丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
AI Agent 十问十答,降低认知摩擦
利用通义灵码和魔搭 Notebook 环境快速搭建一个 AIGC 应用 | 视频课
对比测评:为什么AI编程工具需要 Rules 能力?
StrmVol 存储卷:如何解锁 K8s 对象存储海量小文件访问性能新高度?
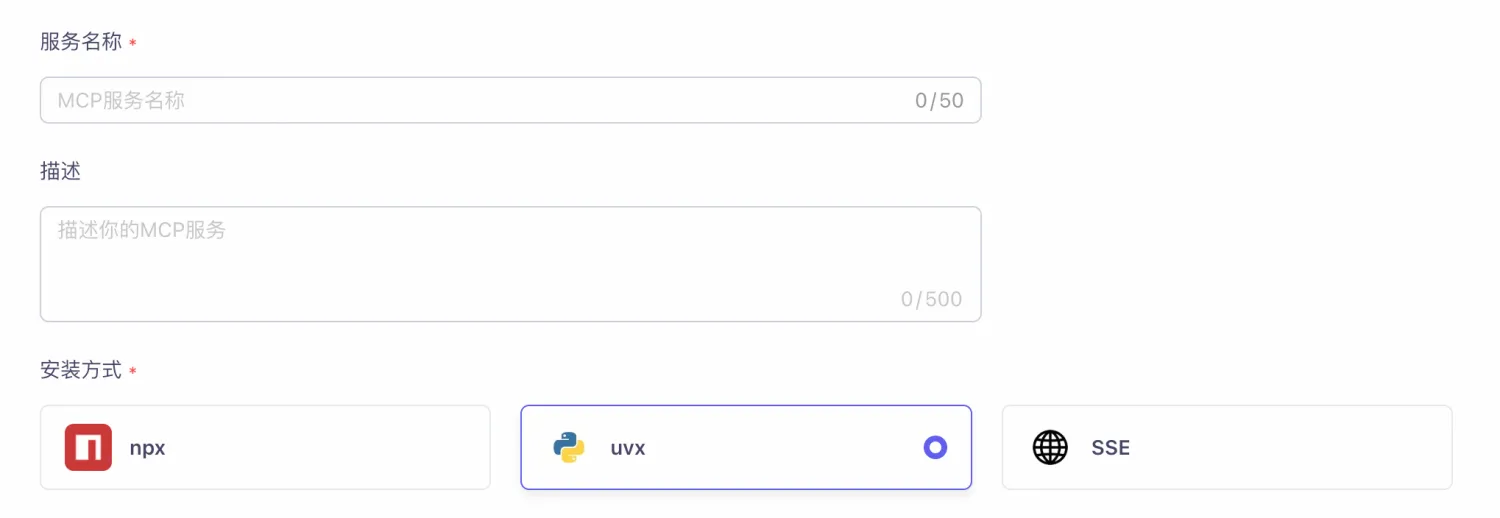
在阿里云百炼平台配置您的自定义阿里云MCP Server
MCP Server 实践之旅第 1 站:MCP 协议解析与云上适配
Bolt.diy 一键部署,“一句话”实现全栈开发
理工科 MCP Server 神器,补足人工智能幻觉短板
SAE 实现应用发布全过程可观测
A2A(Agent2Agent) 简介
通义灵码技术进阶实战:三个企业级应用案例深度解析
301重定向:网站迁移与SEO优化的关键技术指南
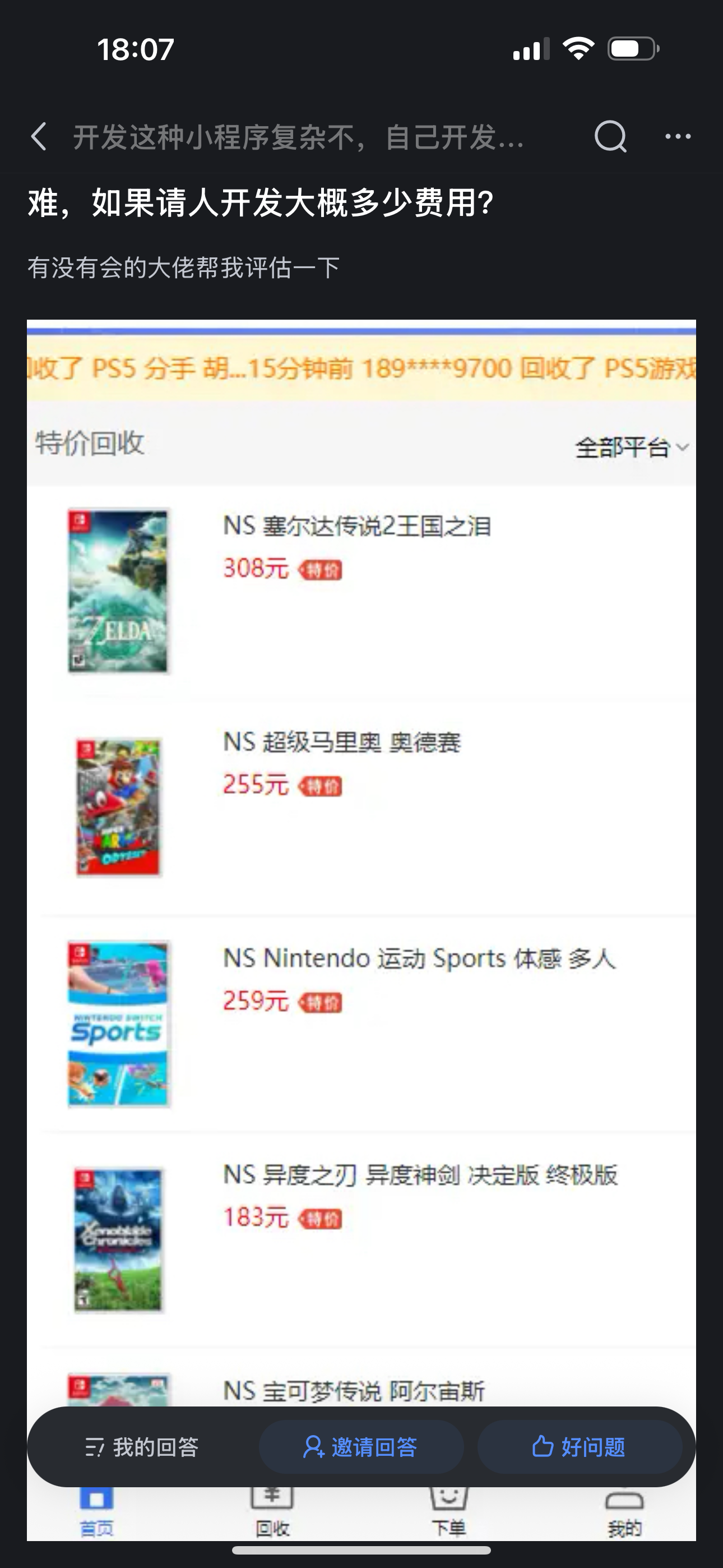
游戏开发成本认知鸿沟:从民间臆测到3A现实的残酷距离-优雅草卓伊凡
《前端秘籍:SCSS阴影效果全兼容指南》
《解锁SCSS算术运算:构建灵动样式的奥秘》
5G赛道,谁主沉浮?——技术、市场与背后的博弈
酷阿鲸森林农场:Java 区块链系统中的 P2P 区块同步与节点自动加入机制
别再全靠人眼盯日志了,深度学习帮你自动测出“炸锅点”
别让“数据”白跑!大数据也能拯救地球
酷阿鲸森林农场:使用 Java 构建的去中心化区块链电商系统
亲测:Grok 3.5 国内使用指南, Grok 3.5的正确使用方法揭晓!
使用 Dockerfile 定制镜像
Spring MVC设计与实现
Access Granted!! Here's the recipe behind my AI DMS
AI Agents: how they work and how to build them
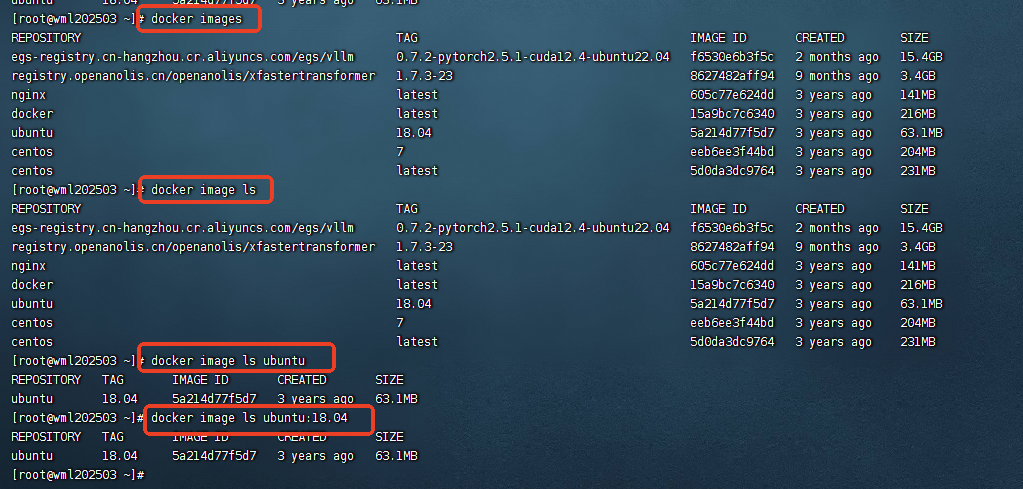
docker 镜像的部分常用命令
Python:蓝牙心率广播设备监测(BLE 心率监测器)技术解析与实现
在Node.js中,如何合理使用模块来避免全局变量的问题?
如何减少Node.js应用中的全局变量?
有哪些有效的方法可以优化Node.js应用的性能?
【设计模式】【创建型模式】单例模式(Singleton)
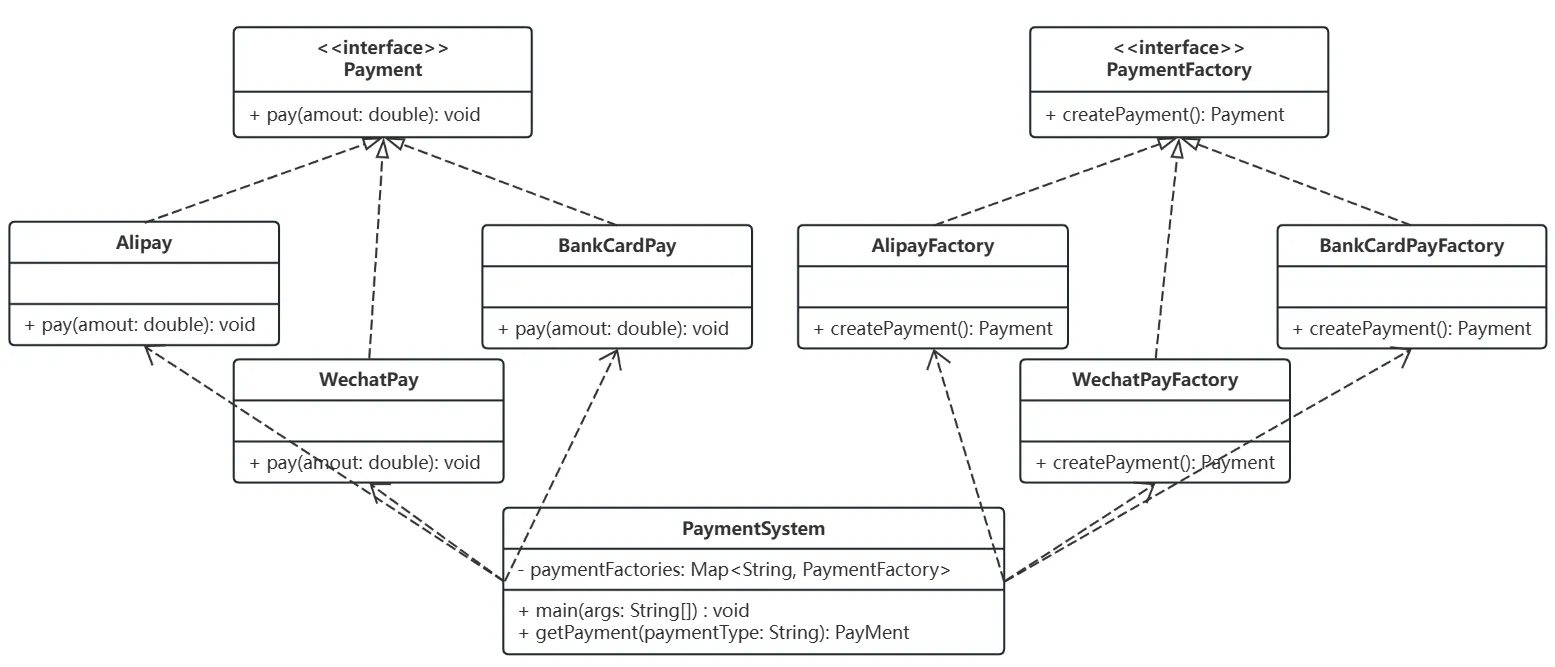
【设计模式】【创建型模式】工厂方法模式(Factory Methods)
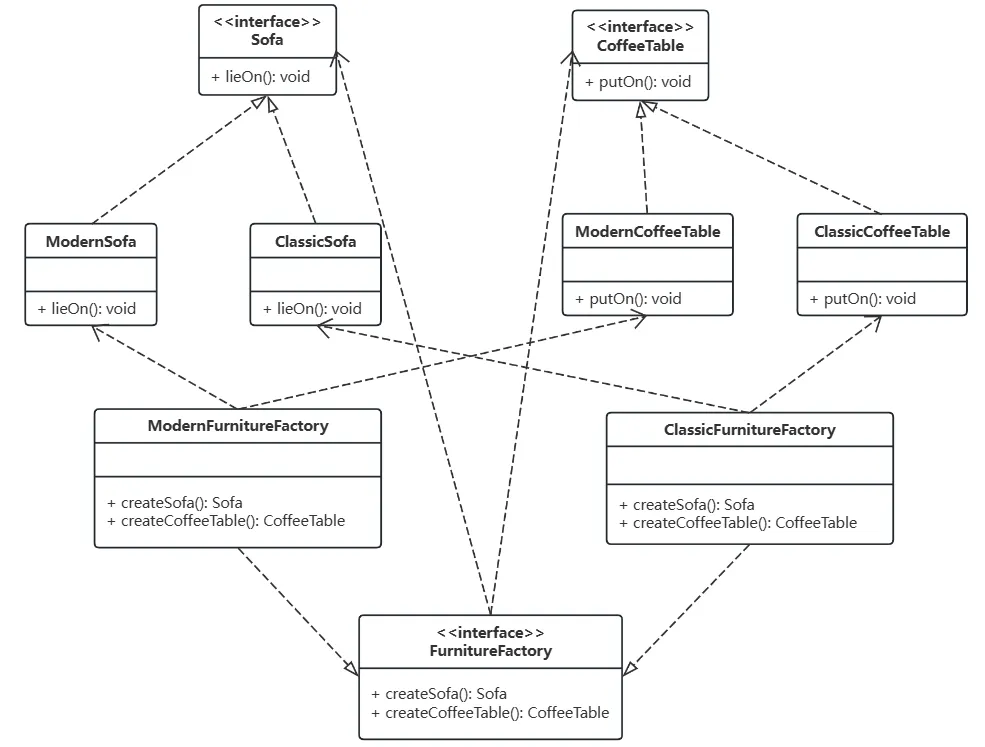
【设计模式】【创建型模式】抽象工厂模式(Abstract Factory)
在Promise.race()中判断哪个Promise被拒绝了
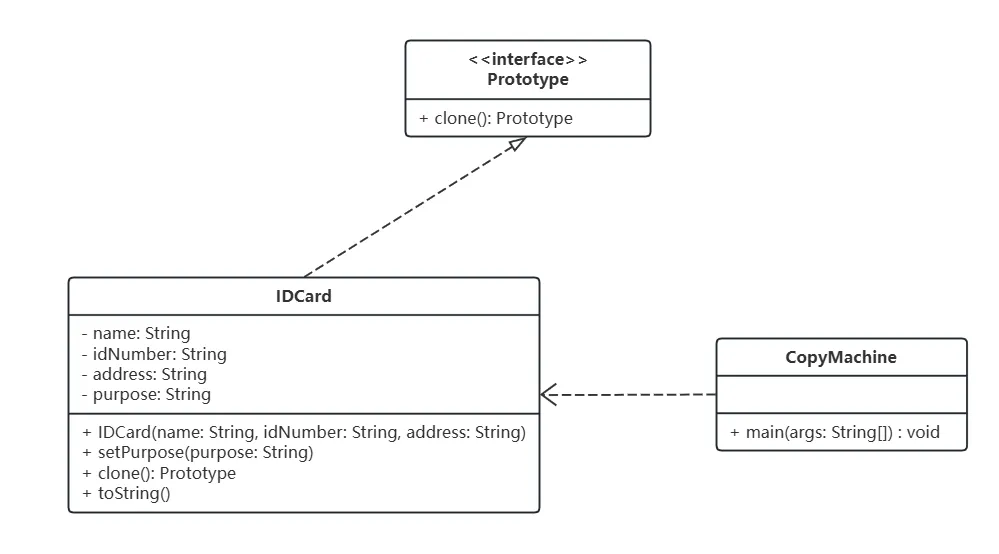
【设计模式】【创建型模式】原型模式(Prototype)
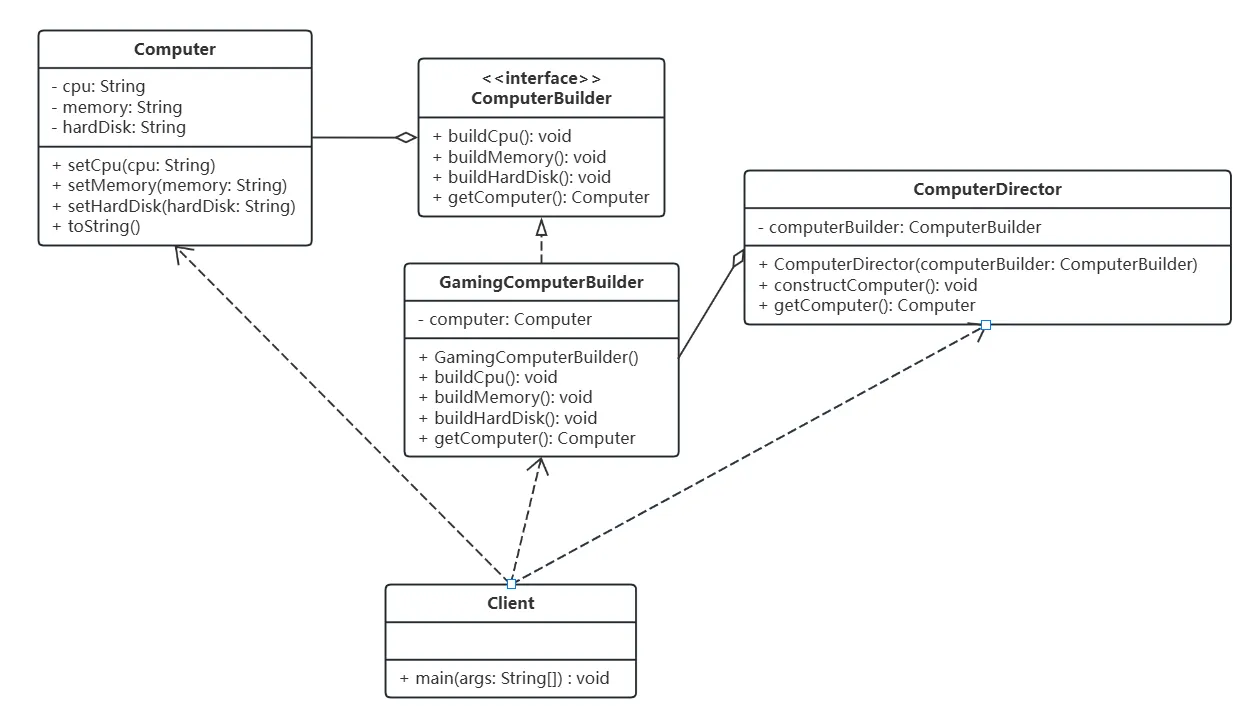
【设计模式】【创建型模式】建造者模式(Builder)
【设计模式】【结构型模式】代理模式(Proxy)
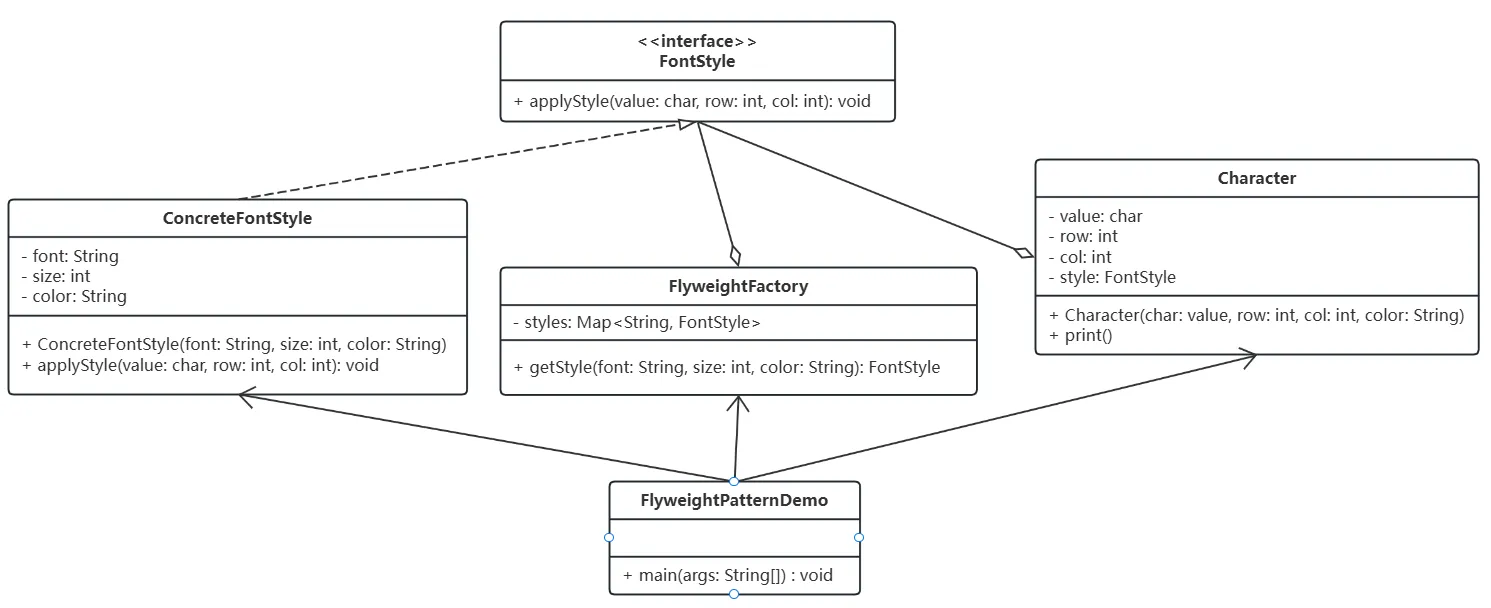
【设计模式】【结构型模式】享元模式(Flyweight)
在Promise.race()中,如何判断是哪个Promise被解决了?
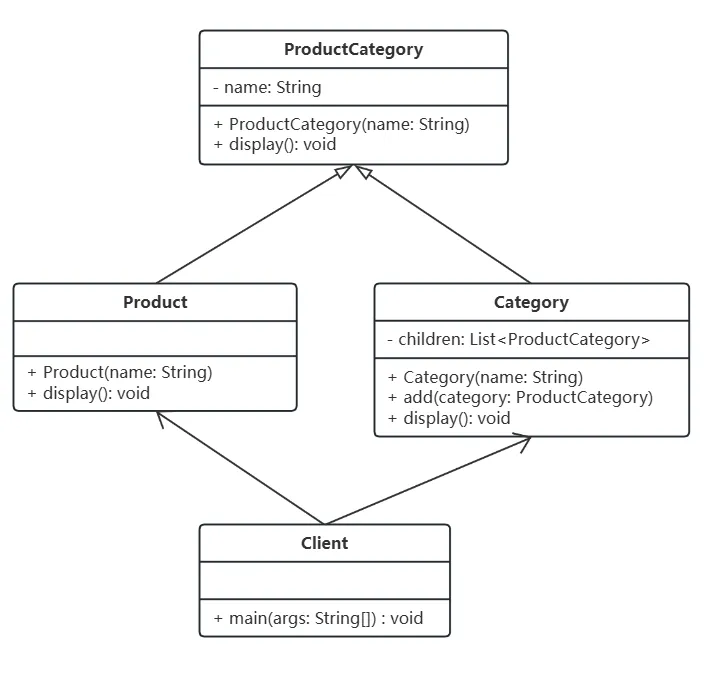
【设计模式】【结构型模式】组合模式(Composite)
如何在Promise.race()中处理超时后的操作?
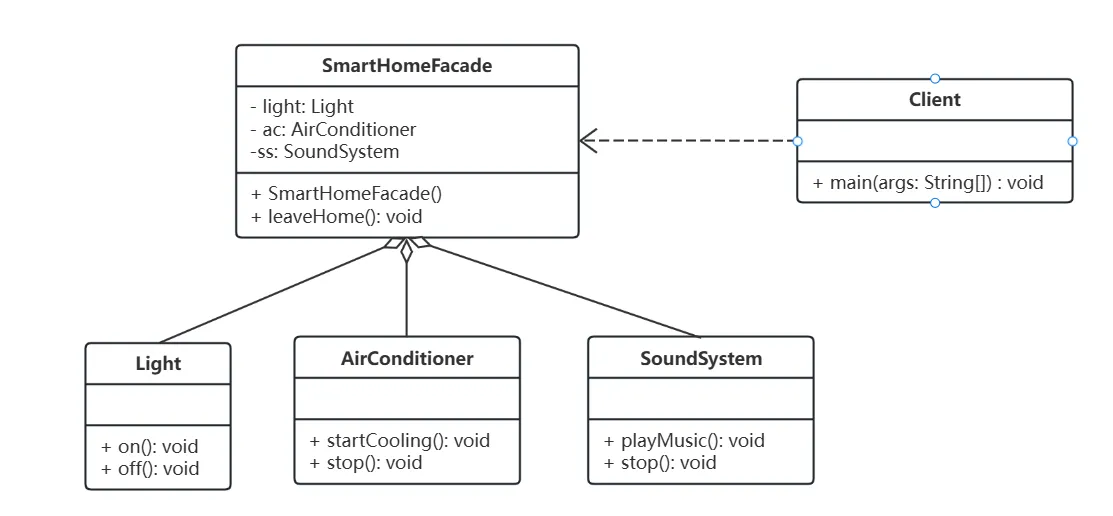
【设计模式】【结构型模式】外观模式(Facde)
在什么场景下适合使用 Promise.race() 方法?
如何使用 Promise 的 race 方法?
如何使用 Promise 的 all 方法?
基于Java+Springboot+Vue开发的体育用品商城管理系统源码+运行
大数据与机器学习:数据驱动的智能时代
云效DevOps:加速企业数字化转型的利器
监理17年选择真题解析
【Oracle】使用Navicat Premium连接Oracle数据库两种方法
社区积分兑好礼