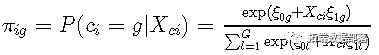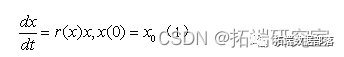热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
Python的装饰器
R语言用潜类别混合效应模型(Latent Class Mixed Model ,LCMM)分析老年痴呆年龄数据
数据分享|R语言用logistic逻辑回归和AFRIMA、ARIMA时间序列模型预测世界人口
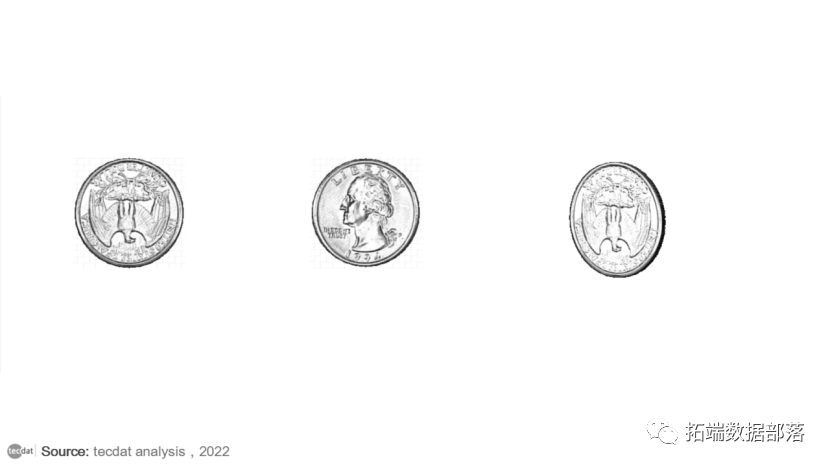
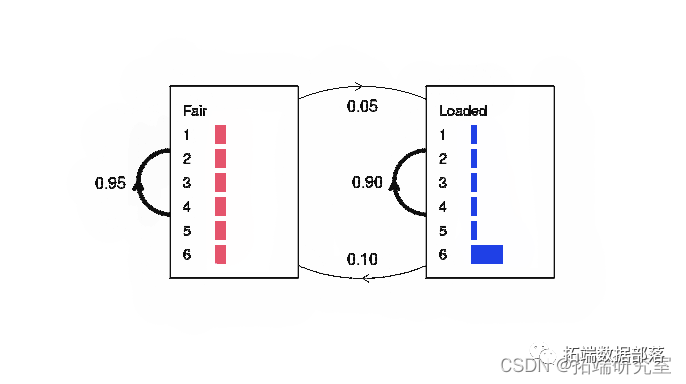
【视频】马尔可夫链蒙特卡罗方法MCMC原理与R语言实现|数据分享(下)
【视频】马尔可夫链蒙特卡罗方法MCMC原理与R语言实现|数据分享(上)
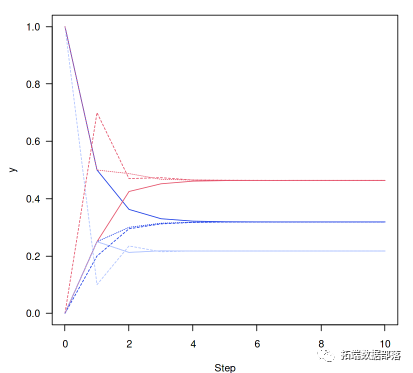
数据分享|数据探索电商平台用户行为流失可视化分析
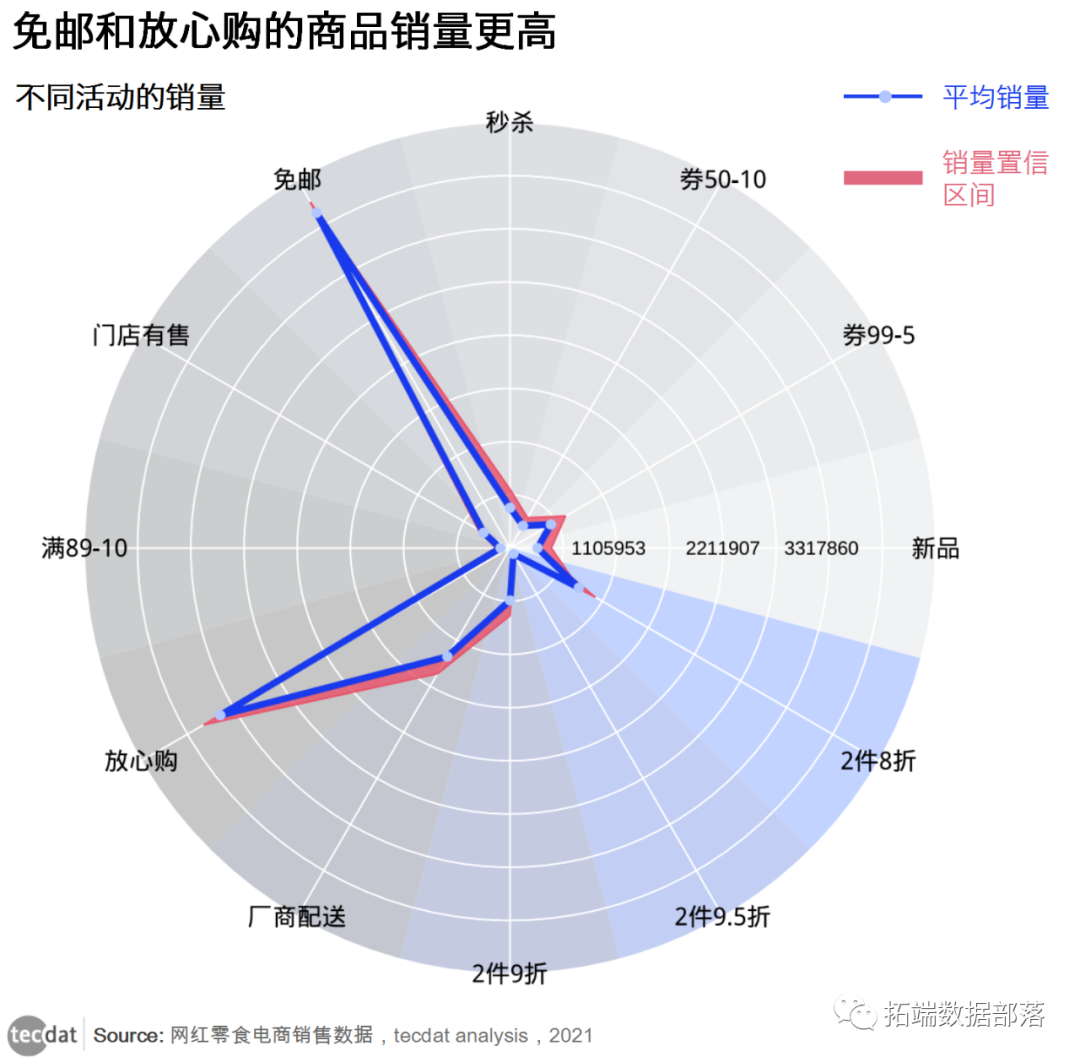
电商平台数据可视化分析网红零食销量
R语言线性回归模型拟合诊断异常值分析家庭燃气消耗量和卡路里实例带自测题
数据分享|R语言GLM广义线性模型:逻辑回归、泊松回归拟合小鼠临床试验数据(剂量和反应)示例和自测题
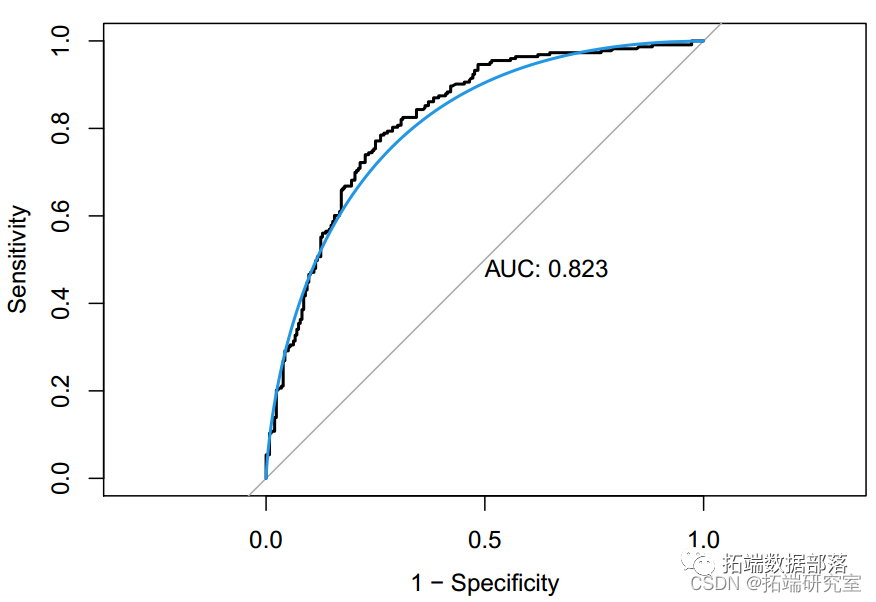
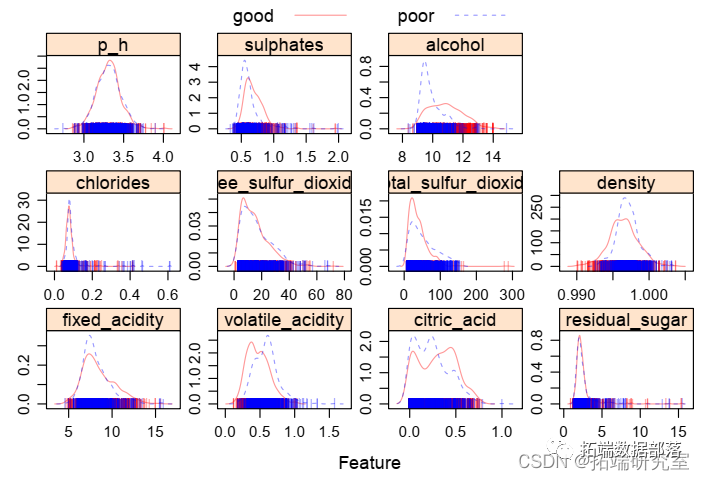
数据分享|R语言逻辑回归、线性判别分析LDA、GAM、MARS、KNN、QDA、决策树、随机森林、SVM分类葡萄酒交叉验证ROC(下)
MySQL 存储引擎
数据分享|R语言逻辑回归、线性判别分析LDA、GAM、MARS、KNN、QDA、决策树、随机森林、SVM分类葡萄酒交叉验证ROC(上)
【视频】马尔可夫链原理可视化解释与R语言区制转换MRS实例|数据分享
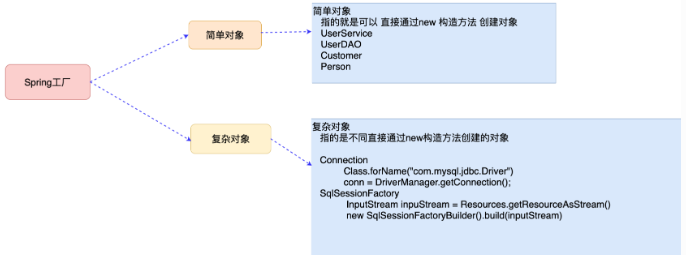
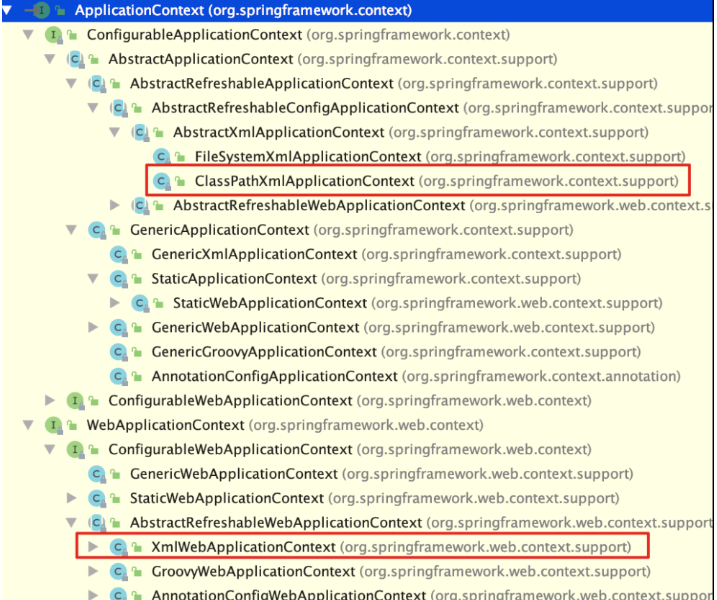
Spring⼯⼚创建复杂对象
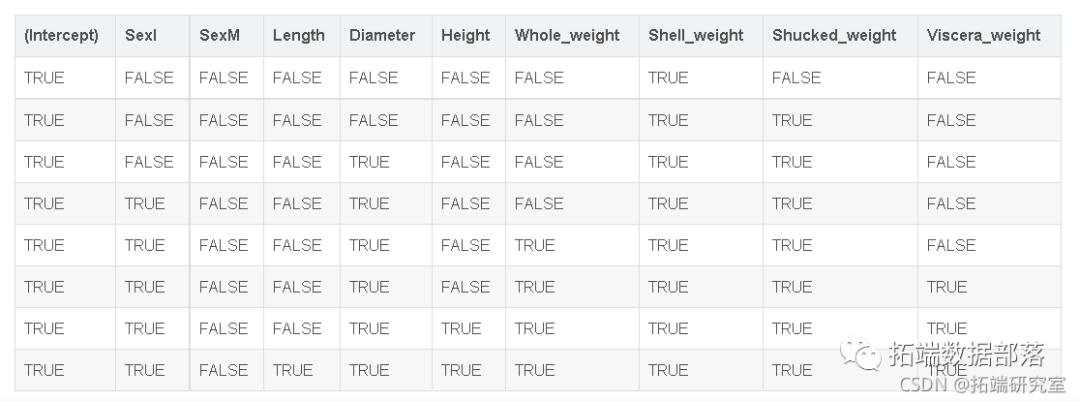
数据分享|用加性多元线性回归、随机森林、弹性网络模型预测鲍鱼年龄和可视化(下)
数据分享|用加性多元线性回归、随机森林、弹性网络模型预测鲍鱼年龄和可视化(中)
数据分享|用加性多元线性回归、随机森林、弹性网络模型预测鲍鱼年龄和可视化(上)
Spring 控制反转与依赖注入
Spring注入
数据分享|PYTHON用ARIMA ,ARIMAX预测商店商品销售需求时间序列数据
Spring工厂API与原理
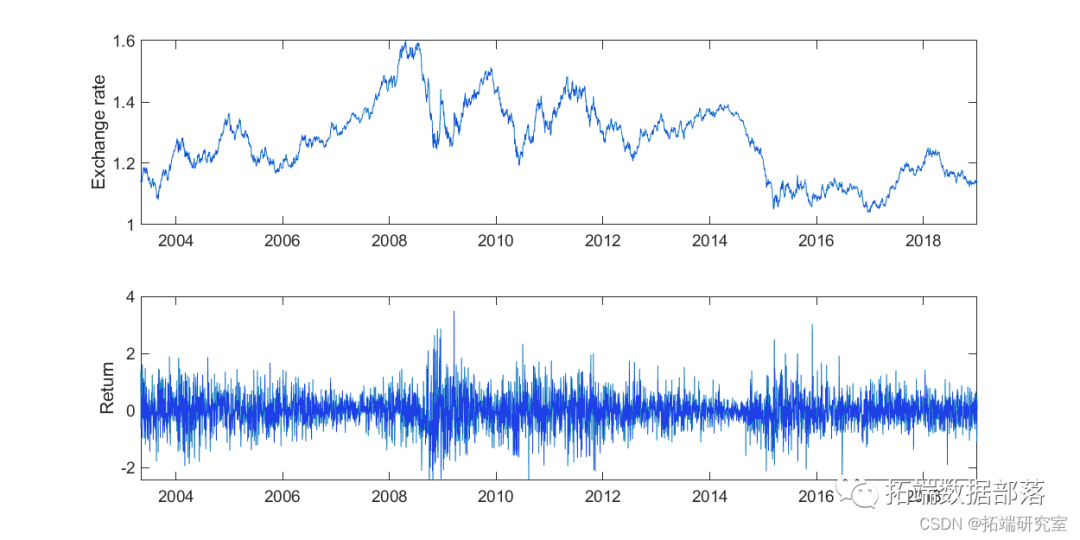
MATLAB随机波动率SV、GARCH用MCMC马尔可夫链蒙特卡罗方法分析汇率时间序列
数据分享|R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
Spring及工厂模式概述
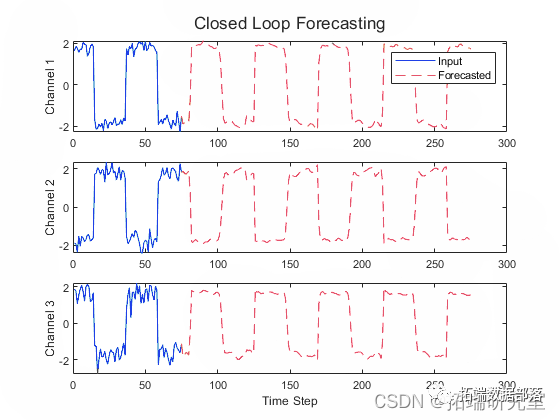
Matlab用深度学习循环神经网络RNN长短期记忆LSTM进行波形时间序列数据预测
Python用MCMC马尔科夫链蒙特卡洛、拒绝抽样和Metropolis-Hastings采样算法
JavaSE&多线程&线程池
xiaodisec day032
xiaodisec day031
xiaodisec day029
xiaodisec day028
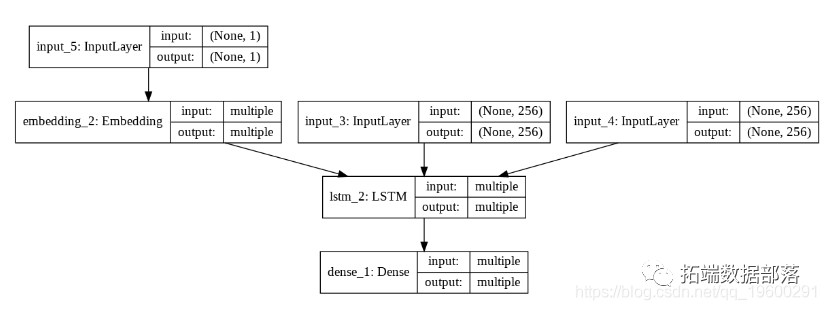
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
xiaodisec day027
xiaodisec day026
xiaodisec day025
xiaodisec day024
xiaodisec day023
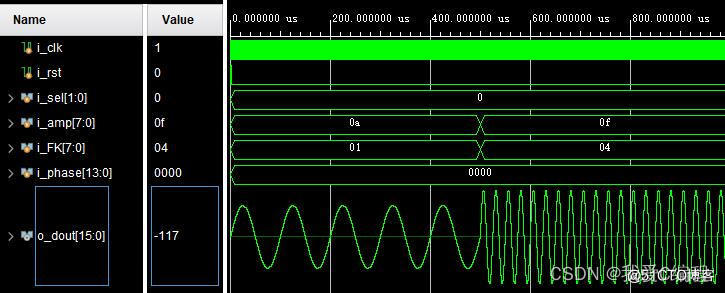
m基于FPGA的多功能信号发生器verilog实现,包含testbench,可以调整波形类型,幅度,频率,初始相位等
xiaodisec day22
【视频】R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险|数据分享
高分通过Kubernetes/k8s CKS认证考试!
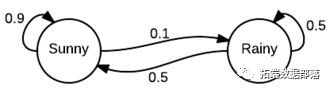
R语言用隐马尔可夫Profile HMM模型进行生物序列分析和模拟可视化
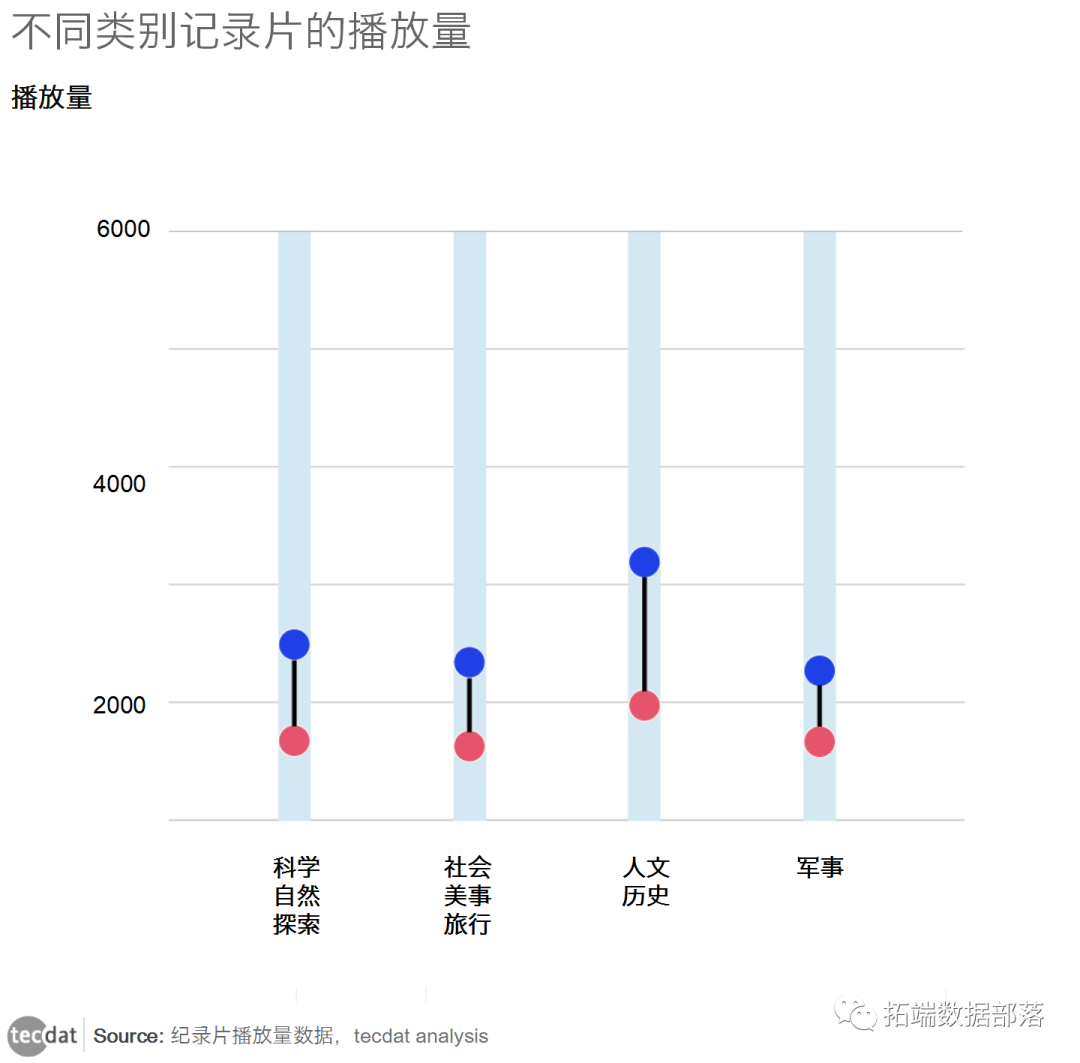
回归树模型分析纪录片播放量影响因素|数据分享
Matlab用向量误差修正VECM模型蒙特卡洛Monte Carlo预测债券利率时间序列和MMSE 预测
【Redis系列笔记】Redis集群
BigDecimal 详解