1.概述
大多数情况下,我们使用 Kafka 只是作为消息处理。在有些情况下,我们需要多次读取 Kafka 集群中的数据。当然,我们可以通过调用 Kafka 的 API 来完成,但是针对不同的业务需求,我们需要去编写不同的接口,在经过编译,打包,发布等一系列流程。最后才能看到我们预想的结果。那么,我们能不能有一种 简便的方式去实现这一部分功能,通过编写 SQL 的方式,来可视化我们的结果。今天,笔者给大家分享一些心得,通过使用 SQL 的形式来完成这些需求。
2.内容
实现这些功能,其架构和思路并不复杂。这里笔者将整个实现流程,通过一个原理图来呈现。如下图所示:

这里笔者给大家详述一下上图的含义,消息数据源存放与 Kafka 集群当中,开启低阶和高阶两个消费线程,将消费的结果以 RPC 的方式共享出去(即:请求者)。数据共享出去后,回流经到 SQL 引擎处,将内存中的数据翻译成 SQL Tree,这里使用到了 Apache 的 Calcite 项目来承担这一部分工作。然后,我们通过 Thrift 协议来响应 Web Console 的 SQL 请求,最后将结果返回给前端,让其以图表的实行可视化。
3.插件配置
这里,我们需要遵循 Calcite 的 JSON Models,比如,针对 Kafka 集群,我们需要配置一下内容:
{
version: '1.0',
defaultSchema: 'kafka',
schemas: [
{
name: 'kafka',
type: 'custom',
factory: 'cn.smartloli.kafka.visual.engine.KafkaMemorySchemaFactory',
operand: {
database: 'kafka_db'
}
}
]
} 另外,这里最好对表也做一个表述,配置内容如下所示:
[
{
"table":"Kafka",
"schemas":{
"_plat":"varchar",
"_uid":"varchar",
"_tm":"varchar",
"ip":"varchar",
"country":"varchar",
"city":"varchar",
"location":"jsonarray"
}
}
]4.操作
下面,笔者给大家演示通过 SQL 来操作相关内容。相关截图如下所示:
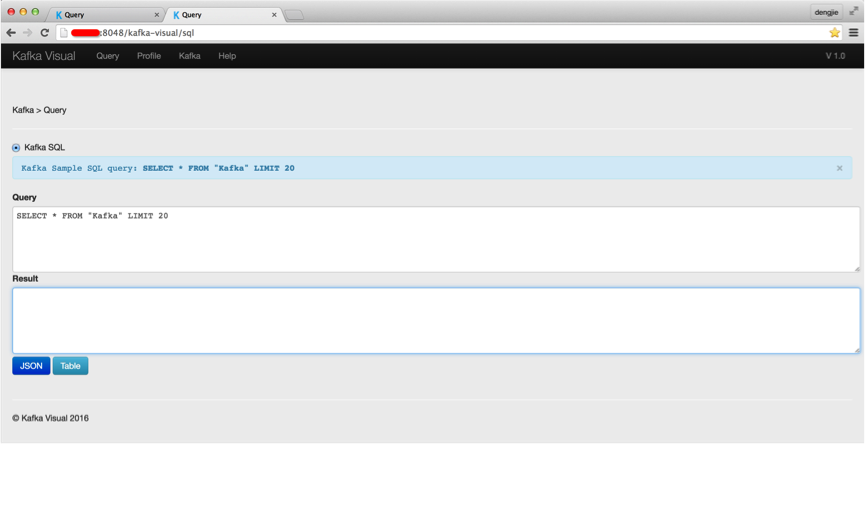
在查询处,填写相关 SQL 查询语句。点击 Table 按钮,得到如下所示结果:

我们,可以将获取的结果以报表的形式进行导出。
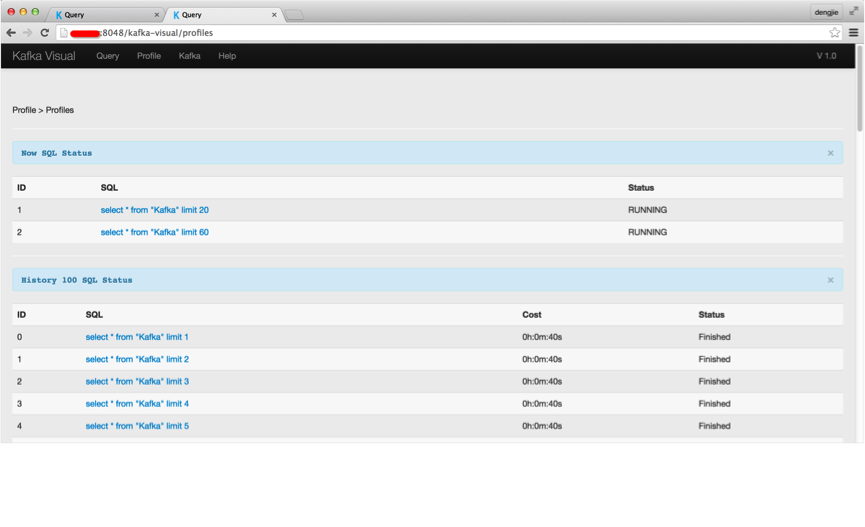
当然,我们可以在 Profile 模块下,浏览查询历史记录和当前正在运行的查询任务。至于其他模块,都属于辅助功能(展示集群信息,Topic 的 Partition 信息等)这里就不多赘述了。
5.总结
分析下来,整体架构和实现的思路都不算太复杂,也不存在太大的难点,需要注意一些实现上的细节,比如消费 API 针对集群消息参数的调整,特别是低阶消费 API,尤为需要注意,其 fetch_size 的大小,以及 offset 是需要我们自己维护的。在使用 Calcite 作为 SQL 树时,我们要遵循其 JSON Model 和标准的 SQL 语法来操作数据源。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!