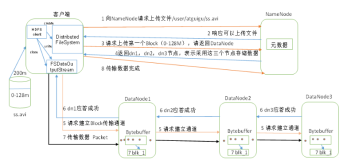
列式系统可提供的优势
对于查询内容之外的列,不必执行I/O和解压(若适用)操作
非常适合仅访问小部分列的查询.如果访问的列很多,则行存格式更为合适
相比由多行构成的数据块,列内的信息熵更低,所以从压缩角度来看,列式存储通常会非常高效.换句话说,同一列中的数据比行存数据块中的数据更为相似.当某一列的取值不多是,行存与列存在压缩效果上的差异尤为显著
数据仓库类型的应用需要在极大的数据集上对某些特定的列进行聚合操作,而列式存储格式通常很适合此类应用场景
显然,列式文件格式也常常出现在Hadoop的应用中.Hadoop支持的列式格式包括一度广泛应用为Hive格式的RPFile,以及其他格式,如ORC(Optimized Row Columnar),以及Parquet等.
RCFile
RCFile专为高效处理MapReduce应用程序而开发,尽管在时间过程中,它一般只作为Hive存储格式使用.RCFile的开发旨在快速加载和查询数据,以及更高效的利用存储空间.RCFile格式将文件按行进行分片,每个分片按列存储.
与SequenceFile相比,RCFile格式在查询与压缩性能方面有很多优势.但这种格式也存在一些缺陷,会阻碍查询时间和压缩空间的进一步优化.这些问题很多都可以由更为新型的列式存储格式(比如ORC与Parquet)化解.大部分不断涌现的应用很有可能放弃使用RCFile,改用新型的列存格式.不过,RCFile目前仍然是Hive中常用的存储格式.
ORC
ORC格式的开发初中是为了弥补RCFile格式方面的一些不足,尤其是查询性能和存储效率方面的缺陷.相比RCFile,ORC格式在很多方面都有显著进步,其特点和优势如下.
通过特定类型(type-specific)的reader与writer提供轻量级的,在线的(always-on)压缩.ORC还支持使用zlib,LZO和Snappy压缩算法提供进一步的压缩
能够将谓词下推至存储层,仅返回查询所需要的数据
支持Hive类型的模型,包括新增的decimal类型与复杂类型.
支持分片
Parquet
Parquet和ORC有很多相同的设计目标,但是Parquet有意成为Hadoop上的通用存储格式.Parquet的目标是成为能够普遍应用于不同MapReduce接口(如Java,Hive与Pig)的格式,同事也要适应其他处理引擎(如Impala与Spark).Parquet的优势如下,其中很多优势与ORC相同
与ORC文件类似,Parquet允许金返回需要的数据字段,因此减少了I/O,提升了性能
提供高效的压缩,可以在每列上指定压缩算法
设计的初衷便是支持复杂的嵌套数据结构
在文件尾部有完整的元数据信息存储,所以Parquet文件是自描述的
完全支持通过Avro和Thrift API写入与读取
使用可扩展的高效编码模式,比如 按位封装(bit-packaging)和游程编码(Run Length Encoding,RLE)
不同文件格式的失败行为
不同文件格式之间一个重要的差异在于如何处理数据错误,某些格式可以更好的处理文件损坏.
列式格式虽然高效,但是在错误处理方面表现并不是很好,这是因为文件损毁可能导致行不完全.
序列化格式在第一个出错的行之前能够正常读取,但是在随后的行中无法恢复
Avro的错误处理能力最强,出现错误记录时,读操作将在下一个同步点(syncpoint)继续,所以错误只会影响文件的一部分