spark-1.6.1-bin-hadoop2.6里Basic包下的SparkPi.scala
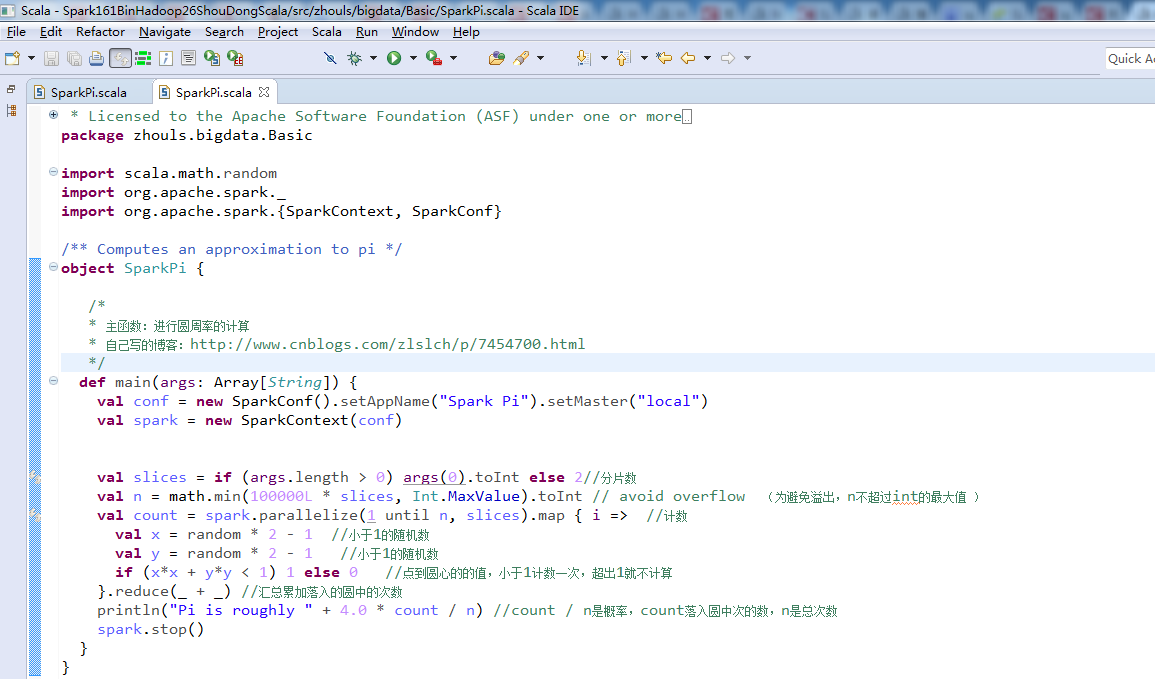

/* * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreements. See the NOTICE file distributed with * this work for additional information regarding copyright ownership. * The ASF licenses this file to You under the Apache License, Version 2.0 * (the "License"); you may not use this file except in compliance with * the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ // scalastyle:off println //package org.apache.spark.examples package zhouls.bigdata.Basic import scala.math.random import org.apache.spark._ import org.apache.spark.{SparkContext, SparkConf} /** Computes an approximation to pi */ object SparkPi { /* * 主函数:进行圆周率的计算 * 自己写的博客:http://www.cnblogs.com/zlslch/p/7454700.html */ def main(args: Array[String]) { val conf = new SparkConf().setAppName("Spark Pi").setMaster("local") val spark = new SparkContext(conf) val slices = if (args.length > 0) args(0).toInt else 2//分片数 val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow (为避免溢出,n不超过int的最大值 ) val count = spark.parallelize(1 until n, slices).map { i => //计数 val x = random * 2 - 1 //小于1的随机数 val y = random * 2 - 1 //小于1的随机数 if (x*x + y*y < 1) 1 else 0 //点到圆心的的值,小于1计数一次,超出1就不计算 }.reduce(_ + _) //汇总累加落入的圆中的次数 println("Pi is roughly " + 4.0 * count / n) //count / n是概率,count落入圆中次的数,n是总次数 spark.stop() } } // scalastyle:on println
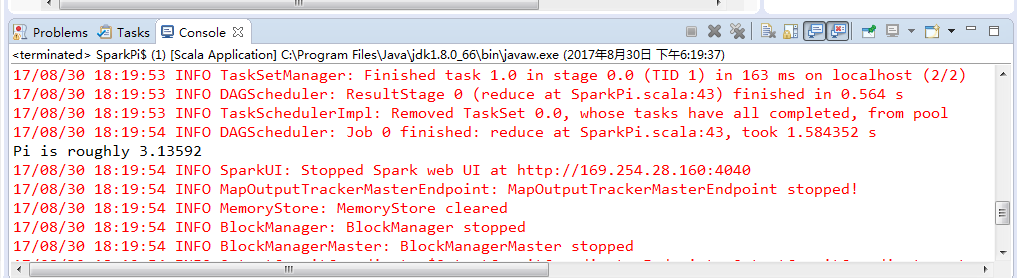
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/D:/SoftWare/spark-1.6.1-bin-hadoop2.6/lib/spark-assembly-1.6.1-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/D:/SoftWare/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 17/08/30 18:19:38 INFO SparkContext: Running Spark version 1.6.1 17/08/30 18:19:40 INFO SecurityManager: Changing view acls to: Administrator 17/08/30 18:19:40 INFO SecurityManager: Changing modify acls to: Administrator 17/08/30 18:19:40 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Administrator); users with modify permissions: Set(Administrator) 17/08/30 18:19:45 INFO Utils: Successfully started service 'sparkDriver' on port 50997. 17/08/30 18:19:46 INFO Slf4jLogger: Slf4jLogger started 17/08/30 18:19:46 INFO Remoting: Starting remoting 17/08/30 18:19:46 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@169.254.28.160:51011] 17/08/30 18:19:46 INFO Utils: Successfully started service 'sparkDriverActorSystem' on port 51011. 17/08/30 18:19:46 INFO SparkEnv: Registering MapOutputTracker 17/08/30 18:19:47 INFO SparkEnv: Registering BlockManagerMaster 17/08/30 18:19:47 INFO DiskBlockManager: Created local directory at C:\Users\Administrator\AppData\Local\Temp\blockmgr-1b45f544-2ff9-4f37-bd89-5550f0f1d613 17/08/30 18:19:47 INFO MemoryStore: MemoryStore started with capacity 1131.0 MB 17/08/30 18:19:47 INFO SparkEnv: Registering OutputCommitCoordinator 17/08/30 18:19:48 INFO Utils: Successfully started service 'SparkUI' on port 4040. 17/08/30 18:19:48 INFO SparkUI: Started SparkUI at http://169.254.28.160:4040 17/08/30 18:19:49 INFO Executor: Starting executor ID driver on host localhost 17/08/30 18:19:49 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 51018. 17/08/30 18:19:49 INFO NettyBlockTransferService: Server created on 51018 17/08/30 18:19:49 INFO BlockManagerMaster: Trying to register BlockManager 17/08/30 18:19:49 INFO BlockManagerMasterEndpoint: Registering block manager localhost:51018 with 1131.0 MB RAM, BlockManagerId(driver, localhost, 51018) 17/08/30 18:19:49 INFO BlockManagerMaster: Registered BlockManager 17/08/30 18:19:52 INFO SparkContext: Starting job: reduce at SparkPi.scala:43 17/08/30 18:19:52 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:43) with 2 output partitions 17/08/30 18:19:52 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:43) 17/08/30 18:19:52 INFO DAGScheduler: Parents of final stage: List() 17/08/30 18:19:52 INFO DAGScheduler: Missing parents: List() 17/08/30 18:19:52 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:39), which has no missing parents 17/08/30 18:19:53 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1896.0 B, free 1896.0 B) 17/08/30 18:19:53 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1226.0 B, free 3.0 KB) 17/08/30 18:19:53 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:51018 (size: 1226.0 B, free: 1131.0 MB) 17/08/30 18:19:53 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006 17/08/30 18:19:53 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:39) 17/08/30 18:19:53 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks 17/08/30 18:19:53 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, partition 0,PROCESS_LOCAL, 2078 bytes) 17/08/30 18:19:53 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 17/08/30 18:19:53 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1031 bytes result sent to driver 17/08/30 18:19:53 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, partition 1,PROCESS_LOCAL, 2078 bytes) 17/08/30 18:19:53 INFO Executor: Running task 1.0 in stage 0.0 (TID 1) 17/08/30 18:19:53 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 385 ms on localhost (1/2) 17/08/30 18:19:53 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1031 bytes result sent to driver 17/08/30 18:19:53 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 163 ms on localhost (2/2) 17/08/30 18:19:53 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:43) finished in 0.564 s 17/08/30 18:19:53 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 17/08/30 18:19:54 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:43, took 1.584352 s Pi is roughly 3.13592 17/08/30 18:19:54 INFO SparkUI: Stopped Spark web UI at http://169.254.28.160:4040 17/08/30 18:19:54 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 17/08/30 18:19:54 INFO MemoryStore: MemoryStore cleared 17/08/30 18:19:54 INFO BlockManager: BlockManager stopped 17/08/30 18:19:54 INFO BlockManagerMaster: BlockManagerMaster stopped 17/08/30 18:19:54 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 17/08/30 18:19:54 INFO SparkContext: Successfully stopped SparkContext 17/08/30 18:19:54 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon. 17/08/30 18:19:54 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports. 17/08/30 18:19:54 INFO ShutdownHookManager: Shutdown hook called 17/08/30 18:19:54 INFO ShutdownHookManager: Deleting directory C:\Users\Administrator\AppData\Local\Temp\spark-3eb1c92a-7733-44d7-9b73-3c78355daf21
spark-2.2.0-bin-hadoop2.6里Basic包下的SparkPi.scala
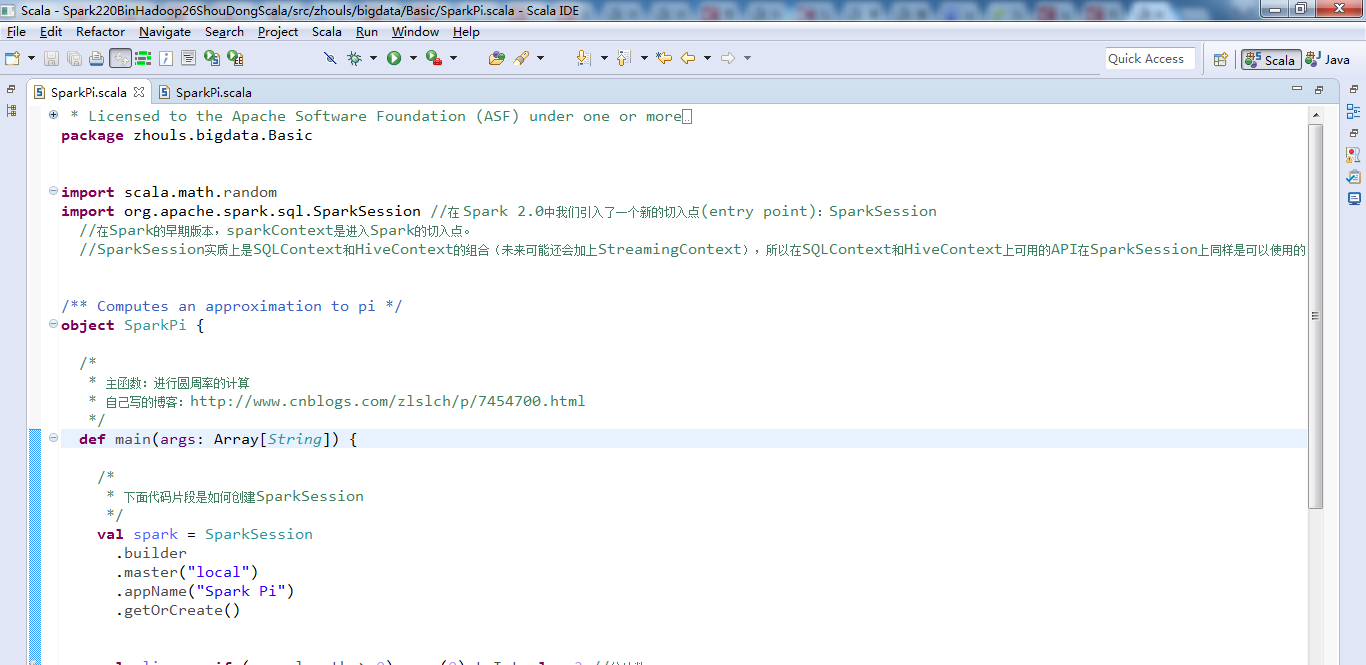
/* * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreements. See the NOTICE file distributed with * this work for additional information regarding copyright ownership. * The ASF licenses this file to You under the Apache License, Version 2.0 * (the "License"); you may not use this file except in compliance with * the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ // scalastyle:off println //package org.apache.spark.examples package zhouls.bigdata.Basic import scala.math.random import org.apache.spark.sql.SparkSession //在 Spark 2.0中我们引入了一个新的切入点(entry point):SparkSession //在Spark的早期版本,sparkContext是进入Spark的切入点。 //SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的。 /** Computes an approximation to pi */ object SparkPi { /* * 主函数:进行圆周率的计算 * 自己写的博客:http://www.cnblogs.com/zlslch/p/7454700.html */ def main(args: Array[String]) { /* * 下面代码片段是如何创建SparkSession */ val spark = SparkSession .builder .master("local") .appName("Spark Pi") .getOrCreate() val slices = if (args.length > 0) args(0).toInt else 2 //分片数 val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow (为避免溢出,n不超过int的最大值 ) val count = spark.sparkContext.parallelize(1 until n, slices).map { i => //计数 val x = random * 2 - 1 //小于1的随机数 val y = random * 2 - 1 //小于1的随机数 if (x*x + y*y <= 1) 1 else 0 //点到圆心的的值,小于1计数一次,超出1就不计算 }.reduce(_ + _) //汇总累加落入的圆中的次数 println("Pi is roughly " + 4.0 * count / (n - 1)) //count / n是概率,count落入圆中次的数,n是总次数 spark.stop() } } // scalastyle:on println
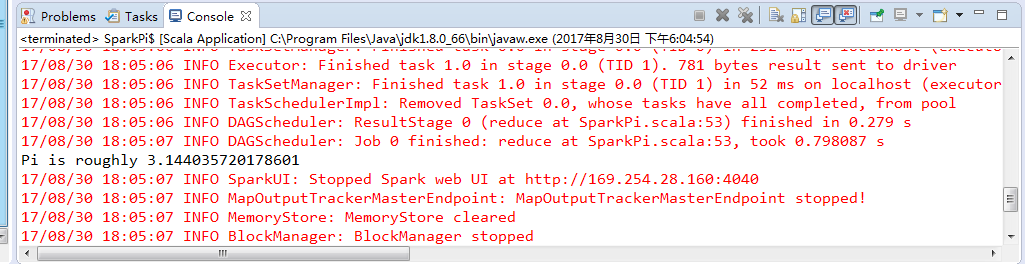
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 17/08/30 18:04:58 INFO SparkContext: Running Spark version 2.2.0 17/08/30 18:04:59 INFO SparkContext: Submitted application: Spark Pi 17/08/30 18:04:59 INFO SecurityManager: Changing view acls to: Administrator 17/08/30 18:04:59 INFO SecurityManager: Changing modify acls to: Administrator 17/08/30 18:04:59 INFO SecurityManager: Changing view acls groups to: 17/08/30 18:04:59 INFO SecurityManager: Changing modify acls groups to: 17/08/30 18:04:59 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Administrator); groups with view permissions: Set(); users with modify permissions: Set(Administrator); groups with modify permissions: Set() 17/08/30 18:05:01 INFO Utils: Successfully started service 'sparkDriver' on port 50715. 17/08/30 18:05:01 INFO SparkEnv: Registering MapOutputTracker 17/08/30 18:05:01 INFO SparkEnv: Registering BlockManagerMaster 17/08/30 18:05:01 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information 17/08/30 18:05:01 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up 17/08/30 18:05:01 INFO DiskBlockManager: Created local directory at C:\Users\Administrator\AppData\Local\Temp\blockmgr-14ee4a48-aeba-4509-8163-ed12fae0aa1a 17/08/30 18:05:01 INFO MemoryStore: MemoryStore started with capacity 904.8 MB 17/08/30 18:05:02 INFO SparkEnv: Registering OutputCommitCoordinator 17/08/30 18:05:02 INFO Utils: Successfully started service 'SparkUI' on port 4040. 17/08/30 18:05:03 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://169.254.28.160:4040 17/08/30 18:05:03 INFO Executor: Starting executor ID driver on host localhost 17/08/30 18:05:03 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 50725. 17/08/30 18:05:03 INFO NettyBlockTransferService: Server created on 169.254.28.160:50725 17/08/30 18:05:03 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy 17/08/30 18:05:03 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 169.254.28.160, 50725, None) 17/08/30 18:05:03 INFO BlockManagerMasterEndpoint: Registering block manager 169.254.28.160:50725 with 904.8 MB RAM, BlockManagerId(driver, 169.254.28.160, 50725, None) 17/08/30 18:05:03 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 169.254.28.160, 50725, None) 17/08/30 18:05:03 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 169.254.28.160, 50725, None) 17/08/30 18:05:04 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/D:/Code/EclipsePaperCode/Spark220BinHadoop26ShouDongScala/spark-warehouse/'). 17/08/30 18:05:04 INFO SharedState: Warehouse path is 'file:/D:/Code/EclipsePaperCode/Spark220BinHadoop26ShouDongScala/spark-warehouse/'. 17/08/30 18:05:05 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint 17/08/30 18:05:06 INFO SparkContext: Starting job: reduce at SparkPi.scala:53 17/08/30 18:05:06 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:53) with 2 output partitions 17/08/30 18:05:06 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:53) 17/08/30 18:05:06 INFO DAGScheduler: Parents of final stage: List() 17/08/30 18:05:06 INFO DAGScheduler: Missing parents: List() 17/08/30 18:05:06 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:49), which has no missing parents 17/08/30 18:05:06 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1816.0 B, free 904.8 MB) 17/08/30 18:05:06 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1182.0 B, free 904.8 MB) 17/08/30 18:05:06 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 169.254.28.160:50725 (size: 1182.0 B, free: 904.8 MB) 17/08/30 18:05:06 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006 17/08/30 18:05:06 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:49) (first 15 tasks are for partitions Vector(0, 1)) 17/08/30 18:05:06 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks 17/08/30 18:05:06 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 4825 bytes) 17/08/30 18:05:06 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 17/08/30 18:05:06 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 824 bytes result sent to driver 17/08/30 18:05:06 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 4825 bytes) 17/08/30 18:05:06 INFO Executor: Running task 1.0 in stage 0.0 (TID 1) 17/08/30 18:05:06 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 232 ms on localhost (executor driver) (1/2) 17/08/30 18:05:06 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 781 bytes result sent to driver 17/08/30 18:05:06 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 52 ms on localhost (executor driver) (2/2) 17/08/30 18:05:06 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 17/08/30 18:05:06 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:53) finished in 0.279 s 17/08/30 18:05:07 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:53, took 0.798087 s Pi is roughly 3.144035720178601 17/08/30 18:05:07 INFO SparkUI: Stopped Spark web UI at http://169.254.28.160:4040 17/08/30 18:05:07 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 17/08/30 18:05:07 INFO MemoryStore: MemoryStore cleared 17/08/30 18:05:07 INFO BlockManager: BlockManager stopped 17/08/30 18:05:07 INFO BlockManagerMaster: BlockManagerMaster stopped 17/08/30 18:05:07 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 17/08/30 18:05:07 INFO SparkContext: Successfully stopped SparkContext 17/08/30 18:05:07 INFO ShutdownHookManager: Shutdown hook called 17/08/30 18:05:07 INFO ShutdownHookManager: Deleting directory C:\Users\Administrator\AppData\Local\Temp\spark-8fa7e9af-5f1c-468a-9583-4d4fb4490449
