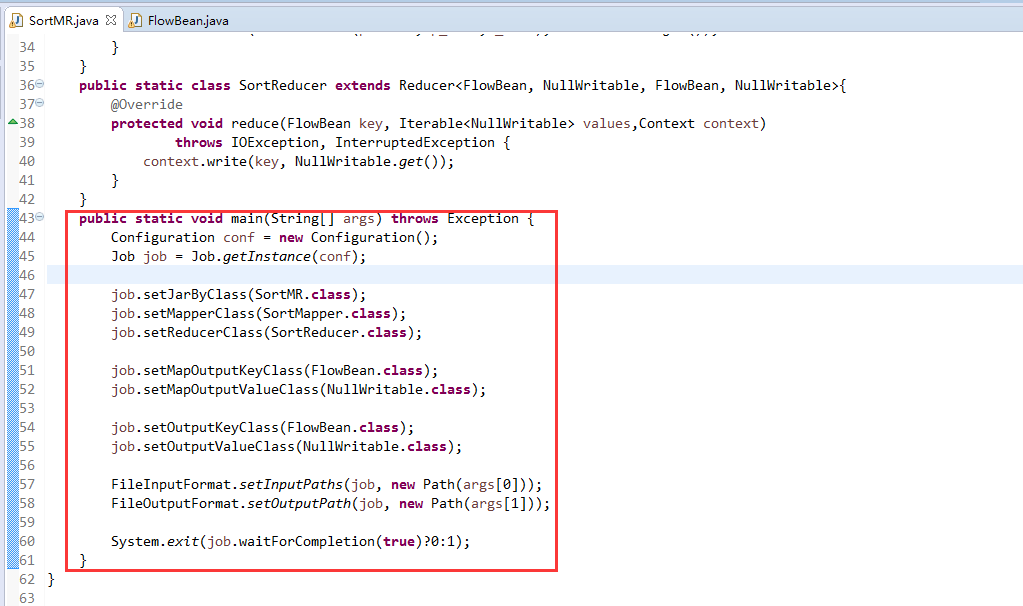
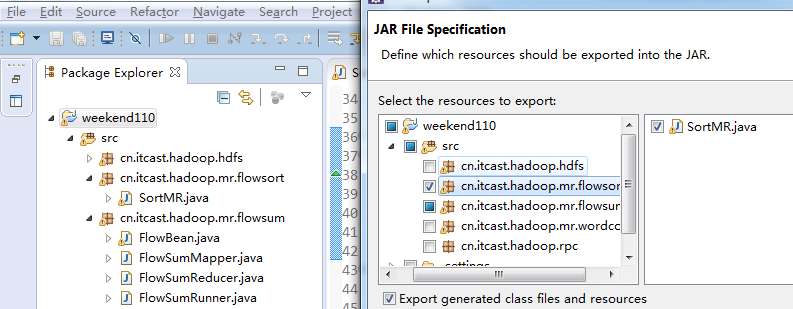
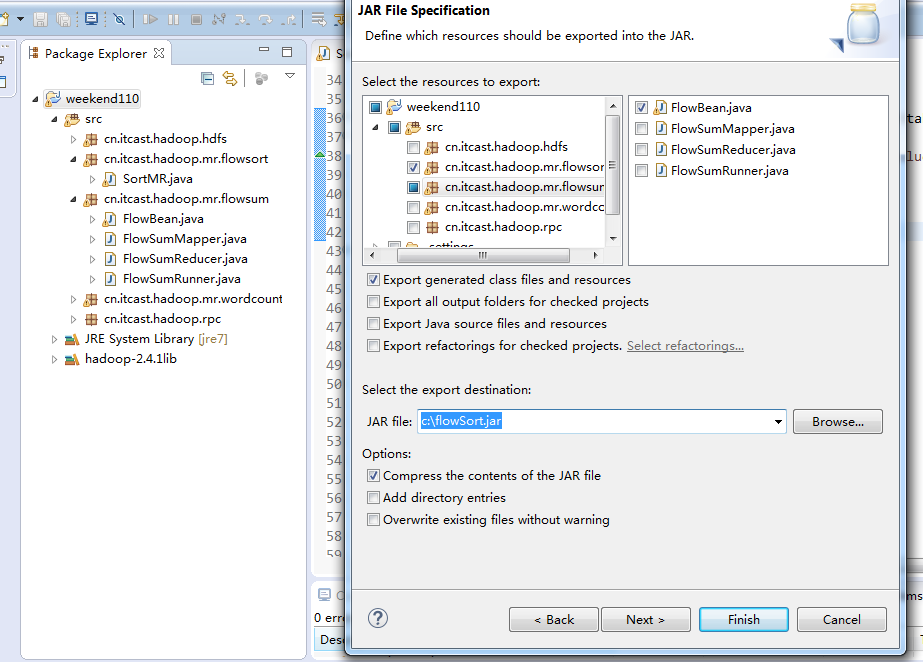
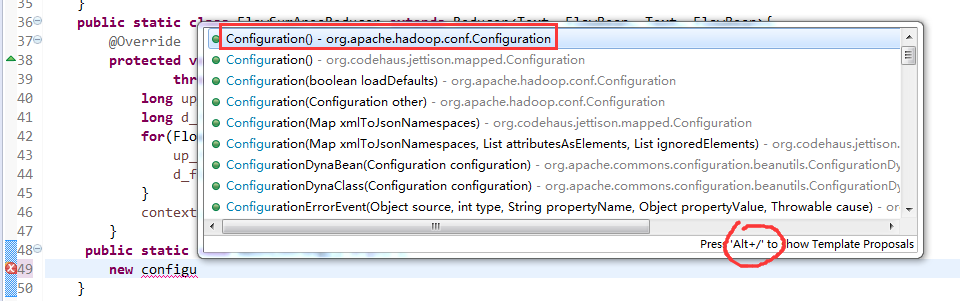
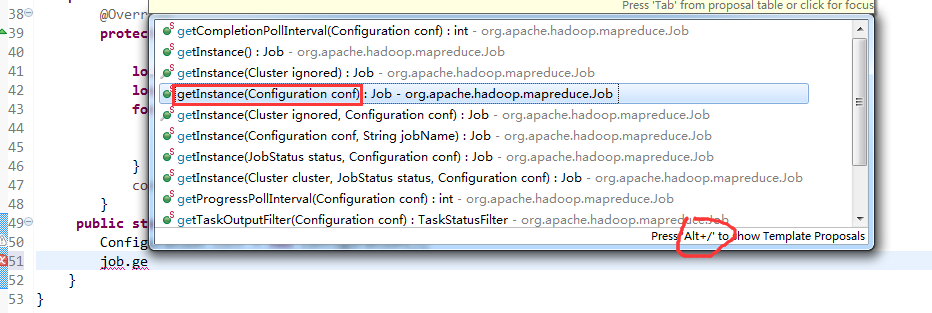
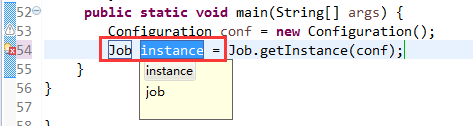
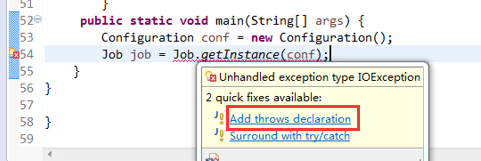
将FlowSortMapper、FlowSortReduce、FlowSortRunner、FlowSortBean,全放到一个SortMR里。
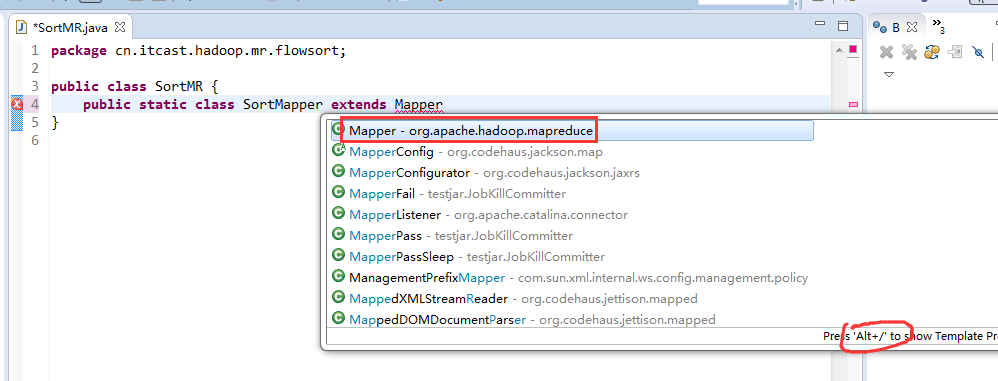

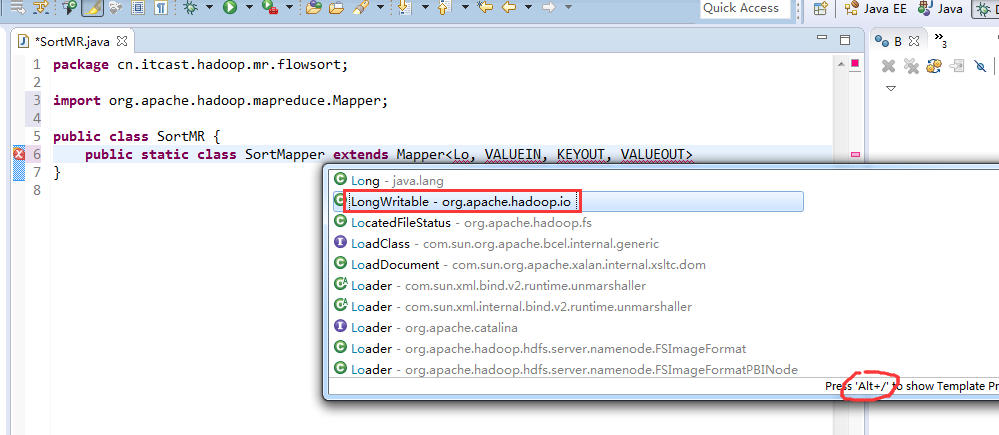
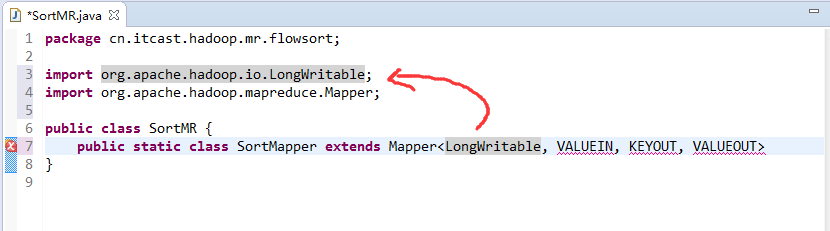
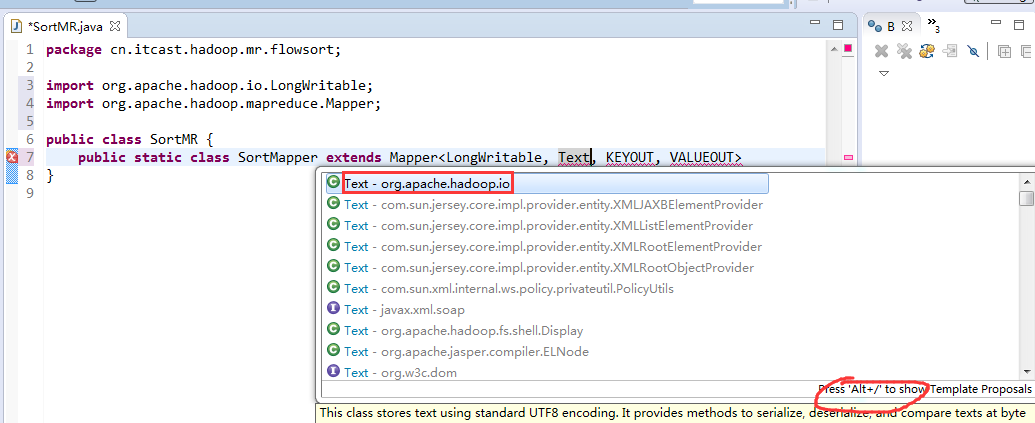
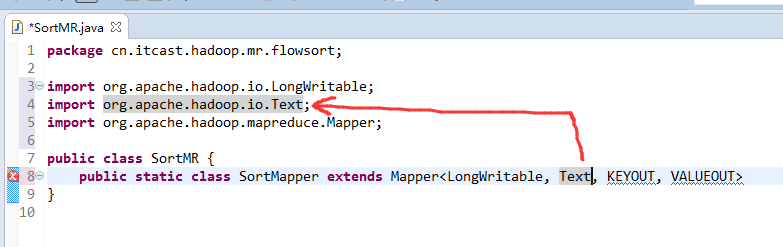

V2我们不要,怎么写代码?
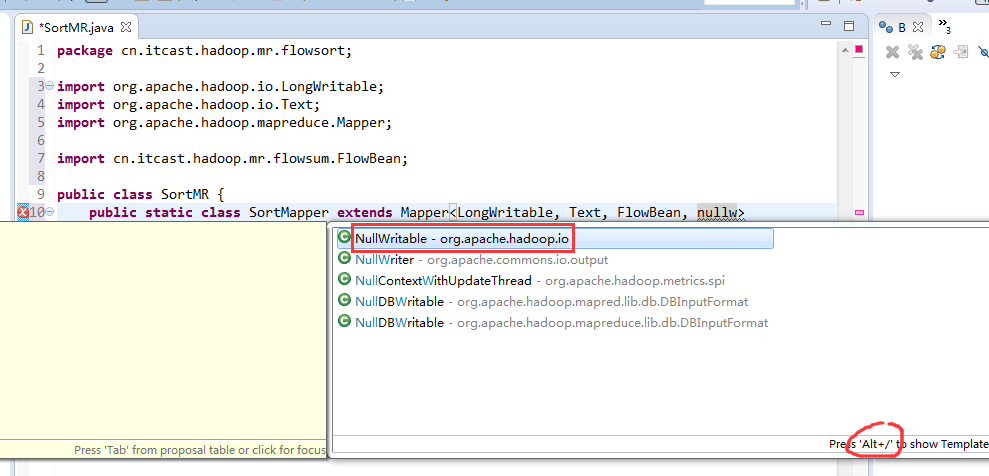

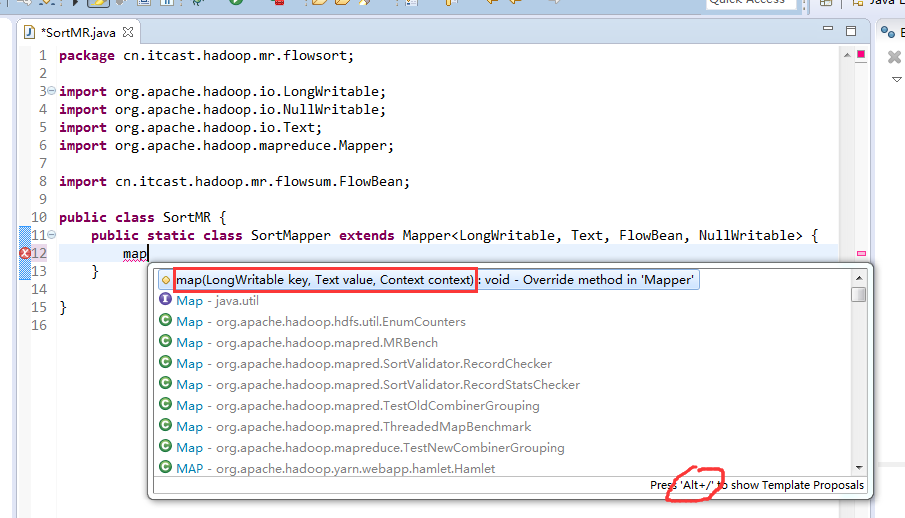
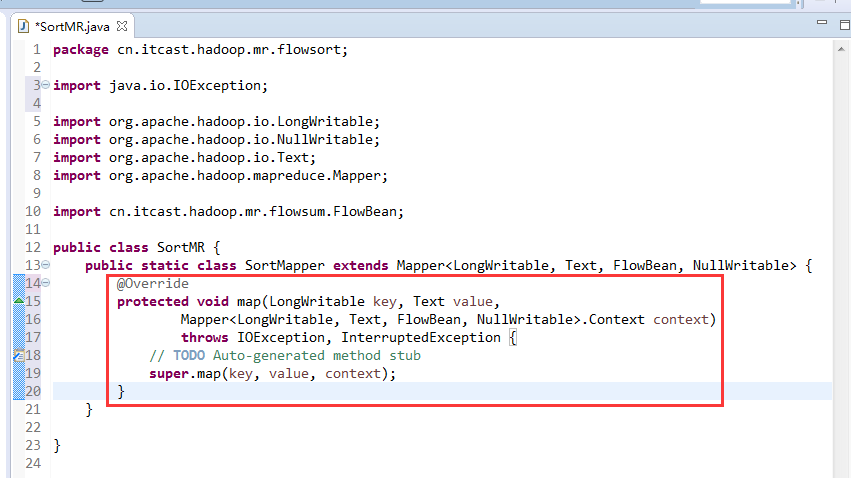
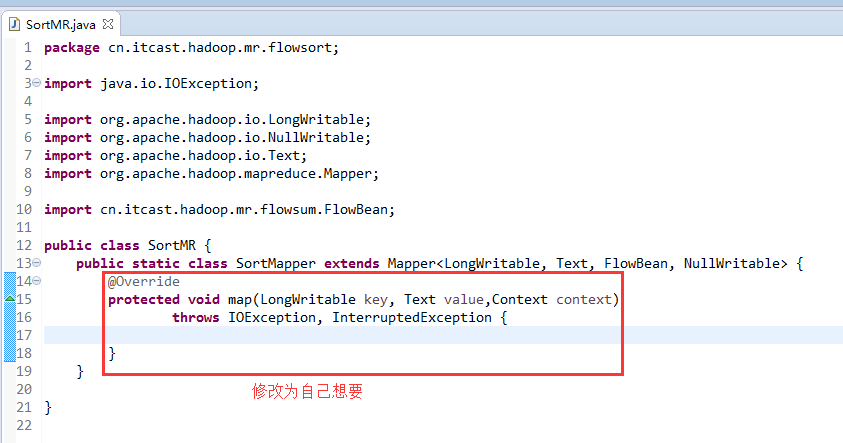
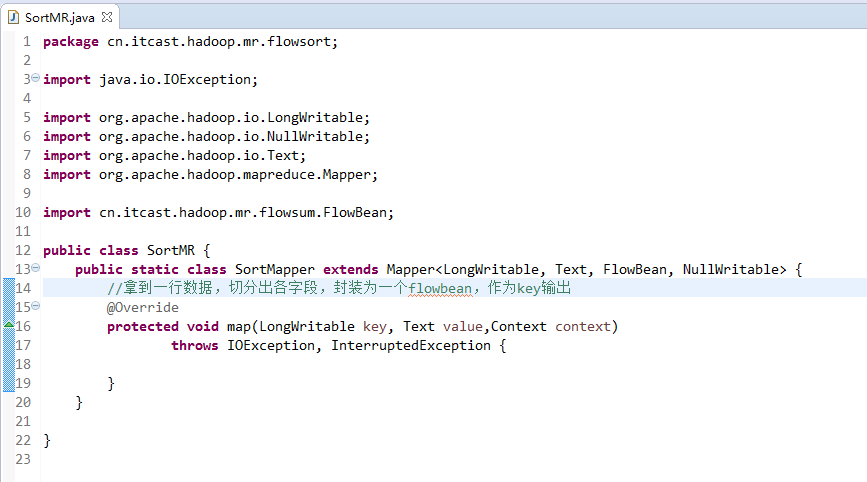
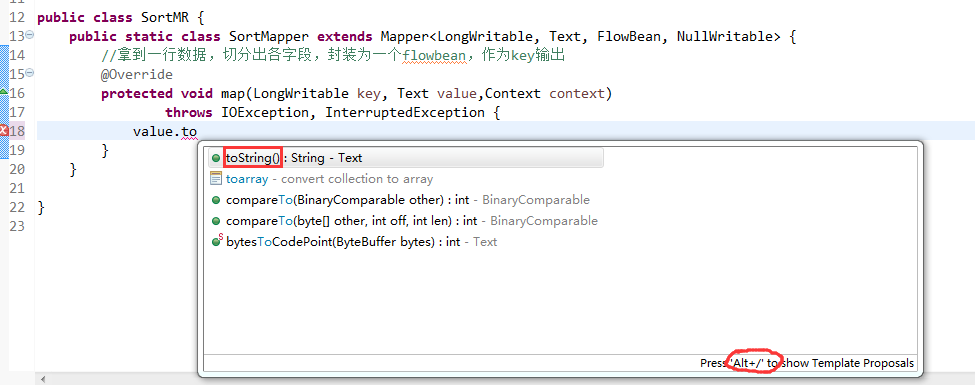
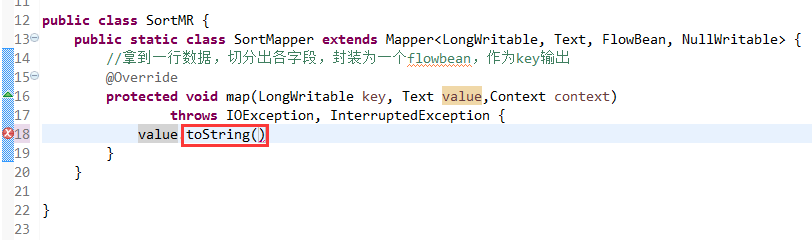
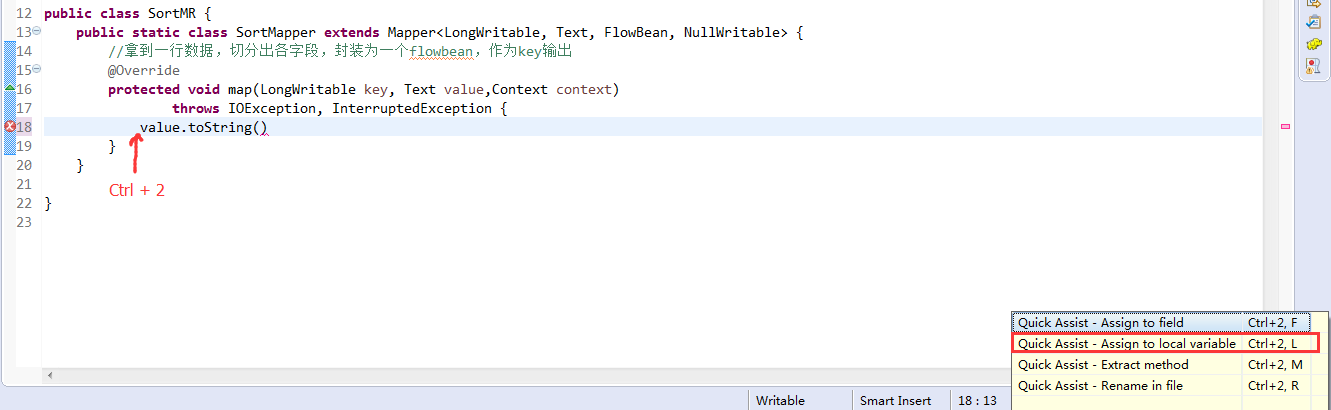


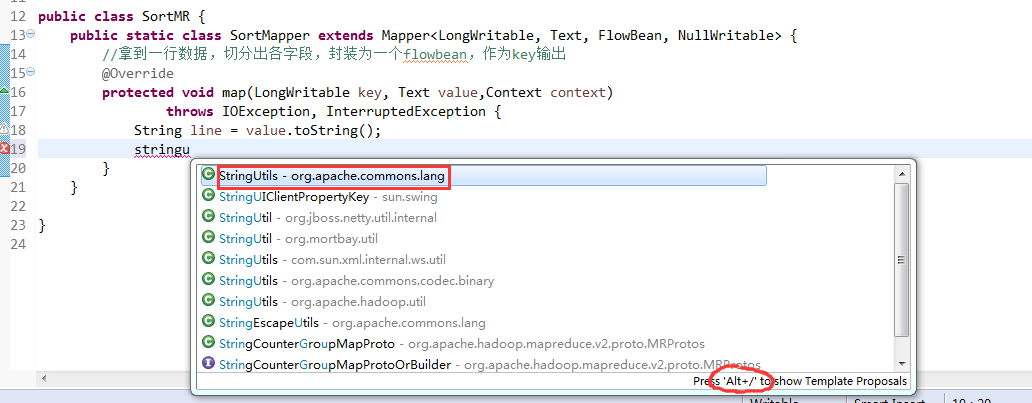



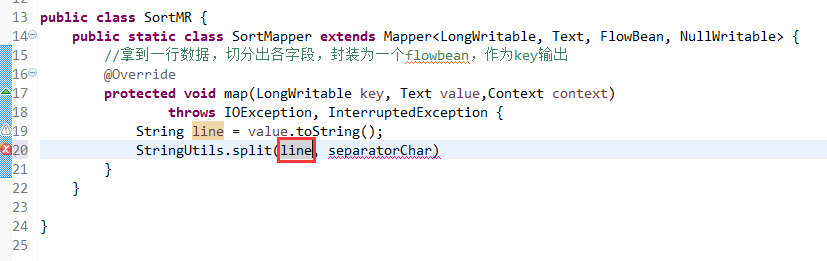
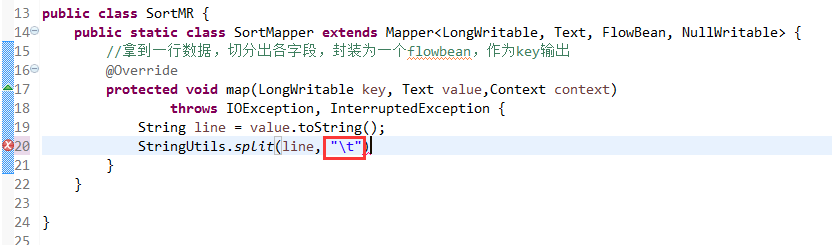
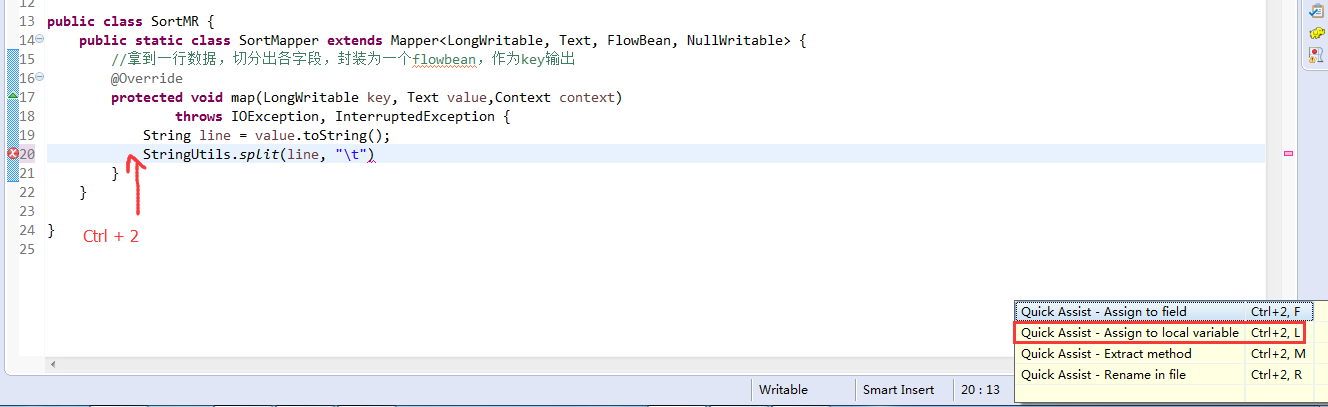


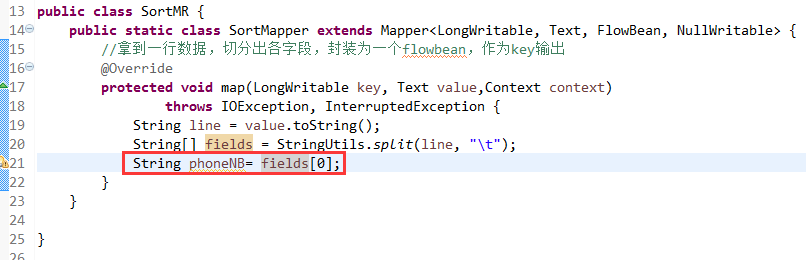

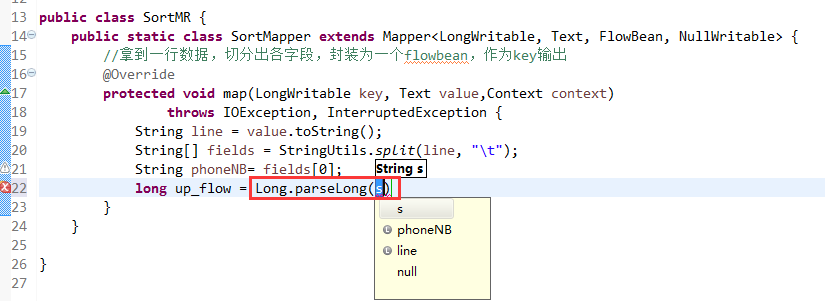
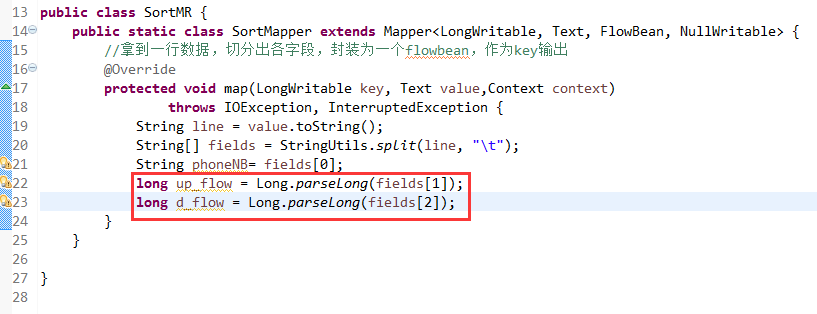
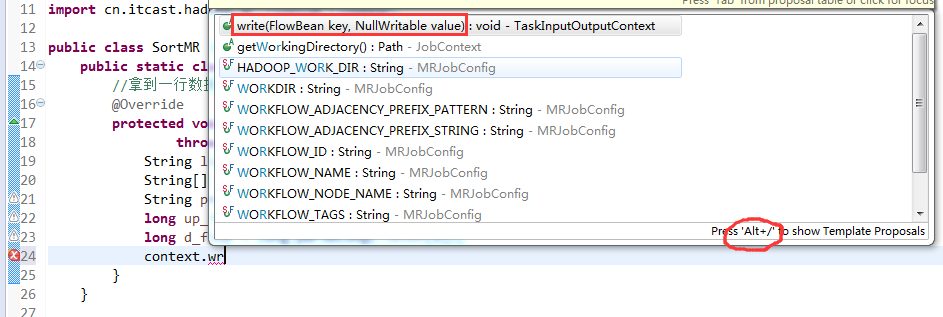
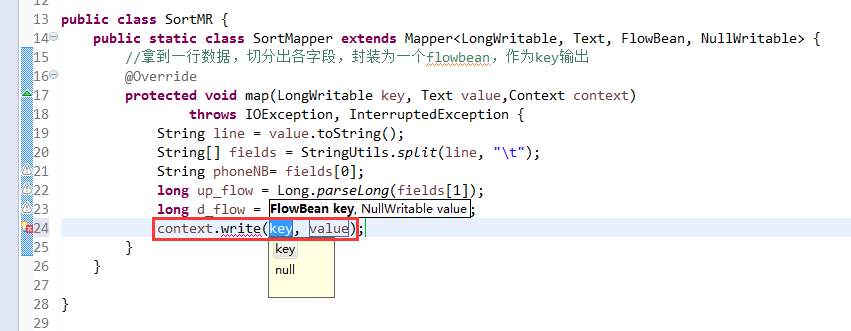
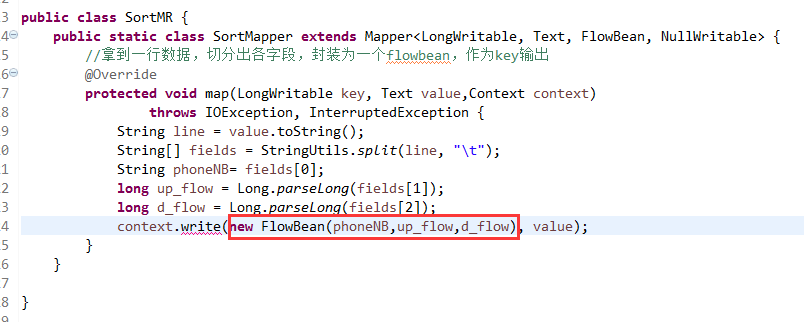
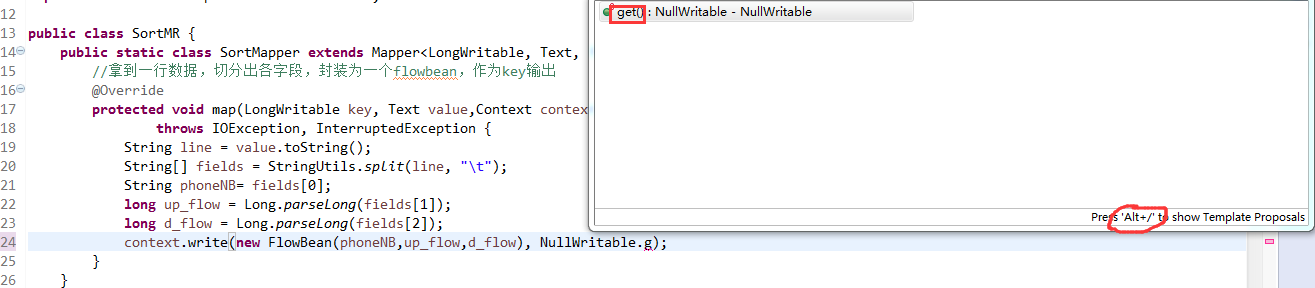
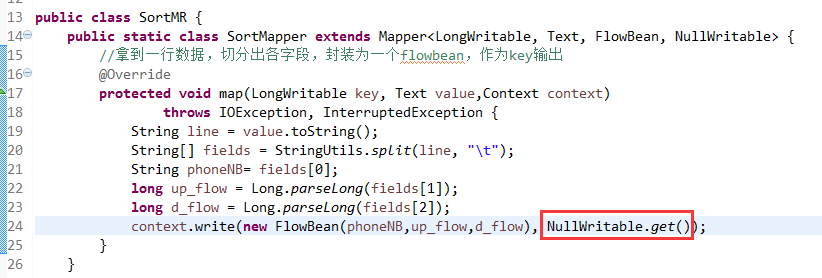

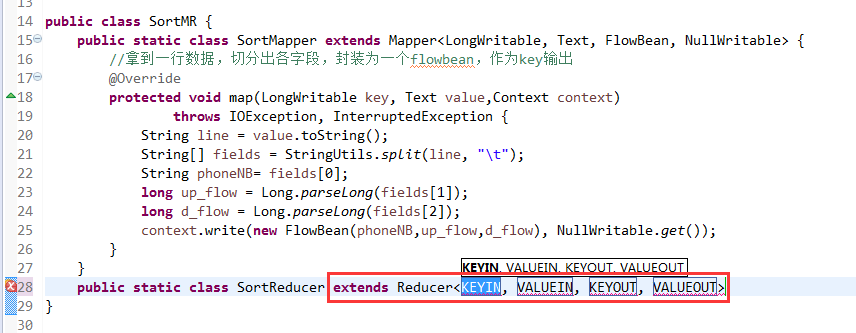
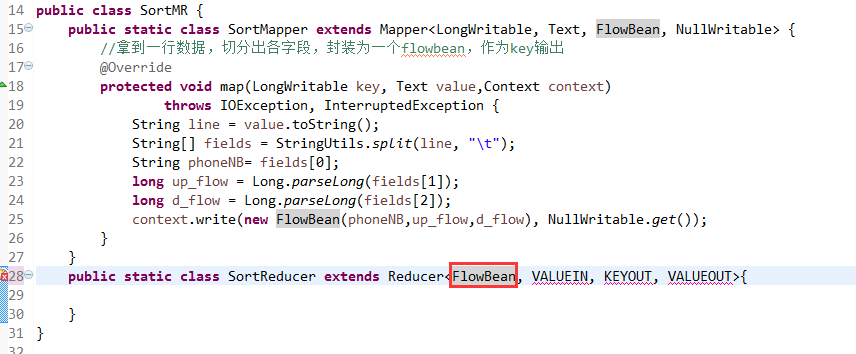
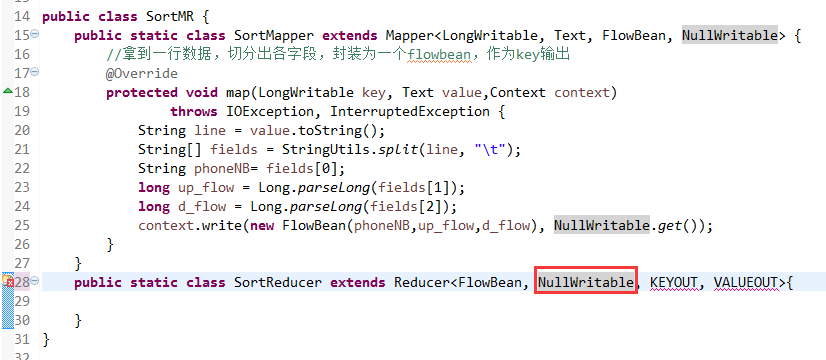

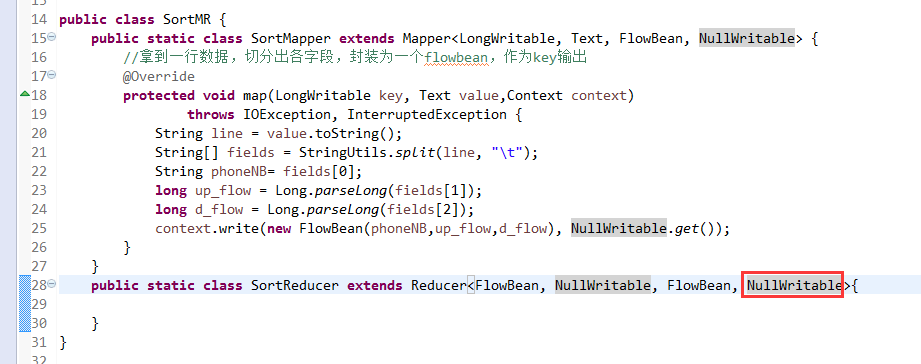
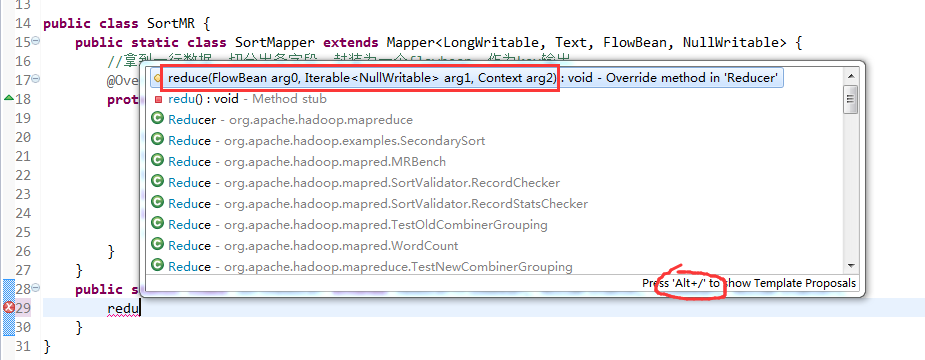
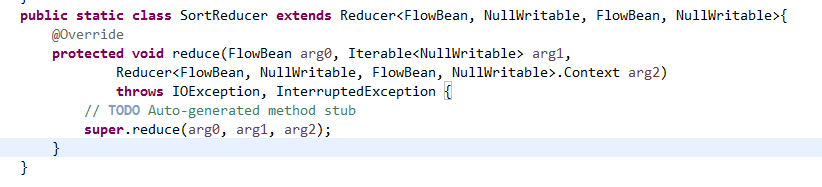



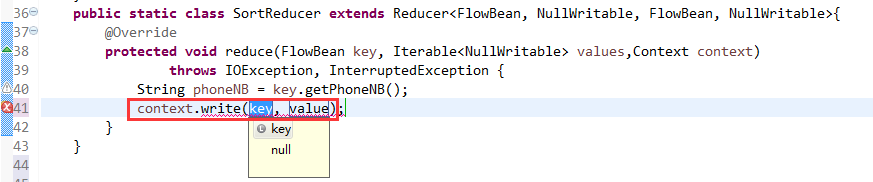

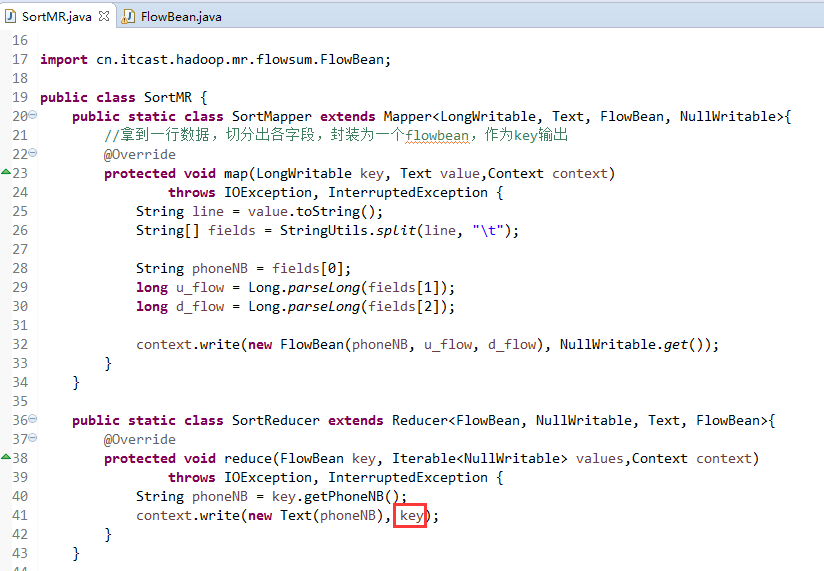
那么,我们想要实现由
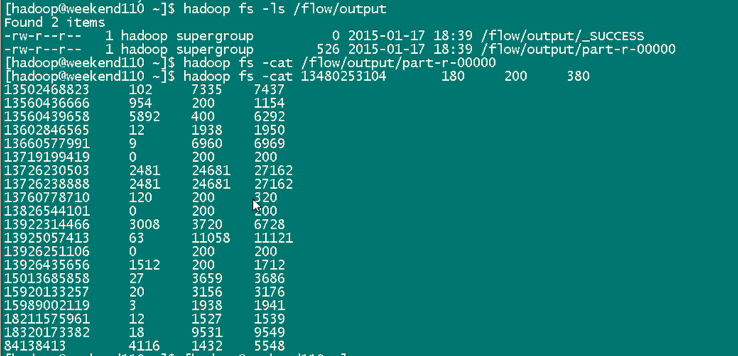
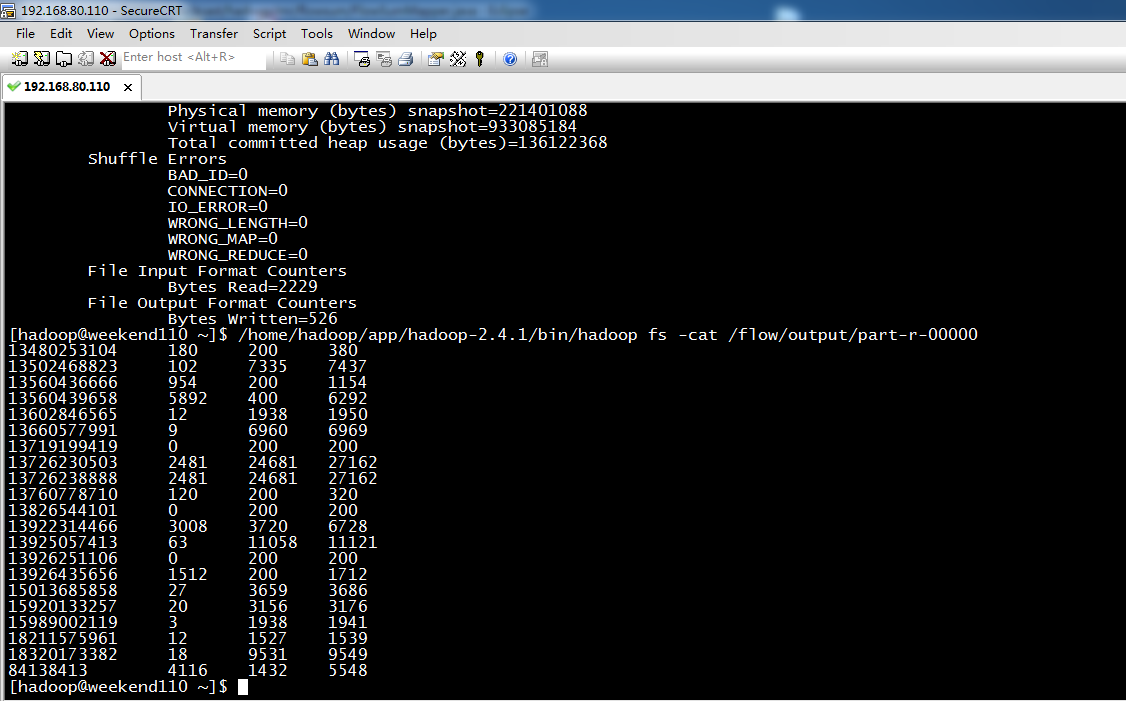
达到下面这种效果,
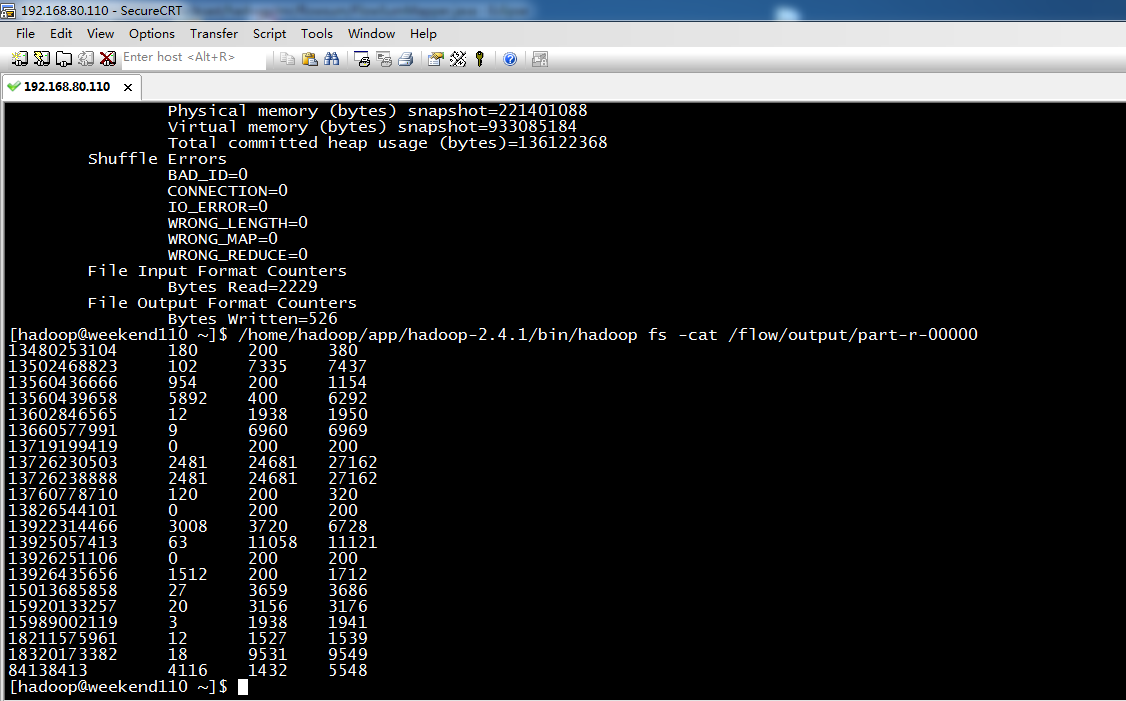
也要修改FlowBean代码
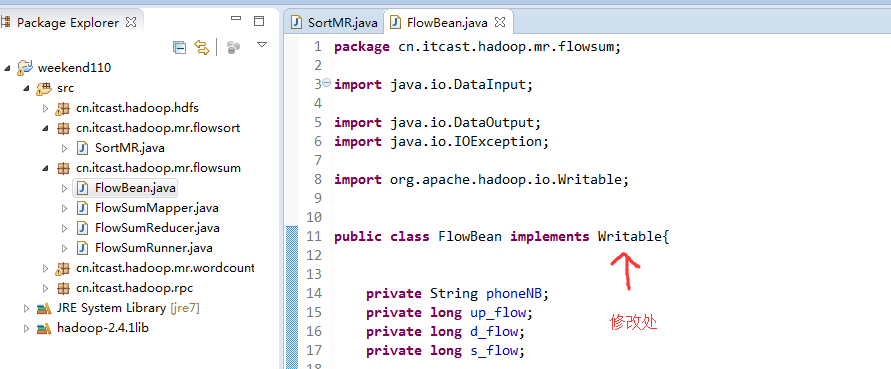
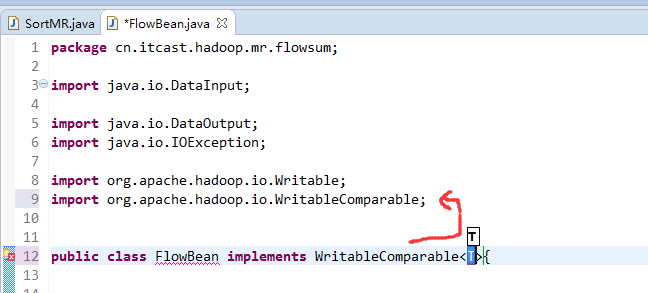
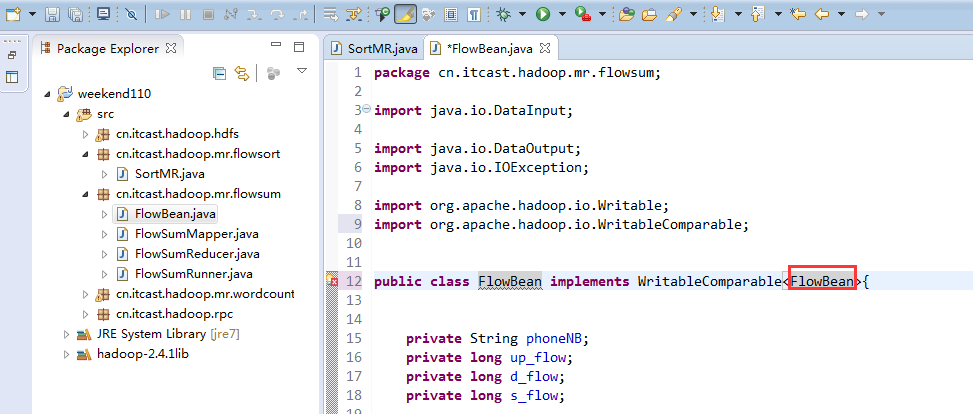
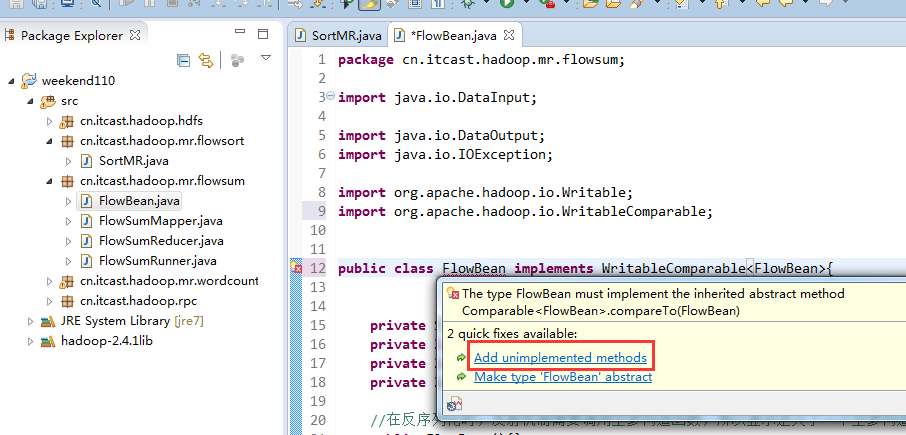
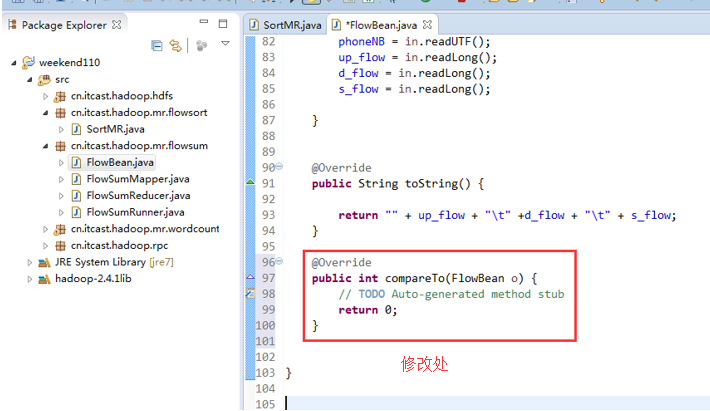
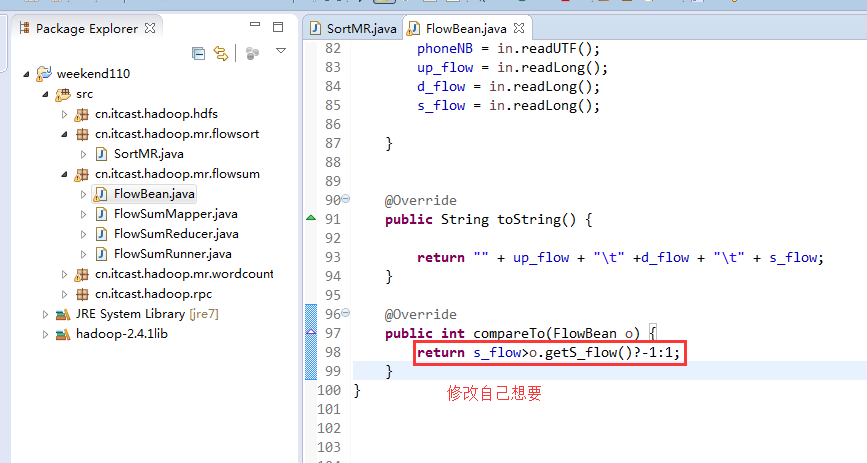
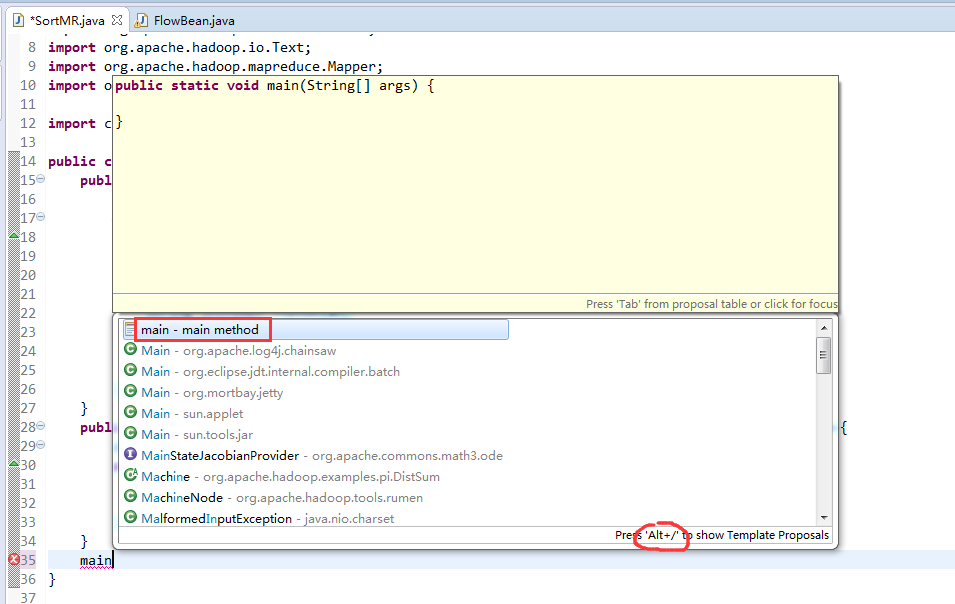
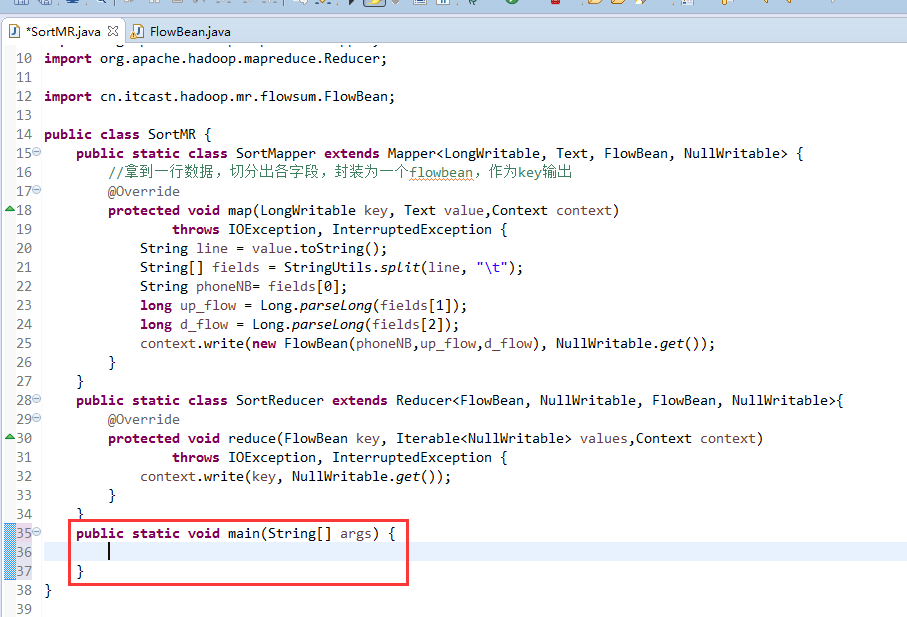
多领悟揣摩。
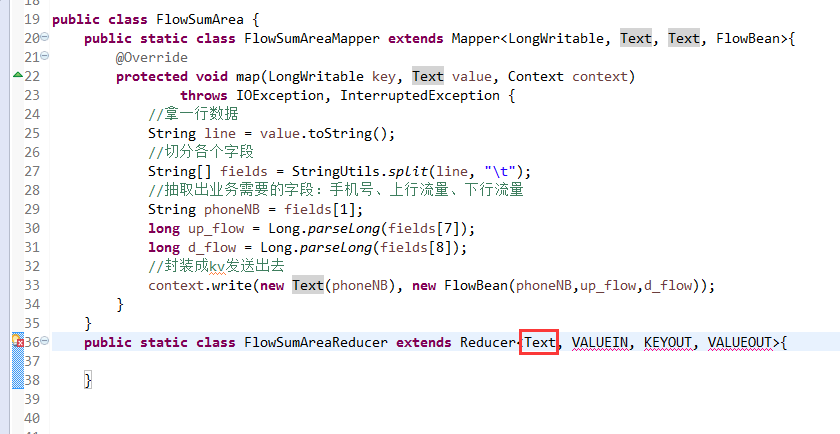
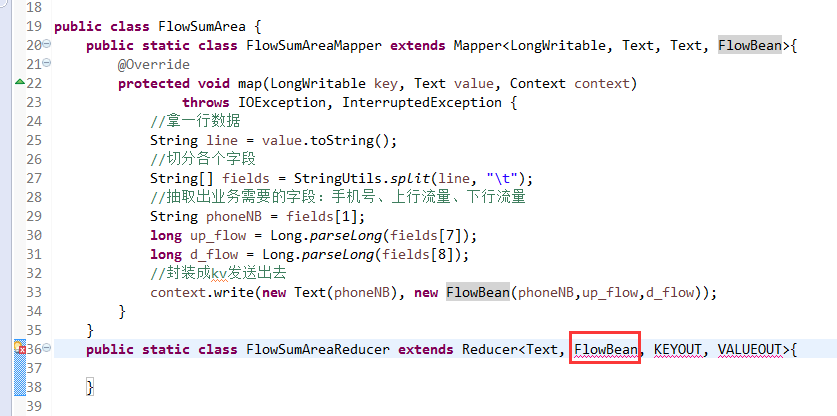
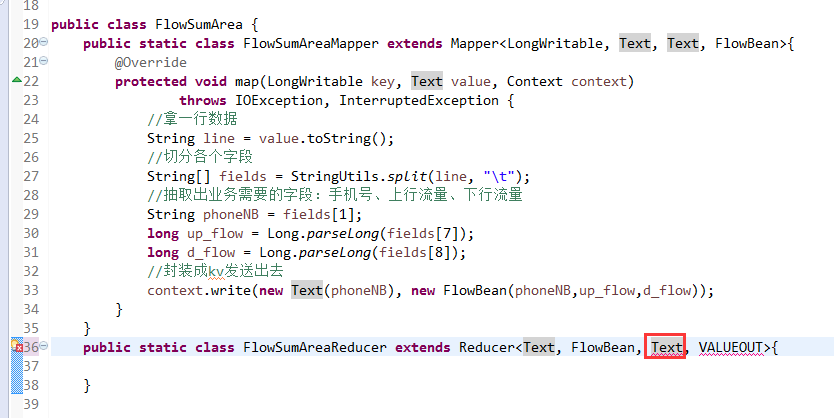
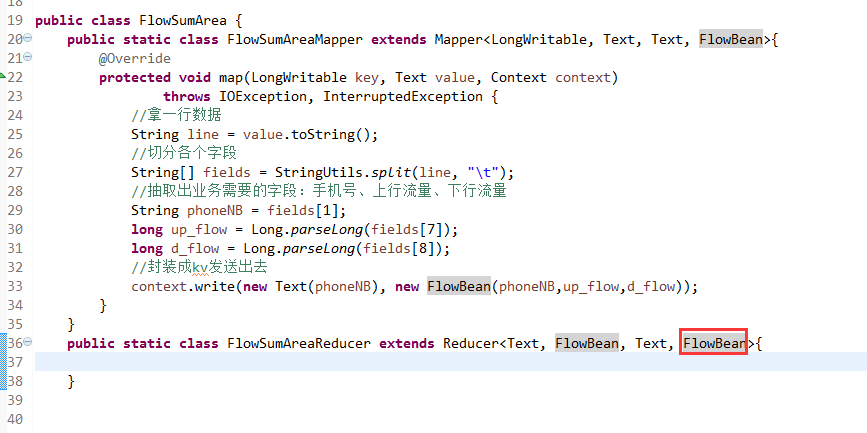
关于SotrMR和FlowBean(增改过的)
关于FlowMapper、FlowReducer、FlowSumRunner、FlowBean
之间的对比




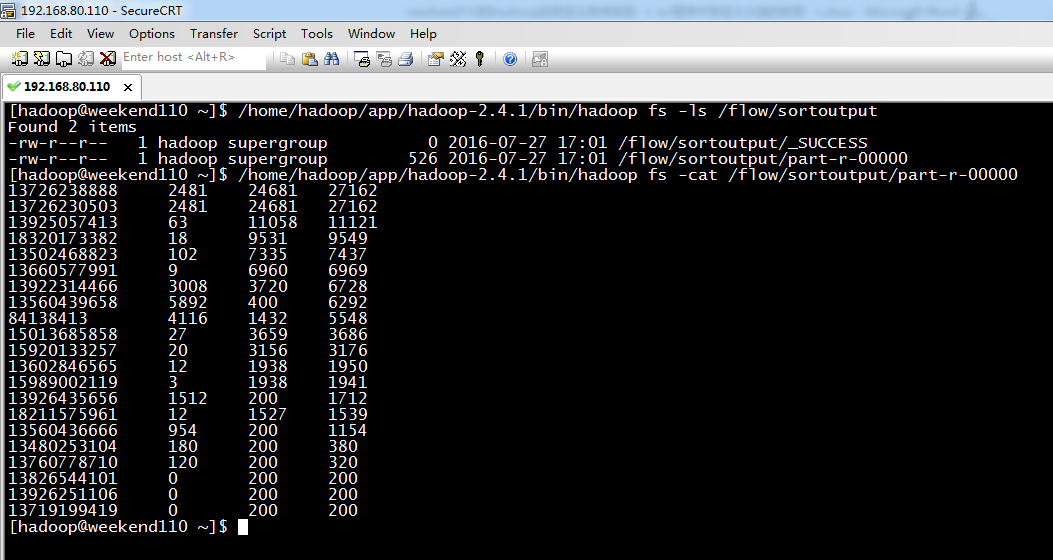
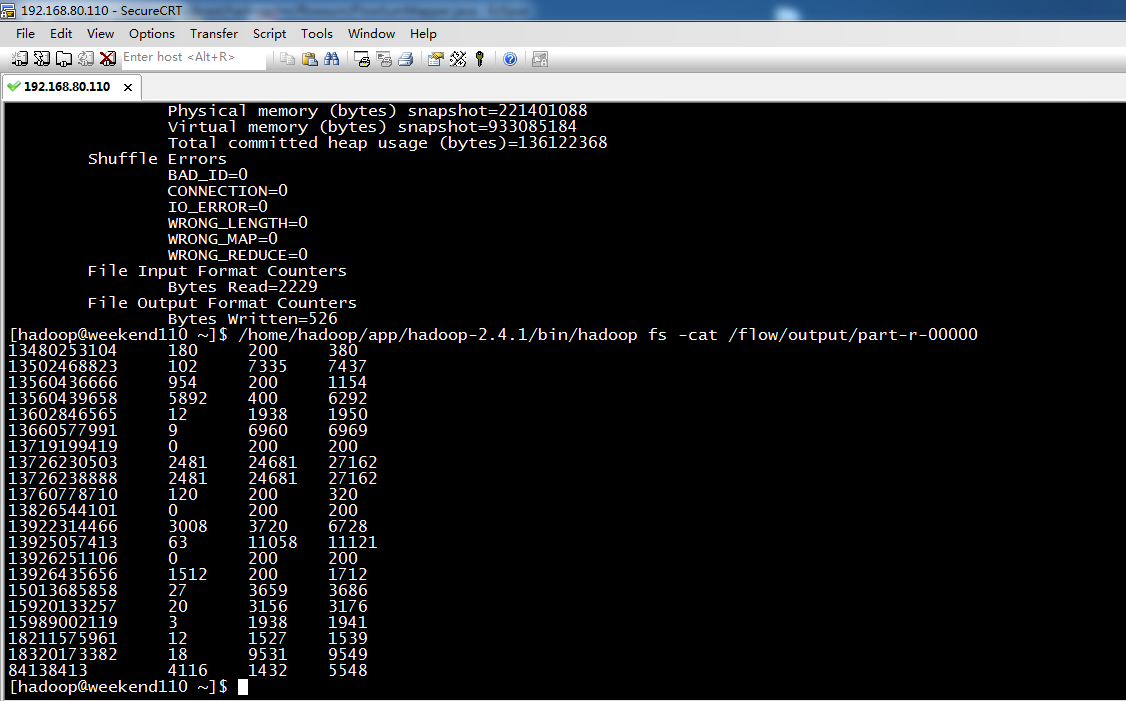
[hadoop@weekend110 ~]$ /home/hadoop/app/hadoop-2.4.1/bin/hadoop fs -cat /flow/sortoutput/part-r-00000
13726238888 2481 24681 27162
13726230503 2481 24681 27162
13925057413 63 11058 11121
18320173382 18 9531 9549
13502468823 102 7335 7437
13660577991 9 6960 6969
13922314466 3008 3720 6728
13560439658 5892 400 6292
84138413 4116 1432 5548
15013685858 27 3659 3686
15920133257 20 3156 3176
13602846565 12 1938 1950
15989002119 3 1938 1941
13926435656 1512 200 1712
18211575961 12 1527 1539
13560436666 954 200 1154
13480253104 180 200 380
13760778710 120 200 320
13826544101 0 200 200
13926251106 0 200 200
13719199419 0 200 200
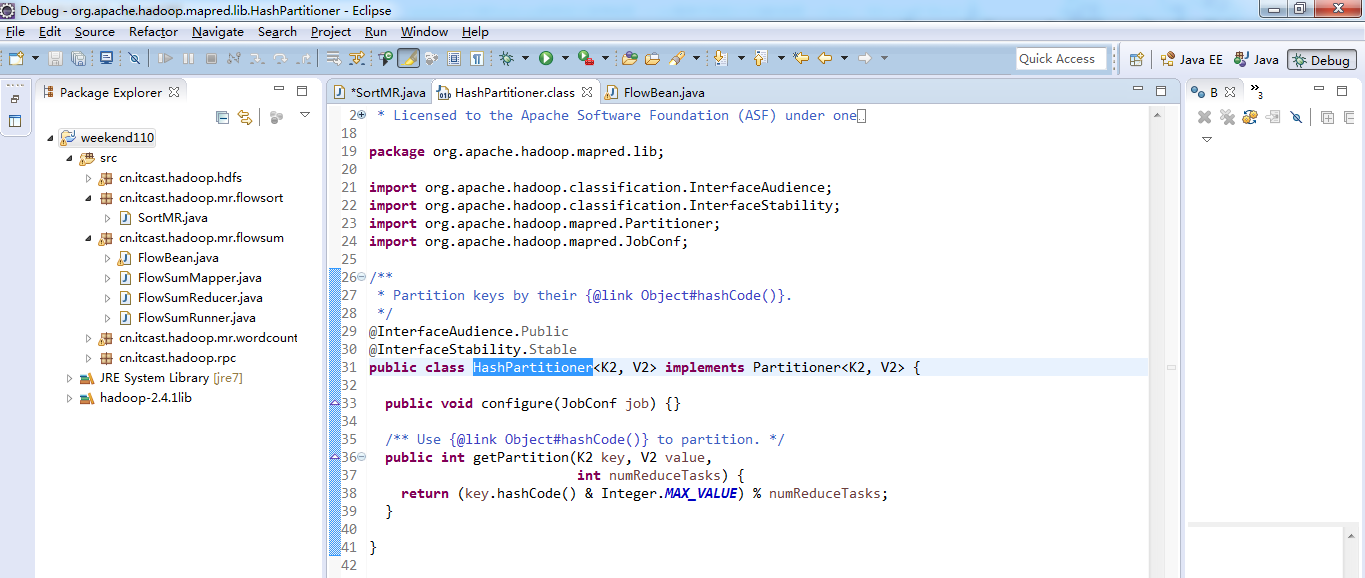
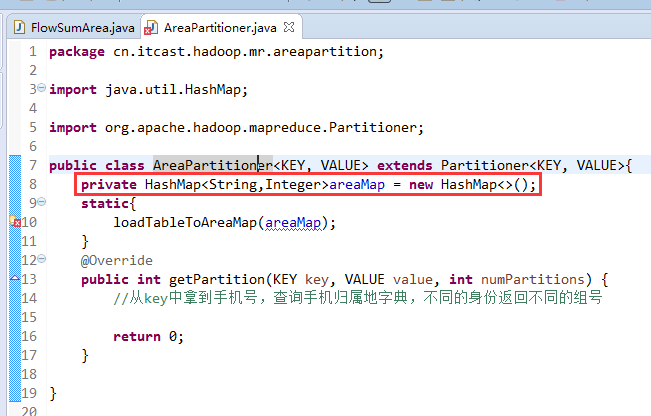
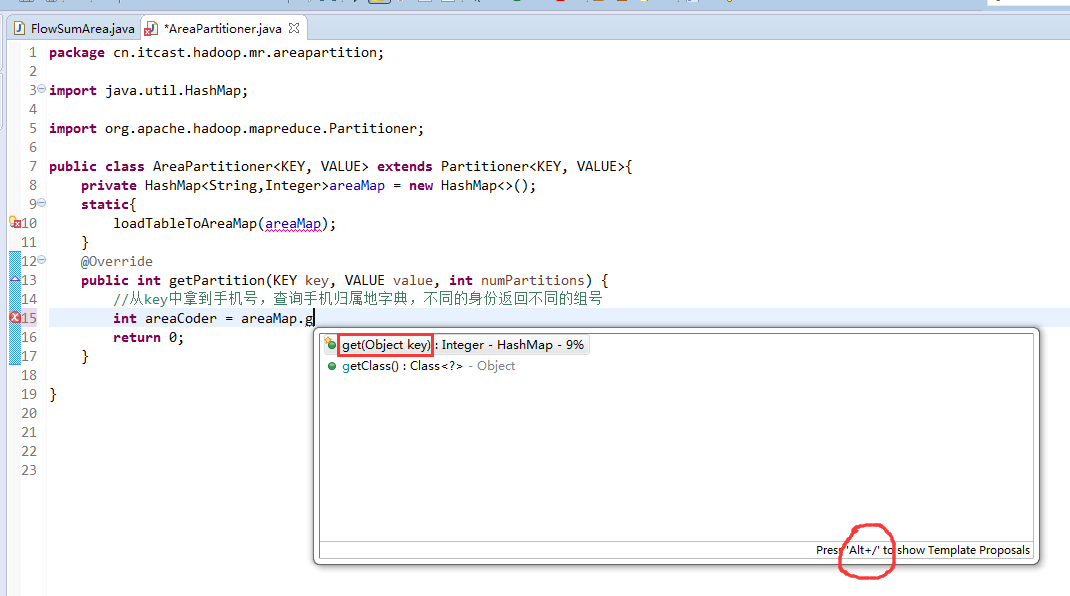
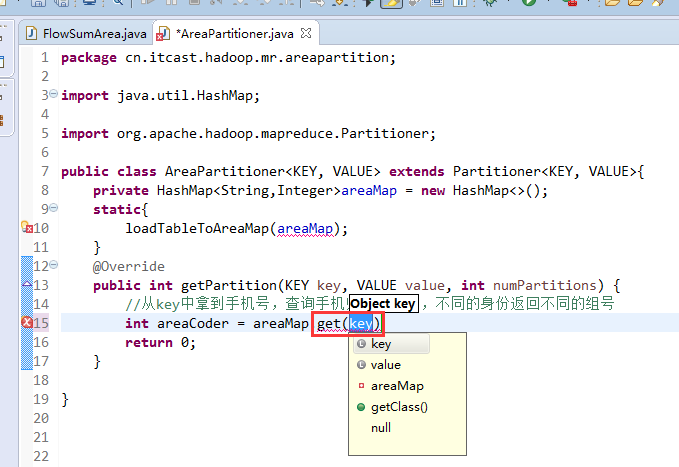
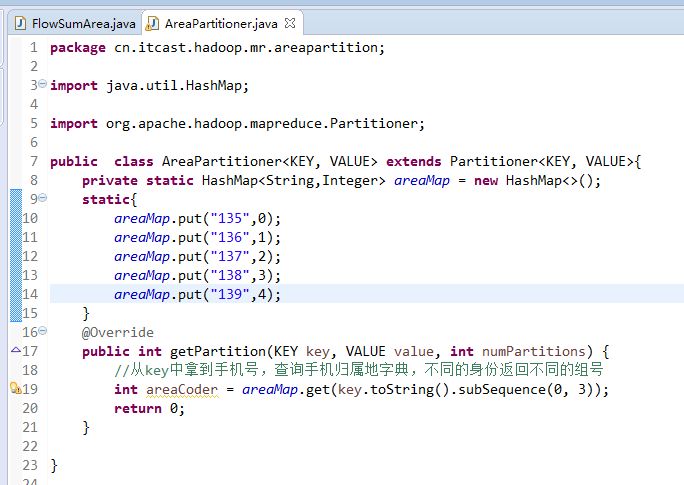
默认分组是哈希,
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.mapred.lib;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.mapred.Partitioner;
import org.apache.hadoop.mapred.JobConf;
/**
* Partition keys by their {@link Object#hashCode()}.
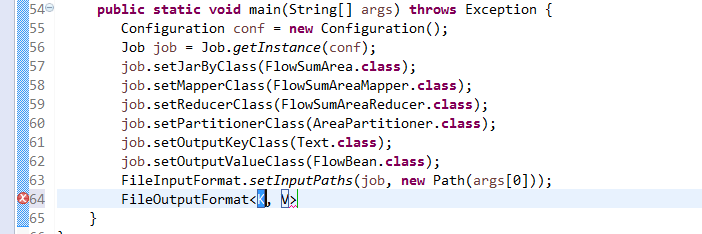
*/
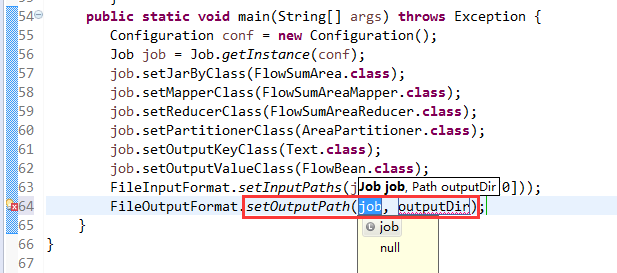
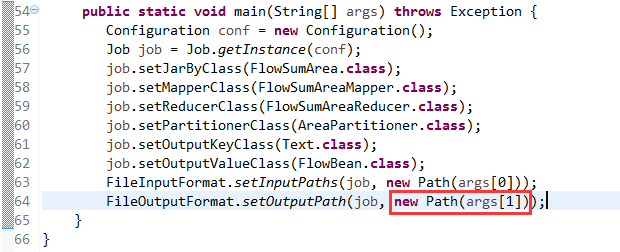
@InterfaceAudience.Public
@InterfaceStability.Stable
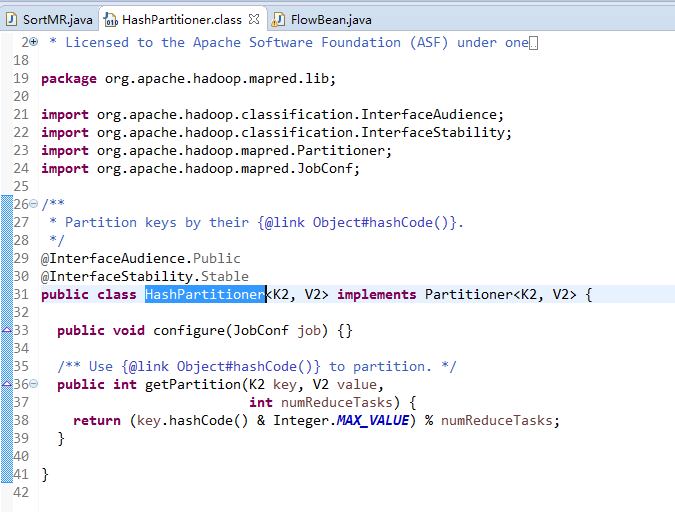
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}


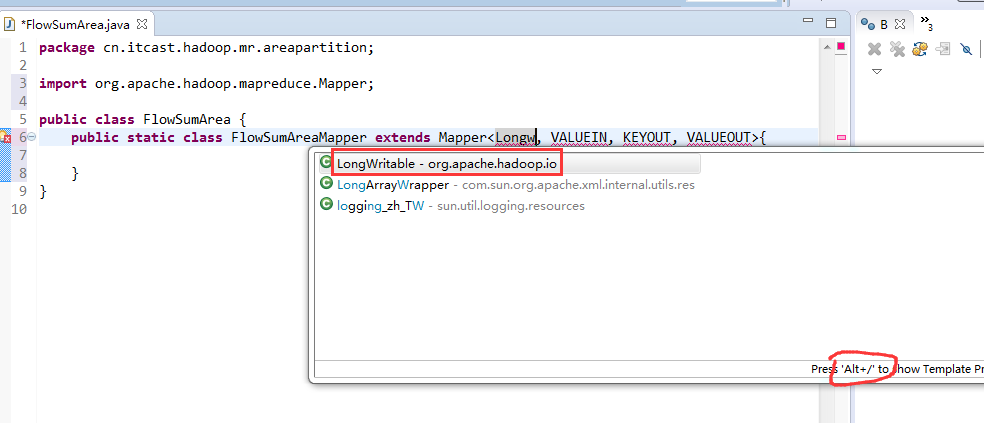


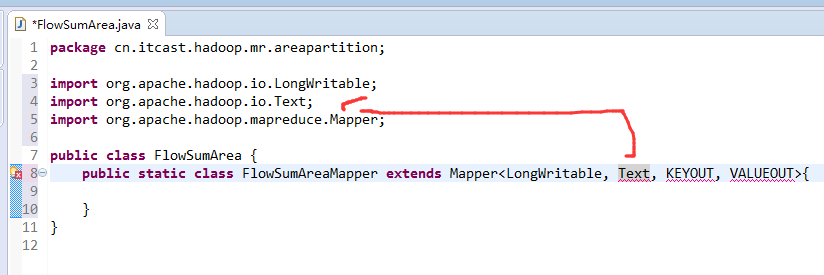
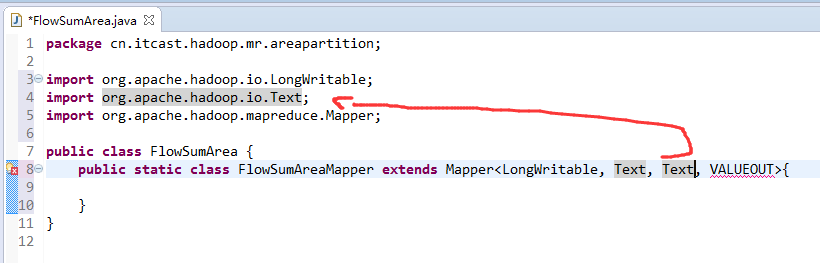



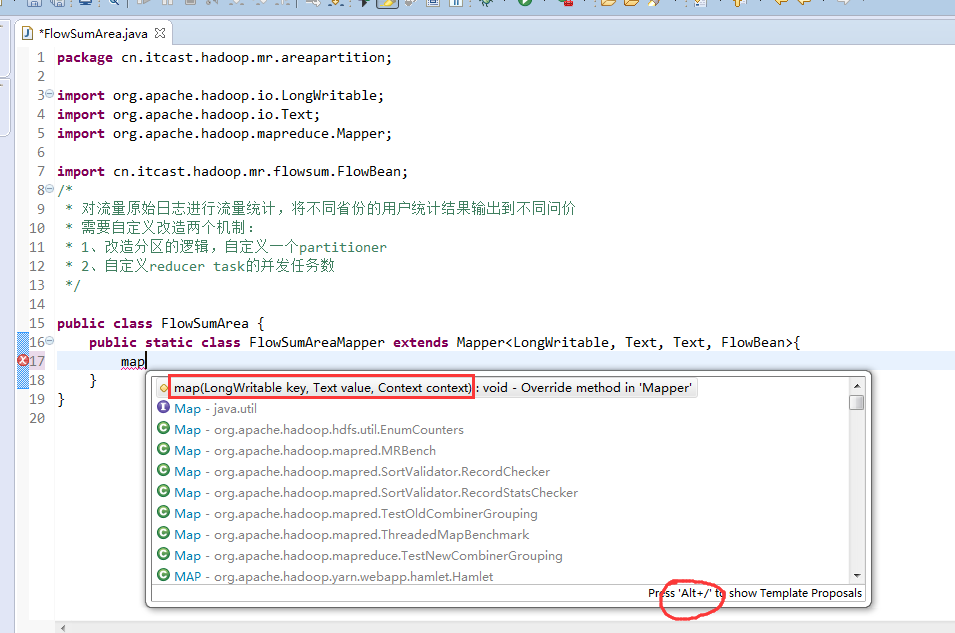
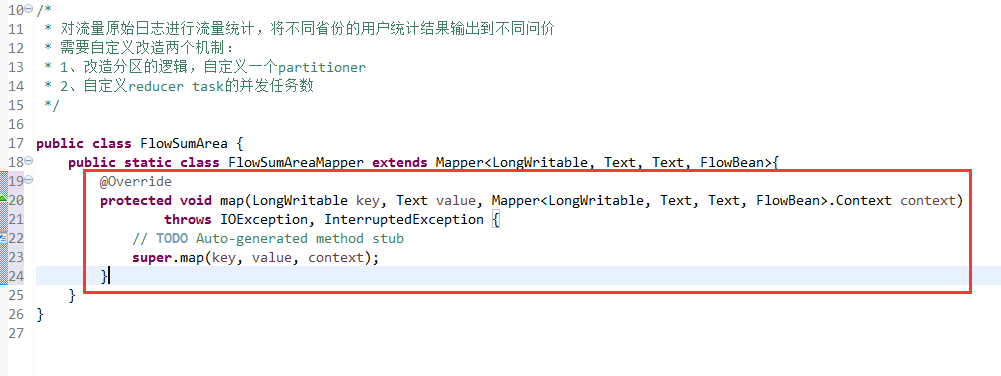

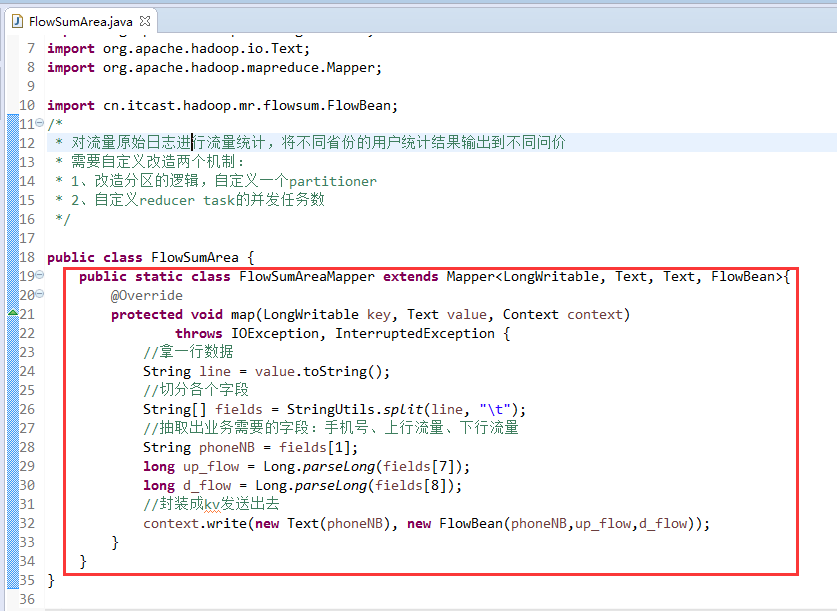
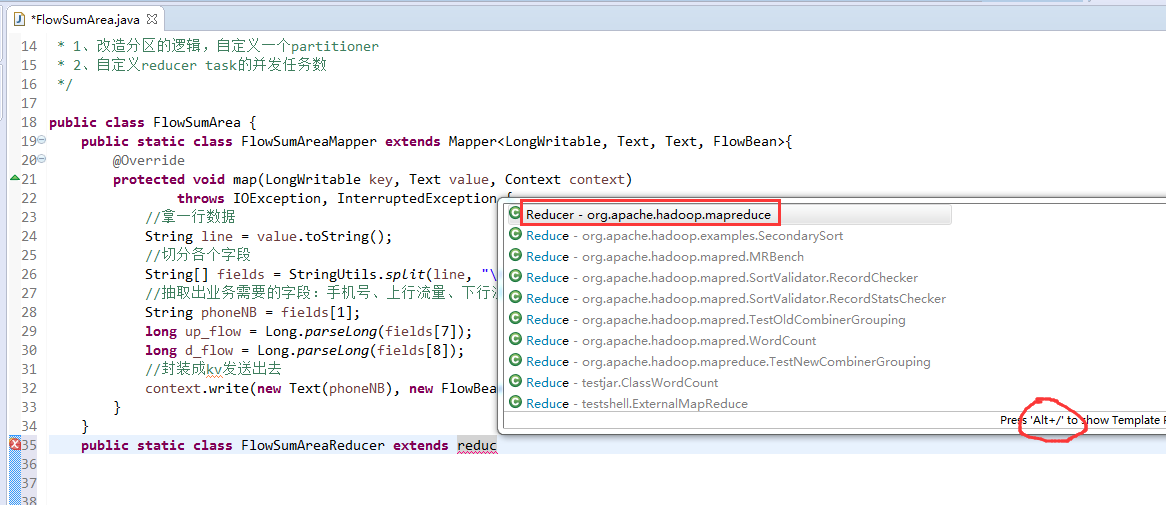
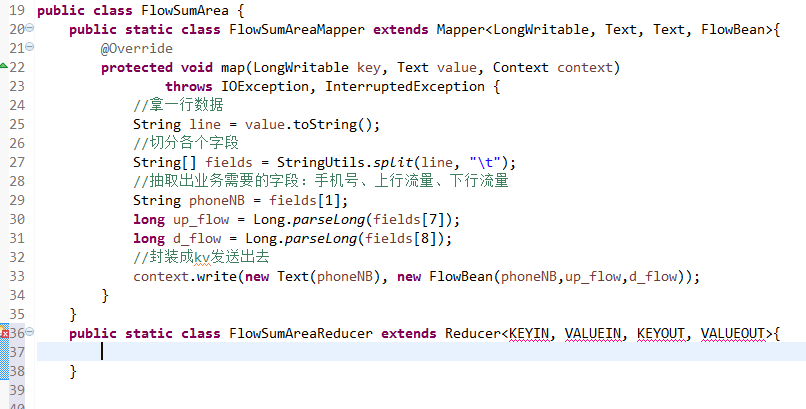
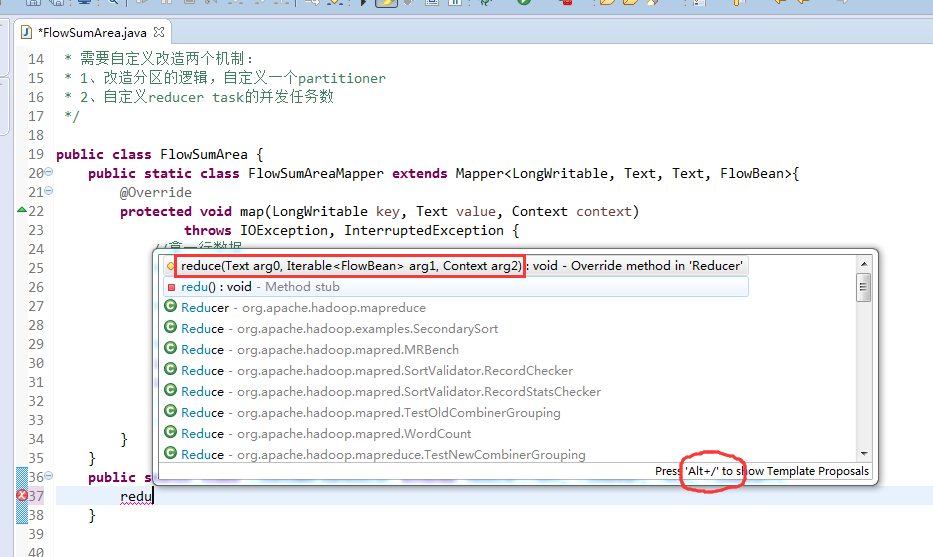


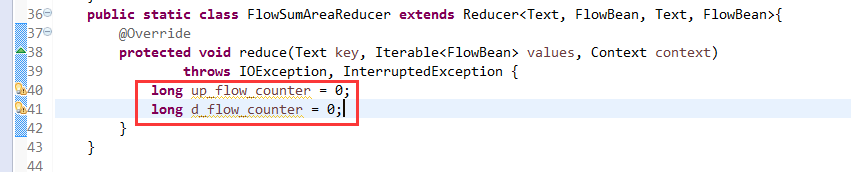
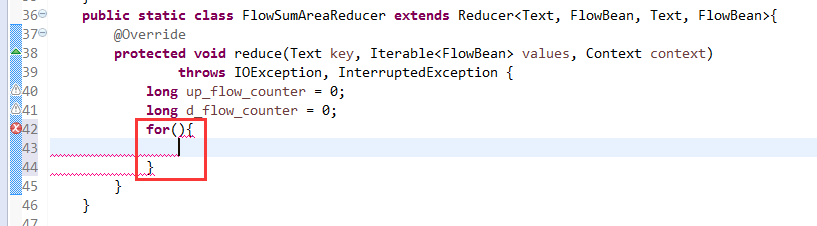

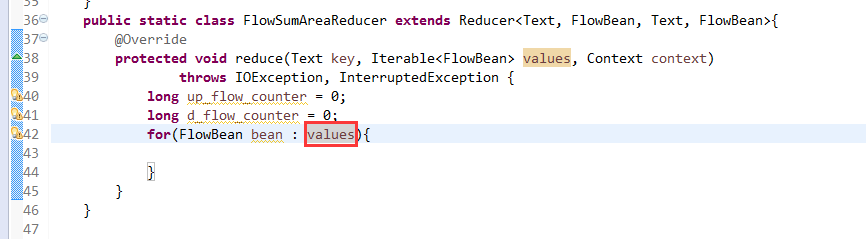
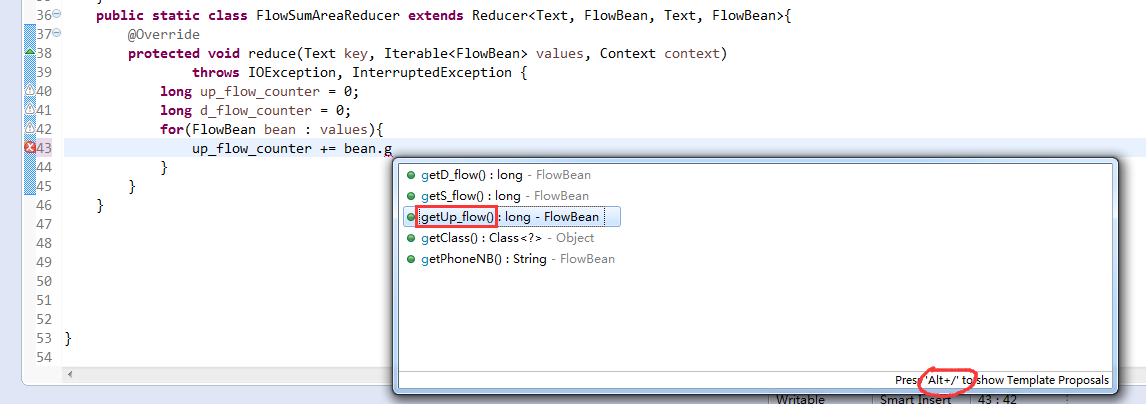
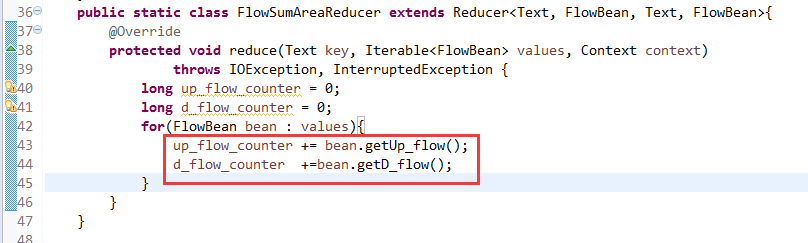
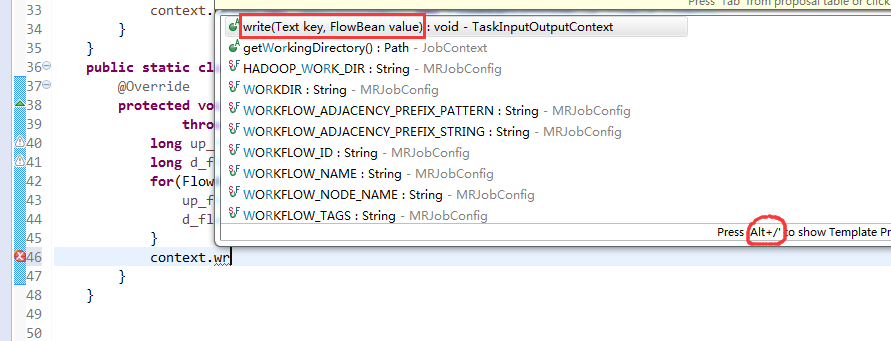
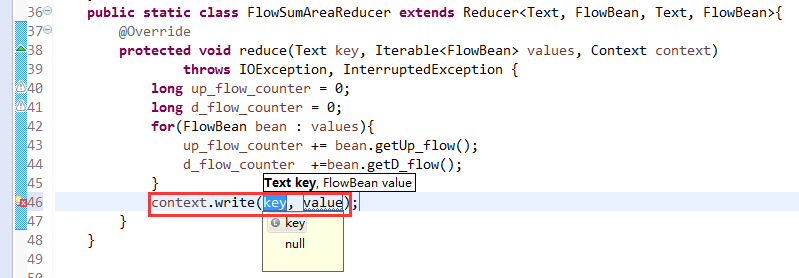

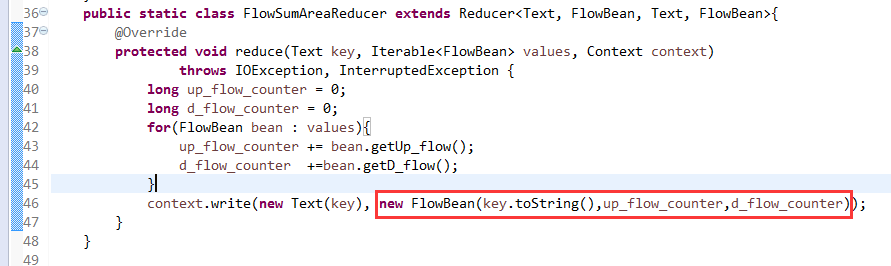
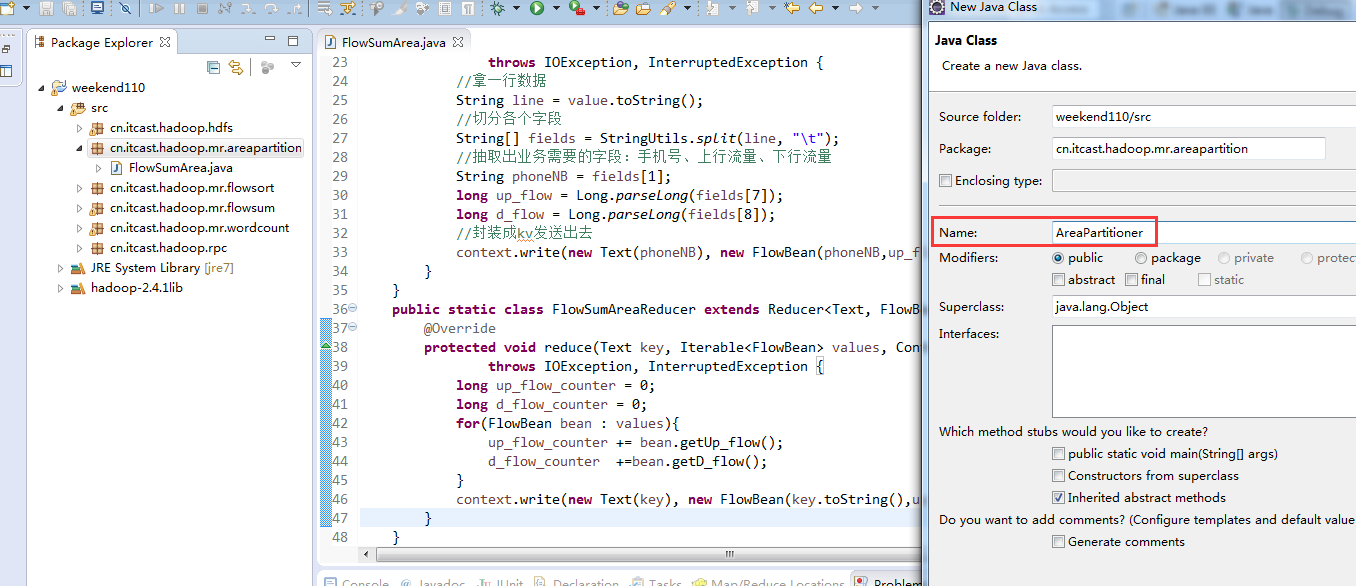
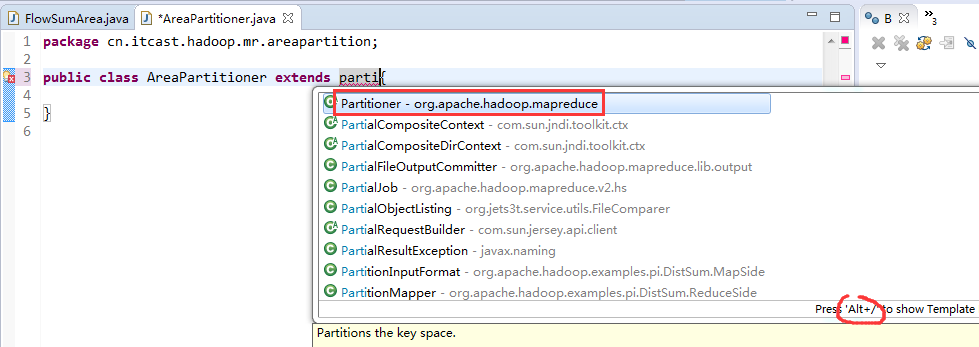
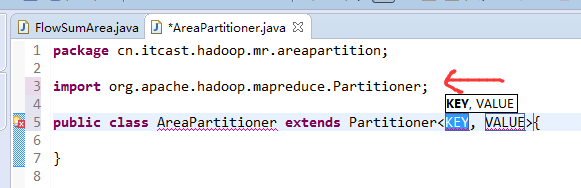
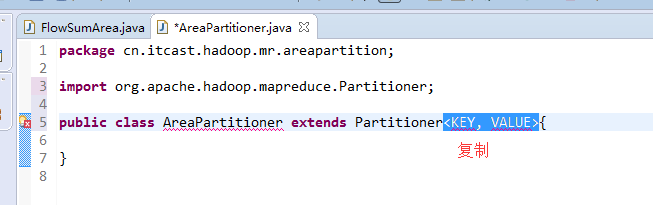
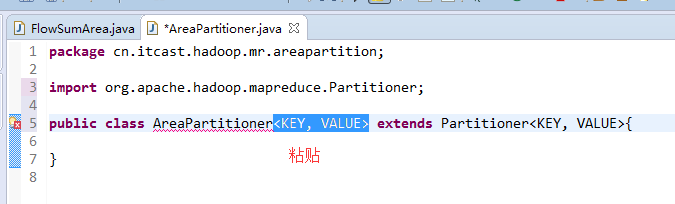
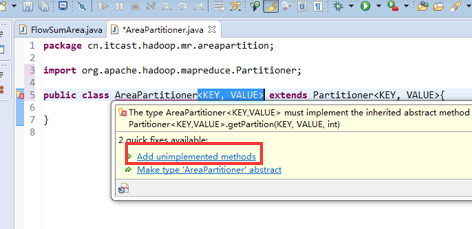
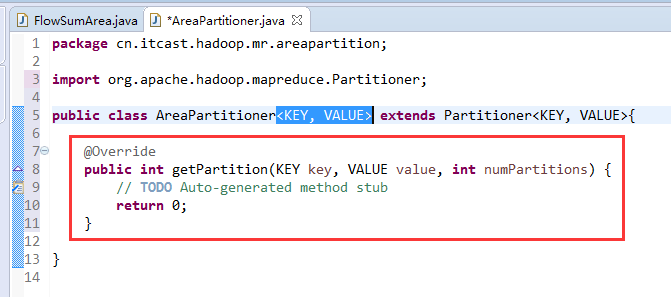
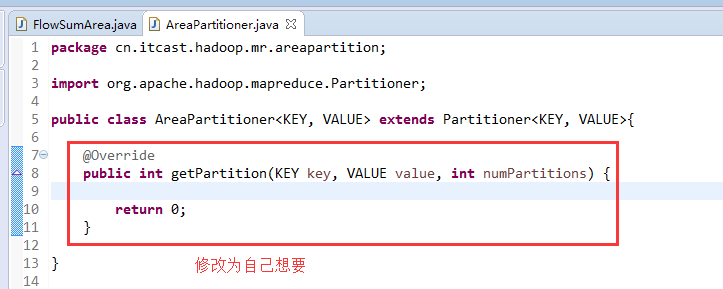

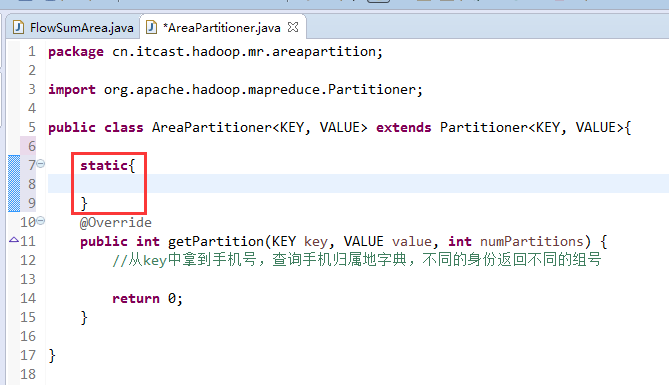
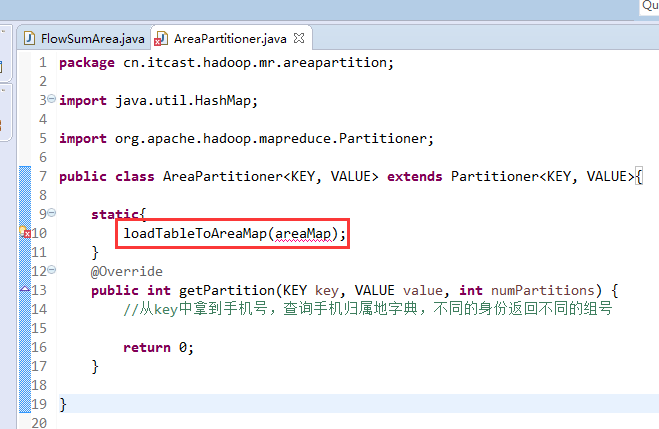



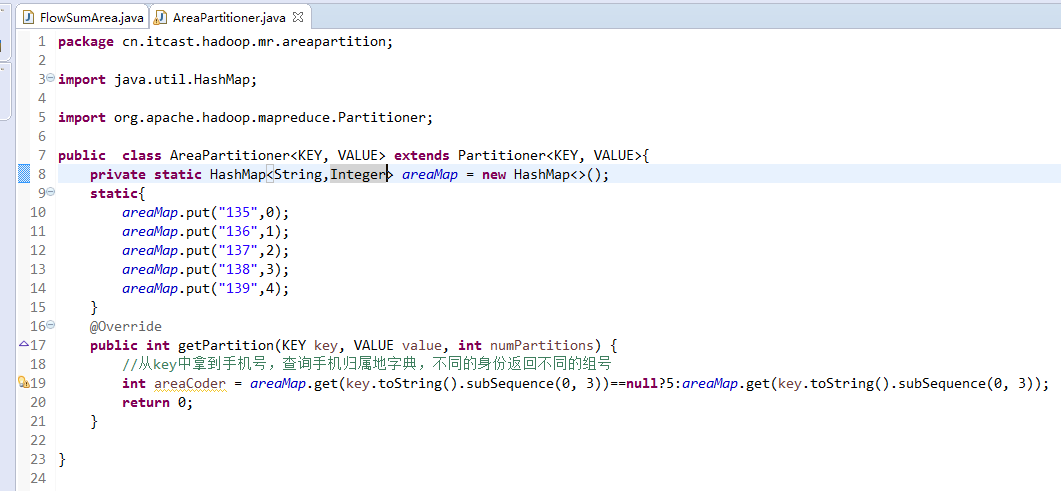
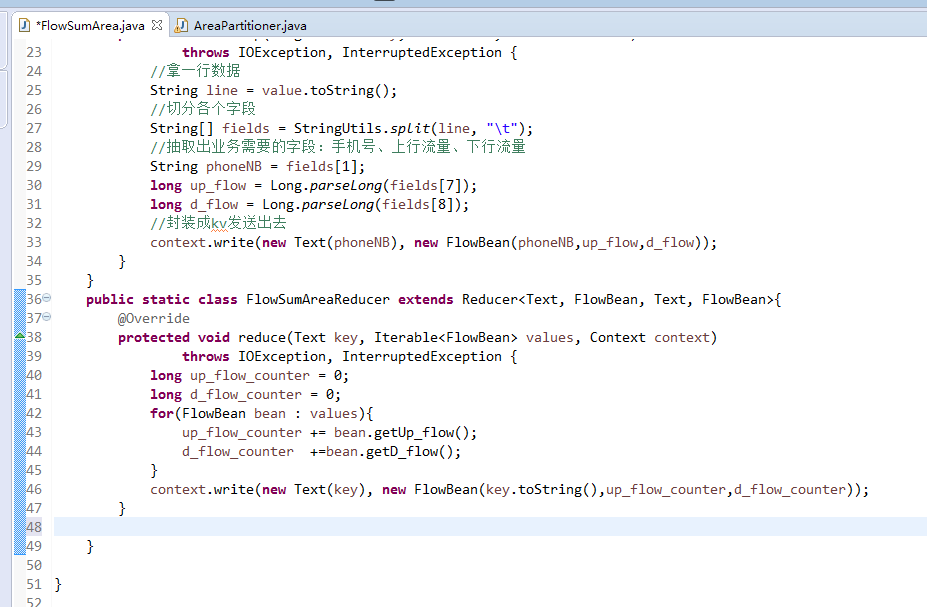
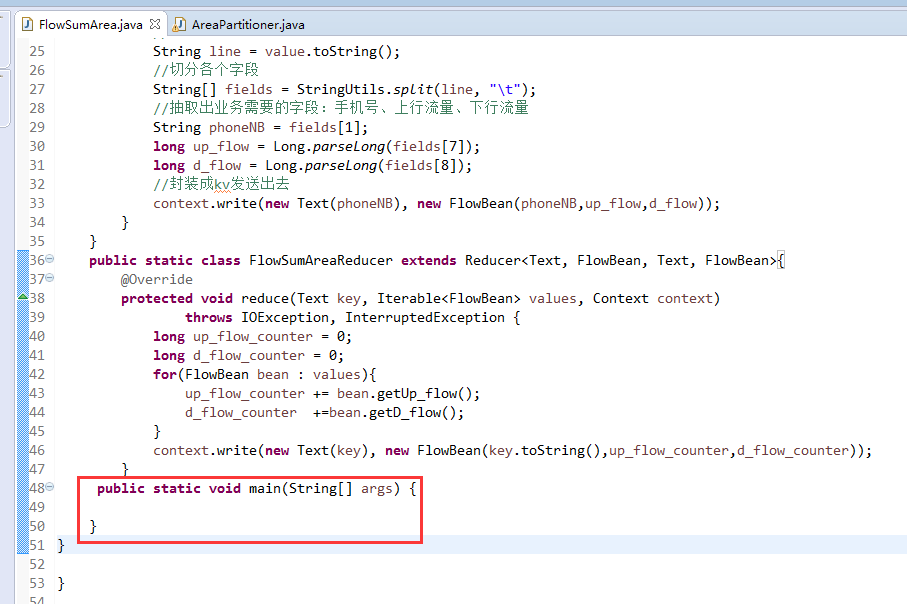









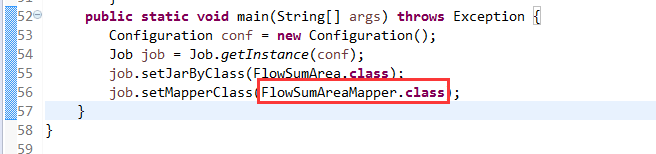
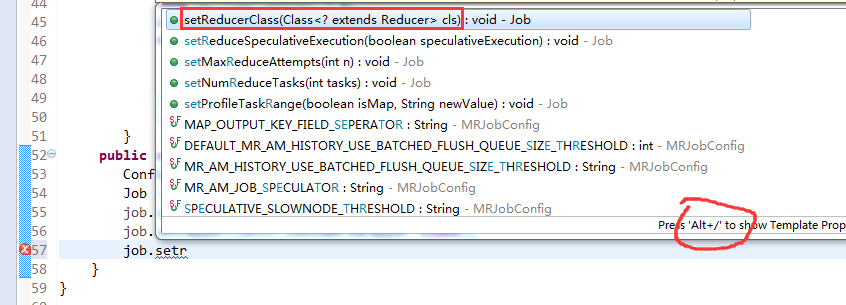
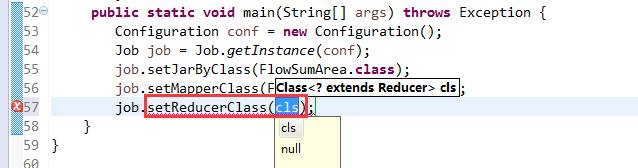
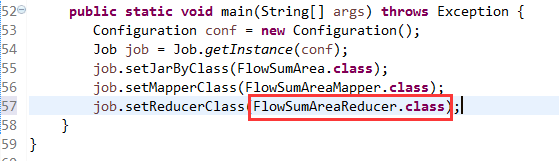
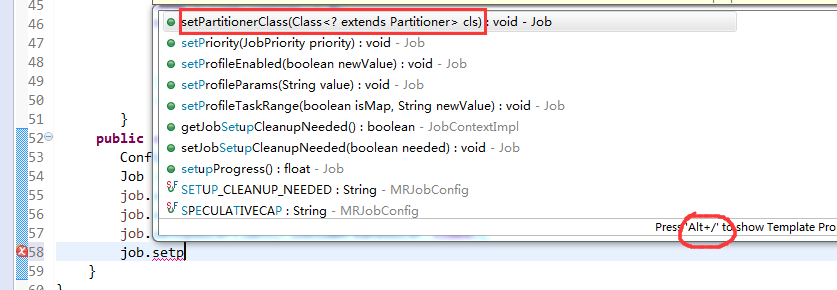
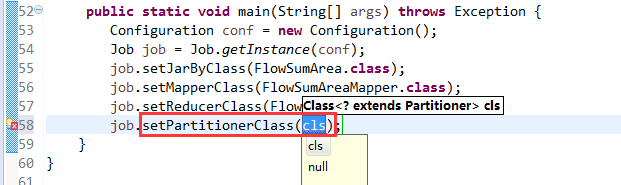
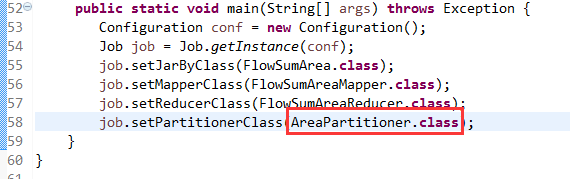


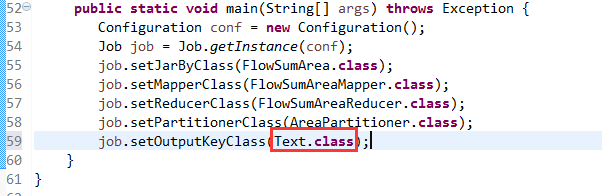
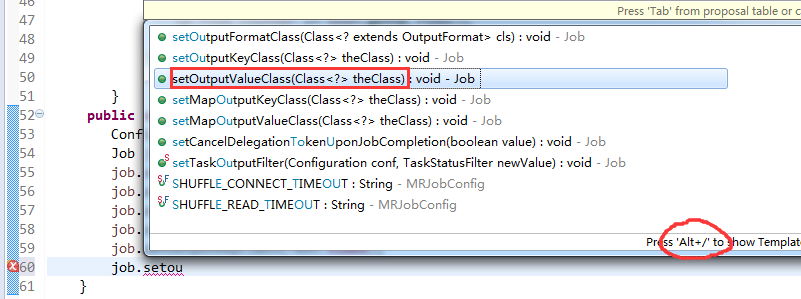
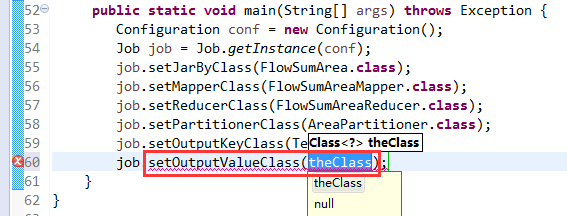
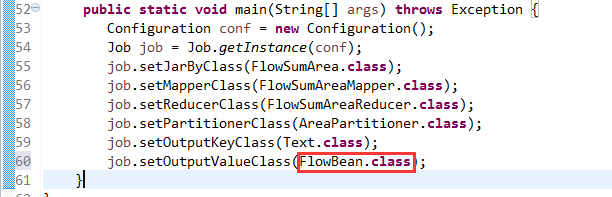
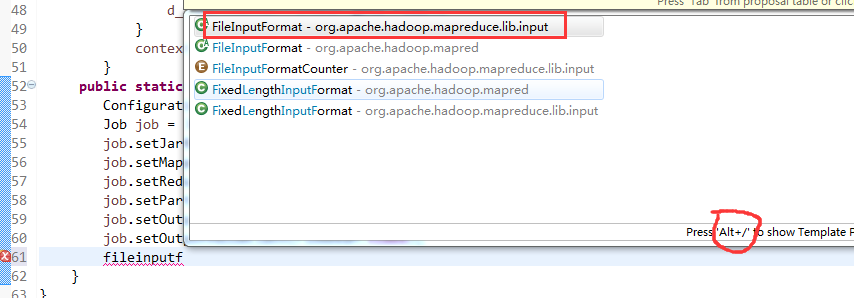
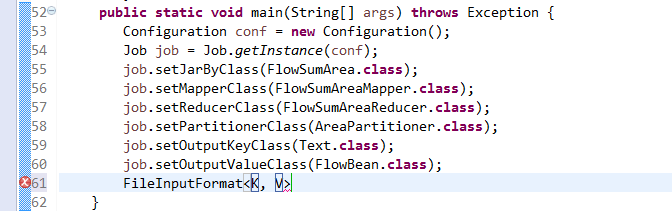

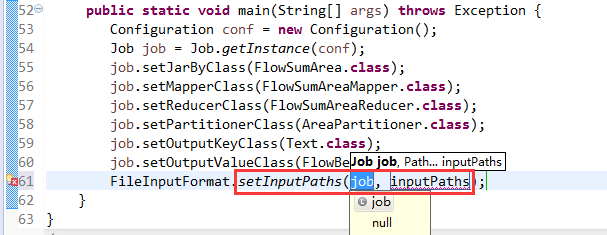
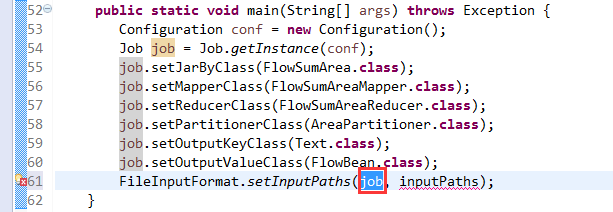

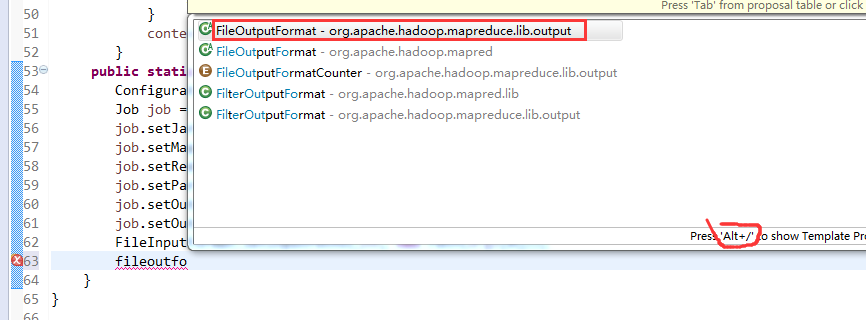


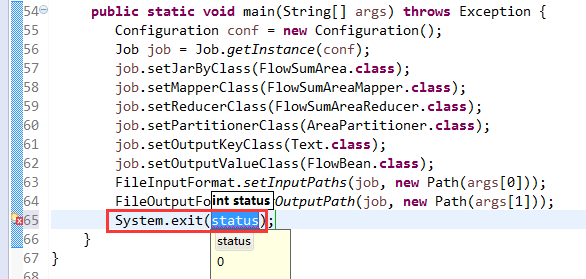
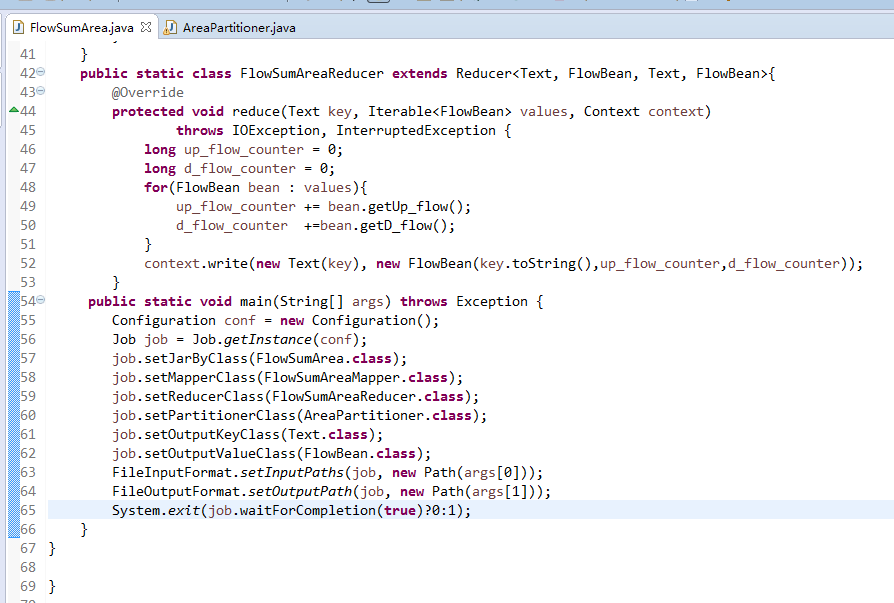

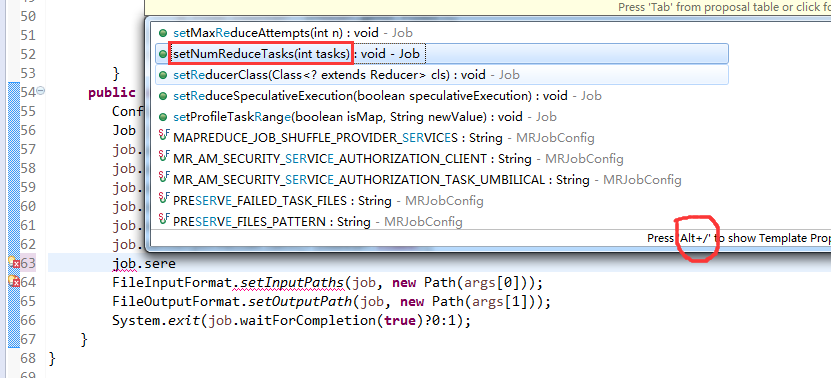
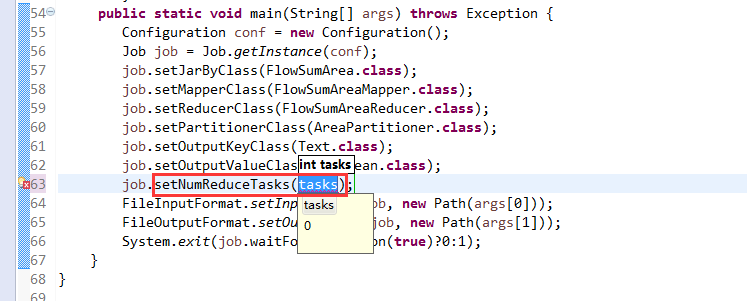
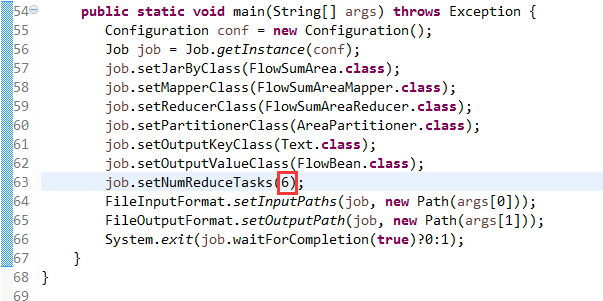
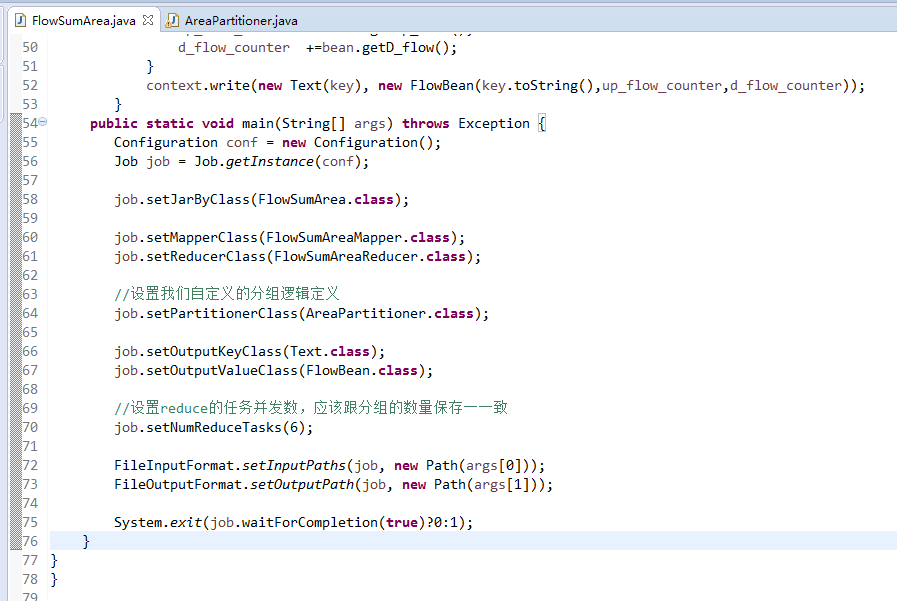

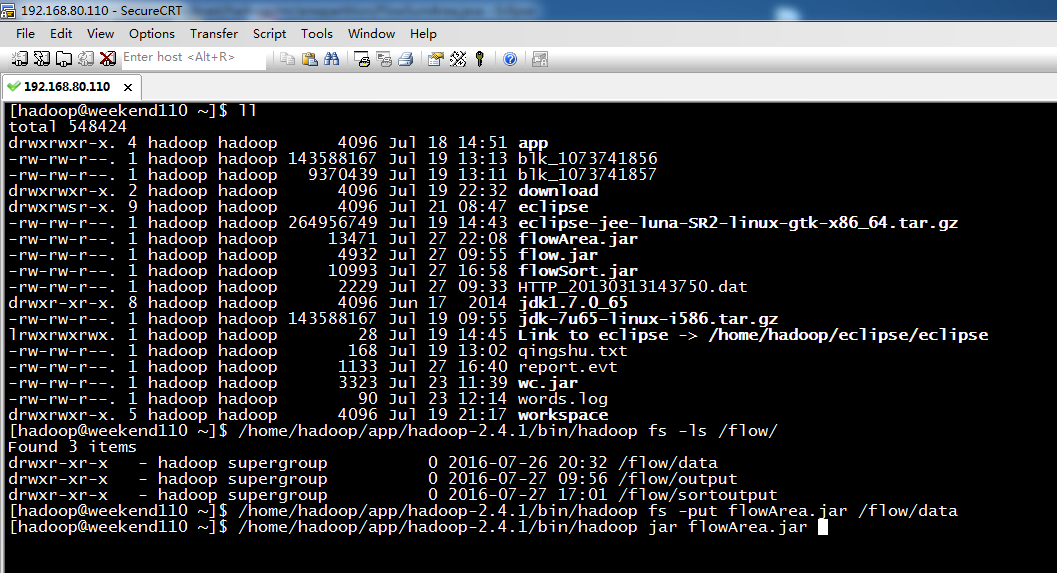
[hadoop@weekend110 ~]$ /home/hadoop/app/hadoop-2.4.1/bin/hadoop jar flowArea.jar cn.itcast.hadoop.mr.areapartition.FlowSumArea /flow/data /flow/areaoutput


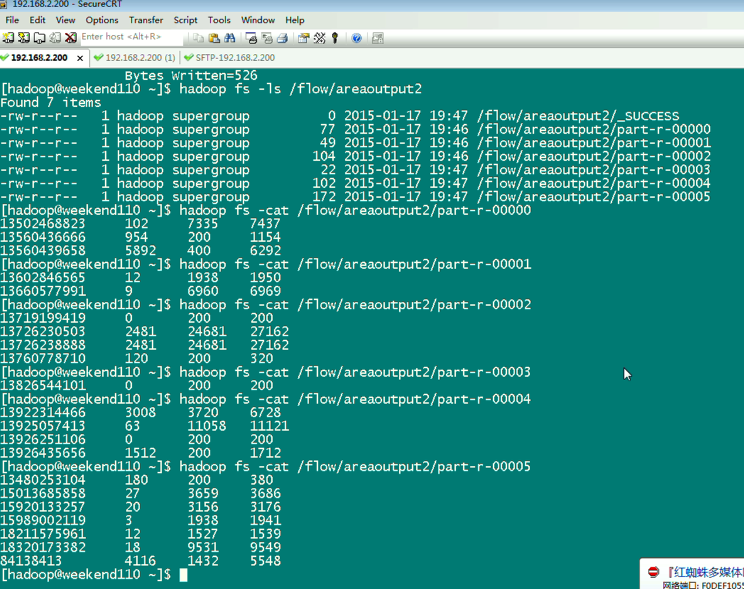
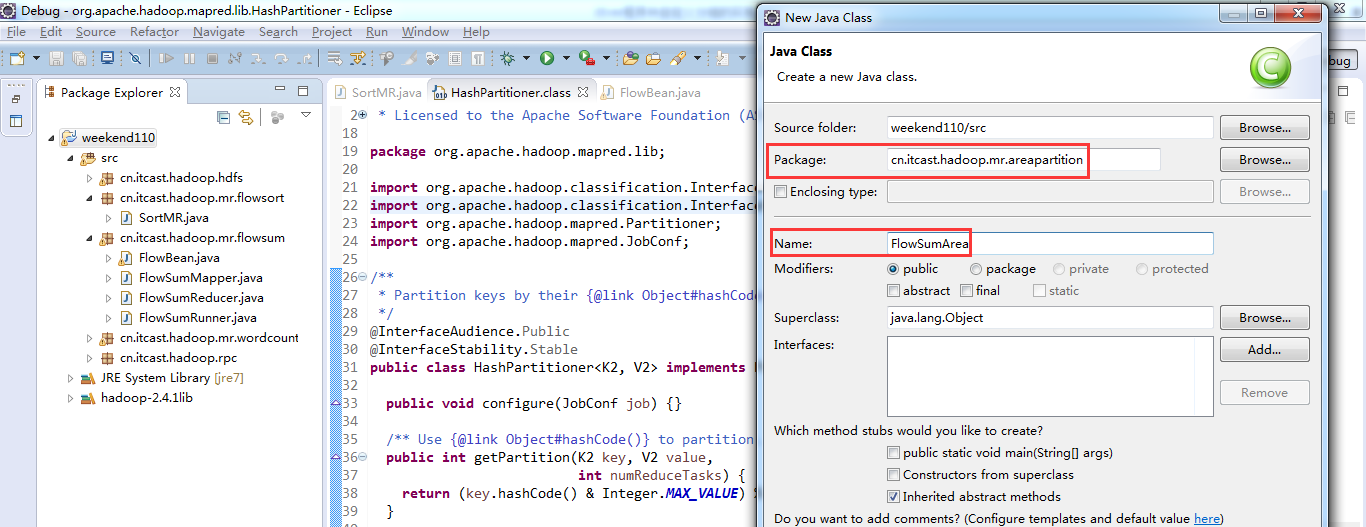
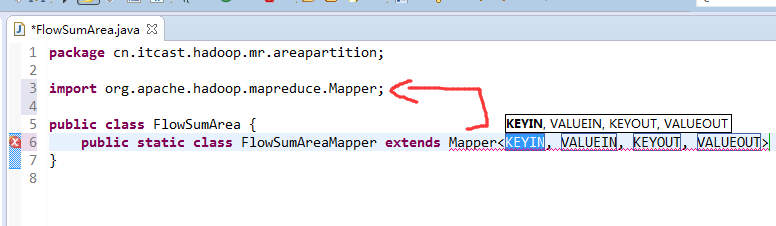
以上是weekend110的mr程序中自定义分组的实现
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5896772.html,如需转载请自行联系原作者