一、自定义拦截器类型必须是:类全名$内部类名,其实就是内部类名称
如:zhouls.bigdata.MySearchAndReplaceInterceptor$Builder
二、为什么这样写
至于为什么这样写:是因为Interceptor接口还有一个 公共的内部接口(Builder) ,所以自定义拦截器 要是实现 Builder接口,
也就是实现一个内部类(该内部类的主要作用是:获取flume-conf.properties 自定义的 参数,并将参数传递给 自定义拦截器)
三、
本人知识有限,可能描述的不太清楚,可自行了解 java接口与内部类
由于有时候内置的拦截器不够用,所以需要针对特殊的业务需求自定义拦截器。
官方文档中没有发现自定义interceptor的步骤,但是可以根据flume源码参考内置的拦截器的代码
flume-1.7/flume-ng-core/src/main/java/org/apache/flume/interceptor/***Iterceptor.java
无论,是flume的自带拦截器,还是,flume的自定义拦截器,我这篇博文呢,是想给大家,去规范和方便化!!!
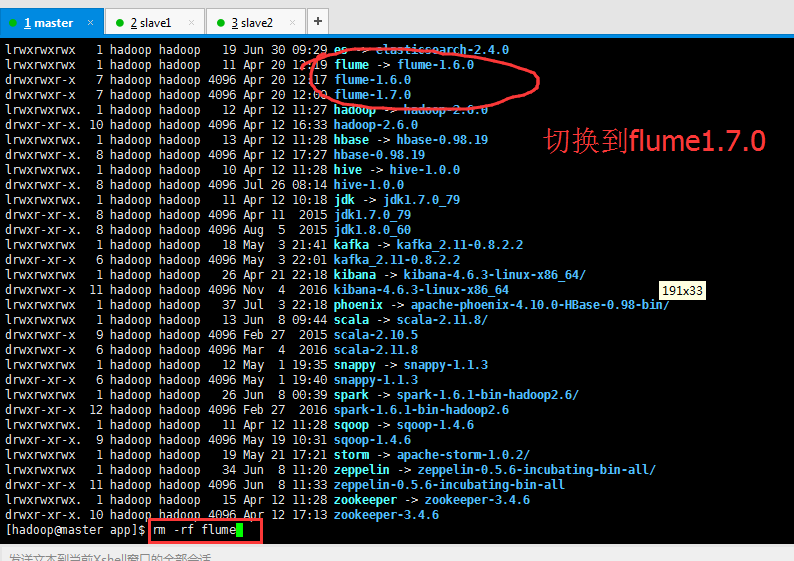
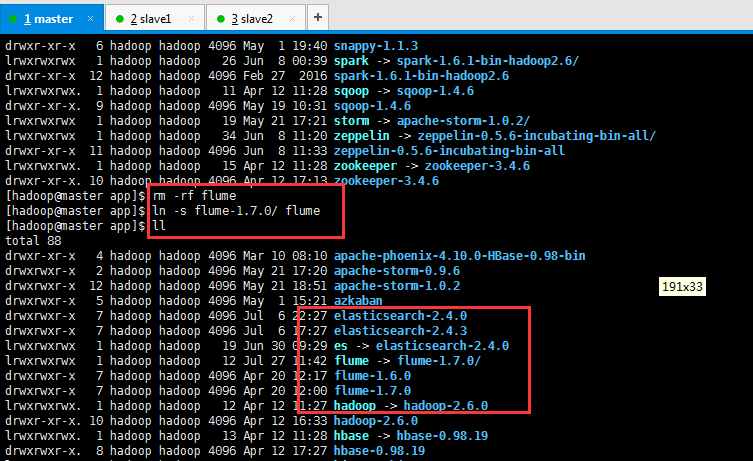

[hadoop@master app]$ rm -rf flume [hadoop@master app]$ ln -s flume-1.7.0/ flume [hadoop@master app]$ ll lrwxrwxrwx 1 hadoop hadoop 12 Jul 27 11:42 flume -> flume-1.7.0/ drwxrwxr-x 7 hadoop hadoop 4096 Apr 20 12:17 flume-1.6.0 drwxrwxr-x 7 hadoop hadoop 4096 Apr 20 12:00 flume-1.7.0

Host Interceptor的应用场景是,将同一主机或服务器上的数据flume在一起。
Regex Extractor Iterceptor的应用场景是,
这里,教大家一个非常实用的技巧,
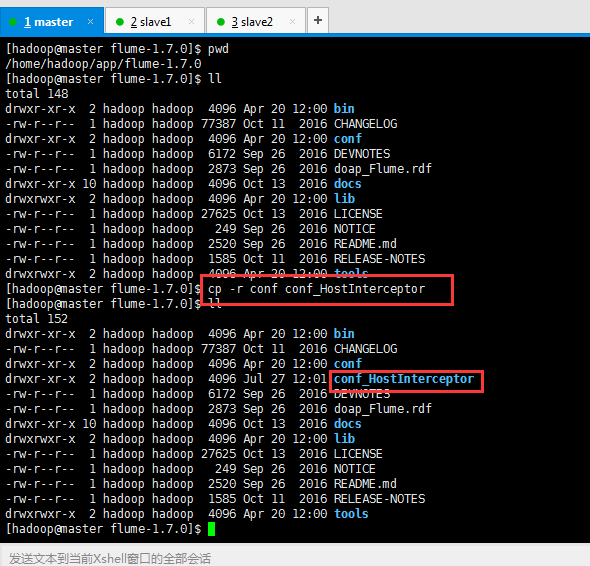

[hadoop@master flume-1.7.0]$ pwd
/home/hadoop/app/flume-1.7.0
[hadoop@master flume-1.7.0]$ ll
total 148
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 bin
-rw-r--r-- 1 hadoop hadoop 77387 Oct 11 2016 CHANGELOG
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 conf
-rw-r--r-- 1 hadoop hadoop 6172 Sep 26 2016 DEVNOTES
-rw-r--r-- 1 hadoop hadoop 2873 Sep 26 2016 doap_Flume.rdf
drwxr-xr-x 10 hadoop hadoop 4096 Oct 13 2016 docs
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 lib
-rw-r--r-- 1 hadoop hadoop 27625 Oct 13 2016 LICENSE
-rw-r--r-- 1 hadoop hadoop 249 Sep 26 2016 NOTICE
-rw-r--r-- 1 hadoop hadoop 2520 Sep 26 2016 README.md
-rw-r--r-- 1 hadoop hadoop 1585 Oct 11 2016 RELEASE-NOTES
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 tools
[hadoop@master flume-1.7.0]$ cp -r conf conf_HostInterceptor
[hadoop@master flume-1.7.0]$ ll
total 152
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 bin
-rw-r--r-- 1 hadoop hadoop 77387 Oct 11 2016 CHANGELOG
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 conf
drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 11:59 conf_HostInterceptor
-rw-r--r-- 1 hadoop hadoop 6172 Sep 26 2016 DEVNOTES
-rw-r--r-- 1 hadoop hadoop 2873 Sep 26 2016 doap_Flume.rdf
drwxr-xr-x 10 hadoop hadoop 4096 Oct 13 2016 docs
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 lib
-rw-r--r-- 1 hadoop hadoop 27625 Oct 13 2016 LICENSE
-rw-r--r-- 1 hadoop hadoop 249 Sep 26 2016 NOTICE
-rw-r--r-- 1 hadoop hadoop 2520 Sep 26 2016 README.md
-rw-r--r-- 1 hadoop hadoop 1585 Oct 11 2016 RELEASE-NOTES
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 tools
[hadoop@master flume-1.7.0]$
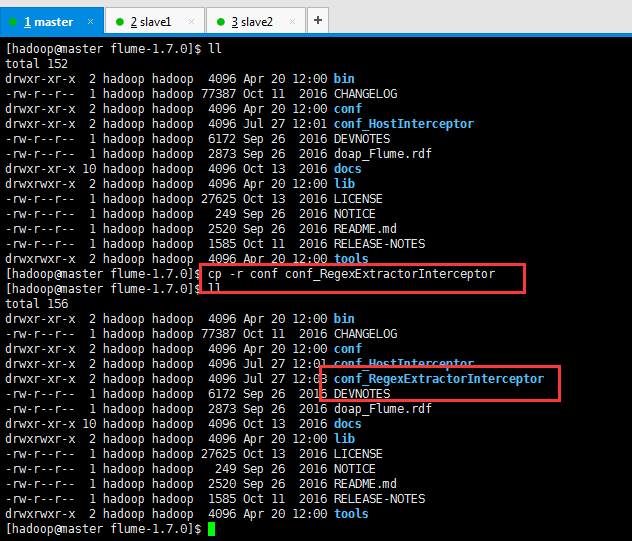
[hadoop@master flume-1.7.0]$ ll
total 152
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 bin
-rw-r--r-- 1 hadoop hadoop 77387 Oct 11 2016 CHANGELOG
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 conf
drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 12:01 conf_HostInterceptor
-rw-r--r-- 1 hadoop hadoop 6172 Sep 26 2016 DEVNOTES
-rw-r--r-- 1 hadoop hadoop 2873 Sep 26 2016 doap_Flume.rdf
drwxr-xr-x 10 hadoop hadoop 4096 Oct 13 2016 docs
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 lib
-rw-r--r-- 1 hadoop hadoop 27625 Oct 13 2016 LICENSE
-rw-r--r-- 1 hadoop hadoop 249 Sep 26 2016 NOTICE
-rw-r--r-- 1 hadoop hadoop 2520 Sep 26 2016 README.md
-rw-r--r-- 1 hadoop hadoop 1585 Oct 11 2016 RELEASE-NOTES
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 tools
[hadoop@master flume-1.7.0]$ cp -r conf conf_RegexExtractorInterceptor
[hadoop@master flume-1.7.0]$ ll
total 156
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 bin
-rw-r--r-- 1 hadoop hadoop 77387 Oct 11 2016 CHANGELOG
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 conf
drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 12:01 conf_HostInterceptor
drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 12:03 conf_RegexExtractorInterceptor
-rw-r--r-- 1 hadoop hadoop 6172 Sep 26 2016 DEVNOTES
-rw-r--r-- 1 hadoop hadoop 2873 Sep 26 2016 doap_Flume.rdf
drwxr-xr-x 10 hadoop hadoop 4096 Oct 13 2016 docs
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 lib
-rw-r--r-- 1 hadoop hadoop 27625 Oct 13 2016 LICENSE
-rw-r--r-- 1 hadoop hadoop 249 Sep 26 2016 NOTICE
-rw-r--r-- 1 hadoop hadoop 2520 Sep 26 2016 README.md
-rw-r--r-- 1 hadoop hadoop 1585 Oct 11 2016 RELEASE-NOTES
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 tools
[hadoop@master flume-1.7.0]$
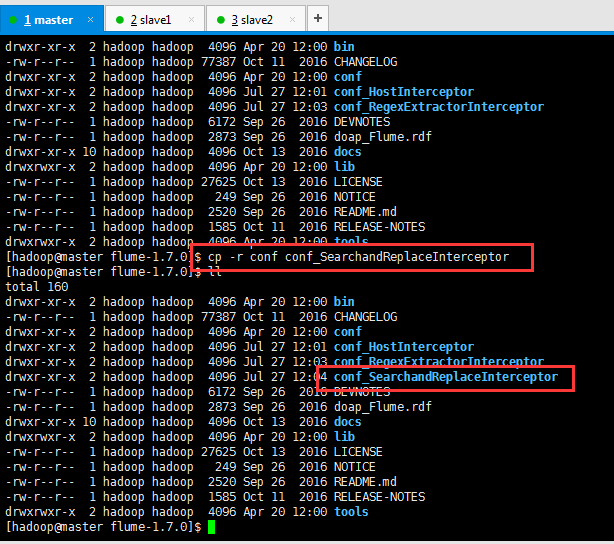
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 bin
-rw-r--r-- 1 hadoop hadoop 77387 Oct 11 2016 CHANGELOG
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 conf
drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 12:01 conf_HostInterceptor
drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 12:03 conf_RegexExtractorInterceptor
-rw-r--r-- 1 hadoop hadoop 6172 Sep 26 2016 DEVNOTES
-rw-r--r-- 1 hadoop hadoop 2873 Sep 26 2016 doap_Flume.rdf
drwxr-xr-x 10 hadoop hadoop 4096 Oct 13 2016 docs
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 lib
-rw-r--r-- 1 hadoop hadoop 27625 Oct 13 2016 LICENSE
-rw-r--r-- 1 hadoop hadoop 249 Sep 26 2016 NOTICE
-rw-r--r-- 1 hadoop hadoop 2520 Sep 26 2016 README.md
-rw-r--r-- 1 hadoop hadoop 1585 Oct 11 2016 RELEASE-NOTES
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 tools
[hadoop@master flume-1.7.0]$ cp -r conf conf_SearchandReplaceInterceptor
[hadoop@master flume-1.7.0]$ ll
total 160
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 bin
-rw-r--r-- 1 hadoop hadoop 77387 Oct 11 2016 CHANGELOG
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 conf
drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 12:01 conf_HostInterceptor
drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 12:03 conf_RegexExtractorInterceptor
drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 12:04 conf_SearchandReplaceInterceptor
-rw-r--r-- 1 hadoop hadoop 6172 Sep 26 2016 DEVNOTES
-rw-r--r-- 1 hadoop hadoop 2873 Sep 26 2016 doap_Flume.rdf
drwxr-xr-x 10 hadoop hadoop 4096 Oct 13 2016 docs
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 lib
-rw-r--r-- 1 hadoop hadoop 27625 Oct 13 2016 LICENSE
-rw-r--r-- 1 hadoop hadoop 249 Sep 26 2016 NOTICE
-rw-r--r-- 1 hadoop hadoop 2520 Sep 26 2016 README.md
-rw-r--r-- 1 hadoop hadoop 1585 Oct 11 2016 RELEASE-NOTES
drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 tools
[hadoop@master flume-1.7.0]$
大家,想必,很想问,为什么要这么cp复制出来呢?如flume的以下3种重要的自带拦截器???
cp -r conf conf_HostInterceptor cp -r conf conf_SearchandReplaceInterceptor cp -r conf conf_RegexExtractorInterceptor
你想啊,若不复制的话,则我们在使用时,则会不方便管理。尤其是,见如下,共用同一个log4j.properties,日志排查起来一点都不方便!!!
而,现在是

这样做下来,就是非常的方便和正规。
同时,大家,还要如下更改下
[hadoop@master conf_HostInterceptor]$ pwd /home/hadoop/app/flume-1.7.0/conf_HostInterceptor [hadoop@master conf_HostInterceptor]$ ll total 16 -rw-r--r-- 1 hadoop hadoop 1661 Jul 27 12:01 flume-conf.properties.template -rw-r--r-- 1 hadoop hadoop 1455 Jul 27 12:01 flume-env.ps1.template -rw-r--r-- 1 hadoop hadoop 1565 Jul 27 12:01 flume-env.sh.template -rw-r--r-- 1 hadoop hadoop 3107 Jul 27 12:01 log4j.properties [hadoop@master conf_HostInterceptor]$ mv flume-conf.properties.template flume-conf.properties [hadoop@master conf_HostInterceptor]$ vim log4j.properties
#flume.root.logger=DEBUG,console flume.root.logger=INFO,LOGFILE flume.log.dir=./logs flume.log.file=flume_HostInterceptor.log
同理
[hadoop@master conf_RegexExtractorInterceptor]$ pwd /home/hadoop/app/flume-1.7.0/conf_RegexExtractorInterceptor [hadoop@master conf_RegexExtractorInterceptor]$ ll total 16 -rw-r--r-- 1 hadoop hadoop 1661 Jul 27 12:03 flume-conf.properties.template -rw-r--r-- 1 hadoop hadoop 1455 Jul 27 12:03 flume-env.ps1.template -rw-r--r-- 1 hadoop hadoop 1565 Jul 27 12:03 flume-env.sh.template -rw-r--r-- 1 hadoop hadoop 3107 Jul 27 12:03 log4j.properties [hadoop@master conf_RegexExtractorInterceptor]$ mv flume-conf.properties.template flume-conf.properties [hadoop@master conf_RegexExtractorInterceptor]$ vim log4j.properties
#flume.root.logger=DEBUG,console flume.root.logger=INFO,LOGFILE flume.log.dir=./logs flume.log.file=flume_RegexExtractorInterceptor.log
同理
[hadoop@master conf_SearchandReplaceInterceptor]$ pwd /home/hadoop/app/flume-1.7.0/conf_SearchandReplaceInterceptor [hadoop@master conf_SearchandReplaceInterceptor]$ ll total 16 -rw-r--r-- 1 hadoop hadoop 1661 Jul 27 12:04 flume-conf.properties.template -rw-r--r-- 1 hadoop hadoop 1455 Jul 27 12:04 flume-env.ps1.template -rw-r--r-- 1 hadoop hadoop 1565 Jul 27 12:04 flume-env.sh.template -rw-r--r-- 1 hadoop hadoop 3107 Jul 27 12:04 log4j.properties [hadoop@master conf_SearchandReplaceInterceptor]$ mv flume-conf.properties.template flume-conf.properties [hadoop@master conf_SearchandReplaceInterceptor]$ vim log4j.properties
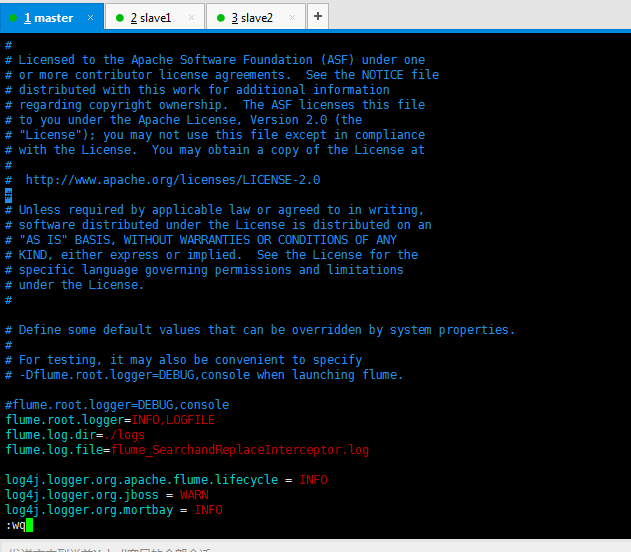
#flume.root.logger=DEBUG,console flume.root.logger=INFO,LOGFILE flume.log.dir=./logs flume.log.file=flume_SearchandReplaceInterceptor.log
Host Interceptor
conf_HostInterceptor的flume-conf.properties
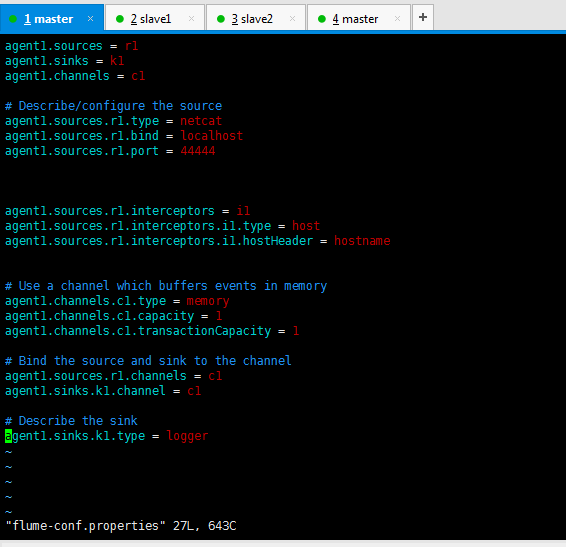
agent1.sources = r1 agent1.sinks = k1 agent1.channels = c1 # Describe/configure the source agent1.sources.r1.type = netcat agent1.sources.r1.bind = localhost agent1.sources.r1.port = 44444 agent1.sources.r1.interceptors = i1 agent1.sources.r1.interceptors.i1.type = host agent1.sources.r1.interceptors.i1.hostHeader = hostname # Use a channel which buffers events in memory agent1.channels.c1.type = memory agent1.channels.c1.capacity = 1 agent1.channels.c1.transactionCapacity = 1 # Bind the source and sink to the channel agent1.sources.r1.channels = c1 agent1.sinks.k1.channel = c1 # Describe the sink agent1.sinks.k1.type = logger
则,注意,启动命令也要发生变化
[hadoop@master flume-1.7.0]$ bin/flume-ng agent --conf conf_HostInterceptor/ --conf-file conf_HostInterceptor/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console
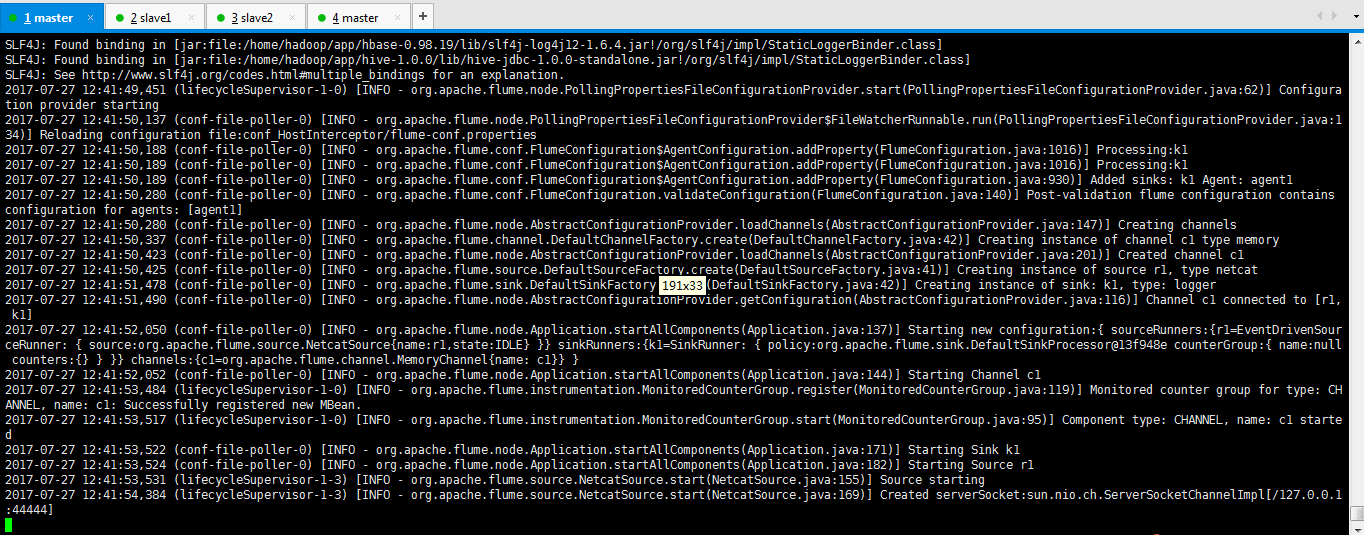
SLF4J: Found binding in [jar:file:/home/hadoop/app/hbase-0.98.19/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/app/hive-1.0.0/lib/hive-jdbc-1.0.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
2017-07-27 12:41:49,451 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:62)] Configuration provider starting
2017-07-27 12:41:50,137 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:134)] Reloading configuration file:conf_HostInterceptor/flume-conf.properties
2017-07-27 12:41:50,188 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1016)] Processing:k1
2017-07-27 12:41:50,189 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1016)] Processing:k1 2017-07-27 12:41:50,189 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:930)] Added sinks: k1 Agent: agent1 2017-07-27 12:41:50,280 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:140)] Post-validation flume configuration contains configuration for agents: [agent1] 2017-07-27 12:41:50,280 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:147)] Creating channels 2017-07-27 12:41:50,337 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel c1 type memory 2017-07-27 12:41:50,423 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:201)] Created channel c1 2017-07-27 12:41:50,425 (conf-file-poller-0) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:41)] Creating instance of source r1, type netcat 2017-07-27 12:41:51,478 (conf-file-poller-0) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:42)] Creating instance of sink: k1, type: logger 2017-07-27 12:41:51,490 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:116)] Channel c1 connected to [r1, k1] 2017-07-27 12:41:52,050 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:137)] Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source:org.apache.flume.source.NetcatSource{name:r1,state:IDLE} }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@13f948e counterGroup:{ name:null counters:{} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} } 2017-07-27 12:41:52,052 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:144)] Starting Channel c1 2017-07-27 12:41:53,484 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean. 2017-07-27 12:41:53,517 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: CHANNEL, name: c1 started 2017-07-27 12:41:53,522 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:171)] Starting Sink k1 2017-07-27 12:41:53,524 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:182)] Starting Source r1 2017-07-27 12:41:53,531 (lifecycleSupervisor-1-3) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:155)] Source starting 2017-07-27 12:41:54,384 (lifecycleSupervisor-1-3) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:169)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
等待数据的采集
[hadoop@master ~]$ yum -y install telnet
Loaded plugins: fastestmirror, refresh-packagekit, security
You need to be root to perform this command.
[hadoop@master ~]$ su root
Password:
[root@master hadoop]# yum -y install telnet
Loaded plugins: fastestmirror, refresh-packagekit, security Loading mirror speeds from cached hostfile * base: mirrors.cqu.edu.cn * extras: mirrors.sohu.com
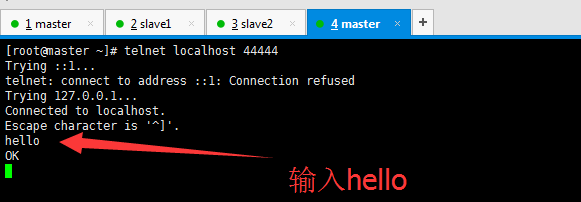
成功地,然后,这边随便输入什么。比如hello
[root@master ~]# telnet localhost 44444
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
hello
OK
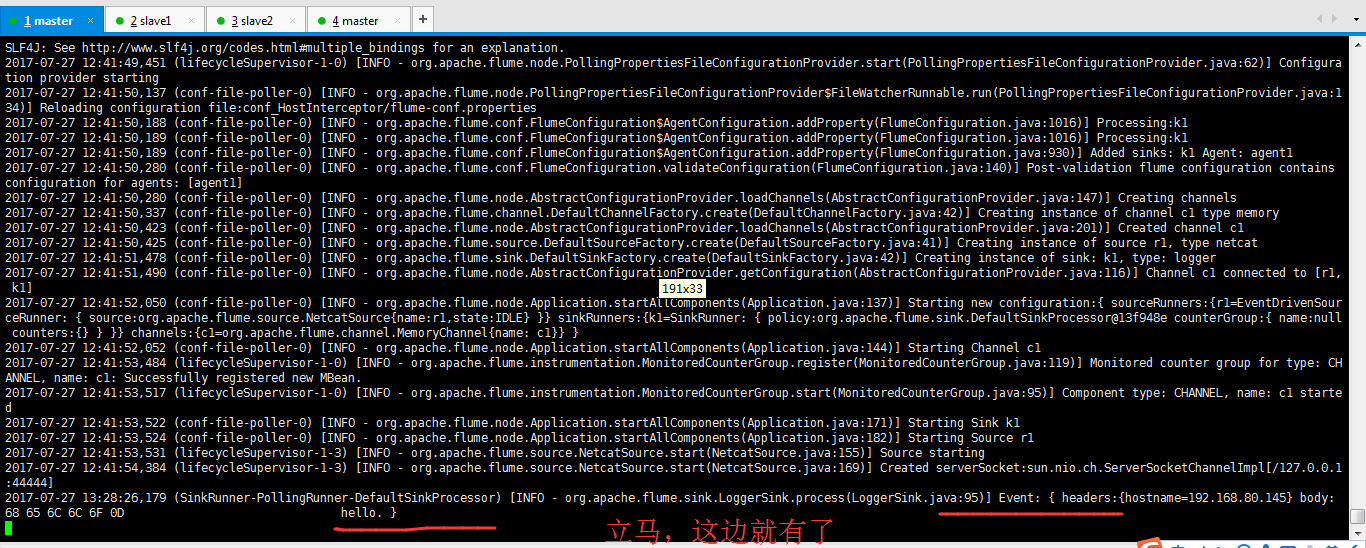
Event: { headers:{hostname=192.168.80.145} body: 68 65 6C 6C 6F 0D hello. }
这就是Host Interceptor的作用体现!
agent1.sources.r1.interceptors = i1
agent1.sources.r1.interceptors.i1.type = host
agent1.sources.r1.interceptors.i1.hostHeader = hostname
若想要如下的效果,则
Event: { headers:{hostname=master} body: 7A 68 6F 75 6C 73 0D zhouls. }
则

agent1.sources = r1 agent1.sinks = k1 agent1.channels = c1 # Describe/configure the source agent1.sources.r1.type = netcat agent1.sources.r1.bind = localhost agent1.sources.r1.port = 44444 agent1.sources.r1.interceptors = i1 agent1.sources.r1.interceptors.i1.type = host agent1.sources.r1.interceptors.i1.useIP = false agent1.sources.r1.interceptors.i1.hostHeader = hostname # Use a channel which buffers events in memory agent1.channels.c1.type = memory agent1.channels.c1.capacity = 1 agent1.channels.c1.transactionCapacity = 1 # Bind the source and sink to the channel agent1.sources.r1.channels = c1 agent1.sinks.k1.channel = c1 # Describe the sink agent1.sinks.k1.type = logger

[hadoop@master flume-1.7.0]$ bin/flume-ng agent --conf conf_HostInterceptor/ --conf-file conf_HostInterceptor/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console

[root@master ~]# telnet localhost 44444 Trying ::1... telnet: connect to address ::1: Connection refused Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. zhouls OK
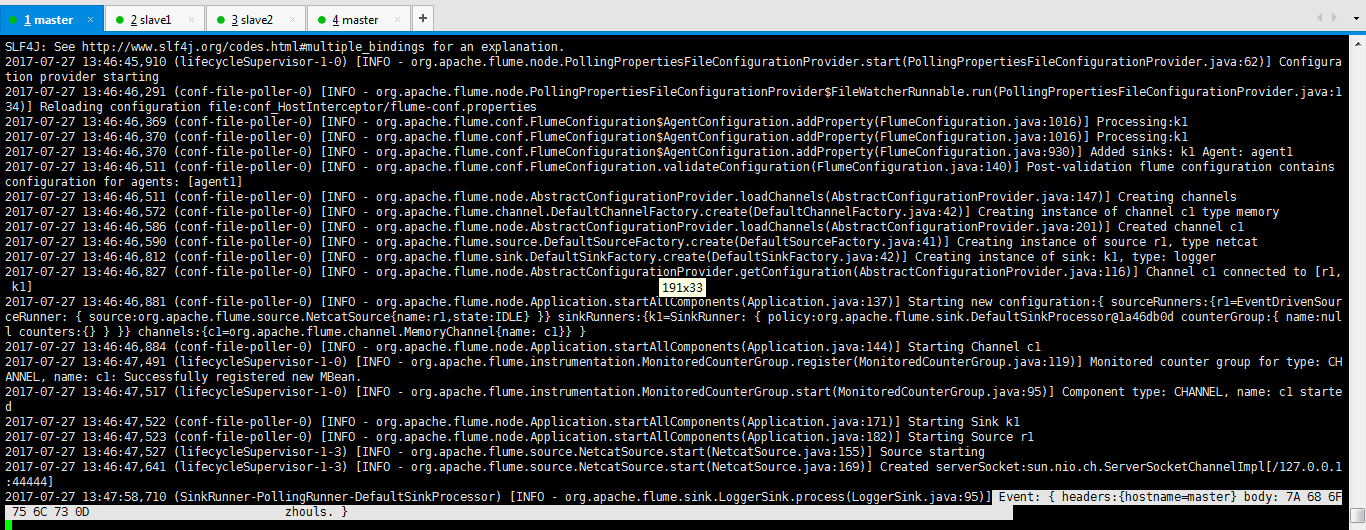
Event: { headers:{hostname=master} body: 7A 68 6F 75 6C 73 0D zhouls. }
Regex Extractor Interceptor(正则抽取拦截器)
conf_RegexExtractorInterceptor的flume-conf.properties
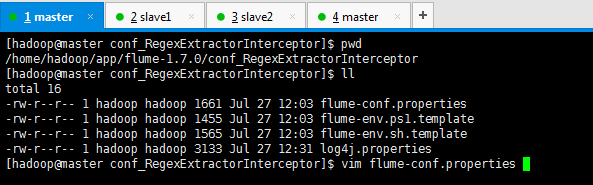
[hadoop@master conf_RegexExtractorInterceptor]$ pwd /home/hadoop/app/flume-1.7.0/conf_RegexExtractorInterceptor [hadoop@master conf_RegexExtractorInterceptor]$ ll total 16 -rw-r--r-- 1 hadoop hadoop 1661 Jul 27 12:03 flume-conf.properties -rw-r--r-- 1 hadoop hadoop 1455 Jul 27 12:03 flume-env.ps1.template -rw-r--r-- 1 hadoop hadoop 1565 Jul 27 12:03 flume-env.sh.template -rw-r--r-- 1 hadoop hadoop 3133 Jul 27 12:31 log4j.properties [hadoop@master conf_RegexExtractorInterceptor]$ vim flume-conf.properties
首先,我们来说说这个拦截器的应用场景
假设,有如下的flume测试数据
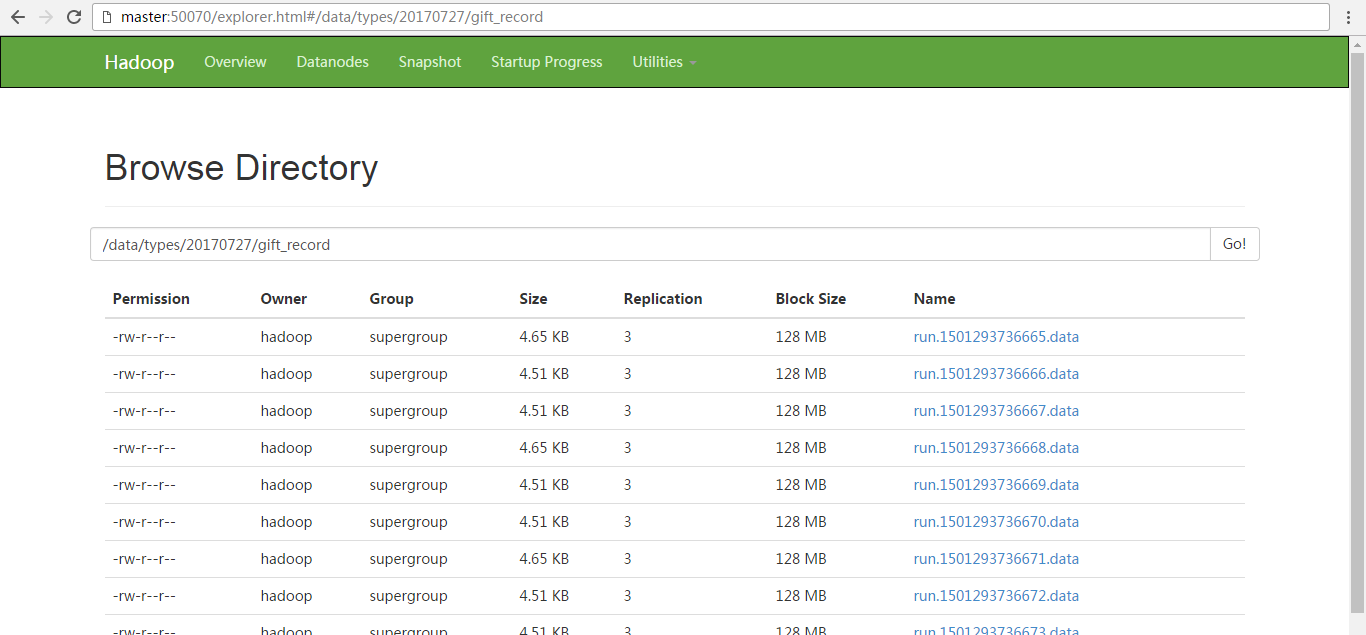
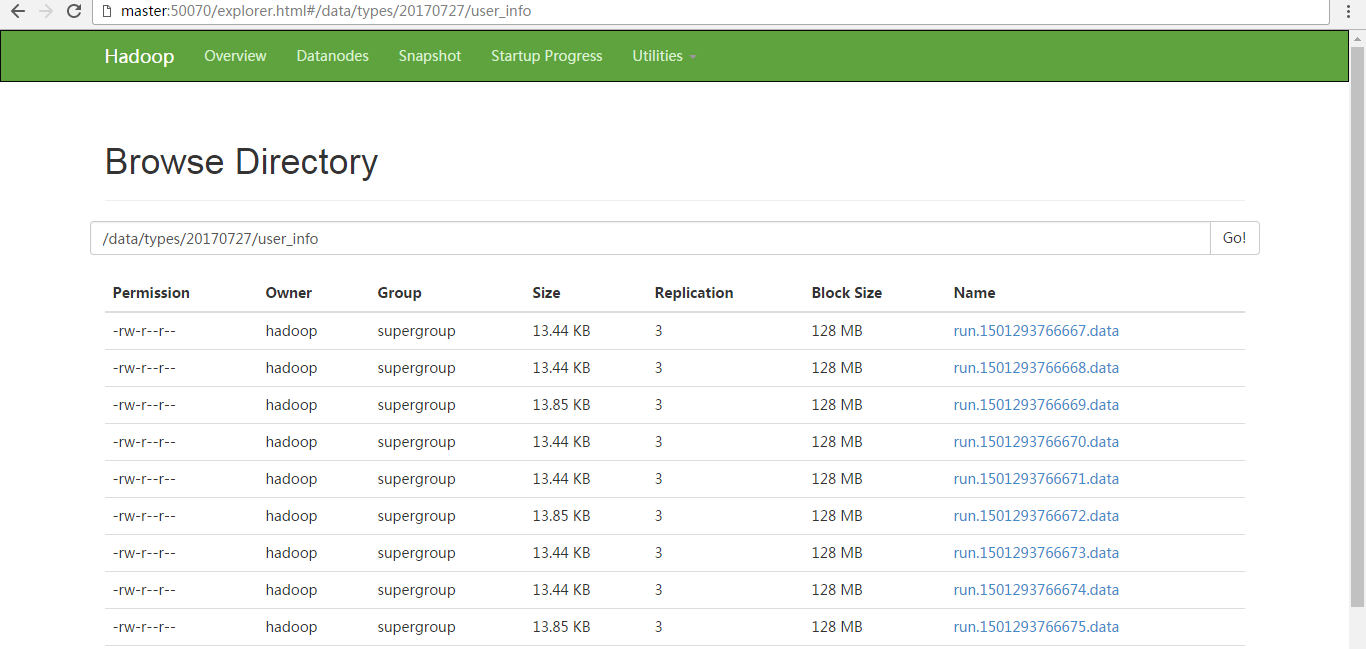
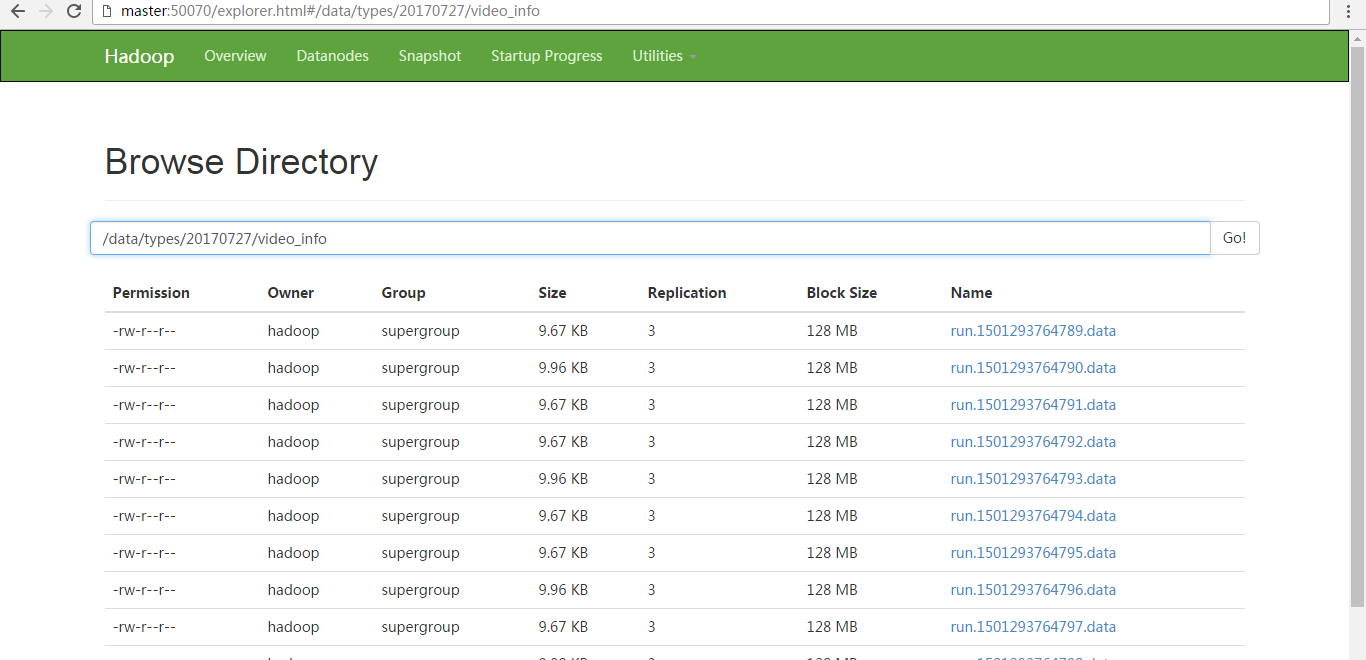
video_info {"id":"14943445328940974601","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hots":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","replay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"} {"id":"14943445328940974602","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hots":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","replay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"} {"id":"14943445328940974603","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hots":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","replay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"} {"id":"14943445328940974604","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hots":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","replay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"} {"id":"14943445328940974605","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hots":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","replay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"} {"id":"14943445328940974606","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hots":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","replay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"} {"id":"14943445328940974607","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hots":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","replay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"} {"id":"14943445328940974608","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hots":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","replay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"} {"id":"14943445328940974609","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hots":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","replay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"} {"id":"14943445328940974610","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hots":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","replay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"} userinfo {"uid":"861848974414839801","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_face":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":"0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"userinfo"} {"uid":"861848974414839802","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_face":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":"0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"userinfo"} {"uid":"861848974414839803","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_face":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":"0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"userinfo"} {"uid":"861848974414839804","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_face":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":"0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"userinfo"} {"uid":"861848974414839805","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_face":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":"0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"userinfo"} {"uid":"861848974414839806","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_face":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":"0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"userinfo"} {"uid":"861848974414839807","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_face":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":"0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"userinfo"} {"uid":"861848974414839808","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_face":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":"0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"userinfo"} {"uid":"861848974414839809","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_face":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":"0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"userinfo"} {"uid":"861848974414839810","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_face":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":"0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"userinfo"} gift_record {"send_id":"834688818270961664","good_id":"223","video_id":"14943443045138661356","gold":"10","timestamp":1494344574,"type":"gift_record"} {"send_id":"829622867955417088","good_id":"72","video_id":"14943429572096925829","gold":"4","timestamp":1494344574,"type":"gift_record"} {"send_id":"827187230564286464","good_id":"193","video_id":"14943394752706070833","gold":"6","timestamp":1494344574,"type":"gift_record"} {"send_id":"829622867955417088","good_id":"80","video_id":"14943429572096925829","gold":"6","timestamp":1494344574,"type":"gift_record"} {"send_id":"799051982152663040","good_id":"72","video_id":"14943435528719800690","gold":"4","timestamp":1494344574,"type":"gift_record"} {"send_id":"848799149716930560","good_id":"72","video_id":"14943435528719800690","gold":"4","timestamp":1494344574,"type":"gift_record"} {"send_id":"775251729037262848","good_id":"777","video_id":"14943390379833490630","gold":"5","timestamp":1494344574,"type":"gift_record"} {"send_id":"835670464000425984","good_id":"238","video_id":"14943428496217015696","gold":"2","timestamp":1494344574,"type":"gift_record"} {"send_id":"834688818270961664","good_id":"223","video_id":"14943443045138661356","gold":"10","timestamp":1494344574,"type":"gift_record"} {"send_id":"834688818270961664","good_id":"223","video_id":"14943443045138661356","gold":"10","timestamp":1494344574,"type":"gift_record"}
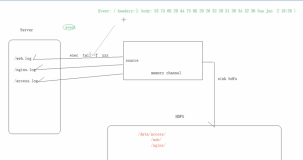
以上是flume采集后的数据。假设都是在这个flume测试数据.txt里,现在呢,我想按照type来存放到不同的目录下。
即video_info的存放到video_info目录下、userinfo的存放到userinfo目录下、gift_record的存放到gift_record目录下。
则,这样的应用场景,即根据数据里内容的type字段的值的不同,来分别存储。则需要Regex Extractor Interceptor派上用场了。
怎么做呢,其实很简单,把type的值,放到
# 定义拦截器 agent1.sources.r1.interceptors = i1 # 设置拦截器类型 agent1.sources.r1.interceptors.i1.type = regex_extractor # 设置正则表达式,匹配指定的数据,这样设置会在数据的header中增加log_type=”对应的值” agent1.sources.r1.interceptors.i1.regex = "type":"(\\w+)" agent1.sources.r1.interceptors.i1.serializers = s1 agent1.sources.r1.interceptors.i1.serializers.s1.name = log_type
为什么是这么来写?
agent1.sources.r1.interceptors.i1.regex = "type":"(\\w+)"
是因为数据的内容决定的。
"type":"video_info" "type":"userinfo" "type":"gift_record"

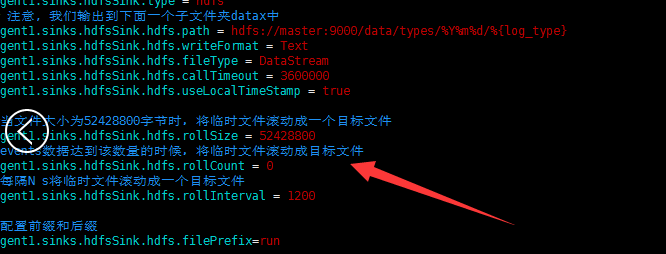
#source的名字 agent1.sources = fileSource # channels的名字,建议按照type来命名 agent1.channels = memoryChannel # sink的名字,建议按照目标来命名 agent1.sinks = hdfsSink # 指定source使用的channel名字 agent1.sources.fileSource.channels = memoryChannel # 指定sink需要使用的channel的名字,注意这里是channel agent1.sinks.hdfsSink.channel = memoryChannel agent1.sources.fileSource.type = exec agent1.sources.fileSource.command = tail -F /usr/local/log/server.log #------- fileChannel-1相关配置------------------------- # channel类型 agent1.channels.memoryChannel.type = memory agent1.channels.memoryChannel.capacity = 1000 agent1.channels.memoryChannel.transactionCapacity = 1000 agent1.channels.memoryChannel.byteCapacityBufferPercentage = 20 agent1.channels.memoryChannel.byteCapacity = 800000 #---------拦截器相关配置------------------ # 定义拦截器 agent1.sources.fileSource.interceptors = i1 # 设置拦截器类型 agent1.sources.fileSource.interceptors.i1.type = regex_extractor # 设置正则表达式,匹配指定的数据,这样设置会在数据的header中增加log_type="某个值" agent1.sources.fileSource.interceptors.i1.regex = "type":"(\\w+)" agent1.sources.fileSource.interceptors.i1.serializers = s1 agent1.sources.fileSource.interceptors.i1.serializers.s1.name = log_type #---------hdfsSink 相关配置------------------ agent1.sinks.hdfsSink.type = hdfs # 注意, 我们输出到下面一个子文件夹datax中 agent1.sinks.hdfsSink.hdfs.path = hdfs://master:9000/data/types/%Y%m%d/%{log_type} agent1.sinks.hdfsSink.hdfs.writeFormat = Text agent1.sinks.hdfsSink.hdfs.fileType = DataStream agent1.sinks.hdfsSink.hdfs.callTimeout = 3600000 agent1.sinks.hdfsSink.hdfs.useLocalTimeStamp = true #当文件大小为52428800字节时,将临时文件滚动成一个目标文件 agent1.sinks.hdfsSink.hdfs.rollSize = 52428800 #events数据达到该数量的时候,将临时文件滚动成目标文件 agent1.sinks.hdfsSink.hdfs.rollCount = 0 #每隔N s将临时文件滚动成一个目标文件 agent1.sinks.hdfsSink.hdfs.rollInterval = 1200 #配置前缀和后缀 agent1.sinks.hdfsSink.hdfs.filePrefix=run agent1.sinks.hdfsSink.hdfs.fileSuffix=.data
监控文件是在
/usr/local/log/server.log
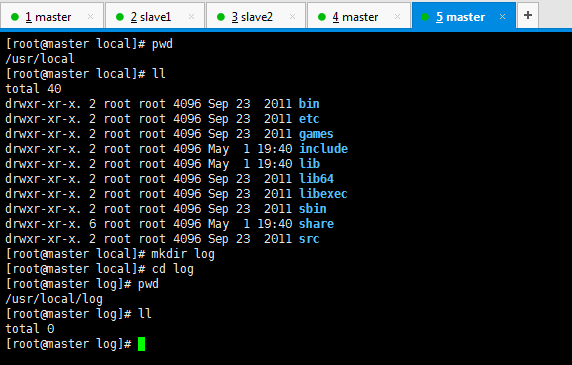
[root@master local]# pwd /usr/local [root@master local]# ll total 40 drwxr-xr-x. 2 root root 4096 Sep 23 2011 bin drwxr-xr-x. 2 root root 4096 Sep 23 2011 etc drwxr-xr-x. 2 root root 4096 Sep 23 2011 games drwxr-xr-x. 2 root root 4096 May 1 19:40 include drwxr-xr-x. 2 root root 4096 May 1 19:40 lib drwxr-xr-x. 2 root root 4096 Sep 23 2011 lib64 drwxr-xr-x. 2 root root 4096 Sep 23 2011 libexec drwxr-xr-x. 2 root root 4096 Sep 23 2011 sbin drwxr-xr-x. 6 root root 4096 May 1 19:40 share drwxr-xr-x. 2 root root 4096 Sep 23 2011 src [root@master local]# mkdir log [root@master local]# cd log [root@master log]# pwd /usr/local/log [root@master log]# ll total 0 [root@master log]#
然后,执行
[hadoop@master flume-1.7.0]$ bin/flume-ng agent --conf conf_RegexExtractorInterceptor/ --conf-file conf_RegexExtractorInterceptor/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console
然后,我这边,采用如下的一个shell脚本来模拟产生测试数据。
producerLog.sh

[root@master log]# pwd /usr/local/log [root@master log]# ll total 0 [root@master log]# vim producerLog.sh
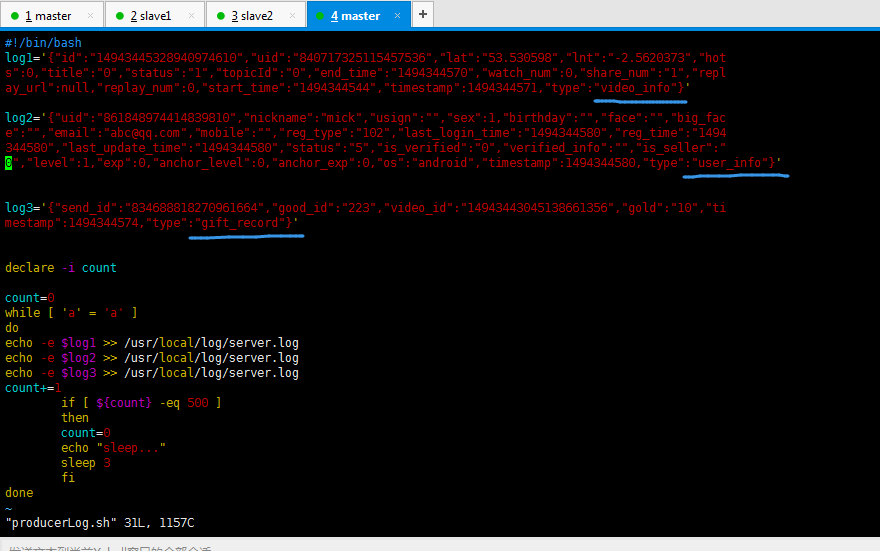
#!/bin/bash log1='{"id":"14943445328940974610","uid":"840717325115457536","lat":"53.530598","lnt":"-2.5620373","hot s":0,"title":"0","status":"1","topicId":"0","end_time":"1494344570","watch_num":0,"share_num":"1","repl ay_url":null,"replay_num":0,"start_time":"1494344544","timestamp":1494344571,"type":"video_info"}' log2='{"uid":"861848974414839810","nickname":"mick","usign":"","sex":1,"birthday":"","face":"","big_fac e":"","email":"abc@qq.com","mobile":"","reg_type":"102","last_login_time":"1494344580","reg_time":"1494 344580","last_update_time":"1494344580","status":"5","is_verified":"0","verified_info":"","is_seller":" 0","level":1,"exp":0,"anchor_level":0,"anchor_exp":0,"os":"android","timestamp":1494344580,"type":"user_info"}' log3='{"send_id":"834688818270961664","good_id":"223","video_id":"14943443045138661356","gold":"10","ti mestamp":1494344574,"type":"gift_record"}' declare -i count count=0 while [ 'a' = 'a' ] do echo -e $log1 >> /usr/local/log/server.log echo -e $log2 >> /usr/local/log/server.log echo -e $log3 >> /usr/local/log/server.log count+=1 if [ ${count} -eq 500 ] then count=0 echo "sleep..." sleep 3 fi done
这个shell脚本不太难哈。即log1会生成500条、log2会生成500条、log3会生成500条。每隔3秒。
然后,再来创建server.log文件

[root@master log]# pwd /usr/local/log [root@master log]# ll total 4 -rw-r--r-- 1 root root 1157 Jul 27 14:39 producerLog.sh [root@master log]# vim producerLog.sh [root@master log]# touch server.log [root@master log]# ll total 4 -rw-r--r-- 1 root root 1157 Jul 27 14:42 producerLog.sh -rw-r--r-- 1 root root 0 Jul 27 14:43 server.log [root@master log]# cat server.log [root@master log]#
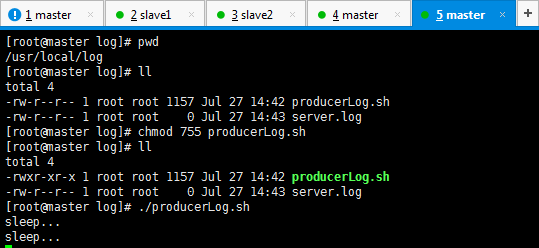
然后,来执行这个脚本,以模拟产生数据。
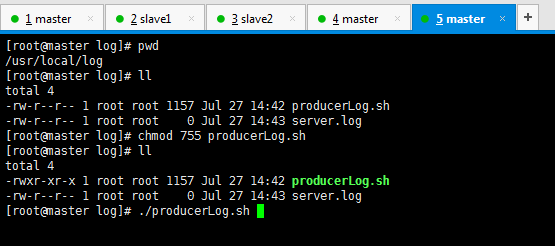
[root@master log]# pwd /usr/local/log [root@master log]# ll total 4 -rw-r--r-- 1 root root 1157 Jul 27 14:42 producerLog.sh -rw-r--r-- 1 root root 0 Jul 27 14:43 server.log [root@master log]# chmod 755 producerLog.sh [root@master log]# ll total 4 -rwxr-xr-x 1 root root 1157 Jul 27 14:42 producerLog.sh -rw-r--r-- 1 root root 0 Jul 27 14:43 server.log [root@master log]# ./producerLog.sh
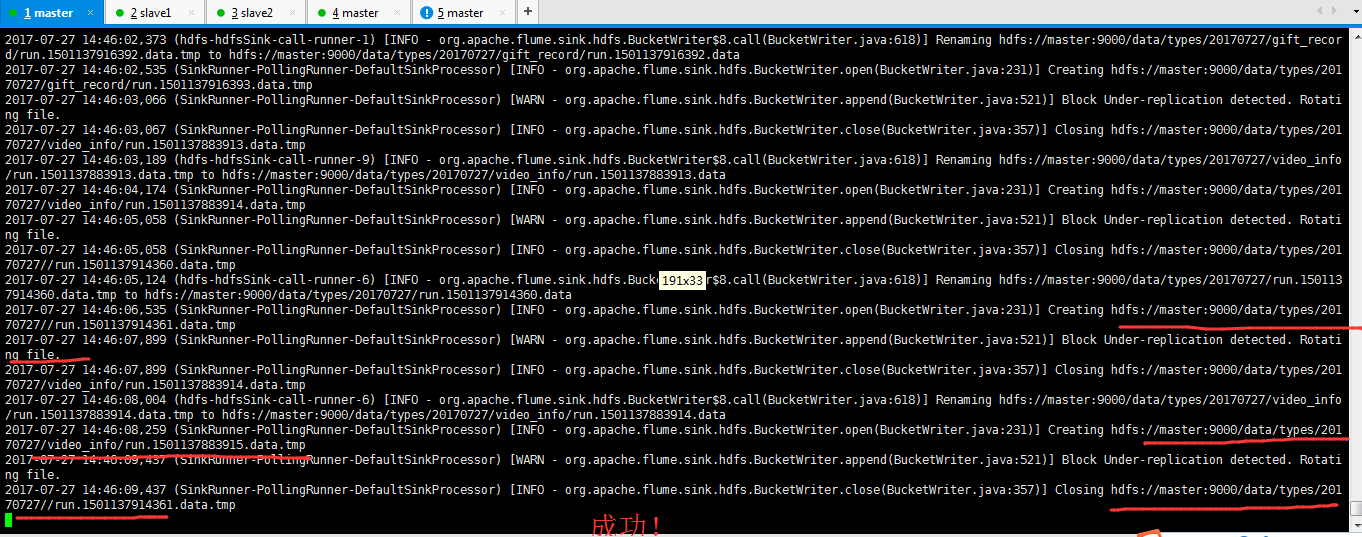
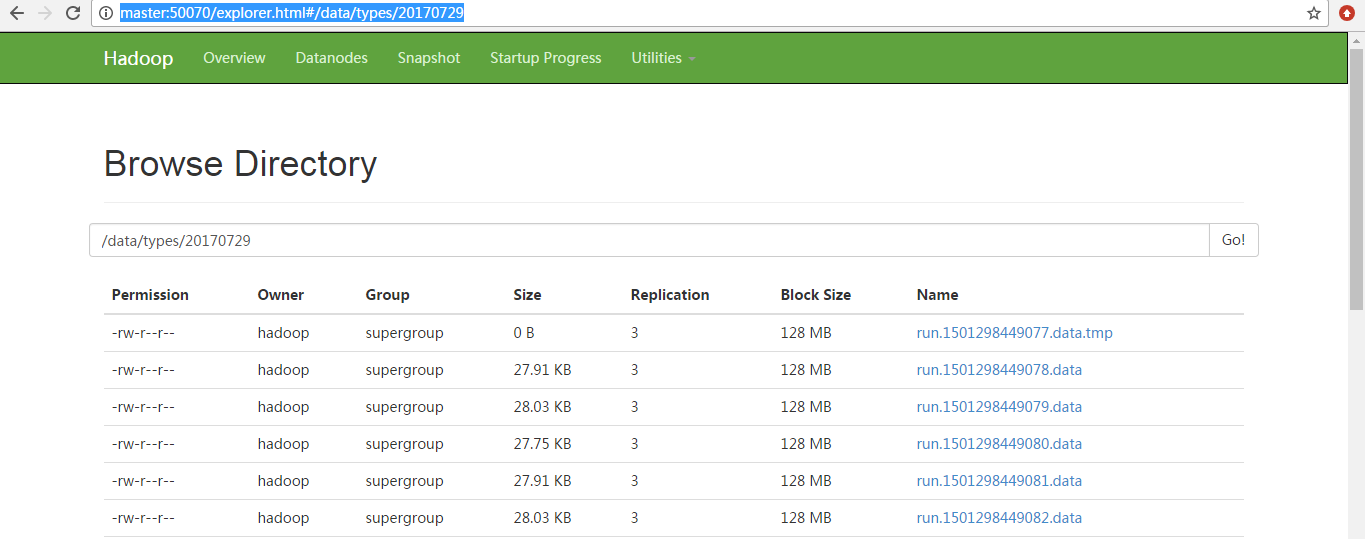
2017-07-27 14:46:42,275 (SinkRunner-PollingRunner-DefaultSinkProcessor) [WARN - org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:521)] Block Under-replication detected. Rotating file. 2017-07-27 14:46:42,279 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.close(BucketWriter.java:357)] Closing hdfs://master:9000/data/types/20170727//run.1501137914366.data.tmp 2017-07-27 14:46:43,117 (hdfs-hdfsSink-call-runner-9) [INFO - org.apache.flume.sink.hdfs.BucketWriter$8.call(BucketWriter.java:618)] Renaming hdfs://master:9000/data/types/20170727/run.1501137914366.data.tmp to hdfs://master:9000/data/types/20170727/run.1501137914366.data 2017-07-27 14:46:43,429 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:231)] Creating hdfs://master:9000/data/types/20170727//run.1501137914367.data.tmp 2017-07-27 14:46:45,017 (SinkRunner-PollingRunner-DefaultSinkProcessor) [WARN - org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:521)] Block Under-replication detected. Rotating file. 2017-07-27 14:46:45,017 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.close(BucketWriter.java:357)] Closing hdfs://master:9000/data/types/20170727/video_info/run.1501137883920.data.tmp 2017-07-27 14:46:45,091 (hdfs-hdfsSink-call-runner-0) [INFO - org.apache.flume.sink.hdfs.BucketWriter$8.call(BucketWriter.java:618)] Renaming hdfs://master:9000/data/types/20170727/video_info/run.1501137883920.data.tmp to hdfs://master:9000/data/types/20170727/video_info/run.1501137883920.data 2017-07-27 14:46:45,236 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:231)] Creating hdfs://master:9000/data/types/20170727/video_info/run.1501137883921.data.tmp 2017-07-27 14:46:45,412 (SinkRunner-PollingRunner-DefaultSinkProcessor) [WARN - org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:521)] Block Under-replication detected. Rotating file. 2017-07-27 14:46:45,412 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.close(BucketWriter.java:357)] Closing hdfs://master:9000/data/types/20170727//run.1501137914367.data.tmp 2017-07-27 14:46:45,455 (hdfs-hdfsSink-call-runner-7) [INFO - org.apache.flume.sink.hdfs.BucketWriter$8.call(BucketWriter.java:618)] Renaming hdfs://master:9000/data/types/20170727/run.1501137914367.data.tmp to hdfs://master:9000/data/types/20170727/run.1501137914367.data 2017-07-27 14:46:45,585 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:231)] Creating hdfs://master:9000/data/types/20170727//run.1501137914368.data.tmp 2017-07-27 14:46:45,942 (SinkRunner-PollingRunner-DefaultSinkProcessor) [WARN - org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:521)] Block Under-replication detected. Rotating file. 2017-07-27 14:46:45,942 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.close(BucketWriter.java:357)] Closing hdfs://master:9000/data/types/20170727/gift_record/run.1501137916399.data.tmp 2017-07-27 14:46:46,074 (hdfs-hdfsSink-call-runner-4) [INFO - org.apache.flume.sink.hdfs.BucketWriter$8.call(BucketWriter.java:618)] Renaming hdfs://master:9000/data/types/20170727/gift_record/run.1501137916399.data.tmp to hdfs://master:9000/data/types/20170727/gift_record/run.1501137916399.data 2017-07-27 14:46:46,138 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:231)] Creating hdfs://master:9000/data/types/20170727/gift_record/run.1501137916400.data.tmp
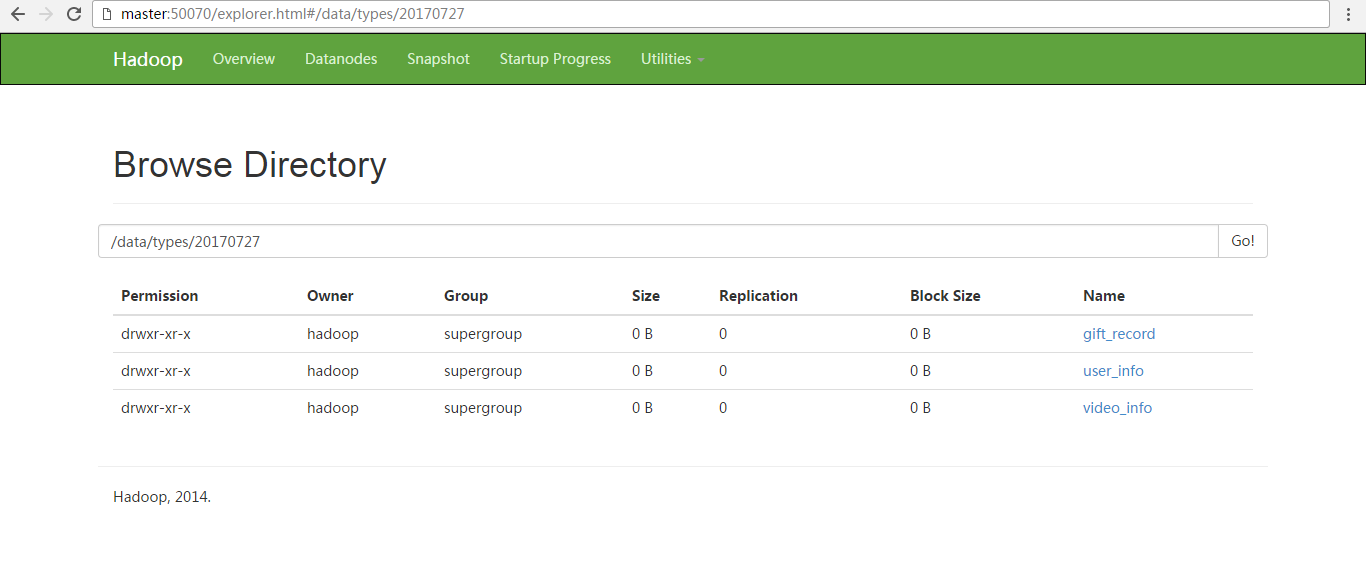
Search and Replace Interceptor
以上存放,是在
模拟产生的gift_record是存放在 /data/types/20170727/gift_record
但是呢。我现在需求是
模拟产生的gift_record是存放在 /data/types/20170727/giftRecord
则改为
agent1.sources.r1.interceptors = i1 i2 i3 i4 agent1.sources.r1.interceptors.i1.type = search_replace agent1.sources.r1.interceptors.i1.searchPattern = "type":"gift_record" agent1.sources.r1.interceptors.i1.replaceString = "type":"giftRecord" agent1.sources.r1.interceptors.i2.type = search_replace agent1.sources.r1.interceptors.i2.searchPattern = "type":"video_info" agent1.sources.r1.interceptors.i2.replaceString = "type":"videoInfo" agent1.sources.r1.interceptors.i3.type = search_replace agent1.sources.r1.interceptors.i3.searchPattern = "type":"user_info" agent1.sources.r1.interceptors.i3.replaceString = "type":"userInfo" agent1.sources.fileSource.interceptors.i4.type = regex_extractor agent1.sources.fileSource.interceptors.i4.regex = "type":"(\\w+)" agent1.sources.fileSource.interceptors.i4.serializers = s1 agent1.sources.fileSource.interceptors.i4.serializers.s1.name = log_type
[hadoop@master conf_SearchandReplaceInterceptor]$ pwd /home/hadoop/app/flume-1.7.0/conf_SearchandReplaceInterceptor [hadoop@master conf_SearchandReplaceInterceptor]$ ll total 16 -rw-r--r-- 1 hadoop hadoop 1661 Jul 27 12:04 flume-conf.properties -rw-r--r-- 1 hadoop hadoop 1455 Jul 27 12:04 flume-env.ps1.template -rw-r--r-- 1 hadoop hadoop 1565 Jul 27 12:04 flume-env.sh.template -rw-r--r-- 1 hadoop hadoop 3135 Jul 27 12:32 log4j.properties [hadoop@master conf_SearchandReplaceInterceptor]$ vim flume-conf.properties
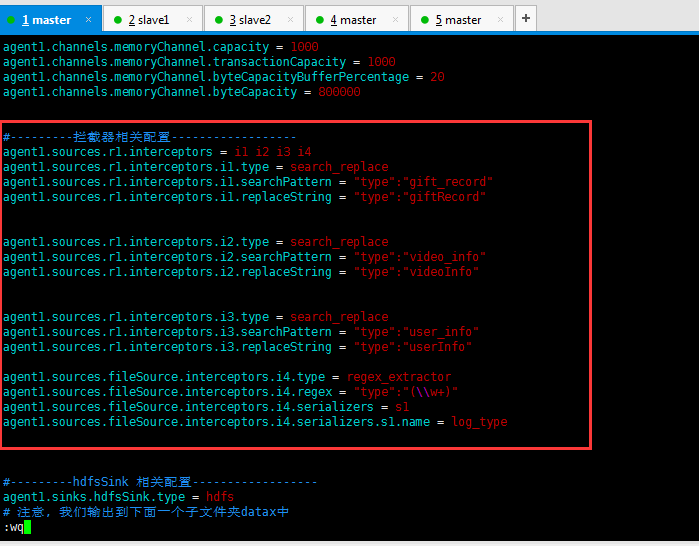
#source的名字 agent1.sources = fileSource # channels的名字,建议按照type来命名 agent1.channels = memoryChannel # sink的名字,建议按照目标来命名 agent1.sinks = hdfsSink # 指定source使用的channel名字 agent1.sources.fileSource.channels = memoryChannel # 指定sink需要使用的channel的名字,注意这里是channel agent1.sinks.hdfsSink.channel = memoryChannel agent1.sources.fileSource.type = exec agent1.sources.fileSource.command = tail -F /usr/local/log/server.log #------- fileChannel-1相关配置------------------------- # channel类型 agent1.channels.memoryChannel.type = memory agent1.channels.memoryChannel.capacity = 1000 agent1.channels.memoryChannel.transactionCapacity = 1000 agent1.channels.memoryChannel.byteCapacityBufferPercentage = 20 agent1.channels.memoryChannel.byteCapacity = 800000 #---------拦截器相关配置------------------
agent1.sources.r1.interceptors = i1 i2 i3 i4
agent1.sources.r1.interceptors.i1.type = search_replace
agent1.sources.r1.interceptors.i1.searchPattern = "type":"gift_record"
agent1.sources.r1.interceptors.i1.replaceString = "type":"giftRecord"
agent1.sources.r1.interceptors.i2.type = search_replace
agent1.sources.r1.interceptors.i2.searchPattern = "type":"video_info"
agent1.sources.r1.interceptors.i2.replaceString = "type":"videoInfo"
agent1.sources.r1.interceptors.i3.type = search_replace
agent1.sources.r1.interceptors.i3.searchPattern = "type":"user_info"
agent1.sources.r1.interceptors.i3.replaceString = "type":"userInfo"
agent1.sources.fileSource.interceptors.i4.type = regex_extractor agent1.sources.fileSource.interceptors.i4.regex = "type":"(\\w+)" agent1.sources.fileSource.interceptors.i4.serializers = s1 agent1.sources.fileSource.interceptors.i4.serializers.s1.name = log_type #---------hdfsSink 相关配置------------------ agent1.sinks.hdfsSink.type = hdfs # 注意, 我们输出到下面一个子文件夹datax中 agent1.sinks.hdfsSink.hdfs.path = hdfs://master:9000/data/types/%Y%m%d/%{log_type} agent1.sinks.hdfsSink.hdfs.writeFormat = Text agent1.sinks.hdfsSink.hdfs.fileType = DataStream agent1.sinks.hdfsSink.hdfs.callTimeout = 3600000 agent1.sinks.hdfsSink.hdfs.useLocalTimeStamp = true #当文件大小为52428800字节时,将临时文件滚动成一个目标文件 agent1.sinks.hdfsSink.hdfs.rollSize = 52428800 #events数据达到该数量的时候,将临时文件滚动成目标文件 agent1.sinks.hdfsSink.hdfs.rollCount = 0 #每隔N s将临时文件滚动成一个目标文件 agent1.sinks.hdfsSink.hdfs.rollInterval = 1200 #配置前缀和后缀 agent1.sinks.hdfsSink.hdfs.filePrefix=run agent1.sinks.hdfsSink.hdfs.fileSuffix=.data
然后,执行
[hadoop@master flume-1.7.0]$ bin/flume-ng agent --conf conf_SearchandReplaceInterceptor/ --conf-file conf_SearchandReplaceInterceptor/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console

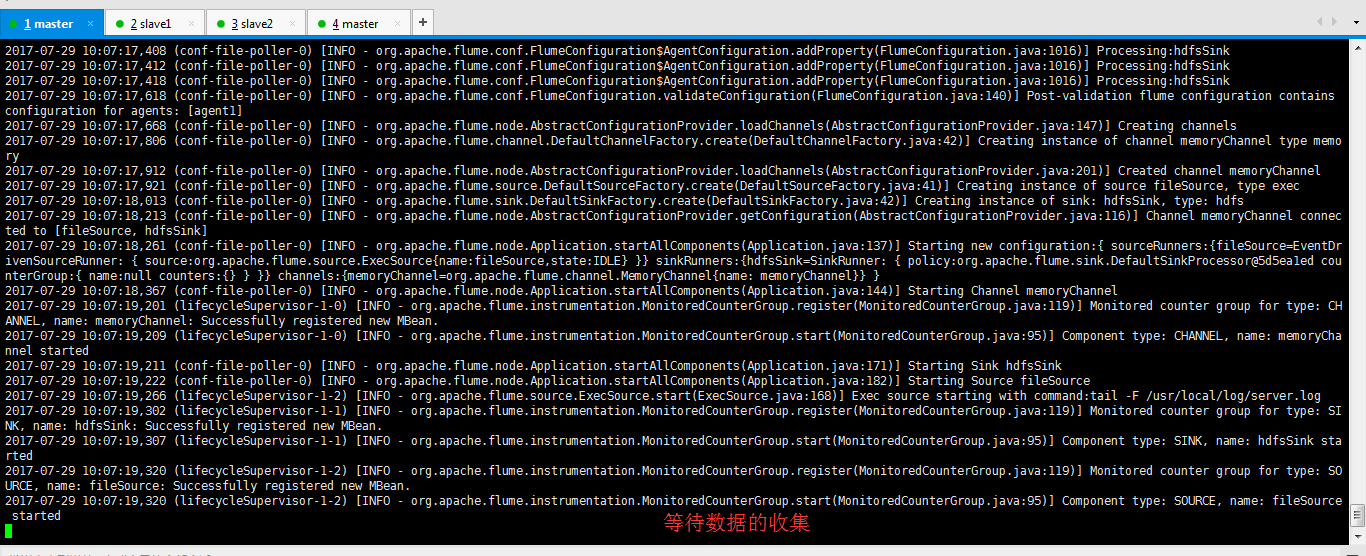
我这里,出现了这个错误
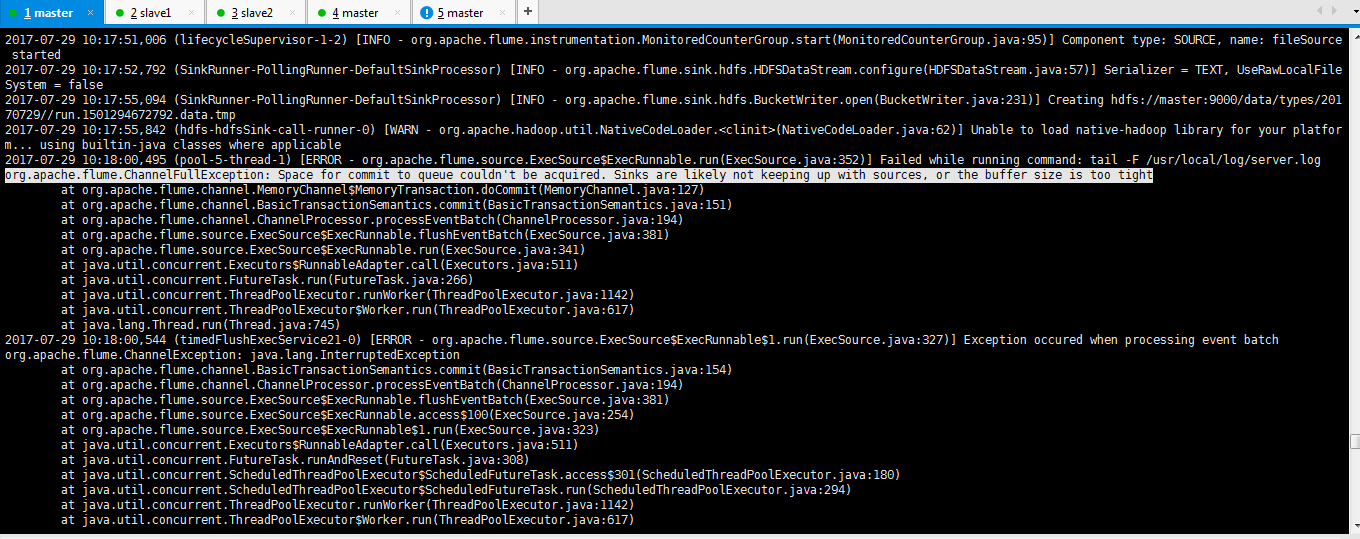
2017-07-29 10:17:51,006 (lifecycleSupervisor-1-2) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: fileSource started 2017-07-29 10:17:52,792 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:57)] Serializer = TEXT, UseRawLocalFileSystem = false 2017-07-29 10:17:55,094 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:231)] Creating hdfs://master:9000/data/types/20170729//run.1501294672792.data.tmp 2017-07-29 10:17:55,842 (hdfs-hdfsSink-call-runner-0) [WARN - org.apache.hadoop.util.NativeCodeLoader.<clinit>(NativeCodeLoader.java:62)] Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2017-07-29 10:18:00,495 (pool-5-thread-1) [ERROR - org.apache.flume.source.ExecSource$ExecRunnable.run(ExecSource.java:352)] Failed while running command: tail -F /usr/local/log/server.log org.apache.flume.ChannelFullException: Space for commit to queue couldn't be acquired. Sinks are likely not keeping up with sources, or the buffer size is too tight at org.apache.flume.channel.MemoryChannel$MemoryTransaction.doCommit(MemoryChannel.java:127) at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151) at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194) at org.apache.flume.source.ExecSource$ExecRunnable.flushEventBatch(ExecSource.java:381) at org.apache.flume.source.ExecSource$ExecRunnable.run(ExecSource.java:341) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) 2017-07-29 10:18:00,544 (timedFlushExecService21-0) [ERROR - org.apache.flume.source.ExecSource$ExecRunnable$1.run(ExecSource.java:327)] Exception occured when processing event batch org.apache.flume.ChannelException: java.lang.InterruptedException at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:154) at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194) at org.apache.flume.source.ExecSource$ExecRunnable.flushEventBatch(ExecSource.java:381) at org.apache.flume.source.ExecSource$ExecRunnable.access$100(ExecSource.java:254) at org.apache.flume.source.ExecSource$ExecRunnable$1.run(ExecSource.java:323) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
然后,这边模拟产生数据。
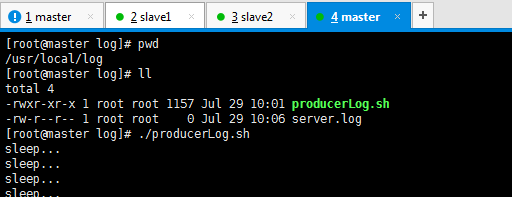
[root@master log]# pwd /usr/local/log [root@master log]# ll total 4 -rwxr-xr-x 1 root root 1157 Jul 29 10:01 producerLog.sh -rw-r--r-- 1 root root 0 Jul 29 10:06 server.log [root@master log]# ./producerLog.sh sleep... sleep... sleep...
Flume自定义拦截器(Interceptors)
一、自定义拦截器类型必须是:类全名$内部类名,其实就是内部类名称
如:zhouls.bigdata.MySearchAndReplaceInterceptor$Builder
二、为什么这样写
至于为什么这样写:是因为Interceptor接口还有一个 公共的内部接口(Builder) ,所以自定义拦截器 要是实现 Builder接口,
也就是实现一个内部类(该内部类的主要作用是:获取flume-conf.properties 自定义的 参数,并将参数传递给 自定义拦截器)
三、
本人知识有限,可能描述的不太清楚,可自行了解 java接口与内部类。


由于有时候内置的拦截器不够用,所以需要针对特殊的业务需求自定义拦截器
官方文档中没有发现自定义interceptor的步骤,但是可以根据flume源码参考内置的拦截器的代码
flume-1.7/flume-ng-core/src/main/java/org/apache/flume/interceptor/HostInterceptor.java
大家,去https://github.com/找到,因为,我的flume是1.7.0的。所以如下
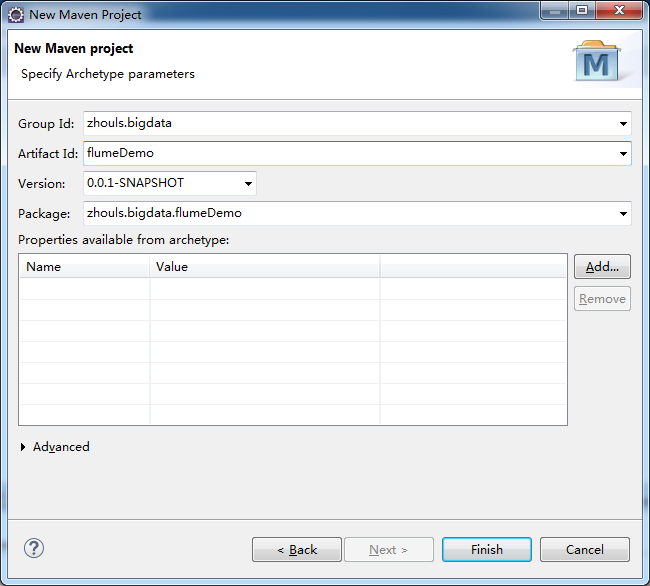
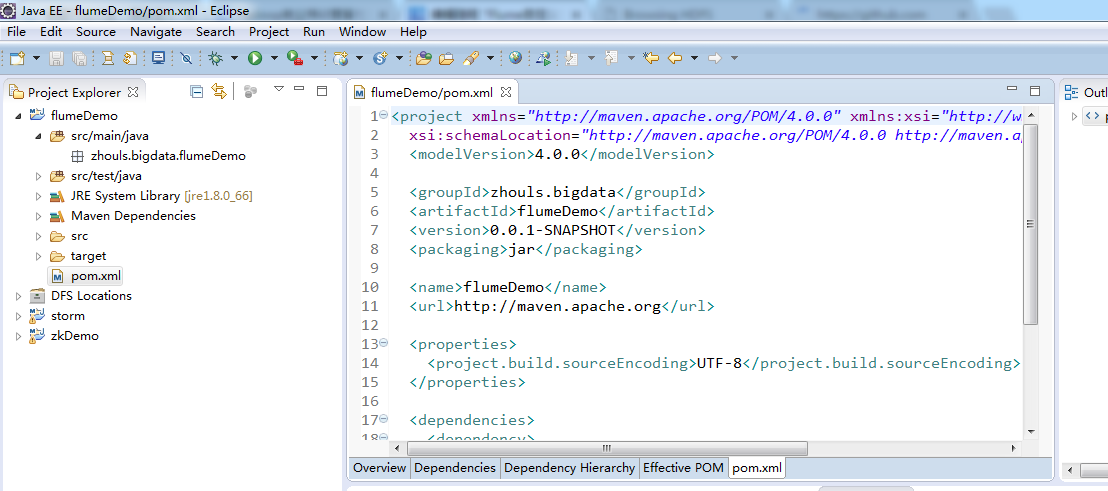
修改后的pom.xml为
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>zhouls.bigdata</groupId> <artifactId>flumeDemo</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>flumeDemo</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> <!-- 此版本的curator操作的zk是3.4.6版本 --> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>2.10.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flume/flume-ng-core --> <dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.7.0</version> </dependency> </dependencies> </project>
然后,我这里,参考github上的给定参考代码,来写出属于我们自己业务需求的flume自定义拦截器代码编程。
MySearchAndReplaceInterceptor.java.java
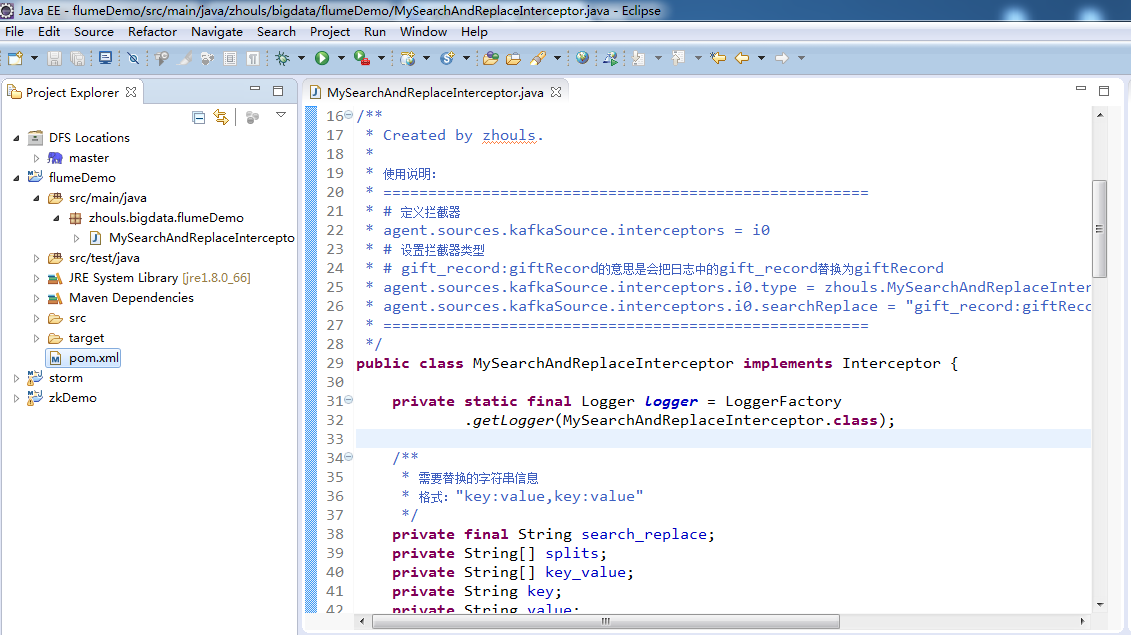
package zhouls.bigdata.flumeDemo; import com.google.common.base.Preconditions; import org.apache.commons.lang.StringUtils; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.util.HashMap; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * Created by zhouls. * * 使用说明: * ====================================================== * # 定义拦截器 * agent.sources.kafkaSource.interceptors = i0 * # 设置拦截器类型 * # gift_record:giftRecord的意思是会把日志中的gift_record替换为giftRecord * agent.sources.kafkaSource.interceptors.i0.type = zhouls.MySearchAndReplaceInterceptor * agent.sources.kafkaSource.interceptors.i0.searchReplace = "gift_record:giftRecord,video_info:videoInfo" * ====================================================== */ public class MySearchAndReplaceInterceptor implements Interceptor { private static final Logger logger = LoggerFactory .getLogger(MySearchAndReplaceInterceptor.class); /** * 需要替换的字符串信息 * 格式:"key:value,key:value" */ private final String search_replace; private String[] splits; private String[] key_value; private String key; private String value; private HashMap<String, String> hashMap = new HashMap<String, String>(); private Pattern compile = Pattern.compile("\"type\":\"(\\w+)\""); private Matcher matcher; private String group; private MySearchAndReplaceInterceptor(String search_replace) { this.search_replace = search_replace; } /** * 初始化放在,最开始执行一次 * 把配置的数据初始化到map中,方便后面调用 */ public void initialize() { try{ if(StringUtils.isNotBlank(search_replace)){ splits = search_replace.split(","); for (String key_value_pair:splits) { key_value = key_value_pair.split(":"); key = key_value[0]; value = key_value[1]; hashMap.put(key,value); } } }catch (Exception e){ logger.error("数据格式错误,初始化失败。"+search_replace,e.getCause()); } } public void close() { } /** * 具体的处理逻辑 * @param event * @return */ public Event intercept(Event event) { try{ String origBody = new String(event.getBody()); matcher = compile.matcher(origBody); if(matcher.find()){ group = matcher.group(1); if(StringUtils.isNotBlank(group)){ String newBody = origBody.replaceAll("\"type\":\""+group+"\"", "\"type\":\""+hashMap.get(group)+"\""); event.setBody(newBody.getBytes()); } } }catch (Exception e){ logger.error("拦截器处理失败!",e.getCause()); } return event; } public List<Event> intercept(List<Event> events) { for (Event event : events) { intercept(event); } return events; } public static class Builder implements Interceptor.Builder { private static final String SEARCH_REPLACE_KEY = "searchReplace"; private String searchReplace; public void configure(Context context) { searchReplace = context.getString(SEARCH_REPLACE_KEY); Preconditions.checkArgument(!StringUtils.isEmpty(searchReplace), "Must supply a valid search pattern " + SEARCH_REPLACE_KEY + " (may not be empty)"); } public Interceptor build() { Preconditions.checkNotNull(searchReplace, "Regular expression searchReplace required"); return new MySearchAndReplaceInterceptor(searchReplace); } } }
然后把MySearchAndReplaceInterceptor这个类导出成一个jar包。
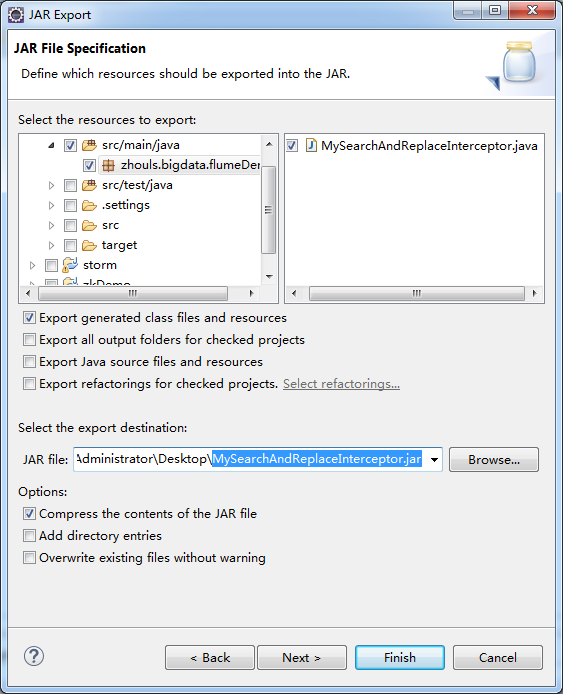
同时,大家也可以用maven来打jar包
把这个jar包上传到flume1.7.0的lib目录下
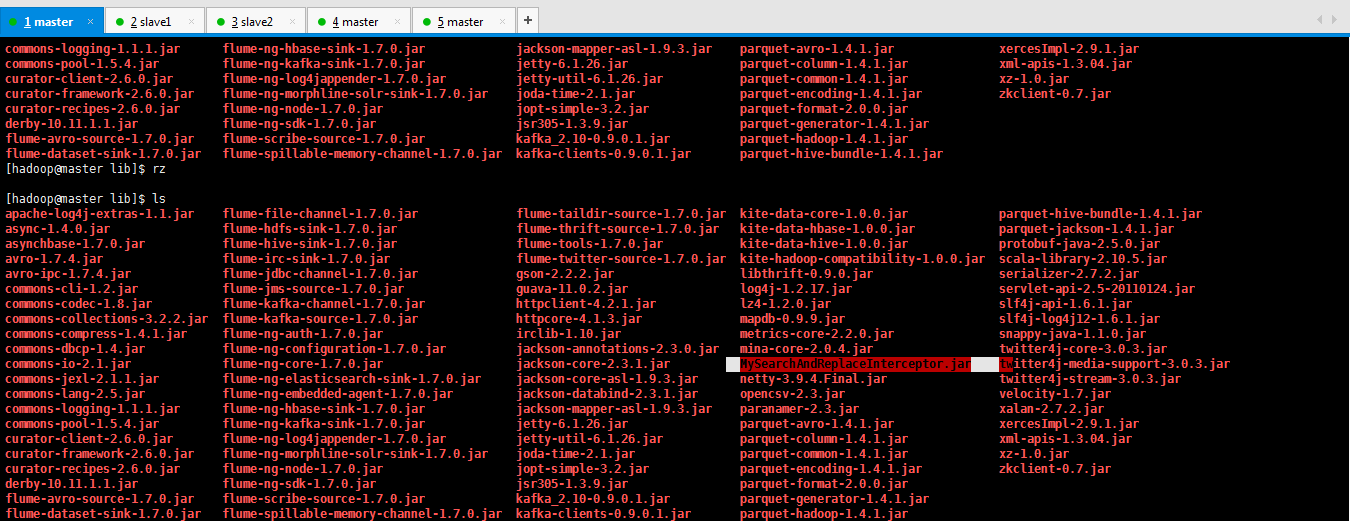
[hadoop@master lib]$ rz [hadoop@master lib]$ ls apache-log4j-extras-1.1.jar flume-file-channel-1.7.0.jar flume-taildir-source-1.7.0.jar kite-data-core-1.0.0.jar parquet-hive-bundle-1.4.1.jar async-1.4.0.jar flume-hdfs-sink-1.7.0.jar flume-thrift-source-1.7.0.jar kite-data-hbase-1.0.0.jar parquet-jackson-1.4.1.jar asynchbase-1.7.0.jar flume-hive-sink-1.7.0.jar flume-tools-1.7.0.jar kite-data-hive-1.0.0.jar protobuf-java-2.5.0.jar avro-1.7.4.jar flume-irc-sink-1.7.0.jar flume-twitter-source-1.7.0.jar kite-hadoop-compatibility-1.0.0.jar scala-library-2.10.5.jar avro-ipc-1.7.4.jar flume-jdbc-channel-1.7.0.jar gson-2.2.2.jar libthrift-0.9.0.jar serializer-2.7.2.jar commons-cli-1.2.jar flume-jms-source-1.7.0.jar guava-11.0.2.jar log4j-1.2.17.jar servlet-api-2.5-20110124.jar commons-codec-1.8.jar flume-kafka-channel-1.7.0.jar httpclient-4.2.1.jar lz4-1.2.0.jar slf4j-api-1.6.1.jar commons-collections-3.2.2.jar flume-kafka-source-1.7.0.jar httpcore-4.1.3.jar mapdb-0.9.9.jar slf4j-log4j12-1.6.1.jar commons-compress-1.4.1.jar flume-ng-auth-1.7.0.jar irclib-1.10.jar metrics-core-2.2.0.jar snappy-java-1.1.0.jar commons-dbcp-1.4.jar flume-ng-configuration-1.7.0.jar jackson-annotations-2.3.0.jar mina-core-2.0.4.jar twitter4j-core-3.0.3.jar commons-io-2.1.jar flume-ng-core-1.7.0.jar jackson-core-2.3.1.jar MySearchAndReplaceInterceptor.jar twitter4j-media-support-3.0.3.jar commons-jexl-2.1.1.jar flume-ng-elasticsearch-sink-1.7.0.jar jackson-core-asl-1.9.3.jar netty-3.9.4.Final.jar twitter4j-stream-3.0.3.jar commons-lang-2.5.jar flume-ng-embedded-agent-1.7.0.jar jackson-databind-2.3.1.jar opencsv-2.3.jar velocity-1.7.jar commons-logging-1.1.1.jar flume-ng-hbase-sink-1.7.0.jar jackson-mapper-asl-1.9.3.jar paranamer-2.3.jar xalan-2.7.2.jar commons-pool-1.5.4.jar flume-ng-kafka-sink-1.7.0.jar jetty-6.1.26.jar parquet-avro-1.4.1.jar xercesImpl-2.9.1.jar curator-client-2.6.0.jar flume-ng-log4jappender-1.7.0.jar jetty-util-6.1.26.jar parquet-column-1.4.1.jar xml-apis-1.3.04.jar curator-framework-2.6.0.jar flume-ng-morphline-solr-sink-1.7.0.jar joda-time-2.1.jar parquet-common-1.4.1.jar xz-1.0.jar curator-recipes-2.6.0.jar flume-ng-node-1.7.0.jar jopt-simple-3.2.jar parquet-encoding-1.4.1.jar zkclient-0.7.jar derby-10.11.1.1.jar flume-ng-sdk-1.7.0.jar jsr305-1.3.9.jar parquet-format-2.0.0.jar flume-avro-source-1.7.0.jar flume-scribe-source-1.7.0.jar kafka_2.10-0.9.0.1.jar parquet-generator-1.4.1.jar flume-dataset-sink-1.7.0.jar flume-spillable-memory-channel-1.7.0.jar kafka-clients-0.9.0.1.jar parquet-hadoop-1.4.1.jar [hadoop@master lib]$ pwd /home/hadoop/app/flume-1.7.0/lib [hadoop@master lib]$
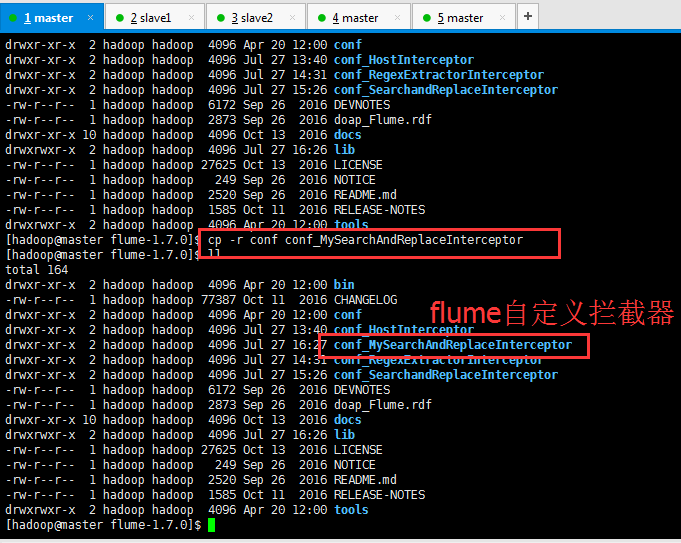
drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 conf drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 13:40 conf_HostInterceptor drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 14:31 conf_RegexExtractorInterceptor drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 15:26 conf_SearchandReplaceInterceptor -rw-r--r-- 1 hadoop hadoop 6172 Sep 26 2016 DEVNOTES -rw-r--r-- 1 hadoop hadoop 2873 Sep 26 2016 doap_Flume.rdf drwxr-xr-x 10 hadoop hadoop 4096 Oct 13 2016 docs drwxrwxr-x 2 hadoop hadoop 4096 Jul 27 16:26 lib -rw-r--r-- 1 hadoop hadoop 27625 Oct 13 2016 LICENSE -rw-r--r-- 1 hadoop hadoop 249 Sep 26 2016 NOTICE -rw-r--r-- 1 hadoop hadoop 2520 Sep 26 2016 README.md -rw-r--r-- 1 hadoop hadoop 1585 Oct 11 2016 RELEASE-NOTES drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 tools [hadoop@master flume-1.7.0]$ cp -r conf conf_MySearchAndReplaceInterceptor [hadoop@master flume-1.7.0]$ ll total 164 drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 bin -rw-r--r-- 1 hadoop hadoop 77387 Oct 11 2016 CHANGELOG drwxr-xr-x 2 hadoop hadoop 4096 Apr 20 12:00 conf drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 13:40 conf_HostInterceptor drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 16:27 conf_MySearchAndReplaceInterceptor drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 14:31 conf_RegexExtractorInterceptor drwxr-xr-x 2 hadoop hadoop 4096 Jul 27 15:26 conf_SearchandReplaceInterceptor -rw-r--r-- 1 hadoop hadoop 6172 Sep 26 2016 DEVNOTES -rw-r--r-- 1 hadoop hadoop 2873 Sep 26 2016 doap_Flume.rdf drwxr-xr-x 10 hadoop hadoop 4096 Oct 13 2016 docs drwxrwxr-x 2 hadoop hadoop 4096 Jul 27 16:26 lib -rw-r--r-- 1 hadoop hadoop 27625 Oct 13 2016 LICENSE -rw-r--r-- 1 hadoop hadoop 249 Sep 26 2016 NOTICE -rw-r--r-- 1 hadoop hadoop 2520 Sep 26 2016 README.md -rw-r--r-- 1 hadoop hadoop 1585 Oct 11 2016 RELEASE-NOTES drwxrwxr-x 2 hadoop hadoop 4096 Apr 20 12:00 tools [hadoop@master flume-1.7.0]$
修改好log4j.properties ,为了方便管理查看日志
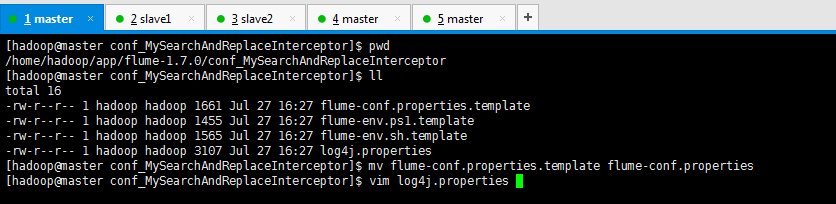
[hadoop@master conf_MySearchAndReplaceInterceptor]$ pwd /home/hadoop/app/flume-1.7.0/conf_MySearchAndReplaceInterceptor [hadoop@master conf_MySearchAndReplaceInterceptor]$ ll total 16 -rw-r--r-- 1 hadoop hadoop 1661 Jul 27 16:27 flume-conf.properties.template -rw-r--r-- 1 hadoop hadoop 1455 Jul 27 16:27 flume-env.ps1.template -rw-r--r-- 1 hadoop hadoop 1565 Jul 27 16:27 flume-env.sh.template -rw-r--r-- 1 hadoop hadoop 3107 Jul 27 16:27 log4j.properties [hadoop@master conf_MySearchAndReplaceInterceptor]$ mv flume-conf.properties.template flume-conf.properties [hadoop@master conf_MySearchAndReplaceInterceptor]$ vim log4j.properties
#flume.root.logger=DEBUG,console flume.root.logger=INFO,LOGFILE flume.log.dir=./logs flume.log.file=flume_MySearchAndReplaceInterceptor.log
[hadoop@master conf_MySearchAndReplaceInterceptor]$ ll total 16 -rw-r--r-- 1 hadoop hadoop 1661 Jul 27 16:27 flume-conf.properties -rw-r--r-- 1 hadoop hadoop 1455 Jul 27 16:27 flume-env.ps1.template -rw-r--r-- 1 hadoop hadoop 1565 Jul 27 16:27 flume-env.sh.template -rw-r--r-- 1 hadoop hadoop 3137 Jul 27 16:29 log4j.properties [hadoop@master conf_MySearchAndReplaceInterceptor]$ vim flume-conf.properties
然后,修改flume的配置文件如下:
注意:不能为上面。

除非你的程序需要引号(“”),否则不要加引号(“”),本程序不需要引号,因此是错误的
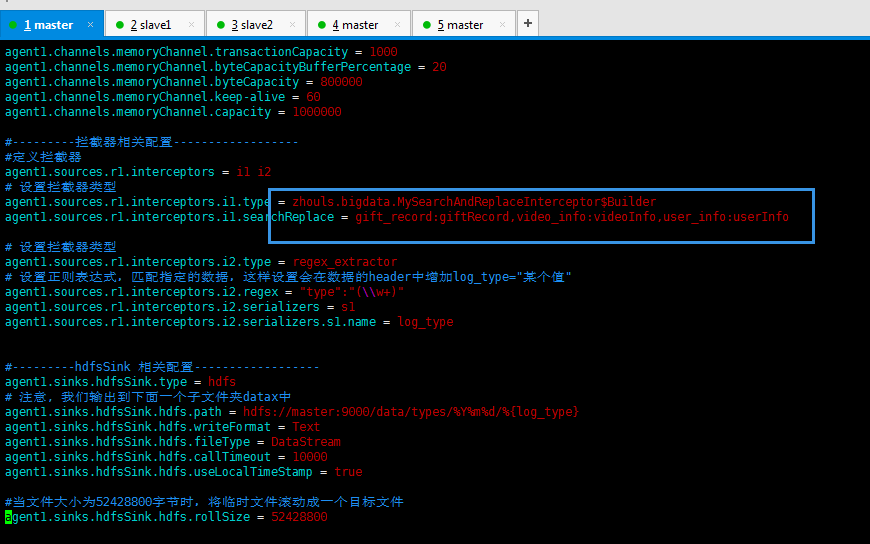
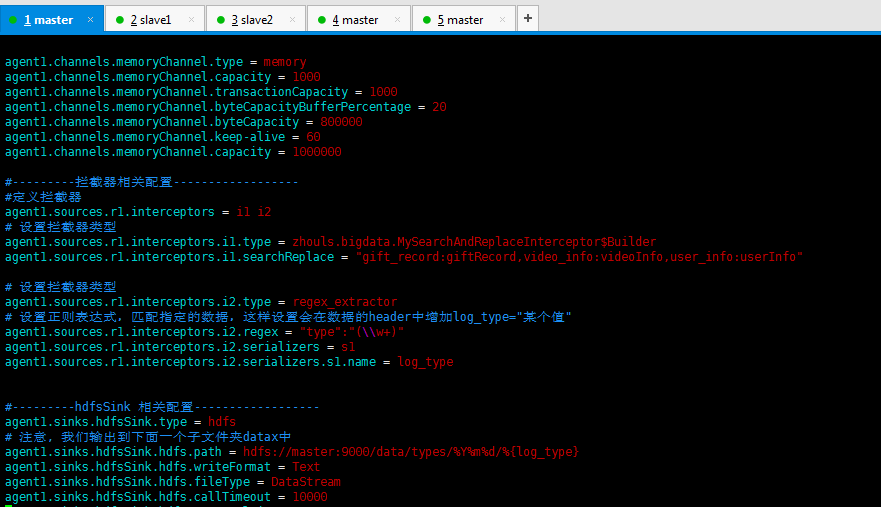
#source的名字 agent1.sources = fileSource # channels的名字,建议按照type来命名 agent1.channels = memoryChannel # sink的名字,建议按照目标来命名 agent1.sinks = hdfsSink # 指定source使用的channel名字 agent1.sources.fileSource.channels = memoryChannel # 指定sink需要使用的channel的名字,注意这里是channel agent1.sinks.hdfsSink.channel = memoryChannel agent1.sources.fileSource.type = exec agent1.sources.fileSource.command = tail -F /usr/local/log/server.log #------- fileChannel-1相关配置------------------------- # channel类型 agent1.channels.memoryChannel.type = memory agent1.channels.memoryChannel.capacity = 1000 agent1.channels.memoryChannel.transactionCapacity = 1000 agent1.channels.memoryChannel.byteCapacityBufferPercentage = 20 agent1.channels.memoryChannel.byteCapacity = 800000 #---------拦截器相关配置------------------ #定义拦截器 agent1.sources.r1.interceptors = i1 i2 # 设置拦截器类型 agent1.sources.r1.interceptors.i1.type = zhouls.bigdata.MySearchAndReplaceInterceptor agent1.sources.r1.interceptors.i1.searchReplace = gift_record:giftRecord,video_info:videoInfo,user_info:userInfo # 设置拦截器类型 agent1.sources.r1.interceptors.i2.type = regex_extractor # 设置正则表达式,匹配指定的数据,这样设置会在数据的header中增加log_type="某个值" agent1.sources.r1.interceptors.i2.regex = "type":"(\\w+)" agent1.sources.r1.interceptors.i2.serializers = s1 agent1.sources.r1.interceptors.i2.serializers.s1.name = log_type #---------hdfsSink 相关配置------------------ agent1.sinks.hdfsSink.type = hdfs # 注意, 我们输出到下面一个子文件夹datax中 agent1.sinks.hdfsSink.hdfs.path = hdfs://master:9000/data/types/%Y%m%d/%{log_type} agent1.sinks.hdfsSink.hdfs.writeFormat = Text agent1.sinks.hdfsSink.hdfs.fileType = DataStream agent1.sinks.hdfsSink.hdfs.callTimeout = 3600000 agent1.sinks.hdfsSink.hdfs.useLocalTimeStamp = true #当文件大小为52428800字节时,将临时文件滚动成一个目标文件 agent1.sinks.hdfsSink.hdfs.rollSize = 52428800 #events数据达到该数量的时候,将临时文件滚动成目标文件 agent1.sinks.hdfsSink.hdfs.rollCount = 0 #每隔N s将临时文件滚动成一个目标文件 agent1.sinks.hdfsSink.hdfs.rollInterval = 1200 #配置前缀和后缀 agent1.sinks.hdfsSink.hdfs.filePrefix=run agent1.sinks.hdfsSink.hdfs.fileSuffix=.data
主要在里面添加拦截器的配置是如下
#---------拦截器相关配置------------------ #定义拦截器 agent1.sources.r1.interceptors = i1 i2 # 设置拦截器类型 agent1.sources.r1.interceptors.i1.type = zhouls.bigdata.MySearchAndReplaceInterceptor agent1.sources.r1.interceptors.i1.searchReplace = "gift_record:giftRecord,video_info:videoInfo,user_info:userInfo" # 设置拦截器类型 agent1.sources.r1.interceptors.i2.type = regex_extractor # 设置正则表达式,匹配指定的数据,这样设置会在数据的header中增加log_type="某个值" agent1.sources.r1.interceptors.i2.regex = "type":"(\\w+)" agent1.sources.r1.interceptors.i2.serializers = s1 agent1.sources.r1.interceptors.i2.serializers.s1.name = log_type
意思就是,即把gift_record 换成giftRecord
video_info转换成videoInfo
user_info转换成userInfo
然后,启动agent服务即可。
[hadoop@master flume-1.7.0]$ bin/flume-ng agent --conf conf_MySearchAndReplaceInterceptor/ --conf-file conf_MySearchAndReplaceInterceptor/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console

我这里,出现了这个错误
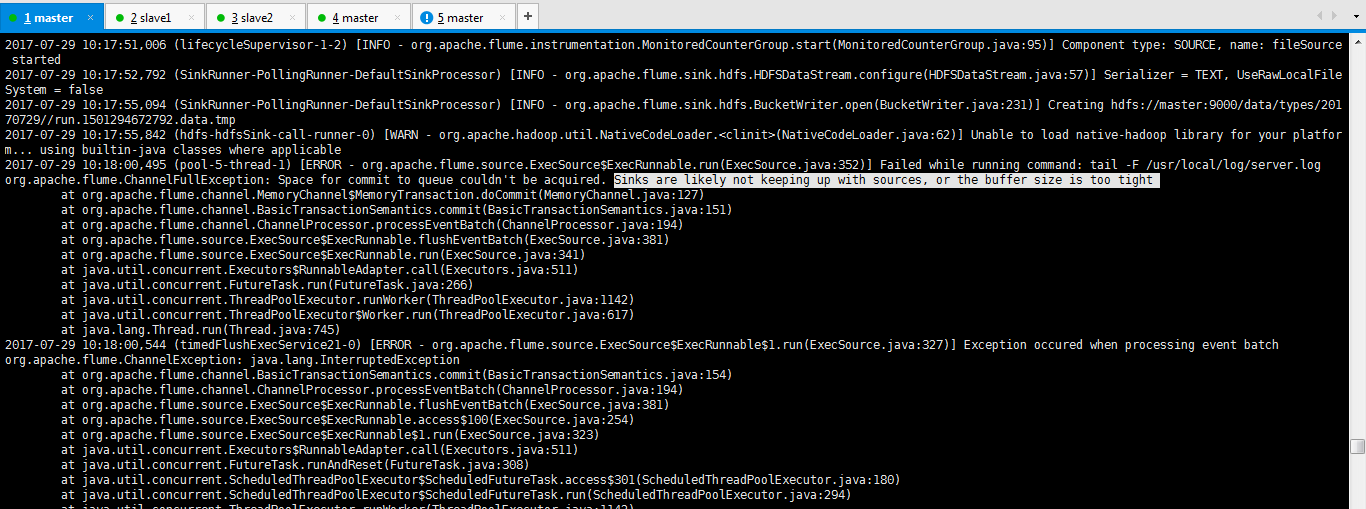
2017-07-29 10:17:51,006 (lifecycleSupervisor-1-2) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: fileSource started 2017-07-29 10:17:52,792 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:57)] Serializer = TEXT, UseRawLocalFileSystem = false 2017-07-29 10:17:55,094 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:231)] Creating hdfs://master:9000/data/types/20170729//run.1501294672792.data.tmp 2017-07-29 10:17:55,842 (hdfs-hdfsSink-call-runner-0) [WARN - org.apache.hadoop.util.NativeCodeLoader.<clinit>(NativeCodeLoader.java:62)] Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2017-07-29 10:18:00,495 (pool-5-thread-1) [ERROR - org.apache.flume.source.ExecSource$ExecRunnable.run(ExecSource.java:352)] Failed while running command: tail -F /usr/local/log/server.log org.apache.flume.ChannelFullException: Space for commit to queue couldn't be acquired. Sinks are likely not keeping up with sources, or the buffer size is too tight at org.apache.flume.channel.MemoryChannel$MemoryTransaction.doCommit(MemoryChannel.java:127) at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151) at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194) at org.apache.flume.source.ExecSource$ExecRunnable.flushEventBatch(ExecSource.java:381) at org.apache.flume.source.ExecSource$ExecRunnable.run(ExecSource.java:341) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) 2017-07-29 10:18:00,544 (timedFlushExecService21-0) [ERROR - org.apache.flume.source.ExecSource$ExecRunnable$1.run(ExecSource.java:327)] Exception occured when processing event batch org.apache.flume.ChannelException: java.lang.InterruptedException at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:154) at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:194) at org.apache.flume.source.ExecSource$ExecRunnable.flushEventBatch(ExecSource.java:381) at org.apache.flume.source.ExecSource$ExecRunnable.access$100(ExecSource.java:254) at org.apache.flume.source.ExecSource$ExecRunnable$1.run(ExecSource.java:323) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
[root@master log]# ll total 4 -rwxr-xr-x 1 root root 1157 Jul 27 14:42 producerLog.sh -rw-r--r-- 1 root root 0 Jul 27 15:30 server.log [root@master log]# ./producerLog.sh
查看
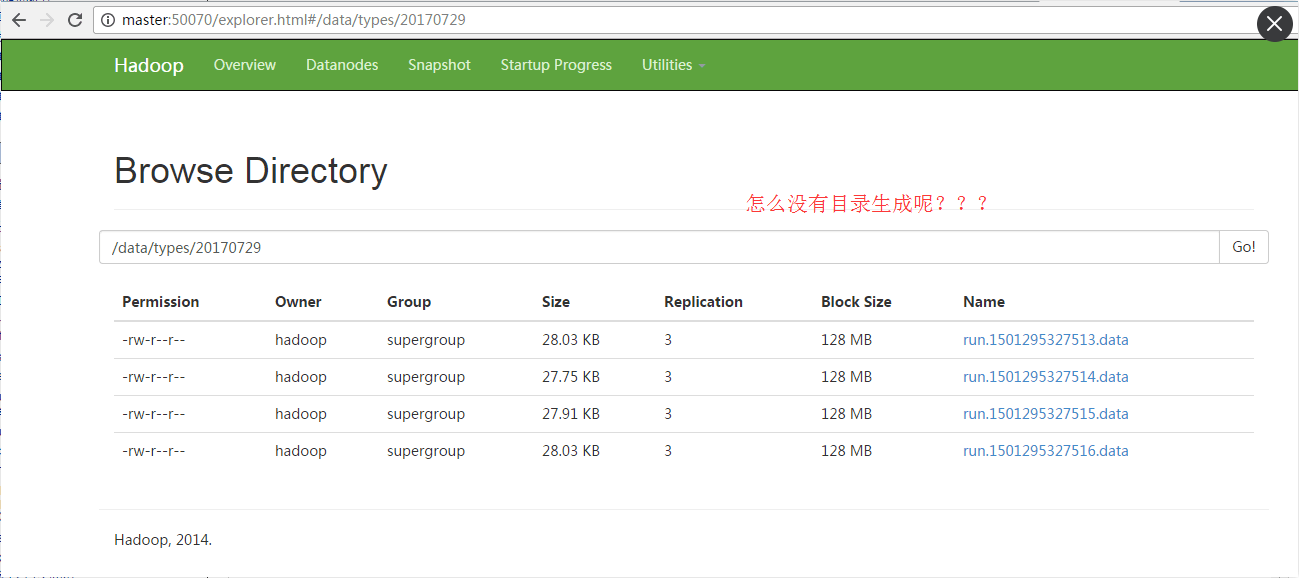
我这里,貌似懂了
是要达到那么多的临时文件大小生成后
才会有一股目标目录出来
让它等吧
flume自定义拦截器实现多行读取日志
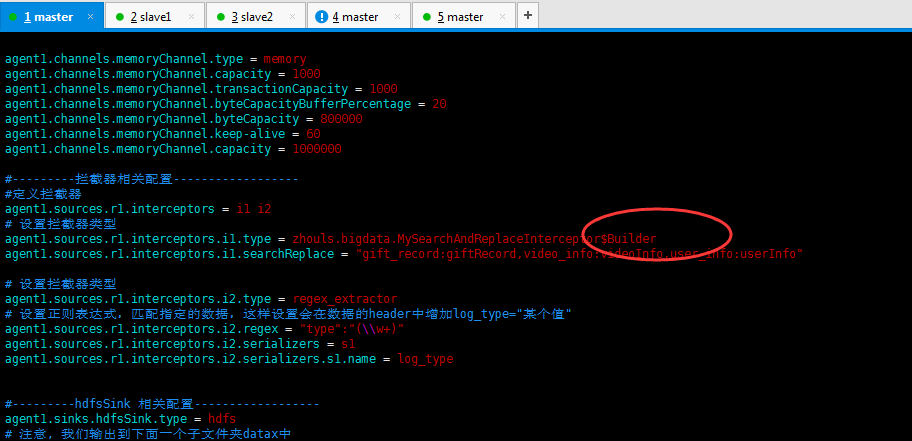
加了还是没用。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/7244211.html,如需转载请自行联系原作者