一、字节序
顾名思义字节的顺序,再多说两句就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。
下面罗列常见的数据类型及其长度对照表:
Wtypes.h 中的非托管类型 非托管C 语言类型 .net托管类名 长度
HANDLE void* System.IntPtr 32 bit位
BYTE unsigned char System.Byte 8 位
SHORT short System.Int16 16 位
WORD unsigned short System.UInt16 16 位
INT int System.Int32 32 位
UINT unsigned int System.UInt32 32 位
LONG long System.Int32 32 位
BOOL long System.Int32 32 位
DWORD unsigned long System.UInt32 32 位
ULONG unsigned long System.UInt32 32 位
CHAR char System.Byte 8 位。
FLOAT Float System.Single 32 位
DOUBLE Double System.Double 64 位
二、字节序分类
有三种:Big-Endian、Little-Endian以及Middle-Endian。常见的主要是Big-Endian和Little-Endian,中文叫高字节序和低字节序(或者是大字节序和小字节序)。引用标准的Big-Endian和Little-Endian的定义如下:
a) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
同时引进主机字节序和网络字节序概念。网络字节序肯定是Big-Endian高字节序,而主机字节序基本上是Little-Endian低字节序,但是主机字节序跟处理器即CPU类型有关,CISC架构的CPU如:X86(包括大部分的intel、AMD等PC处理器)是低字节序,而在嵌入式广泛应用的RISC架构的CPU如:ARM, PowerPC, Alpha, SPARC V9, MIPS等是高字节序的。
三、字节序说明
以c中定义一个16进制的变量为例:unsigned int value = 0x6a7b8c9d,根据上述类型对照表得知,c的unsigned int的value变量为32bit即4个byte。这里的value也等价于:
unsigned char buf[4]= { 0x6a,0x7b,0x8c,0x9d}://语法有问题,就是相当于这么个初始化
现在分别按转高字节序和低字节序解释下,加入这个buf变量的内存初始地址是a:
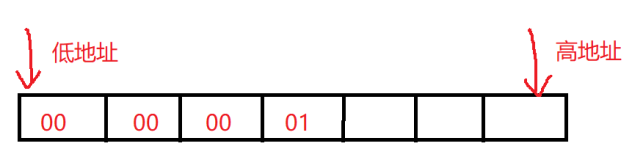
a) Little-Endian: 低地址存放低位 :
(高地址)--------------------------
a+3----- buf[3] (0x6a) -- 高位(相当于10进制的千位)
a+2----- buf[2] (0x7b)
a+1----- buf[1] (0x8c)
a-------- buf[0] (0x9d) -- 低位(相当于10进制的个位)
(低地址)--------------------------
b) Big-Endian: 低地址存放高位:
(高地址)--------------------------
a+3----- buf[3] (0x9d) -- 高位(相当于10进制的千位)
a+2----- buf[2] (0x8c)
a+1----- buf[1] (0x7b)
a-------- buf[0] (0x6a) -- 低位(相当于10进制的个位)
(低地址)--------------------------
一般的处理器高地址对应的是栈底,低地址对应的是栈顶。
四、高/低字节序转换
如果需要在不同的操作系统,或者是基于不同的语言,如c/c++和c#之间不同主机字节序之的网络通信,就需要考虑如何转换字节序。
如果不转换可能遇到问题,这里举个C的客户端和服务器端通信的例子
客户端(低字节序的主机,如intel 奔腾系列处理器)定义: short x=1 为2个byte,在内存中为[1][0](低地址在前面),发送给服务器端。这服务器端(高字节序的主机,如嵌入式的ARM处理器)接收到的为:[1][0](低地址在前面),此时按照高字节序的"低地址存放高位"原则解析的x=256。于实际情况不符。
所以针对这样的情况,编写跨平台或者是跨语言的程序是需要考虑字节序的转换。一般数据发送出去之前需要将主机字节序Little-Endian转换为网络字节序Big-Endian,接收之前需要将Big-Endian转为Little-Endian,下面介绍小.net和C/C++常见方法。
4.1、 .net中:
4.2 、C/C++根据类型的不同有如下方法:
ntohs =net to host short int 16位
htons=host to net short int 16位
ntohl =net to host long int 32位
htonl=host to net long int 32位
简单的说明其中一个方法吧。
将一个无符号短整形数从网络字节顺序转换为主机字节顺序。
#include <winsock.h>
u_short PASCAL FAR ntohs( u_short netshort);
netshort:一个以网络字节顺序表达的16位数。
注释:
本函数将一个16位数由网络字节顺序转换为主机字节顺序。
返回值:
ntohs()返回一个以主机字节顺序表达的数。
五、实际转换过程需要注意点及问题集。
5.1:C++中的unsigned char类型等同于C#的什么类型?
答:C#中的char是16bits的Unicode字符,而一般C++中的字符则是8位的,所以C++中的“unsigned char”在C#中要么转换成char,要么使用Byte类型来代替,前者适用于存放字符型的unsigned char,后者适用于整数型的unsigned char。具体的程序,具体的方法。 比如:c++中申明变量,unsigned char para=0x4a(表示十六进制=2的4次方 ×2的4次方,即8位。 uchar的的范围为0-0xff,即0-255);unsigned char para[4] = 0x6789abcd,表示32位。
5.2:为什么在网络编程中,即需要考虑字节序的问题时。对于double、float以及字符串等数据类型不需要考虑主机序列和网络序列之间的转换?
答:至于float和double,与CPU无关。一般编译器是按照IEEE标准解释的,即把float/double看作4/8个字符的数组进行解释。因此,只要编译器是支持IEEE浮点标准的,就不需要考虑字节顺序。
5.3: BinaryWriter和BinaryReader
BinaryReader和BinaryWriter使用小字节序(即低字节序)读写数据。
如例子:
var stream = new MemoryStream(new byte[] { 4, 1, 0, 0 }); //相当于申请了byte[4],而每个byte相当于256进制
var reader = new BinaryReader(stream);
int i = reader.ReadInt32(); // i == 260
//因为BinaryReader是按照低字节序读取的,所有i=4+256×1=260;
5.4、BitConverter和ASCIIEncoding.ASCII.GetBytes
BitConverter主要是用于.net中byte[]和其他类型的转换,不涉及字符串数据类型。网络通信会经常用到。
ASCIIEncoding.ASCII通常用于字符串和byte[]之间的转换。
5.x: 关于“同样4个字节的数据,我们可以把它看作是1个32位整数、2个Unicode、或者字符4个ASCII字符。”引申:
unicode和utf-8之间最大的区别就是在存储上。unicode是宽字符存储(字符都是2个字节或4个字节来存储),而utf-8是多字节存
储,字符的个数是不确定的(比如英文字符是1个字节表示,汉字可以是2个到6个来表示),其字符的首字节的前几位表明了它的字节
个数。比如某个3字节汉字的uft-8编码(二进制)如下:
1110xxxx 10xxxxxx 10xxxxxx
首字节中1的个数为3表明该汉字用3个字节来表示。
utf-16固定使用两个字节表示一个字符,平常所说的unicode编码就是utf-16的。
ascii字符在utf-8里面还是一样的,一个字节表示,超出ascii字符范围的,就用多字节表示,字节的数目由第一字节确定,最多6
字节。如下:
utf-8:
1字节:0XXXXXXX(ascii)
2字节:110XXXXX 10XXXXXX
3字节:1110XXXX 10XXXXXX 10XXXXXX
4字节:11110XXX 10XXXXXX 10XXXXXX 10XXXXXX
5字节:。。。
utf-16:所有:XXXXXXXX XXXXXXXX
ascii:XXXXXXXX 00000000
ASCII码是用十六进制表示,也就是说它是两个字节byte。如:ASCII码为31(即0x31)对应的字符"1";ASCII码为32(即0x31)对
应的字符"2".
本文转自94cool博客园博客,原文链接:http://www.cnblogs.com/94cool/archive/2010/03/29/1699615.html,如需转载请自行联系原作者